Мова програмування Rust
Стів Клабнік, Керол Ніколс і Кріс Крайчо, за участі спільноти Rust
Ця версія тексту передбачає, що ви використовуєте Rust 1.90.0 (випущений 2025-09-18)
або новіший із edition = "2024" у файлі Cargo.toml усіх проєктів, щоб
налаштувати їх на використання ідіом Rust 2024 Edition. Дивіться розділ “Встановлення”
у Розділі 1 для інструкцій зі встановлення або
оновлення Rust, а також Додаток E для інформації
про редакції.
Формат HTML доступний онлайн за адресою
https://doc.rust-lang.org/stable/book/
і офлайн у встановленнях Rust, зроблених за допомогою rustup; виконайте rustup doc --book, щоб відкрити.
Також доступні кілька спільнотних перекладів.
Цей текст доступний у друкованому та електронному форматах від No Starch Press.
🚨 Хочете більш інтерактивний досвід навчання? Спробуйте іншу версію Книги про Rust, яка містить: вікторини, підсвічування, візуалізації та більше: https://rust-book.cs.brown.edu
Передмова
Мова програмування Rust пройшла довгий шлях за кілька коротких років: від свого створення та становлення невеликою й молодою спільнотою ентузіастів до того, щоб стати однією з найулюбленіших і найбільш затребуваних мов програмування у світі. Озираючись назад, можна сказати, що було неминучим те, що сила й перспективи Rust привернуть увагу та закріплять його позиції в системному програмуванні. Неминучим не було глобальне зростання інтересу та інновацій, яке поширилося через спільноти відкритого коду й стало каталізатором широкомасштабного впровадження в різних галузях.
На цьому етапі легко вказати на чудові можливості, які пропонує Rust, щоб пояснити цей вибух інтересу та впровадження. Хто ж не хоче безпеки пам’яті (memory safety), і швидкої продуктивності, і дружнього компілятора, і чудового інструментарію, серед безлічі інших чудових можливостей? Мова Rust, яку ви бачите сьогодні, поєднує роки досліджень у системному програмуванні з практичною мудрістю живої й захопленої спільноти. Цю мову було спроєктовано цілеспрямовано й створено дбайливо, пропонуючи розробникам інструмент, який полегшує написання безпечного, швидкого й надійного коду.
Але те, що робить Rust по-справжньому особливим, — це його коріння в наданні вам, користувачеві, можливостей досягати своїх цілей. Це мова, яка хоче, щоб ви досягли успіху, і принцип надання можливостей проходить через саму основу спільноти, яка створює, підтримує й популяризує цю мову. Від часу попереднього видання цього авторитетного тексту Rust ще більше розвинувся в справді глобальну й надійну мову. Проєкт Rust тепер має надійну підтримку Rust Foundation, яка також інвестує в ключові ініціативи, щоб забезпечити безпеку, стабільність і сталість Rust.
Це видання The Rust Programming Language є всеосяжним оновленням, яке відображає еволюцію мови протягом років і надає цінну нову інформацію. Але це не просто посібник із синтаксису та бібліотек — це запрошення приєднатися до спільноти, яка цінує якість, продуктивність і продуманий дизайн. Незалежно від того, чи ви досвідчений розробник, який хоче вперше спробувати Rust, чи досвідчений растацеанець (Rustacean), який хоче вдосконалити свої навички, це видання пропонує щось для кожного.
Шлях Rust був шляхом співпраці, навчання й ітерації. Зростання мови та її екосистеми є прямим відображенням живої й різноманітної спільноти, що стоїть за нею. Внесок тисяч розробників, від основних проєктувальників мови до епізодичних дописувачів, — ось що робить Rust таким унікальним і потужним інструментом. Беручи до рук цю книгу, ви не просто вивчаєте нову мову програмування — ви приєднуєтеся до руху за те, щоб зробити програмне забезпечення кращим, безпечнішим і приємнішим у роботі.
Ласкаво просимо до спільноти Rust!
- Bec Rumbul, виконавча директорка Rust Foundation
Вступ
Примітка: Це видання книги збігається з The Rust Programming Language, доступним у друкованому та електронному форматі від No Starch Press.
Ласкаво просимо до Мови програмування Rust — вступної книги про Rust. Мова програмування Rust допомагає писати швидше та надійніше програмне забезпечення. Висока ергономіка та низькорівневий контроль часто суперечать одне одному в дизайні мов програмування; Rust кидає виклик цьому протиріччю. Балансуючи між потужними технічними можливостями та чудовим досвідом розробника, Rust дає вам можливість контролювати низькорівневі деталі (наприклад, використання пам’яті) без усіх труднощів, традиційно пов’язаних з таким контролем.
Для кого призначений Rust
Rust ідеально підходить для багатьох людей з різних причин. Розглянемо кілька найважливіших груп.
Команди розробників
Rust виявляється продуктивним інструментом для співпраці у великих командах розробників з різним рівнем знань системного програмування. Низькорівневий код схильний до різних тонких помилок, які в більшості інших мов можна виявити лише через ретельне тестування та уважний перегляд коду досвідченими розробниками. У Rust компілятор відіграє роль контролера доступу (або воротаря), відмовляючись компілювати код з такими важко вловимими помилками, включаючи помилки конкурентності (concurrency). Працюючи разом з компілятором, команда може витрачати час на логіку програми, а не на пошук помилок.
Rust також привносить сучасні інструменти розробника у світ системного програмування:
- Cargo, вбудований менеджер залежностей та інструмент збірки, робить додавання, компіляцію та управління залежностями безболісним та узгодженим у всій екосистемі Rust.
- Rustfmt забезпечує узгоджений стиль кодування серед розробників.
- rust-analyzer забезпечує інтеграцію з IDE для автодоповнення коду та вбудованих повідомлень про помилки.
Використовуючи ці та інші інструменти в екосистемі Rust, розробники можуть бути продуктивними під час написання системного коду.
Студенти
Rust призначений для студентів та тих, хто зацікавлений у вивченні системних концепцій. Використовуючи Rust, багато людей дізналися про такі теми, як розробка операційних систем. Спільнота дуже привітна та рада відповідати на запитання студентів. Завдяки таким зусиллям, як ця книга, команди Rust хочуть зробити системні концепції більш доступними для більшої кількості людей, особливо для тих, хто тільки починає програмувати.
Компанії
Сотні компаній, великих і малих, використовують Rust у виробництві для різних завдань, включаючи інструменти командного рядка, веб-сервіси, інструменти DevOps, вбудовані пристрої, аналіз та транскодування аудіо та відео, криптовалюти, біоінформатику, пошукові системи, застосунки Інтернету речей, машинне навчання та навіть основні частини браузера Firefox.
Розробники відкритого програмного забезпечення
Rust призначений для людей, які хочуть будувати мову програмування Rust, спільноту, інструменти розробника та бібліотеки. Ми були б раді вашому внеску в мову Rust.
Люди, яким важлива швидкість та стабільність
Rust призначений для людей, які прагнуть швидкості та стабільності в мові. Під швидкістю ми маємо на увазі як швидкість програм, які ви можете створювати за допомогою Rust, так і швидкість, з якою Rust дозволяє вам їх писати. Перевірки компілятора Rust забезпечують стабільність через додавання функцій та рефакторинг. Це на відміну від крихкого застарілого коду в мовах без цих перевірок, який розробники часто бояться змінювати. Прагнучи до абстракцій з нульовою вартістю — функцій вищого рівня, які компілюються в код так само швидко, як і написаний вручну низькорівневий код, — Rust намагається зробити безпечний код також швидким кодом.
Мова Rust сподівається підтримати і багатьох інших користувачів; ті, що згадані тут, є лише деякими з найбільших зацікавлених сторін. Загалом, найбільша амбіція Rust — усунути компроміси, які програмісти приймали десятиліттями, забезпечуючи безпеку та продуктивність, швидкість та ергономіку. Спробуйте Rust і подивіться, чи підходять вам його варіанти.
Для кого призначена ця книга
Ця книга передбачає, що ви вже писали код іншою мовою програмування, але не робить жодних припущень про те, якою саме. Ми намагалися зробити матеріал широко доступним для людей з різним програмістським досвідом. Ми не витрачаємо багато часу на розмови про те, що таке програмування або як про нього думати. Якщо ви зовсім новачок у програмуванні, вам краще прочитати книгу, яка спеціально знайомить з програмуванням.
Як користуватися цією книгою
Загалом, ця книга передбачає, що ви читаєте її послідовно від початку до кінця. Пізніші розділи спираються на концепції з попередніх розділів, а попередні розділи можуть не заглиблюватися в деталі певної теми, повертаючись до неї в пізнішому розділі.
У цій книзі ви знайдете два типи розділів: концептуальні розділи та проєктні розділи. У концептуальних розділах ви дізнаєтеся про аспект Rust. У проєктних розділах ми будуємо невеликі програми разом, застосовуючи те, що ви дізналися до цього часу. Розділи 2, 12 та 21 є проєктними розділами; решта — концептуальні.
Розділ 1 пояснює, як встановити Rust, як написати програму “Привіт, Світ!” та як використовувати Cargo, менеджер пакетів та інструмент збірки Rust. Розділ 2 є практичним вступом до написання програми на Rust, де ви будуєте гру в вгадування числа. Тут ми охоплюємо концепції на високому рівні, а пізніші розділи надають додаткові деталі. Якщо ви хочете одразу забруднити руки, Розділ 2 — це місце для цього. Розділ 3 охоплює функції Rust, схожі на функції інших мов програмування, а в Розділі 4 ви дізнаєтеся про систему володіння (ownership) Rust. Якщо ви особливо прискіпливий учень, який воліє вивчити кожну деталь перед тим, як рухатися далі, ви можете пропустити Розділ 2 і перейти безпосередньо до Розділу 3, повернувшись до Розділу 2, коли захочете попрацювати над проєктом, застосовуючи деталі, які ви вивчили.
Розділ 5 обговорює структури (structs) та методи (methods), а Розділ 6 охоплює переліки (enums), вирази
match та конструкцію потоку управління if let. Ви будете використовувати
структури та переліки для створення власних типів у Rust.
У Розділі 7 ви дізнаєтеся про систему модулів (modules) Rust та про правила приватності для організації вашого коду та його публічного інтерфейсу прикладного програмування (API). Розділ 8 обговорює деякі загальні структури даних колекцій, які надає стандартна бібліотека, такі як вектори (vectors), рядки (strings) та хеш-таблиці (hash maps). Розділ 9 досліджує філософію та техніки обробки помилок (error handling) Rust.
Розділ 10 заглиблюється в узагальнені типи (generics), трейти (traits) та часи життя (lifetimes), які дають вам
можливість визначати код, що застосовується до кількох типів. Розділ 11 повністю
присвячений тестуванню, яке навіть з гарантіями безпеки Rust необхідне для
забезпечення правильної логіки вашої програми. У Розділі 12 ми будуємо власну
реалізацію підмножини функціональності з інструменту командного рядка grep,
який шукає текст у файлах. Для цього ми використаємо багато концепцій, які
обговорювали в попередніх розділах.
Розділ 13 досліджує замикання (closures) та ітератори (iterators): функції Rust, що надходять з функціональних мов програмування. У Розділі 14 ми детальніше розглянемо Cargo та поговоримо про найкращі практики обміну вашими бібліотеками з іншими. Розділ 15 обговорює розумні вказівники (smart pointers), які надає стандартна бібліотека, та трейти, що забезпечують їх функціональність.
У Розділі 16 ми розглянемо різні моделі конкурентного програмування та поговоримо про те, як Rust допомагає вам програмувати в кількох потоках (threads) конкурентність без страху (fearless concurrency). Розділ 17 розширює це, розглядаючи синтаксис async/await та легку модель конкурентності, яку він підтримує.
Розділ 18 розглядає, як ідіоми Rust порівнюються з принципами об’єктно-орієнтованого програмування, з якими ви можете бути знайомі. Розділ 19 є довідником по шаблонах та зіставленню зі зразком (pattern matching), які є потужними способами вираження ідей у програмах на Rust. Розділ 20 містить різноманітні цікаві розширені теми, включаючи небезпечний Rust, макроси та більше про часи життя, трейти, типи, функції та замикання.
У Розділі 21 ми завершимо проєкт, в якому реалізуємо низькорівневий багатопотоковий веб-сервер!
Нарешті, деякі додатки містять корисну інформацію про мову у форматі довідника. Додаток А охоплює ключові слова Rust, Додаток Б охоплює оператори та символи Rust, Додаток В охоплює похідні трейти, що надаються стандартною бібліотекою Rust, Додаток Г охоплює деякі корисні інструменти розробки, а Додаток Д пояснює видання Rust. У Додатку Е ви можете знайти переклади книги, а в Додатку Є — деталі про те, як створюється Rust та що таке нічний Rust.
Немає неправильного способу читати цю книгу: якщо ви хочете пропустити вперед, дерзайте! Можливо, вам доведеться повернутися до попередніх розділів, якщо відчуєте плутанину. Але робіть те, що вам підходить.
Важливою частиною процесу вивчення Rust є навчання читати повідомлення про помилки, які відображає компілятор: вони направлять вас до робочого коду. Тому ми наведемо багато прикладів, які не компілюються, разом з повідомленням про помилку, яке компілятор покаже вам у кожній ситуації. Знайте, що якщо ви введете та запустите випадковий приклад, він може не скомпілюватися! Переконайтеся, що ви прочитали навколишній текст, щоб побачити, чи призначений приклад, який ви намагаєтеся запустити, для помилки. Ferris також допоможе вам розрізнити код, який не призначений для роботи:
| Ferris | Значення |
|---|---|
 | Цей код не компілюється! |
 | Цей код панікує! |
 | Цей код не виробляє бажаної поведінки. |
У більшості ситуацій ми направимо вас до правильної версії будь-якого коду, який не компілюється.
Вихідний код
Вихідні файли, з яких генерується ця книга, можна знайти на GitHub.
Початок роботи
Почнімо вашу подорож Rust! Є багато чого вивчити, але кожна подорож починається десь. У цьому розділі ми обговоримо:
- Встановлення Rust у Linux, macOS і Windows
- Написання програми, яка друкує
Hello, world! - Використання
cargo, менеджера пакетів і системи збирання Rust
Встановлення
Встановлення (Installation)
Перший крок — встановити Rust. Ми завантажимо Rust через rustup, інструмент командного рядка для керування версіями Rust і пов’язаними інструментами. Для завантаження вам знадобиться підключення до інтернету.
Примітка: якщо з якоїсь причини ви не хочете використовувати
rustup, дивіться сторінку Other Rust Installation Methods для інших варіантів.
Наступні кроки встановлюють останню стабільну версію компілятора Rust. Гарантії стабільності Rust забезпечують, що всі приклади в книзі, які компілюються, і надалі компілюватимуться з новішими версіями Rust. Вивід може трохи відрізнятися між версіями, тому що Rust часто покращує повідомлення про помилки й попередження. Іншими словами, будь-яка новіша стабільна версія Rust, яку ви встановите за допомогою цих кроків, має працювати як очікується з вмістом цієї книги.
Позначення командного рядка
У цьому розділі та впродовж усієї книги ми показуватимемо деякі команди, які використовуються в терміналі. Рядки, які ви маєте вводити в терміналі, усі починаються з
$. Вам не потрібно вводити символ$; це запрошення командного рядка, яке показує початок кожної команди. Рядки, що не починаються з$, зазвичай показують вивід попередньої команди. Крім того, приклади, специфічні для PowerShell, використовуватимуть>замість$.
Встановлення rustup на Linux або macOS
Якщо ви використовуєте Linux або macOS, відкрийте термінал і введіть таку команду:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
Команда завантажує скрипт і запускає встановлення інструмента rustup, який встановлює останню стабільну версію Rust. Вас можуть попросити ввести пароль. Якщо встановлення успішне, з’явиться такий рядок:
Rust is installed now. Great!
Вам також знадобиться лінкер (linker), тобто програма, яку Rust використовує, щоб об’єднати свої скомпільовані результати в один файл. Імовірно, у вас уже є такий. Якщо ви отримаєте помилки лінкера, вам слід встановити компілятор C, який зазвичай міститиме лінкер. Компілятор C також корисний, тому що деякі поширені пакети Rust залежать від коду C і потребуватимуть компілятора C.
На macOS ви можете отримати компілятор C, запустивши:
$ xcode-select --install
Користувачам Linux зазвичай слід встановити GCC або Clang відповідно до документації їхнього дистрибутива. Наприклад, якщо ви використовуєте Ubuntu, ви можете встановити пакет build-essential.
Встановлення rustup на Windows
На Windows перейдіть на https://www.rust-lang.org/tools/install і дотримуйтеся інструкцій для встановлення Rust. На певному етапі встановлення вам запропонують встановити Visual Studio. Це надає лінкер (linker) і рідні бібліотеки, потрібні для компіляції програм. Якщо вам потрібна додаткова допомога з цим кроком, дивіться https://rust-lang.github.io/rustup/installation/windows-msvc.html.
У решті цієї книги використовуються команди, які працюють і в cmd.exe, і в PowerShell. Якщо існують специфічні відмінності, ми пояснимо, що саме використовувати.
Усунення неполадок
Щоб перевірити, чи правильно встановлено Rust, відкрийте shell і введіть цей рядок:
$ rustc --version
Ви маєте побачити номер версії, hash коміту та дату коміту для останньої стабільної версії, яка була випущена, у такому форматі:
rustc x.y.z (abcabcabc yyyy-mm-dd)
Якщо ви бачите цю інформацію, Rust успішно встановлено! Якщо ви не
бачите цю інформацію, перевірте, чи є Rust у вашій системній змінній %PATH%
таким чином.
У Windows CMD використовуйте:
> echo %PATH%
У PowerShell використовуйте:
> echo $env:Path
У Linux і macOS використовуйте:
$ echo $PATH
Якщо все це правильно, а Rust усе ще не працює, є кілька місць, де ви можете отримати допомогу. Дізнайтеся, як зв’язатися з іншими растацеанцями (Rustaceans), на сторінці спільноти.
Оновлення та видалення
Після того як Rust встановлено через rustup, оновити його до нової випущеної версії
легко. У вашому shell виконайте такий скрипт оновлення:
$ rustup update
Щоб видалити Rust і rustup, виконайте такий скрипт видалення у вашому shell:
$ rustup self uninstall
Читання локальної документації
Встановлення Rust також включає локальну копію документації, щоб
ви могли читати її офлайн. Запустіть rustup doc, щоб відкрити локальну документацію
у вашому браузері.
У будь-який момент, коли тип або функція надаються стандартною бібліотекою, і ви не впевнені, що вони роблять або як їх використовувати, скористайтеся документацією інтерфейсу прикладного програмування (API), щоб з’ясувати це!
Використання текстових редакторів та IDE
Ця книга не робить жодних припущень щодо того, які інструменти ви використовуєте для написання коду Rust. Підійде майже будь-який текстовий редактор! Однак багато текстових редакторів і інтегрованих середовищ розробки (IDE (скорочено від англ. integrated development environment)) мають вбудовану підтримку Rust. Ви завжди можете знайти доволі актуальний список багатьох редакторів та IDE на сторінці інструментів на вебсайті Rust.
Робота з цією книгою офлайн
У кількох прикладах ми будемо використовувати пакети Rust поза стандартною бібліотекою. Щоб
пройти ці приклади, вам або потрібно мати підключення до інтернету,
або заздалегідь завантажити ці залежності. Щоб завантажити
залежності заздалегідь, ви можете виконати такі команди. (Ми детально пояснимо,
що таке cargo і що робить кожна з цих команд, пізніше.)
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add rand@0.8.5 trpl@0.2.0
Це закешує завантаження для цих пакетів, тож вам не потрібно буде
завантажувати їх пізніше. Після того як ви виконаєте цю команду, вам не потрібно зберігати
папку get-dependencies. Якщо ви виконали цю команду, ви можете використовувати
прапорець --offline з усіма командами cargo в решті книги, щоб використовувати
ці кешовані версії замість спроби звернення до мережі.
Привіт, світ!
Привіт, світ! (Hello, World!)
Тепер, коли ви встановили Rust, настав час написати вашу першу програму на Rust.
Коли вивчають нову мову, традиційно пишуть невелику програму, яка виводить текст Hello, world! на екран, тож ми зробимо те саме тут!
Примітка: Ця книга припускає базове знайомство з командним рядком. Rust не висуває жодних спеціальних вимог до вашого редагування, інструментів або місця, де знаходиться ваш код, тож якщо ви віддаєте перевагу використанню IDE замість командного рядка, сміливо користуйтеся вашою улюбленою IDE. Багато IDE тепер мають певний рівень підтримки Rust; дивіться документацію IDE для деталей. Команда Rust зосередилася на забезпеченні чудової підтримки IDE через
rust-analyzer. Див. Додаток D для отримання додаткових відомостей.
Налаштування каталогу проєкту
Спочатку ви створите каталог для зберігання вашого коду Rust. Rustу не має значення, де знаходиться ваш код, але для вправ і проєктів у цій книзі ми пропонуємо створити каталог projects у вашому домашньому каталозі й зберігати там усі ваші проєкти.
Відкрийте термінал і введіть такі команди, щоб створити каталог projects і каталог для проєкту “Hello, world!” всередині каталогу projects.
Для Linux, macOS і PowerShell у Windows введіть таке:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
Для Windows CMD введіть таке:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
Основи програми на Rust
Далі створіть новий файл вихідного коду й назвіть його main.rs. Файли Rust завжди закінчуються розширенням .rs. Якщо у назві файла ви використовуєте більше одного слова, прийнято розділяти їх за допомогою підкреслення. Наприклад, використовуйте hello_world.rs, а не helloworld.rs.
Тепер відкрийте файл main.rs, який ви щойно створили, і введіть код із Лістинга (Listing) 1-1.
fn main() {
println!("Hello, world!");
}Збережіть файл і поверніться до вікна термінала в каталозі ~/projects/hello_world. У Linux або macOS введіть такі команди, щоб скомпілювати й запустити файл:
$ rustc main.rs
$ ./main
Hello, world!
У Windows введіть команду .\main замість ./main:
> rustc main.rs
> .\main
Hello, world!
Незалежно від вашої операційної системи, рядок Hello, world! має надрукуватися в
терміналі. Якщо ви не бачите цього виводу, поверніться до частини
“Troubleshooting” розділу Встановлення (Installation), щоб дізнатися
способи отримати допомогу.
Якщо Hello, world! дійсно надрукувалося, вітаємо! Ви офіційно написали програму на Rust.
Це робить вас програмістом Rust — ласкаво просимо!
Анатомія програми на Rust
Давайте детально розглянемо цю програму “Hello, world!”. Ось перша частина головоломки:
fn main() {
}Ці рядки визначають функцію з назвою main. Функція main особлива: вона
завжди є першим кодом, який виконується в кожній виконуваній програмі Rust. Тут
перший рядок оголошує функцію з назвою main, яка не має параметрів і нічого
не повертає. Якби були параметри, вони були б усередині круглих дужок (()).
Тіло функції загорнуте в {}. Rust вимагає фігурні дужки навколо всіх тіл
функцій. Гарним стилем є розміщення відкривальної фігурної дужки в тому самому
рядку, що й оголошення функції, з одним пробілом між ними.
Примітка: Якщо ви хочете дотримуватися стандартного стилю в усіх проєктах Rust, ви можете використовувати інструмент автоматичного форматування під назвою
rustfmt, щоб форматувати ваш код у певному стилі (проrustfmtдокладніше в Додатку D). Команда Rust включила цей інструмент до стандартного дистрибутива Rust, так само як іrustc, тож він уже має бути встановлений на вашому комп’ютері!
Тіло функції main містить такий код:
#![allow(unused)]
fn main() {
println!("Hello, world!");
}Цей рядок робить усю роботу в цій невеликій програмі: він виводить текст на екран. Тут є три важливі деталі, на які слід звернути увагу.
По-перше, println! викликає макрос Rust. Якби він викликав функцію, це було б
записано як println (без !). Макроси Rust — це спосіб писати код, який
створює код для розширення синтаксису Rust, і ми обговоримо їх докладніше в
Розділі 20. Наразі вам достатньо знати, що використання !
означає, що ви викликаєте макрос замість звичайної функції, і що макроси не завжди
слідують тим самим правилам, що й функції.
По-друге, ви бачите рядок "Hello, world!". Ми передаємо цей рядок як аргумент
println!, і рядок виводиться на екран.
По-третє, ми закінчуємо рядок крапкою з комою (;), яка вказує, що цей
вираз завершено, і наступний готовий початися. Більшість рядків коду Rust
закінчуються крапкою з комою.
Компіляція та виконання
Ви щойно запустили нещодавно створену програму, тож давайте розглянемо кожен крок цього процесу.
Перед запуском програми Rust ви повинні скомпілювати її за допомогою компілятора Rust,
ввівши команду rustc і передавши їй ім’я вашого вихідного файла, ось так:
$ rustc main.rs
Якщо у вас є досвід роботи з C або C++, ви помітите, що це подібно до gcc
або clang. Після успішної компіляції Rust виводить двійковий виконуваний файл.
У Linux, macOS і PowerShell у Windows ви можете побачити виконуваний файл,
ввівши команду ls у вашій оболонці:
$ ls
main main.rs
У Linux і macOS ви побачите два файли. У PowerShell у Windows ви побачите ті самі три файли, які побачили б, використовуючи CMD. У CMD у Windows ви ввели б таке:
> dir /B %= the /B option says to only show the file names =%
main.exe
main.pdb
main.rs
Це показує файл вихідного коду з розширенням .rs, виконуваний файл (main.exe у Windows, але main на всіх інших платформах) і, під час використання Windows, файл, що містить відомості для налагодження, з розширенням .pdb. Після цього ви запускаєте файл main або main.exe ось так:
$ ./main # or .\main on Windows
Якщо ваш main.rs — це програма “Hello, world!”, цей рядок виводить Hello, world! у ваш термінал.
Якщо ви краще знайомі з динамічною мовою, такою як Ruby, Python або JavaScript, ви можете бути не звиклі до компіляції та запуску програми як окремих кроків. Rust — це мова попередньої компіляції (ahead-of-time compiled), що означає, що ви можете скомпілювати програму й передати виконуваний файл комусь іншому, і ця людина зможе запустити його навіть без встановленого Rust. Якщо ви дасте комусь файл .rb, .py або .js, їм потрібно буде мати встановлену реалізацію Ruby, Python або JavaScript (відповідно). Але в цих мовах вам потрібна лише одна команда, щоб скомпілювати й запустити вашу програму. У дизайні мов завжди є компроміс.
Проста компіляція за допомогою rustc цілком підходить для простих програм, але
коли ваш проєкт росте, вам захочеться керувати всіма параметрами й легко ділитися
вашим кодом. Далі ми познайомимо вас із інструментом Cargo, який допоможе вам
писати реальні програми на Rust.
Привіт, Cargo!
Привіт, Cargo! (Hello, Cargo!)
Cargo — це система збирання та менеджер пакетів Rust. Більшість растацеанців (Rustaceans) використовують цей інструмент для керування своїми проєктами Rust, тому що Cargo бере на себе багато завдань, таких як збирання вашого коду, завантаження бібліотек, від яких залежить ваш код, і збирання цих бібліотек. (Ми називаємо бібліотеки, які потрібні вашому коду, залежностями.)
Найпростіші програми Rust, як та, яку ми написали досі, не мають жодних залежностей. Якби ми зібрали проєкт “Hello, world!” за допомогою Cargo, він використовував би лише ту частину Cargo, яка відповідає за збирання вашого коду. У міру того як ви пишете складніші програми Rust, ви додаватимете залежності, і якщо ви почнете проєкт за допомогою Cargo, додавати залежності буде значно простіше.
Оскільки переважна більшість проєктів Rust використовує Cargo, решта цієї книги припускає, що ви теж використовуєте Cargo. Cargo встановлюється разом із Rust, якщо ви користувалися офіційними інсталяторами, про які йшлося в розділі “Встановлення (Installation)”. Якщо ви встановили Rust іншим способом, перевірте, чи встановлено Cargo, ввівши в терміналі таку команду:
$ cargo --version
Якщо ви бачите номер версії, він у вас є! Якщо ви бачите помилку, наприклад command not found, перегляньте документацію для вашого способу встановлення, щоб визначити, як встановити Cargo окремо.
Створення проєкту за допомогою Cargo
Давайте створимо новий проєкт за допомогою Cargo і подивимося, чим він відрізняється від нашого початкового проєкту “Hello, world!”. Поверніться до вашого каталогу projects (або до того місця, де ви вирішили зберігати свій код). Потім, на будь-якій операційній системі, виконайте таке:
$ cargo new hello_cargo
$ cd hello_cargo
Перша команда створює новий каталог і проєкт під назвою hello_cargo. Ми назвали наш проєкт hello_cargo, і Cargo створює його файли в каталозі з тією самою назвою.
Перейдіть до каталогу hello_cargo і виведіть список файлів. Ви побачите, що Cargo згенерував для нас два файли й один каталог: файл Cargo.toml і каталог src з файлом main.rs всередині.
Він також ініціалізував новий репозиторій Git разом із файлом .gitignore. Файли Git не будуть згенеровані, якщо ви запускаєте cargo new всередині наявного репозиторію Git; ви можете перевизначити цю поведінку, використавши cargo new --vcs=git.
Примітка: Git — поширена система керування версіями. Ви можете змінити
cargo new, щоб використовувати іншу систему керування версіями або взагалі не використовувати її, за допомогою прапорця--vcs. Запустітьcargo new --help, щоб побачити доступні варіанти.
Відкрийте Cargo.toml у текстовому редакторі на ваш вибір. Він має виглядати подібно до коду в Лістингу (Listing) 1-2.
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
Цей файл має формат TOML (Tom’s Obvious, Minimal Language), який є форматом конфігурації Cargo.
Перший рядок, [package], є заголовком розділу, що вказує, що наступні оператори налаштовують пакет. У міру того як ми додаватимемо більше інформації до цього файлу, ми додаватимемо й інші розділи.
Наступні три рядки задають інформацію конфігурації, яка потрібна Cargo для компіляції вашої програми: назву, версію та редакцію (edition) Rust, яку слід використовувати. Про ключ edition ми поговоримо в Додатку E.
Останній рядок, [dependencies], — це початок розділу, у якому ви можете перелічити будь-які залежності вашого проєкту. У Rust пакети коду називають крейтами (crates). Для цього проєкту нам не знадобляться інші крейти, але вони знадобляться в першому проєкті в Розділі 2, тож тоді ми використаємо цей розділ dependencies.
Тепер відкрийте src/main.rs і погляньте:
Ім’я файлу: src/main.rs
fn main() {
println!("Hello, world!");
}Cargo згенерував для вас програму “Hello, world!”, так само як ту, яку ми написали в Лістингу (Listing) 1-1! Поки що відмінності між нашим проєктом і проєктом, згенерованим Cargo, полягають у тому, що Cargo розмістив код у каталозі src, а в нас є файл конфігурації Cargo.toml у верхньому каталозі.
Cargo очікує, що ваші вихідні файли будуть розміщені всередині каталогу src. Каталог проєкту верхнього рівня призначений лише для файлів README, інформації про ліцензію, конфігураційних файлів і всього іншого, що не пов’язано з вашим кодом. Використання Cargo допомагає вам упорядковувати ваші проєкти. Для всього є своє місце, і все перебуває на своєму місці.
Якщо ви почали проєкт, який не використовує Cargo, як ми зробили з проєктом “Hello, world!”, ви можете перетворити його на проєкт, який використовує Cargo. Перемістіть код проєкту в каталог src і створіть відповідний файл Cargo.toml. Один простий спосіб отримати цей файл Cargo.toml — запустити cargo init, який створить його для вас автоматично.
Збирання та запуск проєкту Cargo
Тепер давайте подивимося, що змінюється, коли ми збираємо та запускаємо програму “Hello, world!” за допомогою Cargo! У вашому каталозі hello_cargo зберіть проєкт, ввівши таку команду:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
Ця команда створює виконуваний файл у target/debug/hello_cargo (або target\debug\hello_cargo.exe на Windows), а не у вашому поточному каталозі. Оскільки стандартне збирання — це debug-збирання, Cargo поміщає бінарний файл у каталог із назвою debug. Ви можете запустити виконуваний файл цією командою:
$ ./target/debug/hello_cargo # or .\target\debug\hello_cargo.exe on Windows
Hello, world!
Якщо все піде добре, Hello, world! має вивестися в термінал. Перший запуск cargo build також змушує Cargo створити новий файл на верхньому рівні: Cargo.lock. Цей файл відстежує точні версії залежностей у вашому проєкті. У цього проєкту немає залежностей, тож файл трохи порожній. Вам ніколи не потрібно буде змінювати цей файл вручну; Cargo керує його вмістом за вас.
Ми щойно зібрали проєкт за допомогою cargo build і запустили його за допомогою ./target/debug/hello_cargo, але ми також можемо використовувати cargo run, щоб скомпілювати код, а потім запустити отриманий виконуваний файл — усе в одній команді:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
Використовувати cargo run зручніше, ніж пам’ятати про необхідність спочатку запускати cargo build, а потім вказувати повний шлях до бінарного файлу, тому більшість розробників використовують cargo run.
Зверніть увагу, що цього разу ми не побачили виводу, який вказував би, що Cargo компілює hello_cargo. Cargo зрозумів, що файли не змінилися, тому він не перебудовував їх, а лише запустив бінарний файл. Якби ви змінили свій вихідний код, Cargo перебудував би проєкт перед запуском, і ви побачили б такий вивід:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo також надає команду під назвою cargo check. Ця команда швидко перевіряє ваш код, щоб переконатися, що він компілюється, але не створює виконуваний файл:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
Чому вам може не хотітися виконуваного файлу? Часто cargo check набагато швидший за cargo build, тому що він пропускає крок створення виконуваного файлу. Якщо ви постійно перевіряєте свою роботу під час написання коду, використання cargo check пришвидшить процес повідомлення вам про те, чи ваш проєкт і далі компілюється! Тому багато растацеанців (Rustaceans) періодично запускають cargo check у міру написання своєї програми, щоб переконатися, що вона компілюється. Потім вони запускають cargo build, коли готові використовувати виконуваний файл.
Давайте підсумуємо, що ми вже дізналися про Cargo:
- Ми можемо створювати проєкт за допомогою
cargo new. - Ми можемо збирати проєкт за допомогою
cargo build. - Ми можемо збирати та запускати проєкт за один крок за допомогою
cargo run. - Ми можемо збирати проєкт без створення бінарного файла, щоб перевірити наявність помилок, за допомогою
cargo check. - Замість того щоб зберігати результат збирання в тому самому каталозі, що й наш код, Cargo зберігає його в каталозі target/debug.
Додатковою перевагою використання Cargo є те, що команди однакові незалежно від того, в якій операційній системі ви працюєте. Тож на цьому етапі ми більше не наводитимемо окремих інструкцій для Linux і macOS проти Windows.
Збирання для випуску
Коли ваш проєкт нарешті готовий до випуску, ви можете використати cargo build --release, щоб скомпілювати його з оптимізаціями. Ця команда створить виконуваний файл у target/release замість target/debug. Оптимізації змушують ваш код Rust працювати швидше, але їх увімкнення збільшує час, потрібний для компіляції вашої програми. Саме тому існують два різні профілі: один для розробки, коли ви хочете швидко і часто перебудовувати, і інший для збирання фінальної програми, яку ви передасте користувачу, яку не буде потрібно перебудовувати багато разів і яка працюватиме максимально швидко. Якщо ви вимірюєте час виконання вашого коду, обов’язково запускайте cargo build --release і виконуйте вимірювання з виконуваним файлом у target/release.
Використання конвенцій Cargo
Для простих проєктів Cargo не дає багато переваг порівняно з просто використанням rustc, але він доведе свою цінність у міру того, як ваші програми ставатимуть складнішими. Щойно програми зростають до кількох файлів або потребують залежності, значно простіше дозволити Cargo координувати збирання.
Хоча проєкт hello_cargo простий, він уже використовує багато реальних інструментів, які ви використовуватимете протягом решти своєї кар’єри в Rust. Насправді, щоб працювати з будь-якими наявними проєктами, ви можете використовувати такі команди, щоб отримати код за допомогою Git, перейти до каталогу цього проєкту та зібрати його:
$ git clone example.org/someproject
$ cd someproject
$ cargo build
Більше інформації про Cargo дивіться в його документації.
Підсумок
Ви вже чудово почали свою подорож Rust! У цьому розділі ви дізналися, як:
- Встановити найновішу стабільну версію Rust за допомогою
rustup. - Оновитися до новішої версії Rust.
- Відкрити локально встановлену документацію.
- Написати та запустити програму “Hello, world!” безпосередньо за допомогою
rustc. - Створити та запустити новий проєкт, використовуючи конвенції Cargo.
Це чудовий момент, щоб створити більш змістовну програму й звикнути читати та писати код Rust. Тож у Розділі 2 ми створимо програму гри в вгадування. Якщо ви волієте спочатку дізнатися, як працюють поширені концепції програмування в Rust, дивіться Розділ 3, а потім повертайтеся до Розділу 2.
Програмування гри у вгадування (Programming a Guessing Game)
Давайте зануримося в Rust, разом виконавши практичний проєкт! Цей
розділ знайомить вас із кількома поширеними концепціями Rust, показуючи, як
використовувати їх у реальній програмі. Ви дізнаєтеся про let, match, методи (methods), асоційовані
функції (associated functions), зовнішні крейти (external crates) та багато іншого! У наступних розділах ми розглянемо
ці ідеї детальніше. У цьому розділі ви просто потренуєте
основи.
Ми реалізуємо класичну програму для початківців: гру у вгадування. Ось як вона працює: програма згенерує випадкове ціле число від 1 до 100. Потім вона запропонує гравцеві ввести припущення. Після введення припущення програма повідомить, чи є припущення надто малим або надто великим. Якщо припущення є правильним, гра надрукує вітальне повідомлення та завершиться.
Налаштування нового проєкту (Setting Up a New Project)
Щоб налаштувати новий проєкт, перейдіть до каталогу projects, який ви створили в Розділі 1, і створіть новий проєкт за допомогою Cargo, ось так:
$ cargo new guessing_game
$ cd guessing_game
Перша команда, cargo new, бере назву проєкту (guessing_game)
як перший аргумент. Друга команда змінює каталог на каталог
нового проєкту.
Подивіться на згенерований файл Cargo.toml:
Filename: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
[dependencies]
Як ви бачили в Розділі 1, cargo new генерує для вас програму “Hello, world!”. Подивіться на файл src/main.rs:
Filename: src/main.rs
fn main() {
println!("Hello, world!");
}Тепер давайте скомпілюємо цю програму “Hello, world!” і запустимо її на тому ж кроці,
використовуючи команду cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/guessing_game`
Hello, world!
Команда run дуже корисна, коли вам потрібно швидко ітерувати над проєктом,
як ми й робитимемо в цій грі, швидко тестуючи кожну ітерацію перед переходом до
наступної.
Знову відкрийте файл src/main.rs. Ви писатимете весь код у цьому файлі.
Обробка припущення (Processing a Guess)
Перша частина програми гри у вгадування попросить у користувача введення, обробить це введення та перевірить, що введення має очікувану форму. Для початку ми дозволимо гравцеві ввести припущення. Введіть код із Лістинга (Listing) 2-1 у src/main.rs.
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Цей код містить багато інформації, тож розглянемо його рядок за рядком. Щоб
отримати введення користувача, а потім надрукувати результат як виведення, нам потрібно
внести бібліотеку введення/виведення io в область видимості. Бібліотека io
походить зі стандартної бібліотеки, відомої як std:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}За замовчуванням Rust має набір елементів, визначених у стандартній бібліотеці, які він вносить в область видимості кожної програми. Цей набір називається prelude, і ви можете побачити все в ньому в документації стандартної бібліотеки.
Якщо тип, який ви хочете використовувати, не входить до prelude, вам потрібно внести цей тип
в область видимості явно за допомогою оператора use. Використання бібліотеки std::io
надає вам низку корисних можливостей, зокрема здатність приймати
введення користувача.
Як ви бачили в Розділі 1, функція main є точкою входу в
програму:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Синтаксис fn оголошує нову функцію; дужки () вказують, що
немає параметрів; а фігурна дужка { починає тіло функції.
Як ви також дізналися в Розділі 1, println! — це макрос, який друкує рядок на
екран:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Цей код друкує підказку, яка повідомляє, що це за гра, і запитує введення від користувача.
Зберігання значень у змінних (Storing Values with Variables)
Далі ми створимо змінну для зберігання введення користувача, ось так:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Тепер програма стає цікавішою! У цьому маленькому рядку відбувається багато
чого. Ми використовуємо оператор let, щоб створити змінну. Ось ще один приклад:
let apples = 5;Цей рядок створює нову змінну з іменем apples і зв’язує її зі значенням 5.
У Rust змінні за замовчуванням є незмінними (immutable), тобто після того, як ми надаємо змінній
значення, це значення не змінюватиметься. Ми детально обговоримо цю концепцію в
розділі “Змінні та змінність (Variables and Mutability)”
Розділу 3. Щоб зробити змінну змінною, ми додаємо mut перед
іменем змінної:
let apples = 5; // immutable
let mut bananas = 5; // mutableПримітка: Синтаксис
//починає коментар, який триває до кінця рядка. Rust ігнорує все в коментарях. Ми детальніше обговоримо коментарі в Розділі 3.
Повертаючись до програми гри у вгадування, ви тепер знаєте, що let mut guess введе
змінну guess, яка є змінною. Знак рівності (=) каже Rust, що ми
хочемо щось прив’язати до змінної зараз. Праворуч від знака рівності знаходиться
значення, до якого прив’язується guess, а саме результат виклику
String::new, функції, яка повертає новий екземпляр String.
String — це тип рядка, який надається стандартною
бібліотекою та є текстом змінної довжини, закодованим у UTF-8.
Синтаксис :: у рядку ::new вказує, що new є асоційованою
функцією типу String. Асоційована функція — це функція, яка реалізована для типу, у
цьому випадку String. Ця функція new створює новий, порожній рядок. Ви
знайдете функцію new у багатьох типах, тому що це поширена назва для функції, яка
створює нове значення певного виду.
У повному вигляді рядок let mut guess = String::new(); створив
змінну, яка наразі прив’язана до нового, порожнього екземпляра String. Ух!
Отримання введення від користувача (Receiving User Input)
Згадайте, що ми включили функціональність введення/виведення зі стандартної
бібліотеки за допомогою use std::io; у першому рядку програми. Тепер ми викличемо
функцію stdin із модуля io, що дозволить нам обробляти введення
користувача:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Якби ми не імпортували модуль io за допомогою use std::io; на початку
програми, ми все одно могли б використати цю функцію, записавши цей виклик функції як
std::io::stdin. Функція stdin повертає екземпляр
std::io::Stdin, який є типом, що представляє
дескриптор стандартного введення вашого термінала.
Далі рядок .read_line(&mut guess) викликає метод read_line на дескрипторі стандартного введення, щоб отримати введення від користувача.
Ми також передаємо &mut guess як аргумент до read_line, щоб сказати йому, у який
рядок зберігати введення користувача. Повне завдання read_line — взяти
все, що користувач вводить у стандартне введення, і додати це до рядка
(не перезаписуючи його вміст), тож ми відповідно передаємо цей рядок як
аргумент. Аргумент рядка має бути змінним, щоб метод міг змінити
вміст рядка.
Символ & вказує, що цей аргумент є посиланням, яке дає вам спосіб
дозволити кільком частинам вашого коду отримувати доступ до одного фрагмента даних без
потрібності копіювати ці дані в пам’ять багато разів. Посилання — це складна можливість,
і однією з головних переваг Rust є те, наскільки безпечно та легко використовувати
посилання. Вам не потрібно знати багато з цих деталей, щоб завершити цю
програму. Наразі все, що вам потрібно знати, це те, що, як і змінні, посилання є
незмінними за замовчуванням. Отже, вам потрібно писати &mut guess замість
&guess, щоб зробити його змінним. (Розділ 4 пояснить посилання детальніше.)
Обробка можливої помилки за допомогою Result (Handling Potential Failure with the Result Type)
Ми все ще працюємо над цим рядком коду. Тепер ми обговорюємо третій рядок тексту, але зверніть увагу, що він усе ще є частиною одного логічного рядка коду. Наступна частина — це цей метод:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Ми могли б записати цей код так:
io::stdin().read_line(&mut guess).expect("Failed to read line");Однак один довгий рядок важко читати, тому краще його розбити. Часто доцільно
вставити новий рядок та інші пробіли, щоб допомогти розбити довгі
рядки, коли ви викликаєте метод із синтаксисом .method_name(). Тепер давайте
обговоримо, що робить цей рядок.
Як уже згадувалося раніше, read_line кладе все, що користувач вводить, у рядок,
який ми йому передаємо, але він також повертає значення Result. Result — це перелік (enum (скорочено від enumeration)), який часто називають переліком,
і це тип, який може перебувати в одному з кількох можливих станів. Кожен
можливий стан ми називаємо варіантом.
Розділ 6 детальніше розгляне enum. Призначення
цих типів Result — кодувати інформацію про обробку помилок.
Варіанти Result — це Ok і Err. Варіант Ok вказує,
що операція була успішною, і містить успішно згенероване значення.
Варіант Err означає, що операція не вдалася, і містить інформацію
про те, як або чому операція не вдалася.
Значення типу Result, як і значення будь-якого типу, мають визначені для них методи. Екземпляр Result має expect method
який ви можете викликати. Якщо цей екземпляр Result є значенням Err, expect
призведе до аварійного завершення програми та покаже повідомлення, яке ви передали як
аргумент до expect. Якщо метод read_line повертає Err, це, ймовірно, буде
результатом помилки, що надходить від базової операційної системи.
Якщо цей екземпляр Result є значенням Ok, expect візьме значення, яке
містить Ok, і поверне вам лише це значення, щоб ви могли
його використати. У цьому випадку це значення — кількість байтів у введенні користувача.
Якщо ви не викличете expect, програма скомпілюється, але ви отримаєте попередження:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut guess);
| +++++++
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
Rust попереджає, що ви не використали значення Result, повернуте з read_line,
вказуючи, що програма не обробила можливу помилку.
Правильний спосіб прибрати попередження — це фактично написати код обробки помилок,
але у нашому випадку ми просто хочемо, щоб ця програма аварійно завершувалася, коли виникає проблема, тож ми
можемо використати expect. Ви дізнаєтеся про відновлення після помилок у Розділі
9.
Виведення значень з місцезаповнювачами println!
Окрім закривної фігурної дужки, залишився ще лише один рядок, який треба обговорити в коді на цей момент:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Цей рядок друкує рядок, який тепер містить введення користувача. Пара {} з
фігурних дужок — це місцезаповнювач: уявіть {} як маленькі клешні краба, які утримують
значення на місці. Під час друку значення змінної, ім’я змінної може
бути всередині фігурних дужок. Під час друку результату обчислення
виразу, поставте порожні фігурні дужки у форматний рядок, а потім допишіть
після форматного рядка список виразів, розділених комами, які потрібно надрукувати в кожному порожньому
місцезаповнювачі у тому самому порядку. Друк змінної та результату
виразу в одному виклику println! виглядав би так:
#![allow(unused)]
fn main() {
let x = 5;
let y = 10;
println!("x = {x} and y + 2 = {}", y + 2);
}Цей код надрукував би x = 5 and y + 2 = 12.
Тестування першої частини (Testing the First Part)
Давайте протестуємо першу частину гри у вгадування. Запустіть її за допомогою cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
На цьому етапі перша частина гри завершена: ми отримуємо введення з клавіатури, а потім друкуємо його.
Генерування секретного числа (Generating a Secret Number)
Далі нам потрібно згенерувати секретне число, яке користувач намагатиметься відгадати. Секретне число
має бути різним щоразу, щоб гра була цікавою більше ніж один раз. Ми використаємо випадкове число від 1
до 100, щоб гра не була надто складною. Rust ще не включає функціональність випадкових чисел у
свою стандартну бібліотеку. Однак команда Rust надає rand
crate із такою функціональністю.
Розширення функціональності за допомогою крейта (Using a Crate to Get More Functionality)
Пам’ятайте, що крейт — це колекція вихідних файлів Rust. Проєкт,
який ми будуємо, є бінарним крейтом, тобто виконуваним файлом. Крейт rand
— це бібліотечний крейт, який містить код, призначений для використання в інших
програмах і не може виконуватися самостійно.
Координація зовнішніх крейтів Cargo — це те, де Cargo справді показує себе з найкращого боку. Перш ніж
ми зможемо написати код, який використовує rand, нам потрібно змінити файл Cargo.toml, щоб
включити крейт rand як залежність. Відкрийте цей файл зараз і додайте
такий рядок у нижню частину, під заголовком розділу [dependencies], який
Cargo створив для вас. Переконайтеся, що ви вказали rand точно так, як тут, із
цим номером версії, інакше приклади коду в цьому підручнику можуть не працювати:
Filename: Cargo.toml
[dependencies]
rand = "0.8.5"
У файлі Cargo.toml все, що йде після заголовка, належить до цього
розділу, який триває, доки не починається інший розділ. У [dependencies] ви
кажете Cargo, від яких зовнішніх крейтів залежить ваш проєкт і які версії
цих крейтів вам потрібні. У цьому випадку ми вказуємо крейт rand за допомогою
специфікатора семантичного версіонування 0.8.5. Cargo розуміє Semantic
Versioning (іноді званий SemVer), який є
стандартом для запису номерів версій. Специфікатор 0.8.5 насправді є
скороченням для ^0.8.5, що означає будь-яку версію, яка є принаймні 0.8.5, але
нижче за 0.9.0.
Cargo вважає ці версії сумісними з публічними API версії 0.8.5, і цей запис гарантує, що ви отримаєте останній патч-реліз, який усе ще скомпілюється з кодом у цьому розділі. Будь-яка версія 0.9.0 або вища не гарантується як така, що має той самий API, який використовують наведені нижче приклади.
Тепер, не змінюючи жодного рядка коду, давайте зберемо проєкт, як показано в Лістингу (Listing) 2-2.
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
Ви можете побачити різні номери версій (але всі вони будуть сумісні з кодом, завдяки SemVer!) і різні рядки (залежно від операційної системи), а рядки можуть бути в іншому порядку.
Коли ми додаємо зовнішню залежність, Cargo отримує останні версії всього, що цій залежності потрібно, із registry, яка є копією даних з Crates.io. Crates.io — це місце, де люди в екосистемі Rust публікують свої проєкти з відкритим кодом на Rust, щоб інші могли ними користуватися.
Після оновлення registry Cargo перевіряє розділ [dependencies] і
завантажує будь-які перелічені крейти, які ще не завантажено. У цьому випадку,
хоча ми перелічили лише rand як залежність, Cargo також підтягнув інші крейти,
від яких rand залежить для роботи. Після завантаження крейтів Rust компілює
їх, а потім компілює проєкт із доступними залежностями.
Якщо ви одразу знову запустите cargo build без жодних змін, ви
не отримаєте жодного виведення, окрім рядка Finished. Cargo знає, що вже
завантажив і скомпілював залежності, і ви не змінили нічого
з них у файлі Cargo.toml. Cargo також знає, що ви не змінили
нічого у вашому коді, тож він і це не перекомпілює. Не маючи нічого
для виконання, він просто завершується.
Якщо ви відкриєте файл src/main.rs, внесете тривіальну зміну, а потім збережете його та зберете знову, ви побачите лише два рядки виведення:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Ці рядки показують, що Cargo оновлює збірку лише з вашою маленькою зміною у файлі src/main.rs. Ваші залежності не змінилися, тож Cargo знає, що може повторно використати те, що вже завантажив і скомпілював для них.
Забезпечення відтворюваних збірок (Ensuring Reproducible Builds with the Cargo.lock File)
У Cargo є механізм, який гарантує, що ви зможете перебудувати той самий артефакт щоразу,
коли ви або хтось інший збирає ваш код: Cargo використовуватиме лише
версії залежностей, які ви вказали, доки ви не вкажете інше. Наприклад, скажімо,
що наступного тижня виходить версія 0.8.6 крейта rand, і ця версія
містить важливе виправлення помилки, але також містить регресію, яка
зламає ваш код. Щоб вирішити це, Rust створює файл Cargo.lock під час першого
запуску cargo build, тож тепер у каталозі guessing_game ми маємо цей файл.
Коли ви вперше збираєте проєкт, Cargo визначає всі версії залежностей, що відповідають критеріям, а потім записує їх у файл Cargo.lock. Коли ви збираєте свій проєкт у майбутньому, Cargo побачить, що файл Cargo.lock існує, і використовуватиме вказані там версії замість того, щоб знову виконувати всю роботу з визначення версій. Це дає вам можливість автоматично мати відтворювану збірку. Іншими словами, ваш проєкт залишатиметься на 0.8.5, доки ви явно не оновите його, завдяки файлу Cargo.lock. Оскільки файл Cargo.lock важливий для відтворюваних збірок, його часто додають до системи керування вихідним кодом разом з рештою коду вашого проєкту.
Оновлення крейта, щоб отримати нову версію (Updating a Crate to Get a New Version)
Коли ви дійсно хочете оновити крейт, Cargo надає команду update,
яка ігноруватиме файл Cargo.lock і визначатиме всі останні версії,
що відповідають вашим специфікаціям у Cargo.toml. Потім Cargo запише ці
версії у файл Cargo.lock. В іншому випадку, за замовчуванням, Cargo шукатиме
лише версії більші за 0.8.5 і менші за 0.9.0. Якщо крейт rand випустив
дві нові версії 0.8.6 і 0.999.0, ви побачили б таке, якби
запустили cargo update:
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.999.0)
Cargo ігнорує реліз 0.999.0. На цьому етапі ви також помітили б
зміну у вашому файлі Cargo.lock, що вказує, що версія крейта rand,
яку ви тепер використовуєте, — 0.8.6. Щоб використовувати версію rand 0.999.0 або будь-яку версію в
серії 0.999.x, вам потрібно було б оновити файл Cargo.toml так, щоб він виглядав ось так
(не робіть цього насправді, тому що наведені нижче приклади припускають, що
ви використовуєте rand 0.8):
[dependencies]
rand = "0.999.0"
Наступного разу, коли ви запустите cargo build, Cargo оновить реєстр доступних
крейтів і повторно оцінить ваші вимоги до rand відповідно до нової версії,
яку ви вказали.
Є ще багато що сказати про Cargo та його екосистему, про що ми поговоримо в Розділі 14, але поки що це все, що вам потрібно знати. Cargo дуже полегшує повторне використання бібліотек, тож растацеанці (Rustaceans) можуть писати менші проєкти, які складаються з низки пакетів.
Генерування випадкового числа (Generating a Random Number)
Давайте почнемо використовувати rand, щоб згенерувати число для вгадування. Наступний крок —
оновити src/main.rs, як показано в Лістингу (Listing) 2-3.
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Спочатку ми додаємо рядок use rand::Rng;. Трейт Rng визначає методи, які
реалізують генератори випадкових чисел, і цей трейт має бути в області видимості, щоб ми
могли використовувати ці методи. Розділ 10 детально розгляне трейт.
Далі ми додаємо два рядки посередині. У першому рядку ми викликаємо
функцію rand::thread_rng, яка дає нам конкретний генератор випадкових чисел,
який ми використовуватимемо: той, що локальний для поточного потоку виконання і
ініціалізується операційною системою. Потім ми викликаємо метод gen_range
на генераторі випадкових чисел. Цей метод визначений трейтом Rng,
який ми внесли в область видимості за допомогою оператора use rand::Rng;. Метод
gen_range бере вираз діапазону як аргумент і генерує випадкове число в
цьому діапазоні. Тип виразу діапазону, який ми використовуємо тут, має
форму start..=end і є включним як для нижньої, так і для верхньої межі, тож нам
потрібно вказати 1..=100, щоб запросити число від 1 до 100.
Примітка: Ви не просто знатимете, які трейтів використовувати і які методи та функції викликати з крейта, тож кожен крейт має документацію з інструкціями щодо використання. Ще однією зручністю Cargo є те, що запуск команди
cargo doc --openзбудує документацію, надану всіма вашими залежностями, локально і відкриє її у вашому браузері. Якщо вам, наприклад, цікава інша функціональність у крейтіrand, запустітьcargo doc --openі клацнітьrandу бічній панелі ліворуч.
Другий новий рядок друкує секретне число. Це корисно під час розробки програми, щоб можна було її протестувати, але ми видалимо це у фінальній версії. Це не надто схоже на гру, якщо програма друкує відповідь, щойно вона запускається!
Спробуйте запустити програму кілька разів:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
Ви повинні отримати різні випадкові числа, і всі вони мають бути числами від 1 до 100. Чудова робота!
Порівняння припущення із секретним числом (Comparing the Guess to the Secret Number)
Тепер, коли у нас є введення користувача і випадкове число, ми можемо їх порівняти. Цей крок показано в Лістингу (Listing) 2-4. Зверніть увагу, що цей код ще не скомпілюється, як ми зараз пояснимо.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Спочатку ми додаємо ще один оператор use, вносячи в область видимості тип під назвою
std::cmp::Ordering зі стандартної бібліотеки. Тип Ordering
— це ще один перелік (enum) і має варіанти Less, Greater і Equal. Це
три результати, які можливі, коли ви порівнюєте два значення.
Потім ми додаємо п’ять нових рядків унизу, які використовують тип Ordering. Метод
cmp порівнює два значення і може бути викликаний на будь-чому, що можна
порівняти. Він бере посилання на те, з чим ви хочете порівняти: тут він
порівнює guess із secret_number. Потім він повертає варіант enum Ordering,
який ми внесли в область видимості за допомогою оператора use. Ми використовуємо
вираз match, щоб вирішити, що робити далі, залежно від того,
який варіант Ordering був повернутий із виклику cmp зі значеннями
в guess і secret_number.
Вираз match складається з гілок. Гілка складається із шаблону для
зіставлення та коду, який слід виконати, якщо значення, передане до match,
відповідає шаблону цієї гілки. Rust бере значення, передане до match, і
послідовно перевіряє шаблон кожної гілки. Шаблони та конструкція match
— це потужні можливості Rust: вони дають вам змогу виражати різноманітні ситуації, з якими
може зіткнутися ваш код, і гарантують, що ви обробите їх усі. Ці можливості будуть
детально розглянуті в Розділі 6 і Розділі 19 відповідно.
Розгляньмо приклад із виразом match, який ми використовуємо тут. Припустімо, що
користувач вгадав 50, а випадково згенероване секретне число цього разу — 38.
Коли код порівнює 50 із 38, метод cmp поверне
Ordering::Greater, тому що 50 більше за 38. Вираз match отримує
значення Ordering::Greater і починає перевіряти шаблон кожної гілки. Він дивиться
на шаблон першої гілки, Ordering::Less, і бачить, що значення
Ordering::Greater не відповідає Ordering::Less, тож він ігнорує код у цій
гілці та переходить до наступної. Зразок наступної гілки —
Ordering::Greater, який справді відповідає Ordering::Greater! Відповідний
код у цій гілці виконається і надрукує Too big! на
екран. Вираз match завершується після першого успішного зіставлення, тож у
цьому сценарії він не дивитиметься на останню
гілку.
Однак код у Лістингу (Listing) 2-4 ще не скомпілюється. Давайте спробуємо:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:23:21
|
23 | match guess.cmp(&secret_number) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/cmp.rs:979:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` (bin "guessing_game") due to 1 previous error
Суть помилки полягає в тому, що є mismatched types. Rust має
сильну статичну систему типів. Однак він також має виведення типів. Коли ми написали
let mut guess = String::new(), Rust зміг вивести, що guess має бути
String, і не змусив нас писати тип. secret_number, з іншого боку,
є числовим типом. Кілька числових типів Rust можуть мати значення між 1
і 100: i32, 32-бітне число; u32, беззнакове 32-бітне число; i64,
64-бітне число; а також інші. Якщо не вказано інше, Rust за замовчуванням
використовує i32, що і є типом secret_number, якщо ви не додасте
типову інформацію десь іще, що змусить Rust вивести інший числовий тип. Причина
помилки в тому, що Rust не може порівняти рядок і числовий тип.
Зрештою, ми хочемо перетворити String, який програма читає як введення, на
числовий тип, щоб ми могли порівняти його чисельно із секретним числом.
Ми робимо це, додаючи цей рядок до тіла функції main:
Filename: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Цей рядок:
let guess: u32 = guess.trim().parse().expect("Please type a number!");Ми створюємо змінну з іменем guess. Але зачекайте, хіба програма вже не має
змінної з іменем guess? Має, але, на щастя, Rust дозволяє нам затінити
попереднє значення guess новим. Затінення дозволяє нам повторно використовувати
ім’я змінної guess замість того, щоб змушувати нас створювати дві унікальні змінні, такі як
guess_str і guess, наприклад. Ми детальніше розглянемо затінення (shadowing) в
Розділі 3, але наразі знайте, що цю можливість
часто використовують, коли хочуть перетворити значення з одного типу в інший.
Ми прив’язуємо цю нову змінну до виразу guess.trim().parse(). guess
у виразі посилається на початкову змінну guess, яка містила
введення як рядок. Метод trim на екземплярі String видалить будь-які
пробіли на початку і в кінці, що ми повинні зробити перед тим, як можемо перетворити
рядок на u32, який може містити лише числові дані. Користувач має натиснути
enter, щоб задовольнити read_line і ввести своє припущення, що додає
символ нового рядка до рядка. Наприклад, якщо користувач вводить 5 і
натискає enter, guess виглядає так: 5\n. \n означає
“новий рядок”. (У Windows натискання enter призводить до символу повернення каретки
і нового рядка, \r\n.) Метод trim усуває \n або \r\n, залишаючи
лише 5.
Метод parse on strings перетворює рядок на
інший тип. Тут ми використовуємо його, щоб перетворити рядок на число. Нам потрібно
сказати Rust точний тип числа, який ми хочемо, використовуючи let guess: u32. Двокрапка
(:) після guess каже Rust, що ми будемо анотувати тип змінної. Rust має
кілька вбудованих числових типів; u32, який тут показано, — це беззнакове
32-бітне ціле число. Це хороший вибір за замовчуванням для невеликого додатного числа. Ви дізнаєтеся про
інші числові типи в Розділі 3.
Крім того, анотація u32 у цьому прикладному програмному коді та порівняння
з secret_number означає, що Rust також виведе, що secret_number має бути
u32. Отже, тепер порівняння буде між двома значеннями одного
типу!
Метод parse працюватиме лише з символами, які можна логічно перетворити
на числа, тож він легко може спричиняти помилки. Якщо, наприклад, рядок
містив A👍%, не було б способу перетворити це на число. Оскільки
він може зазнати невдачі, метод parse повертає тип Result, так само як і
метод read_line (обговорювався раніше в “Обробка можливої помилки за допомогою
Result (Handling Potential Failure with the Result Type)”). Ми поводитимемося
з цим Result так само, знову використавши метод expect. Якщо parse
повертає варіант Err типу Result, тому що не зміг створити число з
рядка, виклик expect аварійно завершить гру та надрукує повідомлення, яке ми
йому дамо. Якщо parse може успішно перетворити рядок на число, він поверне
варіант Ok типу Result, а expect поверне число, яке ми хочемо з
значення Ok.
Давайте запустимо програму зараз:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
Чудово! Хоча перед припущенням були додані пробіли, програма все одно з’ясувала, що користувач вгадав 76. Запустіть програму кілька разів, щоб перевірити різну поведінку з різними типами введення: вгадайте число правильно, вгадайте число, яке надто велике, і вгадайте число, яке надто мале.
Зараз у нас працює більша частина гри, але користувач може зробити лише одне припущення. Давайте змінимо це, додавши цикл!
Дозволяємо кілька припущень за допомогою циклу (Allowing Multiple Guesses with Looping)
Ключове слово loop створює нескінченний цикл. Ми додамо цикл, щоб дати користувачам
більше шансів відгадати число:
Filename: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}Як ви бачите, ми перемістили все від підказки введення припущення і далі в цикл. Обов’язково зробіть відступ у чотири додаткові пробіли для рядків усередині циклу і запустіть програму знову. Тепер програма буде знову і знову запитувати ще одне припущення, що насправді створює нову проблему. Схоже, користувач не може вийти!
Користувач завжди може перервати програму за допомогою комбінації клавіш
ctrl-C. Але є ще один спосіб вирватися з цього ненажерливого
монстра, як згадувалося в обговоренні parse у “Порівняння припущення із
секретним числом”: якщо
користувач вводить відповідь не числом, програма аварійно завершиться. Ми можемо скористатися цим, щоб
дозволити користувачеві вийти, як показано тут:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
quit
thread 'main' panicked at src/main.rs:28:47:
Please type a number!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Введення quit завершить гру, але, як ви помітите, так само завершить її і будь-яке
інше невідповідне числу введення. Це, м’яко кажучи, неоптимально; ми хочемо, щоб гра
також зупинялася, коли вгадано правильне число.
Вихід після правильного припущення (Quitting After a Correct Guess)
Давайте запрограмуємо гру завершуватися, коли користувач перемагає, додавши оператор break:
Filename: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Додавання рядка break після You win! змушує програму вийти з циклу, коли
користувач правильно вгадає секретне число. Вихід із циклу також означає
вихід із програми, тому що цикл — це остання частина main.
Обробка некоректного введення (Handling Invalid Input)
Щоб далі вдосконалити поведінку гри, замість аварійного завершення програми, коли
користувач вводить нечислове значення, давайте зробимо так, щоб гра ігнорувала нечислове значення, щоб
користувач міг продовжувати відгадувати. Ми можемо зробити це, змінивши рядок, де
guess перетворюється зі String на u32, як показано в Лістингу (Listing) 2-5.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Ми переходимо від виклику expect до виразу match, щоб перейти від аварійного
завершення при помилці до обробки помилки. Пам’ятайте, що parse повертає тип Result,
а Result — це перелік (enum), який має варіанти Ok і Err. Тут ми використовуємо
вираз match, як і з результатом Ordering методу cmp.
Якщо parse може успішно перетворити рядок на число, він
поверне значення Ok, яке містить отримане число. Це значення Ok відповідатиме
шаблону першої гілки, і вираз match просто поверне значення num, яке parse
створив і поклав у значення Ok. Це число
опиниться саме там, де ми хочемо, у новій змінній guess, яку ми створюємо.
Якщо parse не може перетворити рядок на число, він поверне
значення Err, яке містить більше інформації про помилку. Значення Err
не відповідає шаблону Ok(num) у першій гілці match, але воно
відповідає шаблону Err(_) у другій гілці. Підкреслення, _, — це
значення catch-all; у цьому прикладі ми кажемо, що хочемо зіставити всі значення Err,
незалежно від того, яку інформацію вони містять усередині. Отже, програма
виконає код другої гілки, continue, який каже програмі перейти до
наступної ітерації loop і попросити ще одне припущення. Тож фактично
програма ігнорує всі помилки, з якими може зіткнутися parse!
Тепер усе в програмі має працювати як очікується. Давайте спробуємо:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
Чудово! З одним маленьким фінальним налаштуванням ми завершимо гру у вгадування. Згадайте,
що програма все ще друкує секретне число. Це добре працювало для
тестування, але псує гру. Давайте видалимо println!, який виводить
секретне число. Лістинг (Listing) 2-6 показує фінальний код.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}На цьому етапі ви успішно створили гру у вгадування. Вітаємо!
Підсумок (Summary)
Цей проєкт був практичним способом ознайомити вас із багатьма новими концепціями Rust:
let, match, функції, використання зовнішніх крейтів, і багато чого ще. У наступних
кількох розділах ви детальніше дізнаєтеся про ці концепції. Розділ 3
охоплює концепції, які є в більшості мов програмування, такі як змінні, типи даних і функції,
та показує, як використовувати їх у Rust. Розділ 4 досліджує
володіння (ownership), можливість, яка робить Rust відмінним від інших мов. Розділ 5
обговорює структури (structs) та синтаксис методів (methods), а Розділ 6 пояснює, як працюють переліки (enums).
Загальні концепції програмування (Common Programming Concepts)
Цей розділ охоплює концепції, які з’являються майже в кожній мові програмування, і те, як вони працюють у Rust. Багато мов програмування мають багато спільного в своїй основі. Жодна з концепцій, представлених у цьому розділі, не є унікальною для Rust, але ми обговоримо їх у контексті Rust і пояснимо конвенції щодо їхнього використання.
Зокрема, ви дізнаєтеся про змінні (variables), базові типи (basic types), функції (functions), коментарі (comments) та потік управління (control flow). Ці основи будуть у кожній програмі Rust, і раннє їхнє вивчення дасть вам міцну основу, від якої можна відштовхуватися.
Ключові слова
Мова Rust має набір ключових слів, зарезервованих для використання лише мовою, так само, як і в інших мовах. Пам’ятайте, що ви не можете використовувати ці слова як назви змінних або функцій. Більшість ключових слів мають спеціальні значення, і ви використовуватимете їх для виконання різних завдань у ваших програмах Rust; деякі наразі не мають пов’язаної з ними функціональності, але зарезервовані для функціональності, яка може бути додана до Rust у майбутньому. Ви можете знайти список ключових слів у Додатку A.
Змінні та змінність (mutability)
Змінні та змінність (Variables and Mutability)
Як згадувалося в розділі «Зберігання значень зі змінними», за замовчуванням змінні є незмінними. Це — один із багатьох поштовхів, які Rust дає вам, щоб писати свій код так, щоб він використовував переваги безпеки та легкої конкурентності, які пропонує Rust. Однак у вас усе ще є можливість зробити ваші змінні змінними. Дослідимо, як і чому Rust заохочує вас надавати перевагу незмінності та чому інколи ви можете захотіти від цього відмовитися.
Коли змінна є незмінною, після того як значення прив’язано до імені, ви не
можете змінити це значення. Щоб проілюструвати це, створіть новий проєкт під
назвою variables у вашому каталозі projects, використавши cargo new variables.
Потім у вашому новому каталозі variables відкрийте src/main.rs і замініть його код таким кодом, який поки що не скомпілюється:
Filename: src/main.rs
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}Збережіть і запустіть програму за допомогою cargo run. Ви маєте отримати
повідомлення про помилку, пов’язану з незмінністю, як показано в цьому виводі:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Цей приклад показує, як компілятор допомагає вам знаходити помилки у ваших програмах. Помилки компілятора можуть дратувати, але насправді вони лише означають, що ваша програма ще не безпечно робить те, що ви хочете, щоб вона робила; вони не означають, що ви не є хорошим програмістом! Досвідчені растацеанці (Rustaceans) досі отримують помилки компілятора.
Ви отримали повідомлення про помилку cannot assign twice to immutable variable `x`, тому що спробували присвоїти друге значення незмінній змінній
x.
Важливо, щоб ми отримували помилки часу компіляції, коли намагаємося змінити значення, позначене як незмінне, тому що саме така ситуація може призвести до помилок. Якщо одна частина нашого коду працює, виходячи з припущення, що значення ніколи не зміниться, а інша частина нашого коду змінює це значення, то можливо, що перша частина коду не зробить того, для чого її було спроєктовано. Причину такої помилки може бути важко відстежити згодом, особливо коли другий фрагмент коду змінює значення лише інколи. Компілятор Rust гарантує, що коли ви заявляєте, що значення не зміниться, воно справді не зміниться, тож вам не потрібно відстежувати це самостійно. Таким чином, ваш код легше зрозуміти.
Але змінність може бути дуже корисною і може зробити код зручнішим для
написання. Хоча змінні за замовчуванням є незмінними, ви можете зробити їх
змінними, додавши mut перед іменем змінної, як ви зробили в розділі
2. Додавання mut також
передає намір майбутнім читачам коду, вказуючи, що інші частини коду
змінюватимуть значення цієї змінної.
Наприклад, змінимо src/main.rs на таке:
Filename: src/main.rs
fn main() {
let mut x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}Коли ми запускаємо програму тепер, отримуємо таке:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
The value of x is: 5
The value of x is: 6
Нам дозволено змінювати значення, прив’язане до x, з 5 на 6, коли
використовується mut. Зрештою, вирішувати, використовувати змінність чи ні,
— це залежить від вас і від того, що ви вважаєте найчіткішим у конкретній
ситуації.
Оголошення констант (Declaring Constants)
Як і незмінні змінні, константи — це значення, які прив’язуються до імені і не можуть змінюватися, але між константами та змінними є кілька відмінностей.
По-перше, вам не дозволено використовувати mut із константами. Константи не
просто незмінні за замовчуванням — вони завжди незмінні. Ви оголошуєте
константи, використовуючи ключове слово const замість ключового слова let,
і тип значення має бути вказаний. Ми розглянемо типи та анотації типів у
наступному розділі, «Типи даних», тож не
хвилюйтеся про деталі зараз. Просто знайте, що ви завжди повинні вказувати
тип.
Константи можуть бути оголошені в будь-якій області видимості, включно з глобальною областю видимості, що робить їх корисними для значень, про які потрібно знати багатьом частинам коду.
Остання відмінність полягає в тому, що константам можна надавати лише константний вираз, а не результат значення, який можна обчислити лише під час виконання.
Ось приклад оголошення константи:
#![allow(unused)]
fn main() {
const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;
}Ім’я константи — THREE_HOURS_IN_SECONDS, а її значення встановлюється як
результат множення 60 (кількості секунд у хвилині) на 60 (кількість хвилин у
годині) на 3 (кількість годин, які ми хочемо порахувати в цій програмі).
Умовність найменування констант у Rust полягає у використанні всіх великих
літер із підкресленнями між словами. Компілятор здатний обчислювати обмежений
набір операцій під час компіляції, що дає нам змогу записати це значення так,
щоб його було легше зрозуміти й перевірити, замість того щоб встановлювати цю
константу в значення 10,800. Дивіться розділ Rust Reference про обчислення
констант для отримання додаткової інформації про те, які
операції можна використовувати під час оголошення констант.
Константи дійсні протягом усього часу виконання програми в межах області видимості, в якій вони були оголошені. Ця властивість робить константи корисними для значень у вашій предметній області застосунку, про які можуть потрібно знати кілька частин програми, наприклад максимальну кількість балів, яку будь-який гравець у грі може набрати, або швидкість світла.
Надання жорстко закодованим значенням, що використовуються у вашій програмі, імен як констант корисне для передавання значення цього значення майбутнім підтримувачам коду. Також зручно мати лише одне місце у вашому коді, яке вам потрібно буде змінити, якщо жорстко закодоване значення потрібно буде оновити в майбутньому.
Затінення (Shadowing)
Як ви бачили в підручнику з гри у вгадування в розділі
2, ви можете
оголосити нову змінну з тим самим іменем, що й попередня змінна. растацеанці (Rustaceans)
кажуть, що перша змінна затінена другою, що означає, що друга змінна — це
те, що компілятор бачитиме, коли ви використовуєте ім’я змінної. Фактично,
друга змінна затінює першу, забираючи всі звернення до імені змінної собі,
доки або вона сама не буде затінена, або не завершиться область видимості. Ми
можемо затінити змінну, використавши те саме ім’я змінної та повторно
використавши ключове слово let, як показано нижче:
Filename: src/main.rs
fn main() {
let x = 5;
let x = x + 1;
{
let x = x * 2;
println!("The value of x in the inner scope is: {x}");
}
println!("The value of x is: {x}");
}Ця програма спочатку прив’язує x до значення 5. Потім вона створює нову
змінну x, повторно записуючи let x =, беручи початкове значення та додаючи
1, так що значення x стає 6. Потім, у внутрішній області видимості,
створеній фігурними дужками, третій оператор let також затінює x і
створює нову змінну, множачи попереднє значення на 2, щоб надати x
значення 12. Коли ця область видимості завершується, внутрішнє затінення
закінчується, і x повертається до значення 6. Коли ми запускаємо цю
програму, вона виведе таке:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
The value of x in the inner scope is: 12
The value of x is: 6
Затінення відрізняється від позначення змінної як mut, тому що ми отримаємо
помилку часу компіляції, якщо випадково спробуємо повторно присвоїти цій
змінній значення без використання ключового слова let. Використовуючи
let, ми можемо виконати кілька перетворень над значенням, але після
завершення цих перетворень змінна буде незмінною.
Інша відмінність між mut і затіненням полягає в тому, що оскільки ми
фактично створюємо нову змінну, коли знову використовуємо ключове слово
let, ми можемо змінити тип значення, але повторно використати те саме ім’я.
Наприклад, припустімо, що наша програма просить користувача показати, скільки
пробілів він хоче між якимось текстом, вводячи символи пробілу, а потім ми
хочемо зберегти це введення як число:
fn main() {
let spaces = " ";
let spaces = spaces.len();
}Перша змінна spaces має тип рядка, а друга змінна spaces має числовий
тип. Отже, затінення позбавляє нас необхідності вигадувати різні імена, такі
як spaces_str і spaces_num; натомість ми можемо повторно використати
простішу назву spaces. Однак, якщо ми спробуємо використати для цього
mut, як показано тут, ми отримаємо помилку часу компіляції:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}У повідомленні про помилку сказано, що нам не дозволено змінювати тип змінної:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Тепер, коли ми дослідили, як працюють змінні, давайте подивимося на інші типи даних, які вони можуть мати.
Типи даних
Типи даних (Data Types)
Кожне значення в Rust має певний тип даних, який повідомляє Rust, який саме вид даних було вказано, щоб він знав, як працювати з цими даними. Ми розглянемо два підмножини типів даних: скалярні (scalar) та складені (compound).
Пам’ятайте, що Rust — це статично типізована мова, що означає, що вона
має знати типи всіх змінних під час компіляції. Зазвичай компілятор може
вивести, який тип ми хочемо використовувати, на основі значення та того, як
ми його використовуємо. У випадках, коли можливі багато типів, наприклад, коли
ми перетворювали String на числовий тип за допомогою parse у розділі
“Порівняння припущення із секретним
числом” у розділі 2,
ми маємо додати анотацію типу, ось так:
#![allow(unused)]
fn main() {
let guess: u32 = "42".parse().expect("Not a number!");
}Якщо ми не додамо показану в попередньому коді анотацію типу : u32, Rust
відобразить таку помилку, яка означає, що компілятору потрібно від нас більше
інформації, щоб знати, який тип ми хочемо використовувати:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `guess` an explicit type
|
2 | let guess: /* Type */ = "42".parse().expect("Not a number!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
Ви побачите різні анотації типів для інших типів даних.
Скалярні типи (Scalar Types)
Скалярний тип представляє одне значення. Rust має чотири основні скалярні типи: цілі числа, числа з рухомою комою, булеві (boolean) та символи. Ви можете впізнати їх з інших мов програмування. Давайте перейдемо до того, як вони працюють у Rust.
Цілі типи (Integer Types)
Ціле число — це число без дробової частини. Ми використовували один цілочисельний
тип у розділі 2, тип u32. Це оголошення типу вказує, що значення, з яким воно
пов’язане, має бути беззнаковим цілим числом (знакові цілочисельні типи
починаються з i замість u), яке займає 32 біти пам’яті. Таблиця 3-1 показує
вбудовані цілочисельні типи в Rust. Ми можемо використовувати будь-який із цих
варіантів, щоб оголосити тип цілочисельного значення.
Таблиця 3-1: Цілочисельні типи в Rust
| Довжина | Знаковий | Беззнаковий |
|---|---|---|
| 8-бітний | i8 | u8 |
| 16-бітний | i16 | u16 |
| 32-бітний | i32 | u32 |
| 64-бітний | i64 | u64 |
| 128-бітний | i128 | u128 |
| Залежний від архітектури | isize | usize |
Кожен варіант може бути або знаковим, або беззнаковим і має явний розмір. Знаковий і беззнаковий стосуються того, чи можливо для числа бути від’ємним — іншими словами, чи потрібно числу мати знак із собою (знаковий), чи воно буде лише додатним і тому може бути представлене без знака (беззнаковий). Це як записувати числа на папері: коли знак має значення, число показується зі знаком плюс або мінус; однак коли можна безпечно припустити, що число додатне, воно показується без знака. Знакові числа зберігаються за допомогою представлення доповняльного коду (two’s complement).
Кожен знаковий варіант може зберігати числа від −(2n − 1) до 2n −
1 − 1 включно, де n — це кількість бітів, яку використовує цей варіант.
Отже, i8 може зберігати числа від −(27) до 27 − 1, що дорівнює
від −128 до 127. Беззнакові варіанти можуть зберігати числа від 0 до 2n − 1,
тому u8 може зберігати числа від 0 до 28 − 1, що дорівнює від 0 до 255.
Крім того, типи isize і usize залежать від архітектури комп’ютера, на якому
запущена ваша програма: 64 біти, якщо ви на 64-бітній архітектурі,
і 32 біти, якщо ви на 32-бітній архітектурі.
Ви можете записувати цілочисельні літерали в будь-якій із форм, показаних у Таблиці 3-2. Зауважте,
що числові літерали, які можуть належати до кількох числових типів, дозволяють суфікс типу,
такий як 57u8, щоб позначити тип. Числові літерали також можуть використовувати _ як
візуальний роздільник, щоб зробити число легшим для читання, наприклад 1_000, яке матиме
те саме значення, що й 1000.
Таблиця 3-2: Цілочисельні літерали в Rust
| Числові літерали | Приклад |
|---|---|
| Десятковий | 98_222 |
| Шістнадцятковий | 0xff |
| Вісімковий | 0o77 |
| Двійковий | 0b1111_0000 |
Байтовий (u8 лише) | b'A' |
Отже, як дізнатися, який цілочисельний тип використовувати? Якщо ви не впевнені, типові
значення Rust зазвичай є хорошими точками для початку: цілочисельні типи за замовчуванням
мають тип i32. Основна ситуація, у якій ви б використовували isize або usize,
— це індексування деякої колекції.
Переповнення цілого числа
Припустімо, у вас є змінна типу
u8, яка може містити значення від 0 до 255. Якщо ви спробуєте змінити змінну на значення поза цим діапазоном, наприклад 256, станеться переповнення цілого числа, що може призвести до однієї з двох поведінок. Коли ви компілюєте в режимі debug, Rust додає перевірки на переповнення цілого числа, які спричиняють паніку програми під час виконання, якщо це відбувається. Rust використовує термін панікування, коли програма завершується з помилкою; ми детальніше обговоримо паніку в розділі “Невідновлювані помилки зpanic!” у розділі 9.Коли ви компілюєте в режимі release з прапорцем
--release, Rust не додає перевірки на переповнення цілого числа, які спричиняють паніку. Натомість, якщо відбувається переповнення, Rust виконує зациклення за доповняльним кодом (two’s complement wrap-around). Коротко кажучи, значення, більші за максимальне значення, яке може містити тип, “обертаються” до мінімального значення, яке може містити тип. У випадкуu8значення 256 стає 0, значення 257 стає 1, і так далі. Програма не панікуватиме, але змінна матиме значення, яке, ймовірно, не є тим, якого ви очікували. Покладатися на поведінку переповнення цілого числа як на зациклення (wrap-around) вважається помилкою.Щоб явно обробляти можливість переповнення, ви можете використовувати такі сімейства методів, надані стандартною бібліотекою для примітивних числових типів:
- Обертати в усіх режимах за допомогою методів
wrapping_*, таких якwrapping_add.- Повернути значення
None, якщо є переповнення, за допомогою методівchecked_*.- Повернути значення та булеве значення (boolean), що вказує, чи було переповнення, за допомогою методів
overflowing_*.- Насичуватися на мінімальному або максимальному значенні за допомогою методів
saturating_*.
Типи з рухомою комою (Floating-Point Types)
Rust також має два примітивні типи для чисел з рухомою комою, які є
числами з десятковими крапками. Типи з рухомою комою в Rust — це f32 і f64,
які мають розмір 32 біти та 64 біти відповідно. Тип за замовчуванням — f64,
тому що на сучасних CPU він приблизно такий самий швидкий, як f32, але здатний
до більшої точності. Усі типи з рухомою комою є знаковими.
Ось приклад, який показує числа з рухомою комою в дії:
Ім’я файлу: src/main.rs
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
}Числа з рухомою комою представлені відповідно до стандарту IEEE-754.
Числові операції (Numeric Operations)
Rust підтримує базові математичні операції, яких ви очікували б для всіх
числових типів: додавання, віднімання, множення, ділення та остача. Цілочисельне
ділення відтинає до нуля до найближчого цілого числа. Наступний код показує,
як би ви використовували кожну числову операцію в операторі let:
Ім’я файлу: src/main.rs
fn main() {
// addition
let sum = 5 + 10;
// subtraction
let difference = 95.5 - 4.3;
// multiplication
let product = 4 * 30;
// division
let quotient = 56.7 / 32.2;
let truncated = -5 / 3; // Results in -1
// remainder
let remainder = 43 % 5;
}Кожен вираз у цих операторах використовує математичний оператор і обчислюється до одного значення, яке потім прив’язується до змінної. Додаток B містить список усіх операторів, які надає Rust.
Булевий (boolean) тип (The Boolean Type)
Як і в більшості інших мов програмування, булевий (boolean) тип у Rust має два можливі
значення: true і false. Булеві значення (boolean values) мають розмір один байт. Тип Boolean у
Rust позначається за допомогою bool. Наприклад:
Ім’я файлу: src/main.rs
fn main() {
let t = true;
let f: bool = false; // with explicit type annotation
}Основний спосіб використання булевих значень (boolean values) — через умовні конструкції, такі як
вираз if. Ми розглянемо, як працюють вирази if у Rust, у розділі “Керування
потоком”.
Тип символу (The Character Type)
Тип char у Rust — це найпримітивніший алфавітний тип мови. Ось
кілька прикладів оголошення значень char:
Ім’я файлу: src/main.rs
fn main() {
let c = 'z';
let z: char = 'ℤ'; // with explicit type annotation
let heart_eyed_cat = '😻';
}Зауважте, що ми вказуємо літерали char одинарними лапками, на відміну від
рядкових літералів, які використовують подвійні лапки. Тип char у Rust має
розмір 4 байти і представляє скалярне значення Unicode (Unicode scalar value), що означає, що він може
представляти набагато більше, ніж лише ASCII. Літери з наголосами; китайські,
японські та корейські символи; emoji; і пробіли нульової ширини — усе це
є дійсними значеннями char у Rust. Скалярні значення Unicode (Unicode scalar values) знаходяться в діапазоні
від U+0000 до U+D7FF і від U+E000 до U+10FFFF включно. Однак
“символ” насправді не є концепцією в Unicode, тому ваша людська інтуїція щодо
того, чим є “символ”, може не збігатися з тим, чим є char у Rust. Ми детально
обговоримо цю тему в розділі “Зберігання тексту, закодованого в UTF-8,
у рядках” у розділі 8.
Складені типи (Compound Types)
Складені типи можуть групувати кілька значень в один тип. Rust має два примітивні складені типи: кортежі та масиви.
Тип кортежу (The Tuple Type)
Кортеж — це загальний спосіб згрупувати разом певну кількість значень із різними типами в один складений тип. Кортежі мають фіксовану довжину: після оголошення вони не можуть збільшуватися або зменшуватися в розмірі.
Ми створюємо кортеж, записуючи список значень, розділених комами, всередині дужок. Кожна позиція в кортежі має тип, і типи різних значень у кортежі не обов’язково мають бути однаковими. У цьому прикладі ми додали необов’язкові анотації типів:
Ім’я файлу: src/main.rs
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}Змінна tup прив’язується до всього кортежу, тому що кортеж вважається
одним складеним елементом. Щоб отримати окремі значення з кортежу, ми можемо
використати зіставлення зі зразком (pattern matching), щоб розпакувати значення кортежу, ось так:
Ім’я файлу: src/main.rs
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {y}");
}Ця програма спочатку створює кортеж і прив’язує його до змінної tup. Потім
вона використовує шаблон з let, щоб взяти tup і перетворити його на три окремі
змінні, x, y і z. Це називається розпакуванням, тому що воно розбиває
один кортеж на три частини. Нарешті, програма друкує значення y, яке дорівнює
6.4.
Ми також можемо безпосередньо отримати доступ до елемента кортежу, використовуючи
крапку (.), після якої вказується індекс значення, до якого ми хочемо отримати
доступ. Наприклад:
Ім’я файлу: src/main.rs
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}Ця програма створює кортеж x, а потім отримує доступ до кожного елемента кортежу,
використовуючи відповідні індекси. Як і в більшості мов програмування, перший
індекс у кортежі — 0.
Кортеж без жодних значень має спеціальну назву, одиничний тип (unit type). Це значення і його
відповідний тип обидва записуються як () і представляють порожнє значення або
порожній тип повернення. Вирази неявно повертають значення unit, якщо вони не
повертають жодного іншого значення.
Тип масиву (The Array Type)
Інший спосіб мати колекцію з кількох значень — це масив. На відміну від кортежу, кожен елемент масиву має мати той самий тип. На відміну від масивів у деяких інших мовах, масиви в Rust мають фіксовану довжину.
Ми записуємо значення в масиві як список, розділений комами, всередині квадратних дужок:
Ім’я файлу: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
}Масиви корисні, коли ви хочете, щоб ваші дані були розміщені в стеку, так само як інші типи, які ми бачили дотепер, а не в купі (ми обговоримо стек і купу докладніше в Розділі 4) або коли ви хочете гарантувати, що у вас завжди є фіксована кількість елементів. Однак масив не настільки гнучкий, як тип вектора (vector). Вектор (vector) — це подібний тип колекції, наданий стандартною бібліотекою, якому дозволено збільшуватися або зменшуватися в розмірі, тому що його вміст живе в купі. Якщо ви не впевнені, чи використовувати масив або вектор (vector), швидше за все, вам слід використовувати вектор (vector). Розділ 8 докладніше обговорює вектори (vectors).
Однак масиви корисніші, коли ви знаєте, що кількість елементів не потрібно буде змінювати. Наприклад, якщо б ви використовували назви місяців у програмі, ви, ймовірно, використовували б масив, а не vector, тому що ви знаєте, що він завжди міститиме 12 елементів:
#![allow(unused)]
fn main() {
let months = ["January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"];
}Ви записуєте тип масиву за допомогою квадратних дужок із типом кожного елемента, крапкою з комою, а потім кількістю елементів у масиві, ось так:
#![allow(unused)]
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
}Тут i32 — це тип кожного елемента. Після крапки з комою число 5
вказує, що масив містить п’ять елементів.
Ви також можете ініціалізувати масив так, щоб він містив те саме значення для кожного елемента, вказавши початкове значення, після нього — крапку з комою, а потім довжину масиву в квадратних дужках, як показано тут:
#![allow(unused)]
fn main() {
let a = [3; 5];
}Масив із назвою a міститиме 5 елементів, і всі вони спочатку будуть
встановлені в значення 3. Це те саме, що написати let a = [3, 3, 3, 3, 3];, але
більш стисло.
Доступ до елементів масиву (Accessing Array Elements)
Масив — це один фрагмент пам’яті відомого, фіксованого розміру, який може бути розміщений у стеку. Ви можете отримати доступ до елементів масиву, використовуючи індексування, ось так:
Ім’я файлу: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
let first = a[0];
let second = a[1];
}У цьому прикладі змінна з назвою first отримає значення 1, тому що це
значення з індексом [0] у масиві. Змінна з назвою second отримає
значення 2 з індексу [1] у масиві.
Недійсний доступ до елемента масиву (Invalid Array Element Access)
Давайте подивимося, що станеться, якщо ви спробуєте отримати доступ до елемента масиву, який знаходиться за межами масиву. Припустімо, ви запускаєте цей код, подібний до гри у вгадування в розділі 2, щоб отримати індекс масиву від користувача:
Ім’я файлу: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}Цей код успішно компілюється. Якщо ви запустите цей код за допомогою cargo run
і введете 0, 1, 2, 3 або 4, програма виведе відповідне
значення за цим індексом у масиві. Якщо натомість ви введете число за межами
масиву, наприклад 10, ви побачите такий вивід:
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Програма завершилася з помилкою під час виконання в точці використання недійсного
значення в операції індексування. Програма завершилася з повідомленням про помилку і
не виконала останній оператор println!. Коли ви намагаєтеся отримати доступ до
елемента за допомогою індексування, Rust перевірятиме, що вказаний вами індекс менший
за довжину масиву. Якщо індекс більший або дорівнює довжині,
Rust викличе паніку. Цю перевірку потрібно виконувати під час виконання, особливо в цьому випадку,
тому що компілятор жодним чином не може знати, яке значення введе користувач, коли
запустить код пізніше.
Це приклад принципів безпеки пам’яті Rust у дії. У багатьох мовах низького рівня такий тип перевірки не виконується, і коли ви надаєте неправильний індекс, може бути отримано доступ до недійсної пам’яті. Rust захищає вас від такої помилки, негайно завершуючи роботу замість того, щоб дозволити доступ до пам’яті і продовжити виконання. Розділ 9 обговорює більше про обробку помилок у Rust і про те, як ви можете писати читабельний, безпечний код, який не викликає паніку і не дозволяє отримати доступ до недійсної пам’яті.
Функції
Функції (Functions)
Функції поширені в коді Rust. Ви вже бачили одну з найважливіших функцій у мові: функцію main, яка є точкою входу багатьох програм. Ви також бачили ключове слово fn, яке дозволяє вам оголошувати нові функції.
Код Rust використовує snake case як традиційний стиль для імен функцій і змінних, у якому всі літери є малими, а підкреслення розділяють слова. Ось програма, яка містить приклад визначення функції:
Filename: src/main.rs
fn main() {
println!("Hello, world!");
another_function();
}
fn another_function() {
println!("Another function.");
}Ми визначаємо функцію в Rust, вводячи fn, за яким слідують ім’я функції та набір круглих дужок. Фігурні дужки вказують компілятору, де починається і закінчується тіло функції.
Ми можемо викликати будь-яку функцію, яку визначили, ввівши її ім’я, за яким слідує набір круглих дужок. Оскільки another_function визначена в програмі, її можна викликати зсередини функції main. Зверніть увагу, що ми визначили another_function після функції main у вихідному коді; ми могли б визначити її і до неї. Rust не має значення, де ви визначаєте свої функції, лише те, що вони визначені десь в області видимості, яка може бути видима викликачеві.
Давайте почнемо новий бінарний проєкт під назвою functions, щоб далі дослідити функції. Помістіть приклад another_function у src/main.rs і запустіть його. Ви повинні побачити такий вивід:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Another function.
Рядки виконуються в тому порядку, в якому вони з’являються у функції main. Спочатку друкується повідомлення “Hello, world!”, а потім викликається another_function і друкується її повідомлення.
Параметри (Parameters)
Ми можемо визначати функції так, щоб вони мали параметри (parameters), які є спеціальними змінними, що є частиною сигнатури функції. Коли функція має параметри, ви можете надати їй конкретні значення для цих параметрів. Технічно, конкретні значення називаються аргументами (arguments), але в повсякденному спілкуванні люди, як правило, використовують слова параметр і аргумент взаємозамінно як для змінних у визначенні функції, так і для конкретних значень, переданих під час виклику функції.
У цій версії another_function ми додаємо parameter:
Filename: src/main.rs
fn main() {
another_function(5);
}
fn another_function(x: i32) {
println!("The value of x is: {x}");
}Спробуйте запустити цю програму; ви повинні отримати такий вивід:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
The value of x is: 5
Оголошення another_function має один parameter з іменем x. Тип x вказано як i32. Коли ми передаємо 5 у another_function, макрос println! підставляє 5 туди, де в рядку формату була пара фігурних дужок, що містили x.
У сигнатурах функцій ви маєте оголошувати тип кожного параметра. Це свідоме рішення в дизайні Rust: вимога анотацій типів у визначеннях функцій означає, що компілятор майже ніколи не потребує, щоб ви використовували їх деінде в коді для визначення того, який тип ви маєте на увазі. Компілятор також може надавати більш корисні повідомлення про помилки, якщо він знає, яких типів очікує функція.
Під час визначення кількох параметрів розділяйте оголошення параметрів комами, ось так:
Filename: src/main.rs
fn main() {
print_labeled_measurement(5, 'h');
}
fn print_labeled_measurement(value: i32, unit_label: char) {
println!("The measurement is: {value}{unit_label}");
}Цей приклад створює функцію з іменем print_labeled_measurement із двома параметрами. Перший параметр має ім’я value і є i32. Другий має ім’я unit_label і має тип char. Потім функція друкує текст, що містить і value, і unit_label.
Давайте спробуємо запустити цей код. Замініть програму, яка зараз є у файлі src/main.rs вашого проєкту functions, попереднім прикладом і запустіть його за допомогою cargo run:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
The measurement is: 5h
Оскільки ми викликали функцію зі значенням 5 для value і 'h' для unit_label, вивід програми містить ці значення.
Оператори та вирази (Statements and Expressions)
Тіла функцій складаються з послідовності операторів, які за бажанням завершуються виразом. Поки що функції, які ми розглядали, не містили кінцевого виразу, але ви бачили вираз як частину оператора. Оскільки Rust є мовою на основі виразів, це важлива відмінність, яку потрібно розуміти. В інших мовах немає таких самих відмінностей, тож давайте подивимося, що таке оператори та вирази (operators and expressions) і як їхні відмінності впливають на тіла функцій.
- Оператори (statements) — це інструкції, які виконують певну дію і не повертають значення.
- Вирази (expressions) обчислюються до результуючого значення.
Давайте подивимося на деякі приклади.
Насправді ми вже використовували оператори та вирази (operators and expressions) . Створення змінної та присвоєння їй значення за допомогою ключового слова let — це оператор. У Лістинг (Listing) 3-1, let y = 6; — це оператор.
fn main() {
let y = 6;
}Визначення функцій також є операторами; увесь попередній приклад сам по собі є оператором. (Як ми незабаром побачимо, виклик функції, однак, не є оператором.)
Оператори не повертають значень. Тому ви не можете присвоїти let-оператор іншій змінній, як це намагається зробити наведений нижче код; ви отримаєте помилку:
Filename: src/main.rs
fn main() {
let x = (let y = 6);
}Коли ви запустите цю програму, помилка, яку ви отримаєте, виглядатиме так:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
Оператор let y = 6 не повертає значення, тож немає нічого, до чого міг би прив’язатися x. Це відрізняється від того, що відбувається в інших мовах, таких як C і Ruby, де присвоєння повертає значення присвоєння. У цих мовах ви можете написати x = y = 6 і щоб і x, і y мали значення 6; у Rust це не так.
Вирази (expressions) обчислюються до значення і становлять більшу частину решти коду, який ви писатимете в Rust. Розгляньте математичну операцію, таку як 5 + 6, яка є виразом, що обчислюється до значення 11. Вирази можуть бути частиною операторів: у Лістингу (Listing) 3-1, 6 в операторі let y = 6; — це вираз, який обчислюється до значення 6. Виклик функції — це вираз. Виклик макросу — це вираз. Новий блок області видимості, створений за допомогою фігурних дужок, — це вираз, наприклад:
Filename: src/main.rs
fn main() {
let y = {
let x = 3;
x + 1
};
println!("The value of y is: {y}");
}Цей вираз (expression):
{
let x = 3;
x + 1
}є блоком, який, у цьому випадку, обчислюється до 4. Це значення прив’язується до y як частина оператора let. Зверніть увагу на рядок x + 1 без крапки з комою в кінці, що відрізняється від більшості рядків, які ви бачили досі. Вирази (Expressions) не включають завершувальних крапок з комою. Якщо ви додасте крапку з комою в кінець виразу, ви перетворите його на оператор, і тоді він не повертатиме значення. Майте це на увазі, коли далі досліджуватимете значення, що повертаються функціями, та вирази.
Функції зі значеннями, що повертаються (Functions with Return Values)
Функції можуть повертати значення коду, який їх викликає. Ми не даємо імен поверненим значенням, але маємо оголосити їхній тип після стрілки (->). У Rust значення, що повертається функцією, є синонімом значення останнього виразу (expression) у блоці тіла функції. Ви можете вийти з функції раніше, використовуючи ключове слово return і вказавши значення, але більшість функцій неявно повертають останній вираз (expression). Ось приклад функції, яка повертає значення:
Filename: src/main.rs
fn five() -> i32 {
5
}
fn main() {
let x = five();
println!("The value of x is: {x}");
}У функції five немає викликів функцій, макросів чи навіть let-операторів — лише число 5 саме по собі. Це цілком дійсна функція в Rust. Зверніть увагу, що тип повернення функції також вказано як -> i32. Спробуйте запустити цей код; вивід має виглядати так:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
The value of x is: 5
5 у five — це значення, що повертається функцією, саме тому тип повернення є i32. Давайте розглянемо це докладніше. Є дві важливі речі: по-перше, рядок let x = five(); показує, що ми використовуємо значення, що повертається функцією, для ініціалізації змінної. Оскільки функція five повертає 5, цей рядок є тим самим, що й такий:
#![allow(unused)]
fn main() {
let x = 5;
}По-друге, функція five не має параметрів і визначає тип значення, що повертається, але тіло функції — це самотнє 5 без крапки з комою, тому що це вираз, значення якого ми хочемо повернути.
Давайте подивимося на інший приклад:
Filename: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1
}Запуск цього коду надрукує The value of x is: 6. Але що станеться, якщо ми поставимо крапку з комою в кінці рядка, що містить x + 1, перетворивши його з виразу на оператор?
Filename: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}Компіляція цього коду призведе до помилки, як показано нижче:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
Основне повідомлення про помилку, mismatched types, розкриває ключову проблему цього коду. Визначення функції plus_one говорить, що вона повертатиме i32, але оператори не обчислюються до значення, що виражається (), одиничним типом (unit type). Отже, нічого не повертається, що суперечить визначенню функції й призводить до помилки. У цьому виводі Rust надає повідомлення, яке може допомогти виправити цю проблему: він пропонує прибрати крапку з комою, що виправило б помилку.
Коментарі
Коментарі (Comments)
Усі програмісти прагнуть зробити свій код легким для розуміння, але іноді потрібне додаткове пояснення. У таких випадках програмісти залишають коментарі у своєму вихідному коді, які компілятор ігноруватиме, але які можуть бути корисними для людей, що читають вихідний код.
Ось простий коментар:
#![allow(unused)]
fn main() {
// hello, world
}У Rust ідіоматичний стиль коментарів починає коментар двома слешами, і
коментар триває до кінця рядка. Для коментарів, що виходять за межі
одного рядка, вам потрібно буде додавати // у кожному рядку, ось так:
#![allow(unused)]
fn main() {
// So we're doing something complicated here, long enough that we need
// multiple lines of comments to do it! Whew! Hopefully, this comment will
// explain what's going on.
}Коментарі також можна розміщувати в кінці рядків, що містять код:
Filename: src/main.rs
fn main() {
let lucky_number = 7; // I'm feeling lucky today
}Але ви частіше бачитимете їх використаними в такому форматі, коли коментар розміщується на окремому рядку над кодом, який він анотує:
Filename: src/main.rs
fn main() {
// I'm feeling lucky today
let lucky_number = 7;
}Rust також має інший вид коментарів, документаційні коментарі (documentation comments), які ми обговоримо в розділі “Публікація крейта на Crates.io (Publishing a Crate to Crates.io)” Розділу 14.
Керування потоком виконання
Керування потоком (Control Flow)
Можливість виконувати певний код залежно від того, чи є умова true, і
можливість виконувати певний код повторно, поки умова є true, — це основні
будівельні блоки в більшості мов програмування. Найпоширеніші конструкції, що
дають вам змогу керувати потоком виконання коду Rust, — це вирази if і
цикли.
Вирази if (if Expressions)
Вираз if дає змогу вам розгалужувати код залежно від умов. Ви
надаєте умову, а потім зазначаєте: «Якщо ця умова виконується, виконайте цей блок
коду. Якщо умова не виконується, не виконуйте цей блок коду».
Створіть новий проєкт під назвою branches у вашому каталозі projects, щоб дослідити
вираз if. У файлі src/main.rs введіть таке:
Filename: src/main.rs
fn main() {
let number = 3;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}Усі вирази if починаються з ключового слова if, за яким іде умова. У
цьому випадку умова перевіряє, чи має змінна number значення менше за 5.
Ми розміщуємо блок коду, який потрібно виконати, якщо умова є true,
безпосередньо після умови всередині фігурних дужок. Блоки коду, пов’язані з
умовами у виразах if, інколи називають гілками (arms), так само як гілки (arms) у виразах
match, про які ми говорили в розділі “Порівняння припущення із секретним числом” у розділі 2.
За бажанням, ми також можемо включити вираз else, що ми й вирішили зробити
тут, щоб дати програмі альтернативний блок коду для виконання, якщо
обчислення умови дасть false. Якщо ви не надасте вираз else і
умова є false, програма просто пропустить блок if і перейде
до наступної частини коду.
Спробуйте запустити цей код; ви повинні побачити такий вивід:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was true
Спробуймо змінити значення number на таке, що робить умову
false, щоб побачити, що станеться:
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}Запустіть програму ще раз і подивіться на вивід:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was false
Також варто зазначити, що умова в цьому коді має бути bool. Якщо
умова не є bool, ми отримаємо помилку. Наприклад, спробуйте запустити
такий код:
Filename: src/main.rs
fn main() {
let number = 3;
if number {
println!("number was three");
}
}Умова if цього разу обчислюється до значення 3, і Rust видає
помилку:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Помилка вказує, що Rust очікував bool, але отримав ціле число. На відміну
від мов, таких як Ruby і JavaScript, Rust не намагатиметься автоматично
перетворити небулеві типи на булеве значення. Ви повинні бути явними і завжди надавати
if булеве значення як його умову. Якщо, наприклад, ми хочемо, щоб блок коду if
виконувався лише тоді, коли число не дорівнює 0, ми можемо змінити
вираз if на такий:
Filename: src/main.rs
fn main() {
let number = 3;
if number != 0 {
println!("number was something other than zero");
}
}Запуск цього коду надрукує number was something other than zero.
Обробка кількох умов за допомогою else if (Handling Multiple Conditions with else if)
Ви можете використовувати кілька умов, комбінуючи if і else у виразі else if.
Наприклад:
Filename: src/main.rs
fn main() {
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
}Ця програма має чотири можливі шляхи, якими вона може піти. Після її запуску ви повинні побачити такий вивід:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
number is divisible by 3
Коли ця програма виконується, вона послідовно перевіряє кожен вираз if і виконує
перший блок, для якого умова обчислюється до true. Зверніть увагу, що
хоча 6 ділиться на 2, ми не бачимо виводу number is divisible by 2,
як і не бачимо тексту number is not divisible by 4, 3, or 2 з блоку else.
Це тому, що Rust виконує лише блок для першої умови true,
і, щойно знаходить таку, навіть не перевіряє решту.
Надмірне використання виразів else if може захаращувати ваш код, тож якщо їх
більше ніж один, можливо, вам варто відрефакторити свій код. Розділ 6 описує потужну
конструкцію розгалуження Rust під назвою match для таких випадків.
Використання if в операторі let (Using if in a let Statement)
Оскільки if є виразом, ми можемо використовувати його в правій частині
оператора let, щоб присвоїти результат змінній, як у Лістингу (Listing) 3-2.
fn main() {
let condition = true;
let number = if condition { 5 } else { 6 };
println!("The value of number is: {number}");
}Змінна number буде прив’язана до значення на основі результату виразу if.
Запустіть цей код, щоб побачити, що станеться:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
The value of number is: 5
Пам’ятайте, що блоки коду обчислюються до останнього виразу в них, а
числа самі по собі також є виразами. У цьому випадку значення
всього виразу if залежить від того, який блок коду виконується. Це означає, що
значення, які потенційно можуть бути результатами з кожної гілки виразу if,
мають бути одного й того самого типу; у Лістингу (Listing) 3-2 результати як гілки if,
так і гілки else були цілими числами i32. Якщо типи не збігаються, як у
такому прикладі, ми отримаємо помилку:
Filename: src/main.rs
fn main() {
let condition = true;
let number = if condition { 5 } else { "six" };
println!("The value of number is: {number}");
}Коли ми намагаємося скомпілювати цей код, ми отримаємо помилку. Гілки if і else
мають несумісні типи значень, і Rust точно вказує, де
знайти проблему в програмі:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Вираз у блоці if обчислюється до цілого числа, а вираз у
блоці else обчислюється до рядка. Це не спрацює, тому що змінні повинні
мати один тип, і Rust має точно знати під час компіляції, який
тип має змінна number. Знання типу number дає змогу компілятору
перевірити, що тип є дійсним усюди, де ми використовуємо number. Rust не зміг би
зробити це, якби тип number визначався лише під час виконання; компілятор
був би складнішим і надавав би менше гарантій щодо коду, якби йому
доводилося відстежувати кілька гіпотетичних типів для будь-якої змінної.
Повторення за допомогою циклів (Repetition with Loops)
Часто корисно виконувати блок коду більше ніж один раз. Для цього Rust надає кілька циклів, які проходитимуть по коду всередині тіла циклу до кінця, а потім одразу починатимуть знову з початку. Щоб експериментувати з циклами, створімо новий проєкт під назвою loops.
У Rust є три види циклів: loop, while і for. Спробуймо кожен із них.
Повторення коду за допомогою loop (Repeating Code with loop)
Ключове слово loop повідомляє Rust виконувати блок коду знову і знову
або нескінченно, або доки ви явно не скажете йому зупинитися.
Як приклад, змініть файл src/main.rs у вашому каталозі loops так, щоб він виглядав ось так:
Filename: src/main.rs
fn main() {
loop {
println!("again!");
}
}Коли ми запустимо цю програму, ми побачимо again!, надруковане знову і знову безперервно,
поки ми не зупинимо програму вручну. Більшість терміналів підтримують комбінацію клавіш
ctrl-C, щоб перервати програму, яка застрягла в безперервному
циклі. Спробуйте:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/loops`
again!
again!
again!
again!
^Cagain!
Символ ^C позначає місце, де ви натиснули ctrl-C.
Ви можете побачити, а можете й не побачити слово again!, надруковане після ^C,
залежно від того, де код був у циклі, коли отримав сигнал переривання.
На щастя, Rust також надає спосіб вийти з циклу за допомогою коду. Ви
можете розмістити ключове слово break всередині циклу, щоб сказати програмі, коли
зупинити виконання циклу. Пригадайте, що ми зробили це в грі на вгадування в
розділі “Вихід після правильного припущення” розділу 2, щоб вийти з програми, коли користувач виграв гру, вгадавши
правильне число.
Ми також використовували continue у грі на вгадування, яке в циклі повідомляє програмі
пропустити будь-який код, що залишився в цій ітерації циклу, і перейти до
наступної ітерації.
Повернення значень із циклів (Returning Values from Loops)
Одним із способів використання loop є повторна спроба операції, яка, як ви знаєте, може не вдатися,
наприклад перевірка, чи завершила потік свою роботу. Вам також може знадобитися передати
результат цієї операції з циклу до решти вашого коду. Для цього
ви можете додати значення, яке хочете повернути, після виразу break, який
використовуєте для зупинки циклу; це значення буде повернуто з циклу, щоб ви
могли його використати, як показано тут:
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2;
}
};
println!("The result is {result}");
}Перед циклом ми оголошуємо змінну з ім’ям counter і ініціалізуємо її
значенням 0. Потім ми оголошуємо змінну з ім’ям result, щоб зберегти значення, повернуте з
циклу. На кожній ітерації циклу ми додаємо 1 до змінної counter,
а потім перевіряємо, чи дорівнює counter 10. Коли це так, ми використовуємо
ключове слово break зі значенням counter * 2. Після циклу ми використовуємо
крапку з комою, щоб завершити оператор, який присвоює значення result.
Нарешті, ми друкуємо значення в result, яке в цьому випадку є 20.
Ви також можете return ізсередини циклу. Тоді як break лише виходить із поточного
циклу, return завжди виходить із поточної функції.
Уточнення за допомогою міток циклів (Loop Labels to Disambiguate Between Multiple Loops)
Якщо у вас є цикли всередині циклів, break і continue застосовуються до
найвнутрішнього циклу в цій точці. За бажанням ви можете вказати мітку циклу для циклу,
яку потім можете використовувати з break або continue, щоб указати, що ці ключові слова
застосовуються до позначеного циклу замість найвнутрішнього циклу. Мітки циклів мають починатися
з одинарної лапки. Ось приклад із двома вкладеними циклами:
fn main() {
let mut count = 0;
'counting_up: loop {
println!("count = {count}");
let mut remaining = 10;
loop {
println!("remaining = {remaining}");
if remaining == 9 {
break;
}
if count == 2 {
break 'counting_up;
}
remaining -= 1;
}
count += 1;
}
println!("End count = {count}");
}Зовнішній цикл має мітку 'counting_up, і він рахуватиме вгору від 0 до 2.
Внутрішній цикл без мітки рахує вниз від 10 до 9. Перший break, що
не вказує мітку, вийде лише з внутрішнього циклу. Оператор break 'counting_up; вийде із зовнішнього циклу. Цей код друкує:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
count = 0
remaining = 10
remaining = 9
count = 1
remaining = 10
remaining = 9
count = 2
remaining = 10
End count = 2
Спрощення умовних циклів за допомогою while (Conditional Loops with while)
Програмі часто потрібно оцінювати умову всередині циклу. Поки
умова є true, цикл виконується. Коли умова перестає бути true,
програма викликає break, зупиняючи цикл. Можна реалізувати поведінку
такого типу, використовуючи комбінацію loop, if, else і break; ви могли б
спробувати це зараз у програмі, якщо хочете. Однак цей шаблон настільки поширений,
що Rust має вбудовану мовну конструкцію для нього, яку називають циклом while. У
Лістингу (Listing) 3-3 ми використовуємо while, щоб програма виконала цикл тричі, щоразу
рахуючи вниз, а потім, після циклу, надрукувала повідомлення і вийшла.
fn main() {
let mut number = 3;
while number != 0 {
println!("{number}!");
number -= 1;
}
println!("LIFTOFF!!!");
}Ця конструкція усуває багато вкладеності, яка була б необхідна, якби ви використовували
loop, if, else і break, і вона зрозуміліша. Поки умова
обчислюється до true, код виконується; інакше він виходить із циклу.
Циклічний прохід по колекції за допомогою for (Looping Through a Collection with for)
Ви можете обрати використання конструкції while для проходу по елементах
колекції, такої як масив. Наприклад, цикл у Лістингу (Listing) 3-4 друкує кожен
елемент у масиві a.
fn main() {
let a = [10, 20, 30, 40, 50];
let mut index = 0;
while index < 5 {
println!("the value is: {}", a[index]);
index += 1;
}
}Тут код рахує вгору по елементах у масиві. Він починає з індексу
0, а потім повторює цикл, доки не досягне останнього індексу в масиві (тобто,
коли index < 5 перестає бути true). Запуск цього коду надрукує кожен
елемент у масиві:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
Усі п’ять значень масиву з’являються в терміналі, як і очікувалося. Хоча index
у якийсь момент досягне значення 5, цикл зупиняє виконання перед
спробою отримати шосте значення з масиву.
Однак цей підхід схильний до помилок; ми могли б спричинити паніку програми, якщо
значення індексу або умова перевірки є неправильними. Наприклад, якщо б ви змінили
визначення масиву a, щоб він мав чотири елементи, але забули оновити
умову до while index < 4, код спричинив би паніку. Він також повільний, тому що
компілятор додає код виконання для перевірки умови, чи перебуває індекс у
межах масиву, на кожній ітерації циклу.
Як більш стислу альтернативу, ви можете використати цикл for і виконувати певний код
для кожного елемента в колекції. Цикл for виглядає як код у Лістингу (Listing) 3-5.
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {element}");
}
}Коли ми запустимо цей код, ми побачимо такий самий вивід, як у Лістингу (Listing) 3-4. Що
важливіше, тепер ми підвищили безпеку коду і усунули
ризик помилок, які можуть виникнути через вихід за кінець масиву або через
те, що ви не дійшли достатньо далеко і пропустили деякі елементи. Машинний код, згенерований з
циклів for, також може бути ефективнішим, тому що індекс не потрібно
порівнювати з довжиною масиву на кожній ітерації.
Використовуючи цикл for, вам не потрібно було б пам’ятати про зміну будь-якого іншого коду, якби
ви змінили кількість значень у масиві, як це було б із методом,
використаним у Лістингу (Listing) 3-4.
Безпека й стислість циклів for роблять їх найуживанішою
конструкцією циклів у Rust. Навіть у ситуаціях, коли ви хочете виконати певний код
певну кількість разів, як у прикладі з відліком назад, що використовував цикл while
у Лістингу (Listing) 3-3, більшість растацеанців (Rustaceans) використали б цикл for. Спосіб зробити це —
використати Range, наданий стандартною бібліотекою, який генерує
всі числа послідовно, починаючи з одного числа і закінчуючи перед іншим
числом.
Ось як виглядав би відлік назад із використанням циклу for і ще одного методу,
про який ми ще не говорили, rev, щоб перевернути діапазон:
Filename: src/main.rs
fn main() {
for number in (1..4).rev() {
println!("{number}!");
}
println!("LIFTOFF!!!");
}Цей код трохи кращий, чи не так?
Підсумок (Summary)
Ви дісталися сюди! Це був значний розділ: ви дізналися про змінні, скалярні
та складені типи даних, функції, коментарі, вирази if і цикли! Щоб
практикуватися з концепціями, розглянутими в цьому розділі, спробуйте створити програми, які робитимуть таке:
- Перетворювати температури між Фаренгейтом і Цельсієм.
- Генерувати n-те число Фібоначчі.
- Друкувати текст різдвяної колядки “The Twelve Days of Christmas”, використовуючи повторення в пісні.
Коли будете готові рухатися далі, ми поговоримо про концепцію в Rust, яка не поширена в інших мовах програмування: володіння (ownership).
Розуміння володіння (Understanding Ownership)
Володіння (Ownership) — це найунікальніша особливість Rust і має глибокі наслідки для решти мови. Вона дає змогу Rust гарантувати безпеку пам’яті без потреби у збирачі сміття, тож важливо зрозуміти, як працює володіння. У цьому розділі ми поговоримо про володіння, а також про кілька пов’язаних можливостей: запозичення (borrowing), зрізи (slices) і про те, як Rust розміщує дані в пам’яті.
Що таке власність?
Що таке володіння / власність (Ownership)
Володіння (Ownership) — це набір правил, які керують тим, як програма Rust керує пам’яттю. Усі програми мають керувати способом, у який вони використовують пам’ять комп’ютера під час виконання. Деякі мови мають збирання сміття, яке регулярно шукає пам’ять, що більше не використовується, поки програма працює; в інших мовах програміст має явно виділяти і звільняти пам’ять. Rust використовує третій підхід: пам’ять керується через систему володіння (ownership system) з набором правил, які перевіряє компілятор. Якщо будь-яке з правил порушено, програма не скомпілюється. Жодна з можливостей володіння (ownership) не сповільнить вашу програму під час виконання.
Оскільки володіння (ownership) — це нова концепція для багатьох програмістів, до неї справді потрібно трохи часу, щоб звикнути. Добра новина полягає в тому, що чим досвідченішими ви стаєте з Rust і правилами системи володіння (ownership system), тим легше вам буде природно розробляти код, який є безпечним і ефективним. Продовжуйте!
Коли ви зрозумієте володіння (ownership), у вас буде міцна основа для розуміння можливостей, які роблять Rust унікальним. У цьому розділі ви дізнаєтеся про володіння (ownership), працюючи з кількома прикладами, що зосереджені на дуже поширеній структурі даних: рядках.
Стек і купа (The Stack and the Heap)
Багато мов програмування не вимагають, щоб ви дуже часто думали про стек і купу. Але в системній мові програмування, як-от Rust, те, чи значення перебуває у стеку чи в купі, впливає на те, як поводиться мова і чому вам доводиться робити певні рішення. Частини володіння (ownership) буде описано у зв’язку зі стеком і купою пізніше в цьому розділі, тож ось коротке пояснення для підготовки.
І стек, і купа є частинами пам’яті, доступними для використання вашим кодом під час виконання, але вони структуровані по-різному. Стек зберігає значення в тому порядку, в якому він їх отримує, і видаляє значення у зворотному порядку. Це називається останній прийшов — перший пішов (LIFO). Подумайте про стопку тарілок: коли ви додаєте ще тарілки, ви кладете їх на верхівку стопки, а коли вам потрібна тарілка, ви берете одну згори. Додавати або видаляти тарілки із середини чи знизу працювало б не так добре! Додавання даних називається проштовхуванням у стек, а видалення даних називається виштовхуванням зі стеку. Усі дані, що зберігаються у стеку, мають мати відомий, фіксований розмір. Дані з невідомим розміром під час компіляції або розміром, який може змінюватися, мають зберігатися в купі замість цього.
Купа менш упорядкована: коли ви розміщуєте дані в купі, ви запитуєте певний обсяг простору. Алокатор пам’яті знаходить порожнє місце в купі, достатньо велике, позначає його як таке, що використовується, і повертає вказівник, який є адресою цього місця. Цей процес називається виділенням у купі і інколи скорочується просто до виділення (проштовхування значень у стек не вважається виділенням). Оскільки вказівник на купу має відомий, фіксований розмір, ви можете зберегти вказівник у стеку, але коли ви хочете отримати самі дані, ви маєте слідувати за вказівником. Подумайте про те, як вас садять у ресторані. Коли ви входите, ви повідомляєте кількість людей у вашій групі, а хост знаходить порожній стіл, який вмістить усіх, і проводить вас туди. Якщо хтось із вашої групи запізниться, він може запитати, де вас посадили, щоб знайти вас.
Проштовхування до стеку швидше, ніж виділення в купі, тому що алокатору ніколи не доводиться шукати місце для зберігання нових даних; це місце завжди зверху стеку. Порівняно з цим, виділення простору в купі потребує більше роботи, тому що алокатор спочатку має знайти достатньо велике місце для розміщення даних, а потім виконати службове облікове ведення, щоб підготуватися до наступного виділення.
Доступ до даних у купі загалом повільніший, ніж доступ до даних у стеку, тому що вам потрібно слідувати за вказівником, щоб дістатися туди. Сучасні процесори працюють швидше, якщо вони менше стрибають пам’яттю. Продовжуючи аналогію, уявіть собі офіціанта в ресторані, який приймає замовлення від багатьох столів. Найефективніше отримати всі замовлення за одним столом, перш ніж переходити до наступного столу. Брати замовлення за столом A, потім замовлення за столом B, потім одне з A знову, а потім одне з B знову було б значно повільнішим процесом. Так само процесор зазвичай може краще виконувати свою роботу, якщо він працює з даними, які близько розташовані до інших даних (як це є у стеку), а не далі від них (як це може бути в купі).
Коли ваш код викликає функцію, значення, передані у функцію (включно, потенційно, з вказівниками на дані в купі), і локальні змінні функції проштовхуються у стек. Коли функція завершується, ці значення виштовхуються зі стеку.
очищення невикористаних даних у купі, щоб у вас не закінчився простір, — усе це проблеми, які вирішує володіння (ownership). Щойно ви зрозумієте володіння (ownership), вам не доведеться дуже часто думати про стек і купу. Але знання того, що головна мета володіння (ownership) — керувати даними в купі, може допомогти пояснити, чому вона працює саме так, як працює.
Правила володіння (Ownership Rules)
Спочатку давайте поглянемо на правила володіння (ownership rules). Тримайте ці правила в голові, коли ми розглядатимемо приклади, що їх ілюструють:
- Кожне значення в Rust має власника.
- Одночасно може бути лише один власник.
- Коли власник виходить за межі області видимості, значення буде знищено.
Область видимості змінної (Variable Scope)
Тепер, коли ми вже пройшли базовий синтаксис Rust, ми не включатимемо весь код fn main() {
у приклади, тож якщо ви йдете за текстом, не забудьте вручну помістити
наступні приклади всередину функції main. У результаті наші приклади
будуть трохи лаконічнішими, дозволяючи нам зосередитися на самих деталях, а не на
допоміжному коді.
Як перший приклад володіння (ownership) ми розглянемо область видимості деяких змінних. Область видимості — це діапазон у програмі, протягом якого елемент є дійсним. Візьміть таку змінну:
#![allow(unused)]
fn main() {
let s = "hello";
}Змінна s посилається на рядковий літерал, де значення рядка
жорстко закодоване (hardcoded) в тексті нашої програми. Змінна є дійсною від моменту,
коли її оголошено, і до кінця поточної області видимості. У Лістингу (Listing) 4-1 показано
програму з коментарями, які позначають, де змінна s була б дійсною.
fn main() {
{ // s is not valid here, since it's not yet declared
let s = "hello"; // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no longer valid
}Іншими словами, тут є два важливі моменти в часі:
- Коли
sвходить у область видимості, вона є дійсною. - Вона залишається дійсною, доки не вийде з області видимості.
На цьому етапі взаємозв’язок між областями видимості та моментом, коли змінні є дійсними,
подібний до такого в інших мовах програмування. Тепер ми розвинемо це
розуміння, увівши тип String.
Тип String (The String Type)
Щоб ілюструвати правила володіння (ownership), нам потрібен тип даних, який є складнішим,
ніж ті, що ми розглядали в розділі “Типи даних” (Data Types)
з Розділу 3. Попередньо розглянуті типи мають відомий розмір, можуть зберігатися
у стеку й виштовхуватися зі стеку, коли їхня область видимості завершується, і можуть
швидко та тривіально копіюватися, щоб створити новий, незалежний екземпляр, якщо іншій
частині коду потрібно використати те саме значення в іншій області видимості. Але ми хочемо
подивитися на дані, що зберігаються в купі, і дослідити, як Rust знає, коли
очищати ці дані, а тип String — чудовий приклад.
Ми зосередимося на тих частинах String, які пов’язані з володінням (ownership). Ці
аспекти також застосовуються до інших складних типів даних, незалежно від того, чи надаються вони
стандартною бібліотекою, чи створені вами. Ми обговоримо аспекти String, не пов’язані з
володінням (ownership), у Розділі 8.
Ми вже бачили рядкові літерали, де значення рядка жорстко закодоване у нашій
програмі. Рядкові літерали зручні, але вони не підходять для кожної
ситуації, в якій ми можемо захотіти використовувати текст. Одна з причин полягає в тому, що вони
незмінні. Інша полягає в тому, що не кожне значення рядка можна знати, коли ми пишемо
наш код: наприклад, що якби ми хотіли приймати введення користувача і зберігати його? Саме
для таких ситуацій у Rust є тип String. Цей тип керує
даними, виділеними в купі, і тому може зберігати обсяг тексту, який нам
невідомий під час компіляції. Ви можете створити String з рядкового
літерала за допомогою функції from, ось так:
#![allow(unused)]
fn main() {
let s = String::from("hello");
}Оператор подвійної двокрапки :: дозволяє нам помістити цю конкретну
функцію from у простір імен типу String замість використання
якогось імені на кшталт string_from. Ми обговоримо цей синтаксис детальніше в
розділі “Methods” Розділу 5, а також коли говоритимемо про простори імен за
допомогою модулів у “Paths for Referring to an Item in the Module
Tree” у Розділі 7.
Цей тип рядка можна змінювати:
fn main() {
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() appends a literal to a String
println!("{s}"); // this will print `hello, world!`
}Отже, у чому тут різниця? Чому String можна змінювати, а літерали
— ні? Різниця полягає в тому, як ці два типи поводяться з пам’яттю.
Пам’ять і виділення (Memory and Allocation)
У випадку рядкового літерала ми знаємо вміст під час компіляції, тож текст жорстко закодований безпосередньо у фінальний виконуваний файл. Саме тому рядкові літерали швидкі та ефективні. Але ці властивості походять лише від незмінності рядкового літерала. На жаль, ми не можемо помістити блок пам’яті в бінарний файл для кожного фрагмента тексту, розмір якого невідомий під час компіляції і який може змінюватися під час виконання програми.
У випадку типу String, щоб підтримати змінюваний, зростаючий фрагмент тексту,
нам потрібно виділити в купі обсяг пам’яті, невідомий під час компіляції,
щоб утримувати вміст. Це означає:
- Потрібно запитати пам’ять у алокатора пам’яті під час виконання.
- Нам потрібен спосіб повернути цю пам’ять алокатору, коли ми закінчимо з
нашим
String.
Перша частина робиться нами: коли ми викликаємо String::from, його реалізація
запитує потрібну йому пам’ять. Це майже універсально в мовах програмування.
Однак друга частина відрізняється. У мовах зі збирачем сміття
(GC) збирач сміття відстежує і очищає пам’ять, яка більше не використовується,
і нам не потрібно про це думати. У більшості мов без GC це наша відповідальність —
визначити, коли пам’ять більше не використовується, і викликати код, щоб явно
звільнити її, так само як ми робили для запиту на її виділення. Історично зробити
це правильно було складною програмістською проблемою. Якщо ми забудемо, ми
марнуватимемо пам’ять. Якщо зробимо це занадто рано, у нас буде недійсна змінна. Якщо
зробимо це двічі, це теж помилка. Нам потрібно поєднати рівно один allocate з
рівно одним free.
Rust обирає інший шлях: пам’ять автоматично повертається, коли
змінна, що володіє нею, виходить за межі області видимості. Ось версія нашого прикладу
з областю видимості з Лістингу (Listing) 4-1, але з String замість рядкового літерала:
fn main() {
{
let s = String::from("hello"); // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no
// longer valid
}Існує природний момент, коли ми можемо повернути пам’ять, потрібну нашому String,
алокатору: коли s виходить за межі області видимості. Коли змінна виходить за
межі області видимості, Rust викликає для нас спеціальну функцію. Ця функція називається
drop, і саме в ній автор String може розмістити
код для повернення пам’яті. Rust викликає drop автоматично при
закривальній фігурній дужці.
Примітка: у C++ цей шаблон звільнення ресурсів наприкінці часу життя елемента інколи називається Resource Acquisition Is Initialization (RAII). Функція
dropу Rust буде вам знайома, якщо ви використовували шаблони RAII.
Цей шаблон має глибокий вплив на те, як пишеться код Rust. Зараз це може здаватися простим, але поведінка коду може бути несподіваною в більш складних ситуаціях, коли ми хочемо, щоб кілька змінних використовували дані, які ми виділили в купі. Давайте дослідимо деякі з цих ситуацій зараз.
Змінні та дані, що взаємодіють через переміщення (Variables and Data Interacting with Move)
Кілька змінних можуть взаємодіяти з тими самими даними по-різному в Rust. У Лістингу (Listing) 4-2 показано приклад з використанням цілого числа.
fn main() {
let x = 5;
let y = x;
}Ми, ймовірно, можемо здогадатися, що тут відбувається: “Прив’язати значення 5 до x; потім
зробити копію значення в x і прив’язати її до y.” Тепер у нас є дві змінні, x
і y, і обидві дорівнюють 5. Саме це й відбувається, тому що цілі числа
— це прості значення з відомим, фіксованим розміром, і обидва ці значення 5
проштовхуються у стек.
Тепер давайте подивимося на версію з String:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
}Це виглядає дуже схоже, тож ми можемо припустити, що спосіб роботи буде
такий самий: тобто другий рядок зробить копію значення в s1 і прив’яже
її до s2. Але відбувається не зовсім це.
Подивіться на Figure 4-1, щоб побачити, що відбувається з String
під капотом. String складається з трьох частин, показаних ліворуч: вказівника на
пам’ять, що містить вміст рядка, довжини та ємності.
Ця група даних зберігається у стеку. Праворуч — пам’ять у
купі, яка містить вміст.

Рисунок (Figure) 4-1: Представлення в пам’яті String, що містить значення "hello", прив’язане до s1 (The representation in memory of a String holding the value "hello" bound to s1)
Довжина — це те, скільки пам’яті, у байтах, зараз використовує вміст String.
Ємність — це загальний обсяг пам’яті, у байтах, який String отримав від алокатора.
Різниця між довжиною та ємністю має значення, але не в цьому контексті, тож
поки що її можна ігнорувати.
Коли ми присвоюємо s1 до s2, дані String копіюються, тобто ми копіюємо
вказівник, довжину та ємність, що знаходяться у стеку. Ми не копіюємо
дані в купі, на які вказує вказівник. Іншими словами, представлення даних
у пам’яті виглядає як на Figure 4-2.

Рисунок (Figure) 4-2: Представлення в пам’яті змінної s2, що має копію вказівника, довжини та ємності s1 (The representation in memory of the variable s2 that has a copy of the pointer, length, and capacity of s1)
Представлення не виглядає як Figure 4-3, яке було б у пам’яті, якби Rust
також копіював дані в купі. Якби Rust робив це, операція s2 = s1 могла б
бути дуже дорогою з точки зору продуктивності під час виконання, якщо дані в купі були б великими.

Рисунок (Figure) 4-3: Інша можливість того, що могла б зробити s2 = s1, якби Rust також копіював дані в купі (Another possibility for what s2 = s1 might do if Rust copied the heap data as well)
Раніше ми сказали, що коли змінна виходить за межі області видимості, Rust автоматично
викликає функцію drop і очищає пам’ять у купі для цієї змінної. Але
Figure 4-2 показує, що обидва вказівники даних вказують на одне й те саме місце. Це
проблема: коли s2 і s1 вийдуть за межі області видимості, вони обидва спробують звільнити
ту саму пам’ять. Це відоме як помилка подвійного звільнення (double free) і є однією
з помилок безпеки пам’яті, про які ми згадували раніше. Подвійне звільнення пам’яті (double free)
може призвести до пошкодження пам’яті, що потенційно може призвести до вразливостей
безпеки.
Щоб забезпечити безпеку пам’яті, після рядка let s2 = s1;, Rust вважає s1
більш не дійсною. Тому Rust не потрібно нічого звільняти, коли s1
виходить за межі області видимості. Подивіться, що відбувається, коли ви намагаєтеся використати s1
після створення s2; це не спрацює:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}Ви отримаєте таку помилку, тому що Rust не дає вам використовувати недійсне посилання:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:16
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{s1}, world!");
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Якщо ви чули терміни shallow copy і deep copy, працюючи з
іншими мовами, концепція копіювання вказівника, довжини та ємності
без копіювання даних, імовірно, звучить як створення shallow copy. Але
оскільки Rust також робить першу змінну недійсною, замість того щоб це називалося
shallow copy, це відоме як переміщення. У цьому прикладі ми б сказали, що s1
було переміщено у s2. Отже, те, що насправді відбувається, показано на Figure 4-4.

Рисунок (Figure) 4-4: Представлення в пам’яті після того, як s1 було анульовано (The representation in memory after s1 has been invalidated)
Це вирішує нашу проблему! Оскільки дійсною лишається лише s2, коли вона
вийде за межі області видимості, вона одна звільнить пам’ять, і на цьому все.
Крім того, з цього випливає одне дизайнерське рішення: Rust ніколи не буде автоматично створювати “глибокі” копії ваших даних. Тому будь-яке автоматичне копіювання можна вважати недорогим з точки зору продуктивності під час виконання.
Область видимості та присвоєння (Variables and Data Interacting with Move)
Інверсія цього твердження також справедлива для взаємозв’язку між областю видимості, володінням та
звільненням пам’яті через функцію drop. Коли ви присвоюєте зовсім нове значення
існуючій змінній, Rust викличе drop і негайно звільнить пам’ять початкового
значення. Розглянемо, наприклад, цей код:
fn main() {
let mut s = String::from("hello");
s = String::from("ahoy");
println!("{s}, world!");
}Спочатку ми оголошуємо змінну s і прив’язуємо її до String зі значенням
"hello". Потім ми негайно створюємо новий String зі значенням "ahoy"
і присвоюємо його s. У цей момент жоден об’єкт взагалі не посилається на
початкове значення в купі. Figure 4-5 ілюструє дані стеку та купи тепер:

Рисунок (Figure) 4-5: Представлення в пам’яті після того, як початкове значення було повністю замінено (The representation in memory after the initial value has been replaced in its entirety)
Отже, початковий рядок одразу виходить за межі області видимості. Rust запустить
на ньому функцію drop, і його пам’ять буде звільнено негайно. Коли ми надрукуємо
значення в кінці, це буде "ahoy, world!".
Змінні та дані, що взаємодіють через clone (Variables and Data Interacting with Clone)
Якщо ми дійсно хочемо глибоко скопіювати дані String у купі, а не лише
дані зі стеку, ми можемо використати поширений метод під назвою clone. Синтаксис
методів ми обговоримо в Розділі 5, але оскільки методи є поширеною можливістю в багатьох
мовах програмування, ви, ймовірно, бачили їх раніше.
Ось приклад методу clone у дії:
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {s1}, s2 = {s2}");
}Це працює цілком добре і явно створює поведінку, показану на Рисунку (Figure) 4-3, де дані в купі дійсно копіюються.
Коли ви бачите виклик clone, ви знаєте, що виконується якийсь довільний код
і цей код може бути дорогим. Це візуальний індикатор того, що відбувається
щось інше.
Дані лише у стеку: Copy (Stack-Only Data: Copy)
Є ще одна складність, про яку ми ще не говорили. Цей код із цілими числами — частина якого була показана в Лістингу (Listing) 4-2 — працює і є дійсним:
fn main() {
let x = 5;
let y = x;
println!("x = {x}, y = {y}");
}Але цей код, здається, суперечить тому, що ми щойно дізналися: у нас немає виклику
clone, але x усе ще дійсна і не була переміщена в y.
Причина в тому, що типи на кшталт цілих чисел, які мають відомий розмір під час компіляції,
повністю зберігаються у стеку, тож копії фактичних значень створюються швидко.
Це означає, що немає жодної причини перешкоджати тому, щоб x залишалася
дійсною після створення змінної y. Іншими словами, тут немає різниці
між глибоким і неглибоким копіюванням, тож виклик clone не дав би нічого
іншого порівняно зі звичайним неглибоким копіюванням, і ми можемо його не вживати.
Rust має спеціальну анотацію під назвою трейту (trait) Copy, яку ми можемо застосовувати
до типів, що зберігаються у стеку, як-от цілі числа (ми ще поговоримо більше про трейти (traits) у Розділі 10). Якщо тип реалізує трейт (trait) Copy,
змінні, які його використовують, не переміщуються, а просто копіюються,
залишаючись дійсними після присвоєння іншій змінній.
Rust не дозволить нам анотувати тип Copy, якщо тип або будь-яка з його частин
реалізували трейт (trait) Drop. Якщо для типу має відбуватися щось спеціальне, коли значення
виходить за межі області видимості, і ми додаємо до цього типу анотацію Copy,
ми отримаємо помилку під час компіляції. Щоб дізнатися, як додати анотацію Copy
до вашого типу, щоб реалізувати трейт, див. “Derivable
Traits” в Додатку C.
Отже, які типи реалізують трейт Copy? Ви можете перевірити документацію для
певного типу, щоб переконатися, але загальне правило таке: будь-яка група простих скалярних
значень може реалізувати Copy, а все, що потребує виділення пам’яті або є будь-якою
формою ресурсу, не може реалізувати Copy. Ось деякі з типів, які
реалізують Copy:
- Усі цілі типи, як-от
u32. - Булевий тип,
bool, зі значеннямиtrueіfalse. - Усі типи чисел із рухомою комою, як-от
f64. - Символьний тип,
char. - Кортежі, якщо вони містять лише типи, які також реалізують
Copy. Наприклад,(i32, i32)реалізуєCopy, але(i32, String)— ні.
Володіння / Власність (Ownership) і функції
Механіка передавання значення у функцію подібна до тієї, що й під час присвоєння значення змінній. Передавання змінної у функцію перемістить або скопіює її, так само як і присвоєння. У Лістингу (Listing) 4-3 є приклад із деякими позначками, що показують, де змінні входять у область видимості та виходять з неї.
fn main() {
let s = String::from("hello"); // s comes into scope
takes_ownership(s); // s's value moves into the function...
// ... and so is no longer valid here
let x = 5; // x comes into scope
makes_copy(x); // Because i32 implements the Copy trait,
// x does NOT move into the function,
// so it's okay to use x afterward.
} // Here, x goes out of scope, then s. However, because s's value was moved,
// nothing special happens.
fn takes_ownership(some_string: String) { // some_string comes into scope
println!("{some_string}");
} // Here, some_string goes out of scope and `drop` is called. The backing
// memory is freed.
fn makes_copy(some_integer: i32) { // some_integer comes into scope
println!("{some_integer}");
} // Here, some_integer goes out of scope. Nothing special happens.Якби ми спробували використати s після виклику takes_ownership, Rust викинув би
помилку під час компіляції. Ці статичні перевірки захищають нас від помилок. Спробуйте додати
код до main, який використовує s і x, щоб побачити, де ви можете їх використовувати і де
правила володіння (ownership) не дозволяють вам це робити.
Значення, що повертаються, і область видимості (Return Values and Scope)
Повернення значень також може передавати володіння (ownership). У Лістингу (Listing) 4-4 показано приклад функції, яка повертає деяке значення, з такими ж позначками, як і в Лістингу (Listing) 4-3.
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return
// value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into
// takes_and_gives_back, which also
// moves its return value into s3
} // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing
// happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string comes into scope
some_string // some_string is returned and
// moves out to the calling
// function
}
// This function takes a String and returns a String.
fn takes_and_gives_back(a_string: String) -> String {
// a_string comes into
// scope
a_string // a_string is returned and moves out to the calling function
}Володіння (Ownership) змінної щоразу слідує одному й тому самому шаблону: присвоєння
значення іншій змінній переміщує його. Коли змінна, яка містить дані в купі,
виходить за межі області видимості, значення буде очищено за допомогою drop, якщо володіння (ownership)
даними не було переміщене до іншої змінної.
Хоча це працює, брати володіння (ownership) і потім повертати володіння (ownership) у кожній функції трохи виснажливо. Що якби ми хотіли дозволити функції використати значення, але не брати володіння? Досить незручно, що все, що ми передаємо, також потрібно передати назад, якщо ми хочемо використати це знову, окрім будь-яких даних, що виникають у тілі функції, які ми також можемо захотіти повернути.
Rust справді дозволяє повертати кілька значень за допомогою кортежу, як показано в Лістингу (Listing) 4-5.
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{s2}' is {len}.");
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() returns the length of a String
(s, length)
}Але це забагато церемонності й багато роботи для поняття, яке має бути звичним. На щастя для нас, у Rust є можливість використовувати значення без передавання володіння (ownership): посилання.
Посилання та запозичення
Посилання та запозичення (References and Borrowing)
Проблема з кодом кортежу в Лістингу (Listing) 4-5 полягає в тому, що ми маємо повернути
String викличній функції, щоб ми все ще могли використовувати String після
виклику calculate_length, тому що String було переміщено в
calculate_length. Натомість ми можемо надати посилання на значення String.
Посилання — це як вказівник у тому сенсі, що це адреса, за якою ми можемо
прослідкувати, щоб отримати доступ до даних, що зберігаються за цією адресою;
ці дані належать якійсь іншій змінній. На відміну від вказівника, посилання
гарантовано вказує на дійсне значення певного типу протягом часу життя цього
посилання.
Ось як ви б визначили та використали функцію calculate_length, яка має
посилання на об’єкт як параметр замість того, щоб брати значення у володіння:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}Спочатку зверніть увагу, що весь код кортежу в оголошенні змінної та значення
повернення функції зник. По-друге, зауважте, що ми передаємо &s1 у
calculate_length і, у її визначенні, ми беремо &String, а не
String. Ці амперсанди (ampersands) позначають посилання, і вони дозволяють вам
посилатися на певне значення, не беручи його у володіння. Рисунок (Figure) 4-6
зображує цю концепцію.

Рисунок (Figure) 4-6: Діаграма &String s, що вказує на
String s1 (A diagram of &String s pointing at String s1)
Примітка: Протилежністю посилання через використання
&є розіменування (dereferencing), яке виконується за допомогою оператора розіменування,*. Ми побачимо деякі способи використання оператора розіменування в Розділі 8 і обговоримо деталі розіменування в Розділі 15.
Давайте придивимося до виклику функції тут:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}Синтаксис &s1 дозволяє нам створити посилання, яке посилається на значення
s1, але не володіє ним. Оскільки посилання не володіє ним, значення, на яке
воно вказує, не буде вивільнено, коли посилання перестане використовуватися.
Так само сигнатура функції використовує &, щоб вказати, що тип параметра s
є посиланням. Додамо кілька пояснювальних позначок:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize { // s is a reference to a String
s.len()
} // Here, s goes out of scope. But because s does not have ownership of what
// it refers to, the String is not dropped.Область видимості, у якій змінна s є дійсною, є тією самою, що й область
видимості будь-якого параметра функції, але значення, на яке вказує посилання,
не вивільняється, коли s перестає використовуватися, тому що s не має
володіння. Коли функції мають посилання як параметри замість фактичних
значень, нам не потрібно буде повертати значення, щоб повернути володіння,
тому що ми ніколи не мали володіння.
Дію створення посилання ми називаємо запозиченням. Як і в реальному житті, якщо людина чимось володіє, ви можете позичити це у неї. Коли ви закінчите, ви маєте повернути це. Ви цим не володієте.
Отже, що станеться, якщо ми спробуємо змінити щось, що ми запозичуємо? Спробуйте код у Лістингу (Listing) 4-6. Спойлер: це не працює!
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}Ось помилка:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(some_string: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Так само, як змінні за замовчуванням є незмінними, такими є й посилання. Нам не дозволено змінювати те, на що ми маємо посилання.
Змінні посилання (Mutable References)
Ми можемо виправити код з Лістингу (Listing) 4-6, щоб дозволити нам змінювати запозичене значення, лише з кількома невеликими змінами, які замість цього використовують змінне посилання (mutable reference):
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}Спочатку ми змінюємо s на mut. Потім ми створюємо змінне посилання за
допомогою &mut s там, де ми викликаємо функцію change, і оновлюємо
сигнатуру функції так, щоб вона приймала змінне посилання з
some_string: &mut String. Це дуже чітко показує, що функція change
змінюватиме значення, яке вона запозичує.
Змінні посилання мають одне велике обмеження: якщо у вас є змінне посилання на
значення, ви не можете мати жодних інших посилань на це значення. Цей код,
який намагається створити два змінні посилання на s, завершиться помилкою:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{r1}, {r2}");
}Ось помилка:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{r1}, {r2}");
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ця помилка каже, що цей код є недійсним, тому що ми не можемо запозичити s
як змінне більше ніж один раз одночасно. Перше змінне запозичення знаходиться
в r1 і має тривати до моменту його використання в println!, але між
створенням цього змінного посилання та його використанням ми спробували
створити ще одне змінне посилання в r2, яке запозичує ті самі дані, що й
r1.
Обмеження, яке не дозволяє кільком змінним посиланням на ті самі дані існувати одночасно, дає змогу виконувати змінювання, але в дуже контрольований спосіб. Це те, з чим новачки в Rust, растацеанці (Rustaceans), мають труднощі, тому що більшість мов дозволяють вам змінювати коли завгодно. Перевага наявності цього обмеження полягає в тому, що Rust може запобігати станам гонки даних (data race) під час компіляції. Стан гонки даних — це подібно до умови гонки і трапляється, коли відбуваються такі три поведінки:
- Два або більше вказівники отримують доступ до одних і тих самих даних одночасно.
- Принаймні один із вказівників використовується для запису в дані.
- Немає механізму, який використовується для синхронізації доступу до даних.
Стани гонки даних спричиняють невизначену поведінку і можуть бути складними для діагностики та виправлення, коли ви намагаєтеся знайти їх під час виконання; Rust запобігає цій проблемі, відмовляючись компілювати код зі станами гонки даних!
Як завжди, ми можемо використовувати фігурні дужки, щоб створити нову область видимості, дозволяючи мати кілька змінних посилань, але не одночасних:
fn main() {
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 goes out of scope here, so we can make a new reference with no problems.
let r2 = &mut s;
}Rust застосовує подібне правило для поєднання змінних і незмінних посилань. Цей код призводить до помилки:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{r1}, {r2}, and {r3}");
}Ось помилка:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}, and {r3}");
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ох! Ми також не можемо мати змінне посилання, коли маємо незмінне на те саме значення.
Користувачі незмінного посилання не очікують, що значення раптово зміниться у них під ногами! Однак кілька незмінних посилань дозволені, тому що ніхто, хто лише читає дані, не має змоги вплинути на читання даних кимось іншим.
Зауважте, що область видимості посилання починається з того місця, де його
було введено, і продовжується до останнього разу, коли це посилання
використовується. Наприклад, цей код скомпілюється, тому що останнє
використання незмінних посилань відбувається в println!, до того, як буде
введено змінне посилання:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
println!("{r1} and {r2}");
// Variables r1 and r2 will not be used after this point.
let r3 = &mut s; // no problem
println!("{r3}");
}Області видимості незмінних посилань r1 і r2 закінчуються після println!,
де вони востаннє використовуються, а це відбувається до створення змінного
посилання r3. Ці області видимості не перекриваються, тому цей код
дозволений: компілятор може визначити, що посилання більше не використовується
в точці до кінця області видимості.
Хоча помилки запозичення іноді можуть бути неприємними, пам’ятайте, що це компілятор Rust вказує на потенційну помилку на ранньому етапі (під час компіляції, а не під час виконання) і показує вам точно, де проблема. Тоді вам не потрібно буде шукати, чому ваші дані не такі, як ви думали.
Висячі посилання (Dangling References)
У мовах із вказівниками легко помилково створити висячий вказівник (dangling pointer) — вказівник, який посилається на місце в пам’яті, яке, можливо, було передано комусь іншому — звільнивши частину пам’яті, зберігаючи при цьому вказівник на цю пам’ять. У Rust, навпаки, компілятор гарантує, що посилання ніколи не будуть висячими посиланнями: якщо ви маєте посилання на якісь дані, компілятор забезпечить, що дані не вийдуть за межі області видимості раніше, ніж посилання на ці дані.
Давайте спробуємо створити висяче посилання, щоб побачити, як Rust запобігає цьому за допомогою помилки під час компіляції:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}Ось помилка:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Це повідомлення про помилку стосується можливості, яку ми ще не розглядали: часів життя. Ми детально обговоримо часи життя в Розділі 10. Але якщо проігнорувати частини про часи життя, повідомлення все ж містить ключ до того, чому цей код є проблемою:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
Давайте придивимося уважніше до того, що саме відбувається на кожному етапі
нашого коду dangle:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope and is dropped, so its memory goes away.
// Danger!Оскільки s створюється всередині dangle, коли код dangle завершується,
s буде деалоковано. Але ми спробували повернути на нього посилання. Це
означає, що це посилання вказувало б на недійсний String. Це погано! Rust
не дозволить нам цього зробити.
Рішення тут — повертати String безпосередньо:
fn main() {
let string = no_dangle();
}
fn no_dangle() -> String {
let s = String::from("hello");
s
}Це працює без жодних проблем. Власність переміщується назовні, і нічого не деалокується.
Правила посилань (The Rules of References)
Підсумуймо те, що ми обговорили щодо посилань:
- У будь-який момент часу ви можете мати або одне змінне посилання, або будь-яку кількість незмінних посилань.
- Посилання завжди мають бути дійсними.
Далі ми розглянемо інший вид посилання: зрізи.
Тип зрізу (slice)
Тип зрізу (The Slice Type)
Зрізи (slices) дають змогу вам посилатися на неперервну послідовність елементів у колекції. Зріз — це вид посилання, тож він не має володіння.
Ось невелика програмна задача: напишіть функцію, яка приймає рядок слів, розділених пробілами, і повертає перше слово, яке вона знаходить у цьому рядку. Якщо функція не знаходить пробіл у рядку, увесь рядок має бути одним словом, тож повинно бути повернено весь рядок.
Примітка: Для цілей запровадження зрізів у цьому розділі ми припускаємо лише ASCII; більш ґрунтовне обговорення обробки UTF-8 є в розділі “Збереження кодування UTF-8 для тексту за допомогою рядків” Розділу 8.
Давайте розглянемо, як ми написали б сигнатуру цієї функції без використання зрізів, щоб зрозуміти проблему, яку зрізи розв’яжуть:
fn first_word(s: &String) -> ?Функція first_word має параметр типу &String. Нам не потрібна
володіння, тож це підходить. (В ідіоматичному Rust функції не беруть
володіння над своїми аргументами, якщо їм це не потрібно, і причини цього стануть
очевиднішими, коли ми рухатимемось далі.) Але що ми маємо повернути? У нас
справді немає способу говорити про частину рядка. Однак ми могли б повернути індекс
кінця слова, позначеного пробілом. Спробуймо це, як показано в Лістингу (Listing) 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Оскільки нам потрібно пройти через String по елементу й перевірити,
чи є значення пробілом, ми перетворимо наш String на масив байтів за допомогою
методу as_bytes.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Далі ми створюємо ітератор (iterator) над масивом байтів за допомогою методу iter:
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Ми докладніше обговоримо ітератори в Розділі 13.
Поки що знайте, що iter — це метод, який повертає кожен елемент у колекції,
а enumerate загортає результат iter і натомість повертає кожен елемент як
частину кортежу. Перший елемент кортежу, повернутого з enumerate, — це індекс,
а другий елемент — це посилання на елемент.
Це трохи зручніше, ніж обчислювати індекс самостійно.
Оскільки метод enumerate повертає кортеж, ми можемо використовувати шаблони для
деструктурування цього кортежу. Ми докладніше говоритимемо про шаблони в Розділі
6. У циклі for we вказуємо шаблон, у якому i
— це індекс у кортежі, а &item — це окремий байт у кортежі.
Оскільки ми отримуємо посилання на елемент з .iter().enumerate(), ми використовуємо
& у шаблоні.
Усередині циклу for ми шукаємо байт, який представляє пробіл, використовуючи
синтаксис байтового літерала. Якщо ми знаходимо пробіл, ми повертаємо позицію.
Інакше ми повертаємо довжину рядка, використовуючи s.len().
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Тепер ми маємо спосіб дізнатися індекс кінця першого слова в
рядку, але є проблема. Ми повертаємо сам по собі usize, але це
лише змістовне число в контексті &String. Іншими словами,
оскільки це окреме значення від String, немає гарантії, що воно
і надалі буде чинним. Розгляньте програму в Лістингу (Listing) 4-8, яка
використовує функцію first_word із Лістингу (Listing) 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // word will get the value 5
s.clear(); // this empties the String, making it equal to ""
// word still has the value 5 here, but s no longer has any content that we
// could meaningfully use with the value 5, so word is now totally invalid!
}Ця програма компілюється без жодних помилок і зробила б це також, якби ми використали word
після виклику s.clear(). Оскільки word зовсім не пов’язаний зі станом s,
word усе ще містить значення 5. Ми могли б використати це значення 5 із
змінною s, щоб спробувати витягти перше слово, але це була б помилка,
тому що вміст s змінився після того, як ми зберегли 5 у word.
Потрібність турбуватися про те, що індекс у word розсинхронізується з даними в
s, — це клопітно й схильне до помилок! Керування цими індексами ще більш крихке, якщо
ми напишемо функцію second_word. Її сигнатура мала б виглядати так:
fn second_word(s: &String) -> (usize, usize) {Тепер ми відстежуємо початковий і кінцевий індекс, і в нас є ще більше значень, які було обчислено з даних у певному стані, але які зовсім не прив’язані до цього стану. У нас є три непов’язані змінні, що «плавають» навколо, і їх треба підтримувати в синхронізації.
На щастя, у Rust є розв’язання цієї проблеми: рядкові зрізи.
Рядкові зрізи
Рядковий зріз (string slice) — це посилання на неперервну послідовність елементів
String, і він виглядає так:
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
}Замість посилання на весь String, hello — це посилання на
частину String, указаню додатковим фрагментом [0..5]. Ми створюємо зрізи,
використовуючи діапазон у квадратних дужках, указуючи
[starting_index..ending_index], де starting_index — це перша
позиція в зрізі, а ending_index — це на одиницю більше за останню позицію
в зрізі. Усередині структура даних зрізу зберігає початкову позицію
і довжину зрізу, яка відповідає ending_index мінус
starting_index. Отже, у випадку let world = &s[6..11];, world
буде зрізом, який містить вказівник на байт з індексом 6 у s із значенням
довжини 5.
Рисунок (Figure) 4-7 показує це на діаграмі.

Рисунок (Figure) 4-7: Рядковий зріз, що посилається на частину
String (A string slice referring to part of a String)
За допомогою синтаксису діапазонів Rust .., якщо ви хочете почати з індексу 0, ви можете
опустити значення перед двома крапками. Іншими словами, ці вирази рівні:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
}За тим самим принципом, якщо ваш зріз включає останній байт String, ви
можете опустити кінцеве число. Це означає, що ці вирази рівні:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[3..len];
let slice = &s[3..];
}Ви також можете опустити обидва значення, щоб узяти зріз усього рядка. Отже, ці вирази рівні:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
}Примітка: Індекси діапазону рядкового зрізу мають збігатися з допустимими межами символів UTF-8. Якщо ви спробуєте створити рядковий зріз посередині багатобайтного символу, ваша програма завершиться з помилкою.
Маючи всю цю інформацію, перепишімо first_word, щоб вона повертала
зріз. Тип, який позначає «рядковий зріз», записується як &str:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {}Ми отримуємо індекс кінця слова тим самим способом, що й у Лістингу (Listing) 4-7, — шукаючи перше входження пробілу. Коли ми знаходимо пробіл, ми повертаємо рядковий зріз, використовуючи початок рядка та індекс пробілу як початковий і кінцевий індекси.
Тепер, коли ми викликаємо first_word, ми отримуємо назад одне значення, яке пов’язане з
базовими даними. Це значення складається з посилання на початкову точку
зрізу та кількості елементів у зрізі.
Повернення зрізу також працювало б для функції second_word:
fn second_word(s: &String) -> &str {Тепер у нас є простий API, який набагато важче зламати, тому що
компілятор забезпечить, щоб посилання на String залишалися чинними.
Пам’ятаєте помилку в програмі з Лістингу (Listing) 4-8, коли ми отримали індекс до
кінця першого слова, а потім очистили рядок, тож наш індекс став недійсним?
Той код був логічно неправильним, але не показував негайних помилок. Проблеми
з’явилися б пізніше, якби ми продовжували намагатися використовувати індекс першого слова
з очищеним рядком. Зрізи роблять цю помилку неможливою і дають нам знати
значно раніше, що в нашому коді є проблема. Використання версії first_word
зі зрізом призведе до помилки під час компіляції:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {word}");
}Ось помилка компілятора:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {word}");
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Згадайте з правил запозичення, що якщо ми маємо незмінне посилання на
щось, ми не можемо також узяти змінне посилання. Оскільки clear потрібно
обрізати String, йому потрібно отримати змінне посилання. println!
після виклику clear використовує посилання в word, тож
незмінне посилання має все ще бути активним у цей момент. Rust не дозволяє
змінному посиланню в clear і незмінному посиланню в word існувати одночасно,
і компіляція завершується невдачею. Rust не лише зробив наш API простішим у використанні,
але й усунув цілий клас помилок під час компіляції!
Рядкові літерали як зрізи (String Literals Are Slices)
Згадайте, що ми говорили про те, що рядкові літерали зберігаються всередині бінарного файлу. Тепер, коли ми знаємо про зрізи, ми можемо правильно зрозуміти рядкові літерали:
#![allow(unused)]
fn main() {
let s = "Hello, world!";
}Тип s тут — &str: це зріз, який вказує на цю конкретну точку
бінарного файлу. Саме тому рядкові літерали є незмінними; &str — це
незмінне посилання.
Рядкові зрізи як параметри (String Slices as Parameters)
Знання того, що ви можете брати зрізи літералів і значень String, приводить нас
ще до одного поліпшення first_word, а саме до її сигнатури:
fn first_word(s: &String) -> &str {Більш досвідчений растацеанець (Rustacean) написав би сигнатуру, показану в Лістингу (Listing) 4-9,
замість цього, тому що вона дає змогу використовувати ту саму функцію як зі значеннями &String, так і зі
значеннями &str.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}Якщо в нас є рядковий зріз, ми можемо передати його безпосередньо. Якщо в нас є String, ми
можемо передати зріз String або посилання на String. Ця
гнучкість використовує переваги приведення типів через розіменування (deref coercions) — можливості, яку ми розглянемо в
розділі “Використання приведення типів через розіменування у функціях і методах (Using Deref Coercions with Functions and Methods)” Розділу 15.
Визначення функції, яка приймає рядковий зріз замість посилання на String,
робить наш API більш загальним і корисним, не втрачаючи жодної функціональності:
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}Інші зрізи (Other Slices)
Рядкові зрізи, як ви можете уявити, специфічні для рядків. Але є й більш загальний тип зрізу. Розгляньмо цей масив:
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
}Так само як ми можемо хотіти посилатися на частину рядка, ми можемо хотіти посилатися на частину масиву. Ми зробили б це так:
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
}Цей зріз має тип &[i32]. Він працює так само, як і рядкові зрізи, зберігаючи
посилання на перший елемент і довжину. Ви використовуватимете цей тип
зрізу для різноманітних інших колекцій. Ми докладно обговоримо ці колекції,
коли говоритимемо про вектори в Розділі 8.
Підсумок (Summary)
Поняття володіння, запозичення та зрізів забезпечують безпеку пам’яті в програмах Rust під час компіляції. Мова Rust дає вам контроль над використанням пам’яті так само, як і інші мови системного програмування. Але те, що власник даних автоматично очищає ці дані, коли власник виходить з області видимості, означає, що вам не потрібно писати й налагоджувати додатковий код, щоб отримати цей контроль.
Володіння впливає на те, як працює багато інших частин Rust, тож ми говоритимемо
про ці поняття далі протягом решти книги. Перейдімо до
Розділу 5 і подивімося на групування частин даних разом у struct.
Використання структур для структурування пов’язаних даних (Using Structs to Structure Related Data)
Структура (struct), або structure, — це користувацький тип даних, який дає змогу пакувати разом і називати кілька пов’язаних значень, що утворюють змістовну групу. Якщо ви знайомі з об’єктно-орієнтованою мовою, структура — це як атрибути даних об’єкта. У цьому розділі ми порівняємо й зіставимо кортежі зі структурами, щоб спиратися на те, що ви вже знаєте, і показати, коли структури є кращим способом групування даних.
Ми покажемо, як визначати й створювати екземпляри структур. Ми обговоримо, як визначати асоційовані функції (associated functions), особливо той вид асоційованих функцій, які називаються методами (methods), щоб задавати поведінку, пов’язану з типом структури. Структури та перелічення (enums) (розглянуті в Розділі 6) — це будівельні блоки для створення нових типів у домені вашої програми, щоб повною мірою скористатися перевіркою типів Rust під час компіляції.
Визначення та створення екземплярів структур
Визначення та створення екземплярів структур (Defining and Instantiating Structs)
Структури подібні до кортежів, про які йшлося в розділі “Тип кортежу”, тим, що обидва зберігають кілька пов’язаних значень. Як і кортежі, частини структури можуть мати різні типи. На відміну від кортежів, у структурі ви назвемо кожну частину даних, щоб було зрозуміло, що означають значення. Додавання цих назв означає, що структури є гнучкішими за кортежі: вам не потрібно покладатися на порядок даних, щоб визначати або отримувати доступ до значень екземпляра.
Щоб визначити структуру, ми вводимо ключове слово struct і називаємо всю структуру. Назва структури має описувати значущість частин даних, які групуються разом. Потім, усередині фігурних дужок, ми визначаємо назви та типи частин даних, які ми називаємо полями (fields). Наприклад, у Лістингу (Listing) 5-1 показано структуру, яка зберігає інформацію про обліковий запис користувача.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {}Щоб використати структуру після того, як ми її визначили, ми створюємо екземпляр (instance) цієї структури, вказуючи конкретні значення для кожного з полів. Ми створюємо екземпляр, називаючи структуру, а потім додаючи фігурні дужки, що містять пари key: value, де ключі — це назви полів, а значення — це дані, які ми хочемо зберігати в цих полях. Нам не потрібно вказувати поля в тому самому порядку, в якому ми оголосили їх у структурі. Іншими словами, визначення структури — це як загальний шаблон для типу, а екземпляри заповнюють цей шаблон конкретними даними, щоб створити значення типу. Наприклад, ми можемо оголосити конкретного користувача, як показано в Лістингу (Listing) 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
}Щоб отримати певне значення зі структури, ми використовуємо точкову нотацію. Наприклад, щоб отримати доступ до електронної адреси цього користувача, ми використовуємо user1.email. Якщо екземпляр є змінним, ми можемо змінити значення, використовуючи точкову нотацію і присвоюючи значення в конкретне поле. Лістинг (Listing) 5-3 показує, як змінити значення в полі email змінного екземпляра User.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let mut user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
}Зверніть увагу, що весь екземпляр має бути змінним; Rust не дозволяє нам позначати лише певні поля як змінні. Як і з будь-яким виразом, ми можемо побудувати новий екземпляр структури як останній вираз у тілі функції, щоб неявно повернути цей новий екземпляр.
Лістинг (Listing) 5-4 показує функцію build_user, яка повертає екземпляр User із заданими електронною адресою та ім’ям користувача. Поле active отримує значення true, а sign_in_count — значення 1.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username: username,
email: email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}Має сенс називати параметри функції так само, як і поля структури, але необхідність повторювати назви полів і змінних email та username дещо обтяжлива. Якби структура мала більше полів, повторення кожної назви стало б ще більш набридливим. На щастя, є зручне скорочення!
Використання скороченого синтаксису ініціалізації полів (Using the Field Init Shorthand)
Оскільки в Лістингу (Listing) 5-4 імена параметрів і імена полів структури є точно однаковими, ми можемо використати синтаксис скороченого синтаксису ініціалізації полів для переписування build_user так, щоб вона поводилася точно так само, але без повторення username і email, як показано в Лістингу (Listing) 5-5.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username,
email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}Тут ми створюємо новий екземпляр структури User, яка має поле з назвою email. Ми хочемо встановити значення поля email у значення параметра email функції build_user. Оскільки поле email і параметр email мають однакову назву, нам потрібно лише написати email, а не email: email.
Створення екземплярів за допомогою синтаксису оновлення структури (Creating Instances from Other Instances with Struct Update Syntax)
Часто корисно створити новий екземпляр структури, який включає більшість значень з іншого екземпляра того самого типу, але змінює деякі з них. Ви можете зробити це, використовуючи синтаксис оновлення структури.
Спочатку, у Лістингу (Listing) 5-6 ми покажемо, як створити новий екземпляр User у user2 звичайним способом, без синтаксису оновлення. Ми встановлюємо нове значення для email, але в іншому використовуємо ті самі значення з user1, які ми створили в Лістингу (Listing) 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// --snip--
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
}Використовуючи синтаксис оновлення структури, ми можемо досягти того самого ефекту з меншим обсягом коду, як показано в Лістингу (Listing) 5-7. Синтаксис .. указує, що решта полів, які не встановлено явно, мають мати ті самі значення, що й поля в заданому екземплярі.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// --snip--
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
email: String::from("another@example.com"),
..user1
};
}Код у Лістингу (Listing) 5-7 також створює екземпляр у user2, який має інше значення для email, але має ті самі значення для полів username, active і sign_in_count з user1. ..user1 має бути останнім, щоб указати, що будь-які решта полів мають отримати свої значення з відповідних полів у user1, але ми можемо обрати вказати значення для будь-якої кількості полів у будь-якому порядку, незалежно від порядку полів у визначенні структури.
Зверніть увагу, що синтаксис оновлення структури використовує = як присвоювання; це тому, що він переміщує дані, так само як ми бачили в розділі “Змінні та дані, що взаємодіють із переміщенням”. У цьому прикладі ми більше не можемо використовувати user1 після створення user2, тому що String у полі username з user1 було переміщено в user2. Якби ми надали user2 нові значення String для обох полів email і username, і таким чином використали б лише значення active і sign_in_count з user1, тоді user1 усе ще був би дійсним після створення user2. І active, і sign_in_count — це типи, які реалізують трейт Copy, тому поведінка, яку ми обговорювали в розділі “Дані лише у стеку: Copy”, буде застосовуватися. Ми також усе ще можемо використовувати user1.email у цьому прикладі, тому що його значення не було переміщено з user1.
Створення різних типів за допомогою кортежних структур (Using Tuple Structs without Named Fields to Create Different Types)
Rust також підтримує структури, які виглядають подібно до кортежів, що називаються кортежними структурами (tuple structs). Кортежні структури мають додаткове значення, яке надає назва структури, але не мають назв, пов’язаних із їхніми полями; натомість вони просто мають типи полів. Кортежні структури корисні, коли ви хочете надати всьому кортежу назву і зробити кортеж іншим типом від інших кортежів, а також коли називати кожне поле, як у звичайній структурі, було б багатослівно або надлишково.
Щоб визначити кортежну структуру, почніть із ключового слова struct і назви структури, після чого вкажіть типи в кортежі. Наприклад, тут ми визначаємо та використовуємо дві кортежні структури з назвами Color і Point:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
}Зверніть увагу, що значення black і origin мають різні типи, тому що це екземпляри різних кортежних структур. Кожна визначена вами структура є окремим типом, навіть якщо поля всередині структури можуть мати ті самі типи. Наприклад, функція, яка приймає параметр типу Color, не може приймати Point як аргумент, навіть якщо обидва типи складаються з трьох значень i32. В іншому випадку екземпляри кортежних структур подібні до кортежів тим, що ви можете розпакувати їх на окремі частини, і ви можете використовувати . із наступним індексом, щоб отримати доступ до окремого значення. На відміну від кортежів, кортежні структури вимагають, щоб ви назвали тип структури, коли розпаковуєте їх. Наприклад, ми б написали let Point(x, y, z) = origin;, щоб розпакувати значення в точці origin у змінні з назвами x, y і z.
Визначення одноподібних структур (Defining Unit-Like Structs without Any Fields)
Ви також можете визначати структури, які не мають жодних полів! Вони називаються одноподібними структурами (unit-like structs), тому що поводяться подібно до (), типу одиниці, про який ми згадували в розділі “Тип кортежу”. Одноподібні структури можуть бути корисними, коли вам потрібно реалізувати трейт для якогось типу, але ви не маєте жодних даних, які хочете зберігати в самому типі. Ми обговоримо трейти в Розділі 10. Ось приклад оголошення і створення екземпляра одноподібної структури з назвою AlwaysEqual:
struct AlwaysEqual;
fn main() {
let subject = AlwaysEqual;
}Щоб визначити AlwaysEqual, ми використовуємо ключове слово struct, назву, яку хочемо, а потім крапку з комою. Не потрібно жодних фігурних дужок або круглих дужок! Потім ми можемо отримати екземпляр AlwaysEqual у змінній subject подібним способом: використовуючи назву, яку ми визначили, без будь-яких фігурних дужок або круглих дужок. Уявіть, що пізніше ми реалізуємо поведінку для цього типу так, що кожен екземпляр AlwaysEqual завжди дорівнює кожному екземпляру будь-якого іншого типу, можливо, щоб мати відомий результат для цілей тестування. Нам не потрібні були б жодні дані, щоб реалізувати таку поведінку! У Розділі 10 ви побачите, як визначати трейти і реалізовувати їх для будь-якого типу, включно з одноподібними структурами.
У визначенні структури
Userу Лістингу (Listing) 5-1 ми використовували типString, що володіє даними, а не тип рядкового зрізу&str. Це свідомий вибір, тому що ми хочемо, щоб кожен екземпляр цієї структури володів усіма своїми даними і щоб ці дані були дійсними доти, доки дійсна вся структура.Також можливо, щоб структури зберігали посилання на дані, які належать чомусь іншому, але для цього потрібно використати часи життя (lifetimes), особливість Rust, яку ми обговоримо в Розділі 10. Часи життя гарантують, що дані, на які посилається структура, є дійсними доти, доки дійсна структура. Припустімо, ви намагаєтеся зберегти посилання в структурі без указання часів життя, як у наведеному нижче в src/main.rs; це не спрацює:
struct User { active: bool, username: &str, email: &str, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: "someusername123", email: "someone@example.com", sign_in_count: 1, }; }Компілятор скаржитиметься, що йому потрібні специфікатори часу життя:
$ cargo run Compiling structs v0.1.0 (file:///projects/structs) error[E0106]: missing lifetime specifier --> src/main.rs:3:15 | 3 | username: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 ~ username: &'a str, | error[E0106]: missing lifetime specifier --> src/main.rs:4:12 | 4 | email: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 | username: &str, 4 ~ email: &'a str, | For more information about this error, try `rustc --explain E0106`. error: could not compile `structs` (bin "structs") due to 2 previous errorsУ Розділі 10 ми обговоримо, як виправити ці помилки, щоб ви могли зберігати посилання в структурах, але наразі ми виправлятимемо такі помилки, використовуючи типи, що володіють даними (owned types), як-от
String, замість посилань, як-от&str.
Приклад програми з використанням структур
Приклад програми з використанням структур (An Example Program Using Structs)
Щоб зрозуміти, коли ми можемо захотіти використати структури, давайте напишемо програму, яка обчислює площу прямокутника. Ми почнемо з використання окремих змінних, а потім переробимо програму так, щоб замість цього використовувати структури.
Давайте створимо новий двійковий проєкт за допомогою Cargo під назвою rectangles, який братиме ширину та висоту прямокутника, задані в пікселях, і обчислюватиме площу прямокутника. У Лістингу (Listing) 5-8 показано коротку програму з одним способом зробити саме це в нашому проєкті src/main.rs.
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}Тепер запустіть цю програму за допомогою cargo run:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
Цей код успішно визначає площу прямокутника, викликаючи функцію area з кожним виміром, але ми можемо зробити більше, щоб цей код був чітким і читабельним.
Проблема цього коду очевидна в сигнатурі area:
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}Функція area має обчислювати площу одного прямокутника, але функція, яку ми написали, має два параметри, і ніде в нашій програмі не зрозуміло, що ці параметри пов’язані між собою. Було б читабельніше й зручніше для супроводу згрупувати ширину та висоту разом. Ми вже обговорювали один спосіб, як ми могли б це зробити, у розділі 3: за допомогою кортежів.
Переробка з кортежами (Refactoring with Tuples)
У Лістингу (Listing) 5-9 показано іншу версію нашої програми, яка використовує кортежі.
fn main() {
let rect1 = (30, 50);
println!(
"The area of the rectangle is {} square pixels.",
area(rect1)
);
}
fn area(dimensions: (u32, u32)) -> u32 {
dimensions.0 * dimensions.1
}У певному сенсі ця програма краща. Кортежі дають нам змогу додати трохи структури, і тепер ми передаємо лише один аргумент. Але в іншому сенсі ця версія менш зрозуміла: кортежі не називають свої елементи, тому нам доводиться індексувати частини кортежа, що робить наш обчислення менш очевидним.
Плутанина між шириною та висотою не мала б значення для обчислення площі, але якщо ми хочемо намалювати прямокутник на екрані, це було б важливо! Нам довелося б пам’ятати, що width — це індекс кортежа 0, а height — це індекс кортежа 1. Комусь іншому було б ще важче це зрозуміти й тримати в пам’яті, якби він або вона захотіли використати наш код. Оскільки ми не передали зміст наших даних у нашому коді, тепер легше ввести помилки.
Переробка зі структурами (Refactoring with Structs: Adding More Meaning)
Ми використовуємо структури, щоб додати зміст шляхом маркування даних. Ми можемо перетворити кортеж, який використовуємо, на структуру з назвою для цілого, а також назвами для частин, як показано в Лістингу (Listing) 5-10.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"The area of the rectangle is {} square pixels.",
area(&rect1)
);
}
fn area(rectangle: &Rectangle) -> u32 {
rectangle.width * rectangle.height
}Тут ми визначили структуру й назвали її Rectangle. Усередині фігурних дужок ми визначили поля як width і height, обидва з типом u32. Потім у main ми створили конкретний екземпляр Rectangle, який має ширину 30 і висоту 50.
Наша функція area тепер визначена з одним параметром, який ми назвали rectangle, чий тип є незмінним запозиченням екземпляра структури Rectangle. Як ми обговорювали в розділі 4, ми хочемо запозичити структуру, а не брати її у володіння. Таким чином main зберігає володіння і може продовжувати використовувати rect1, через що ми використовуємо & у сигнатурі функції та там, де викликаємо функцію.
Функція area отримує доступ до полів width і height екземпляра Rectangle (зверніть увагу, що доступ до полів запозиченого екземпляра структури не переміщує значення полів, саме тому ви часто бачите запозичення структур). Наша сигнатура функції для area тепер точно каже те, що ми маємо на увазі: обчислити площу Rectangle, використовуючи його поля width і height. Це передає, що width і height пов’язані між собою, і дає описові назви значенням замість використання значень індексів кортежа 0 і 1. Це виграш для ясності.
Додавання корисної функціональності за допомогою виведених трейтів (Adding Useful Functionality with Derived Traits)
Було б корисно мати змогу надрукувати екземпляр Rectangle, коли ми налагоджуємо нашу програму, і побачити значення всіх його полів. У Лістингу (Listing) 5-11 спробовано використати макрос (macro) println!, як ми вже робили в попередніх розділах. Однак це не спрацює.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1}");
}Коли ми компілюємо цей код, отримуємо помилку з таким основним повідомленням:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
Макрос println! може виконувати багато видів форматування, і за замовчуванням фігурні дужки вказують println! використовувати форматування, відоме як Display: вивід, призначений для безпосереднього споживання кінцевим користувачем. Примітивні типи, які ми бачили досі, реалізують Display за замовчуванням, тому що є лише один спосіб, яким ви хотіли б показати 1 або будь-який інший примітивний тип користувачеві. Але зі структурами спосіб, у який println! має форматувати вивід, менш очевидний, тому що є більше варіантів відображення: чи потрібні коми? Чи потрібно друкувати фігурні дужки? Чи мають бути показані всі поля? Через цю неоднозначність Rust не намагається вгадати, чого ми хочемо, і структури не мають наданої реалізації Display, яку можна використати з println! і заповнювачем {}.
Якщо ми продовжимо читати помилки, то знайдемо таку корисну примітку:
| |`Rectangle` cannot be formatted with the default formatter
| required by this formatting parameter
Спробуймо це! Виклик макроса println! тепер виглядатиме так: println!("rect1 is {rect1:?}");. Розміщення специфікатора :? всередині фігурних дужок повідомляє
println!, що ми хочемо використати формат виводу, який називається Debug. Трейт (trait) Debug дає нам змогу друкувати нашу структуру так, щоб це було корисно для розробників, аби ми могли бачити її значення під час налагодження нашого коду.
Скомпілюйте код із цією зміною. От халепа! Ми все ще отримуємо помилку:
error[E0277]: `Rectangle` doesn't implement `Debug`
Але знову компілятор дає нам корисну примітку:
| required by this formatting parameter
|
Rust дійсно включає функціональність для виведення діагностичної інформації, але нам потрібно явно увімкнути цю функціональність, щоб вона стала доступною для нашої структури. Для цього ми додаємо зовнішній атрибут #[derive(Debug)] безпосередньо перед визначенням структури, як показано в Лістингу 5-12.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1:?}");
}Тепер, коли ми запустимо програму, ми не отримаємо жодних помилок і побачимо такий вивід:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
Чудово! Це не найгарніший вивід, але він показує значення всіх полів цього екземпляра, що безумовно допомогло б під час налагодження. Коли ми маємо більші структури, корисно мати вивід, який трохи легше читати; у таких випадках ми можемо використовувати {:#?} замість {:?} у рядку println!. У цьому прикладі використання стилю {:#?} виведе таке:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
Інший спосіб надрукувати значення, використовуючи формат Debug, — застосувати макрос (macro) dbg!, який бере у володіння вираз (на відміну від println!, який бере посилання), друкує ім’я файлу та номер рядка, де виклик цього макроса dbg! відбувається у вашому коді, разом із результативним значенням цього виразу, і повертає володіння значення.
Примітка: виклик макроса
dbg!друкує в консольний потік стандартної помилки (stderr), на відміну відprintln!, який друкує в консольний потік стандартного виводу (stdout). Ми докладніше говоритимемо проstderrіstdoutу розділі “Redirecting Errors to Standard Error” розділу 12.
Ось приклад, у якому нас цікавить значення, призначене полю width, а також значення всього структури в rect1:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}Ми можемо обгорнути dbg! навколо виразу 30 * scale і, оскільки dbg! повертає володіння значення виразу, поле width отримає те саме значення, ніби виклику dbg! там не було. Ми не хочемо, щоб dbg! брав у володіння rect1, тому в наступному виклику ми використовуємо посилання на rect1. Ось як виглядає вивід цього прикладу:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * scale = 60
[src/main.rs:14:5] &rect1 = Rectangle {
width: 60,
height: 50,
}
Ми можемо побачити, що перша частина виводу походить із src/main.rs рядка 10, де ми налагоджуємо вираз 30 * scale, і його результативне значення дорівнює 60 (форматування Debug, реалізоване для цілих чисел, полягає в друкуванні лише їх значення). Виклик dbg! у рядку 14 src/main.rs виводить значення &rect1, яке є структурою Rectangle. Цей вивід використовує красиве форматування Debug типу Rectangle. Макрос dbg! може бути справді корисним, коли ви намагаєтеся з’ясувати, що робить ваш код!
Окрім трейту Debug, Rust надав нам низку трейтів для використання з атрибутом derive, які можуть додати корисну поведінку нашим власним типам. Ці трейти та їхня поведінка перелічені в Додатку C. Ми розглянемо, як реалізовувати ці трейти з власною поведінкою, а також як створювати власні трейти, у розділі 10. Також існує багато інших атрибутів, окрім derive; для отримання додаткової інформації дивіться розділ “Attributes” у Rust Reference.
Наша функція area дуже специфічна: вона лише обчислює площу прямокутників. Було б корисно тісніше пов’язати цю поведінку з нашою структурою Rectangle, тому що вона не працюватиме з жодним іншим типом. Давайте подивимося, як ми можемо продовжити переробку цього коду, перетворивши функцію area на метод area, визначений для нашого типу Rectangle.
Методи
Методи
Методи подібні до функцій: Ми оголошуємо їх за допомогою ключового слова fn і
імені, вони можуть мати параметри та значення, що повертається, і вони містять код,
який виконується, коли метод викликається звідкись іще. На відміну від функцій,
методи визначаються в контексті структури (або перелічення (enum), або об’єкта трейту (trait object),
що ми розглядаємо в Розділі 6 та Розділі
18 відповідно), і їхній перший параметр завжди
self, який представляє екземпляр структури, для якого викликається метод.
Синтаксис методів
Давайте змінимо функцію area, яка має екземпляр Rectangle як параметр,
і натомість зробимо методом area, визначеним для структури Rectangle, як показано
в Лістингу 5-13.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"The area of the rectangle is {} square pixels.",
rect1.area()
);
}Щоб визначити функцію в контексті Rectangle, ми починаємо блок impl
(реалізація) для Rectangle. Усе в межах цього блоку impl
буде пов’язане з типом Rectangle. Потім ми переміщуємо функцію area
всередину фігурних дужок impl і змінюємо перший (і в цьому випадку єдиний)
параметр на self у сигнатурі та всюди в тілі. У main, де ми викликали
функцію area і передавали rect1 як аргумент,
ми можемо натомість використати синтаксис методів, щоб викликати метод area на нашому
екземплярі Rectangle. Синтаксис методів іде після екземпляра: Ми додаємо крапку, за якою
йде ім’я методу, круглі дужки та будь-які аргументи.
У сигнатурі для area ми використовуємо &self замість rectangle: &Rectangle.
&self насправді є скороченням для self: &Self. Усередині блоку impl
тип Self є псевдонімом для типу, для якого призначений блок impl. Методи повинні
мати параметр на ім’я self типу Self як свій перший параметр, тому Rust
дозволяє скоротити це, використовуючи лише ім’я self у першій позиції параметра.
Зверніть увагу, що нам усе ще потрібно використовувати & перед скороченням self, щоб
позначити, що цей метод запозичує екземпляр Self, так само як ми робили в
rectangle: &Rectangle. Методи можуть брати володіння на self, запозичувати self
незмінно, як ми зробили тут, або запозичувати self змінно, так само як і будь-який
інший параметр.
Ми вибрали тут &self з тієї ж причини, з якої використовували &Rectangle у
версії функції: Ми не хочемо брати володіння, і ми лише хочемо читати дані в
структурі, а не записувати в них. Якби ми хотіли змінити екземпляр, на якому ми
викликали метод, як частину того, що робить метод, ми б використали &mut self як
перший параметр. Мати метод, який бере володіння на екземпляр, використовуючи лише
self як перший параметр, трапляється рідко; цю техніку зазвичай
використовують, коли метод перетворює self на щось інше, і ви хочете
заборонити викликачу використовувати оригінальний екземпляр після перетворення.
Головна причина використовувати методи замість функцій, окрім
надання синтаксису методів і відсутності потреби повторювати тип self у сигнатурі кожного
методу, — це організація. Ми зібрали все, що можемо робити
з екземпляром типу, в одному блоці impl, а не змушуємо майбутніх користувачів
нашого коду шукати можливості Rectangle у різних місцях у
бібліотеці, яку ми надаємо.
Зверніть увагу, що ми можемо дати методу те саме ім’я, що й одному з полів структури.
Наприклад, ми можемо визначити метод для Rectangle, який також називається width:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn width(&self) -> bool {
self.width > 0
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
if rect1.width() {
println!("The rectangle has a nonzero width; it is {}", rect1.width);
}
}Тут ми вирішуємо зробити так, щоб метод width повертав true, якщо значення в
полі width екземпляра більше за 0, і false, якщо значення дорівнює
0: Ми можемо використовувати поле всередині методу з тим самим іменем для будь-якої мети. У
main, коли ми додаємо круглі дужки після rect1.width, Rust знає, що ми маємо на увазі
метод width. Коли ми не використовуємо круглі дужки, Rust знає, що ми маємо на увазі поле
width.
Часто, але не завжди, коли ми даємо методу те саме ім’я, що й поле, ми хочемо, щоб він лише повертав значення поля і більше нічого не робив. Такі методи називаються гетерами, і Rust не реалізує їх автоматично для полів структури, як це роблять деякі інші мови. Гетери корисні, тому що ви можете зробити поле приватним, але метод — публічним і таким чином надати доступ лише для читання до цього поля як частини публічного API типу. Ми обговоримо, що таке публічне і приватне та як позначити поле або метод як публічний чи приватний у Розділі 7.
Де оператор
->?У C і C++, для виклику методів використовуються два різні оператори: Ви використовуєте
.якщо викликаєте метод безпосередньо на об’єкті, і->якщо ви викликаєте метод на вказівнику на об’єкт і спочатку потрібно розіменувати вказівник. Іншими словами, якщоobject— це вказівник,object->something()подібне до(*object).something().У Rust немає еквівалента оператору
->; натомість у Rust є можливість, яка називається автоматичне посилання та розіменування. Виклик методів — одне з небагатьох місць у Rust із такою поведінкою.Ось як це працює: Коли ви викликаєте метод за допомогою
object.something(), Rust автоматично додає&,&mutабо*, щобobjectвідповідав сигнатурі методу. Іншими словами, наведене нижче є однаковим:#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn distance(&self, other: &Point) -> f64 { let x_squared = f64::powi(other.x - self.x, 2); let y_squared = f64::powi(other.y - self.y, 2); f64::sqrt(x_squared + y_squared) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.distance(&p2); (&p1).distance(&p2); }Перше виглядає значно охайніше. Така автоматична поведінка посилання працює тому, що методи мають чіткий одержувач — тип
self. Маючи одержувача та ім’я методу, Rust може безпомилково визначити, чи метод читає (&self), змінює (&mut self) або споживає (self). Той факт, що Rust робить запозичення неявним для одержувачів методів, — велика частина того, що робить володіння ергономічною на практиці.
Методи з більшою кількістю параметрів
Давайте попрактикуємося у використанні методів, реалізувавши другий метод для структури Rectangle.
Цього разу ми хочемо, щоб екземпляр Rectangle приймав інший екземпляр
Rectangle і повертав true, якщо другий Rectangle може повністю поміститися
всередині self (першого Rectangle); інакше він повинен повертати false.
Тобто, після того як ми визначимо метод can_hold, ми хочемо мати змогу написати
програму, показану в Лістингу 5-14.
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}Очікуваний вивід виглядав би так, як наведено нижче, тому що обидва виміри
rect2 менші за виміри rect1, але rect3 ширший за
rect1:
Can rect1 hold rect2? true
Can rect1 hold rect3? false
Ми знаємо, що хочемо визначити метод, отже він буде в блоці impl Rectangle.
Ім’я методу буде can_hold, і він прийматиме незмінне запозичення
іншого Rectangle як параметр. Ми можемо зрозуміти, яким буде тип
параметра, подивившись на код, що викликає метод:
rect1.can_hold(&rect2) передає &rect2, яке є незмінним запозиченням rect2, екземпляра Rectangle.
Це має сенс, тому що нам потрібно лише читати rect2 (а не записувати, що означало б, що нам знадобиться змінне запозичення),
і ми хочемо, щоб main зберіг володіння над rect2, щоб ми могли використати його знову
після виклику методу can_hold. Значення, що повертається can_hold, буде логічним, а реалізація перевірятиме, чи ширина і висота
self більші за ширину і висоту іншого Rectangle
відповідно. Давайте додамо новий метод can_hold до блоку impl із
Лістингу 5-13, показаного в Лістингу 5-15.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}Коли ми запустимо цей код із функцією main з Лістингу 5-14, ми отримаємо бажаний
вивід. Методи можуть приймати кілька параметрів, які ми додаємо до
сигнатури після параметра self, і ці параметри працюють так само, як
параметри у функціях.
Асоційовані функції
Усі функції, визначені в блоці impl, називаються асоційованими функціями
тому що вони пов’язані з типом, названим після impl. Ми можемо визначати
асоційовані функції, які не мають self як свій перший параметр (і отже
не є методами), тому що їм не потрібен екземпляр типу, з яким працювати.
Ми вже використали одну таку функцію: функцію String::from, яка
визначена для типу String.
Асоційовані функції, які не є методами, часто використовуються як конструктори, що
повертатимуть новий екземпляр структури. Їх часто називають new, але
new — не спеціальне ім’я і не вбудоване в мову. Наприклад, ми
могли б вирішити надати асоційовану функцію з назвою square, яка мала б
один параметр розміру та використовувала б його і як ширину, і як висоту, таким чином полегшуючи
створення квадратної Rectangle замість того, щоб указувати одне й те саме
значення двічі:
Filename: src/main.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn square(size: u32) -> Self {
Self {
width: size,
height: size,
}
}
}
fn main() {
let sq = Rectangle::square(3);
}Ключові слова Self у типі, що повертається, та в тілі функції
є псевдонімами для типу, який стоїть після ключового слова impl, яким у цьому випадку
є Rectangle.
Щоб викликати цю асоційовану функцію, ми використовуємо синтаксис :: з назвою структури;
let sq = Rectangle::square(3); — це приклад. Ця функція має простір імен структури: Синтаксис :: використовується як для асоційованих функцій, так і для
просторів імен, створених модулями. Ми обговоримо модулі в Розділі
7.
Кілька блоків impl
Кожна структура може мати кілька блоків impl. Наприклад, Лістинг
5-15 еквівалентний коду, показаному в Лістингу 5-16, який має кожен метод у
власному блоці impl.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}це допустимий синтаксис. Ми побачимо випадок, у якому кілька блоків impl є
корисними, у Розділі 10, де ми обговорюємо узагальнені типи та трейти.
Підсумок
Структури дають змогу створювати власні типи, які мають значення для вашої предметної області. Використовуючи
структури, ви можете тримати пов’язані частини даних разом
і називати кожну частину, щоб зробити ваш код зрозумілим. У блоках impl ви можете визначати
функції, пов’язані з вашим типом, а методи — це різновид
асоційованої функції, який дає змогу вам визначати поведінку, яку мають екземпляри ваших
структур.
Але структури — не єдиний спосіб створювати власні типи: Давайте звернемося до можливості перелічень (enums) у Rust, щоб додати ще один інструмент до вашого набору інструментів.
Перелічення та зіставлення зі зразком (Enums and Pattern Matching)
У цьому розділі ми розглянемо перелічення, також відомі як enum.
Перелічення (Enums) дають змогу визначити тип, перелічуючи його можливі варіанти. Спочатку
ми визначимо та використаємо перелічення (enum), щоб показати, як перелічення (enum) може кодувати значення разом із
даними. Далі ми дослідимо особливо корисне перелічення (enum) під назвою Option, яке
виражає, що значення може бути або чимось, або нічим. Потім ми розглянемо,
як зіставлення зі зразком у виразі match робить простим запуск різного
коду для різних значень перелічення (enum). Нарешті, ми охопимо, як конструкція if let
є ще однією зручною та стислою ідіомою, доступною для обробки перелічень (enums) у
вашому коді.
Визначення переліку
Визначення перелічення (Defining an Enum)
Там, де структури дають вам спосіб групувати пов’язані поля та дані, як-от
Rectangle з його width і height, перелічення (enum) дають вам спосіб сказати, що
значення є одним із можливого набору значень. Наприклад, ми можемо захотіти
сказати, що Rectangle є одним із набору можливих фігур, до якого також входять
Circle і Triangle. Щоб зробити це, Rust дозволяє нам кодувати ці можливості
як перелічення (enum).
Давайте подивимося на ситуацію, яку ми могли б виразити в коді, і побачимо, чому перелічення (enum) корисніші та доречніші за структури в цьому випадку. Припустімо, нам потрібно працювати з IP-адресами. Наразі для IP-адрес використовуються два основні стандарти: версія чотири і версія шість. Оскільки це єдині можливості для IP-адреси, з якими зіткнеться наша програма, ми можемо перелічити всі можливі варіанти, звідси й походить назва перелічення (enum).
Будь-яка IP-адреса може бути або адресою версії чотири, або адресою версії шість, але не обома одночасно. Ця властивість IP-адрес робить структуру даних перелічення доречною, тому що значення перелічення може быть лише одним із його варіантів. І адреси версії чотири, і адреси версії шість все ще є, по суті, IP-адресами, тому їх слід розглядати як один і той самий тип, коли код опрацьовує ситуації, що стосуються будь-якого виду IP-адреси.
Ми можемо виразити цю концепцію в коді, визначивши перелічення IpAddrKind і
перелічивши можливі види, якими може бути IP-адреса, V4 і V6. Це варіанти
перелічення:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}IpAddrKind тепер є власним типом даних, який ми можемо використовувати в іншому
місці нашого коду.
Значення перелічень
Ми можемо створити екземпляри кожного з двох варіантів IpAddrKind ось так:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Зверніть увагу, що варіанти перелічення перебувають у просторі імен свого
ідентифікатора, і ми використовуємо подвійне двокрап’я, щоб розділити ці два
елементи. Це корисно, тому що тепер обидва значення IpAddrKind::V4 і
IpAddrKind::V6 мають один і той самий тип: IpAddrKind. Після цього ми можемо,
наприклад, визначити функцію, яка приймає будь-який IpAddrKind:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}І ми можемо викликати цю функцію з будь-яким із варіантів:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Використання перелічень має ще більше переваг. Якщо подумати ще раз про наш тип IP-адреси, зараз у нас немає способу зберегти фактичні дані IP-адреси; ми знаємо лише, який це вид. Враховуючи, що ви щойно дізналися про структури в Розділі 5, у вас може виникнути спокуса розв’язати цю проблему за допомогою структур, як показано у Лістингу 6-1.
fn main() {
enum IpAddrKind {
V4,
V6,
}
struct IpAddr {
kind: IpAddrKind,
address: String,
}
let home = IpAddr {
kind: IpAddrKind::V4,
address: String::from("127.0.0.1"),
};
let loopback = IpAddr {
kind: IpAddrKind::V6,
address: String::from("::1"),
};
}Тут ми визначили структуру IpAddr, яка має два поля: поле kind, що має тип
IpAddrKind (перелічення, яке ми визначили раніше), і поле address типу
String. У нас є два екземпляри цієї структури. Перший — home, і він має
значення IpAddrKind::V4 як своє kind із пов’язаними даними адреси
127.0.0.1. Другий екземпляр — loopback. Він має інший варіант IpAddrKind
як значення свого kind, V6, і має пов’язану з ним адресу ::1. Ми
використали структуру, щоб об’єднати значення kind і address разом, тож
тепер варіант пов’язаний зі значенням.
Однак подати ту саму концепцію, використовуючи лише перелічення, лаконічніше: Замість
перелічення всередині структури ми можемо помістити дані безпосередньо в кожен
варіант перелічення. Це нове визначення перелічення IpAddr каже, що і варіант V4,
і варіант V6 матимуть пов’язані значення String:
fn main() {
enum IpAddr {
V4(String),
V6(String),
}
let home = IpAddr::V4(String::from("127.0.0.1"));
let loopback = IpAddr::V6(String::from("::1"));
}Ми приєднуємо дані до кожного варіанта перелічення безпосередньо, тож додаткова
структура не потрібна. Тут також легше побачити ще одну деталь того, як
працюють перелічення: Назва кожного визначеного нами варіанта перелічення також стає
функцією, яка створює екземпляр перелічення. Тобто IpAddr::V4() — це виклик
функції, який приймає аргумент String і повертає екземпляр типу IpAddr. Ми
автоматично отримуємо визначення цієї функції-конструктора як результат
визначення перелічення.
Є ще одна перевага використання перелічення замість структури: Кожен варіант може
мати різні типи та обсяги пов’язаних даних. IP-адреси версії чотири завжди
матимуть чотири числові компоненти, значення яких будуть між 0 і 255. Якби ми
хотіли зберігати адреси V4 як чотири значення u8, але все ще подавати
адреси V6 як одне значення String, ми не змогли б зробити це за допомогою
структури. Перелічення легко справляються з цим випадком:
fn main() {
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
let home = IpAddr::V4(127, 0, 0, 1);
let loopback = IpAddr::V6(String::from("::1"));
}Ми показали кілька різних способів визначення структур даних для зберігання
IP-адрес версії чотири та версії шість. Однак, як виявляється, бажання
зберігати IP-адреси й кодувати, до якого виду вони належать, настільки поширене,
що стандартна бібліотека має визначення, яке ми можемо використати! Давайте подивимося, як стандартна бібліотека визначає IpAddr.
Вона має точнісінько той самий перелічення і ті самі варіанти, які ми визначили та
використали, але вона вбудовує дані адреси всередину варіантів у формі двох
різних структур, які визначені по-різному для кожного варіанта:
#![allow(unused)]
fn main() {
struct Ipv4Addr {
// --snip--
}
struct Ipv6Addr {
// --snip--
}
enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
}Цей код ілюструє, що ви можете помістити будь-який вид даних усередину варіанта перелічення: наприклад, рядки, числові типи або структури. Ви навіть можете включити інше перелічення! Також типи стандартної бібліотеки часто не набагато складніші за те, що могли б придумати ви.
Зверніть увагу, що хоча стандартна бібліотека містить визначення для IpAddr, ми
все ще можемо створити та використовувати власне визначення без конфлікту,
оскільки ми ще не ввели визначення стандартної бібліотеки до нашої області
видимості. Ми ще поговоримо про введення типів в область видимості в Розділі 7.
Давайте подивимося на інший приклад перелічення у Лістингу 6-2: У ньому є широкий спектр типів, вбудованих у його варіанти.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}Це перелічення має чотири варіанти з різними типами:
Quit: Не має жодних пов’язаних данихMove: Має іменовані поля, як і структураWrite: Містить одинStringChangeColor: Містить три значенняi32
Визначення перелічення з такими варіантами, як у Лістингу 6-2, схоже на
визначення різних видів структур, за винятком того, що перелічення не використовує
ключове слово struct, і всі варіанти згруповані разом під типом Message.
Такі структури могли б зберігати ті самі дані, що й попередні варіанти перелічення:
struct QuitMessage; // unit struct
struct MoveMessage {
x: i32,
y: i32,
}
struct WriteMessage(String); // tuple struct
struct ChangeColorMessage(i32, i32, i32); // tuple struct
fn main() {}не змогли б так само легко визначити функцію, яка приймає будь-який із цих видів
повідомлень, як ми могли б із визначеним у Лістингу 6-2 переліченням Message, яке
є одним типом.
Є ще одна схожість між переліченнями та структурами: Так само як ми можемо
визначати методи для структур за допомогою impl, ми також можемо визначати
методи для перелічень. Ось метод під назвою call, який ми могли б визначити для
нашого перелічення Message:
fn main() {
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
impl Message {
fn call(&self) {
// method body would be defined here
}
}
let m = Message::Write(String::from("hello"));
m.call();
}Тіло методу використовувало б self, щоб отримати значення, для якого ми
викликали метод. У цьому прикладі ми створили змінну m, яка має значення
Message::Write(String::from("hello")), і саме це значення буде в self у
тілі методу call, коли виконується m.call().
Давайте подивимося на ще одне перелічення в стандартній бібліотеці, яке є дуже
поширеним і корисним: Option.
Перелічення Option
Цей розділ досліджує приклад Option, яке є ще одним переліченням, визначеним
стандартною бібліотекою. Тип Option кодує дуже поширений сценарій, у якому
значення може бути чимось, або може бути нічим.
Наприклад, якщо ви запитуєте перший елемент у непорожньому списку, ви отримаєте значення. Якщо ви запитуєте перший елемент у порожньому списку, ви не отримаєте нічого. Вираження цієї концепції в термінах системи типів означає, що компілятор може перевірити, чи ви обробили всі випадки, які слід обробити; ця функціональність може запобігти помилкам, які надзвичайно поширені в інших мовах програмування.
Проєктування мов програмування часто розглядають з погляду того, які можливості
ви включаєте, але те, які можливості ви виключаєте, теж важливо. Rust не має
можливості null, яка є в багатьох інших мовах. Null — це значення, яке
означає, що там немає значення. У мовах із null змінні завжди можуть
перебувати в одному з двох станів: null або не-null.
У своїй презентації 2009 року “Null References: The Billion Dollar Mistake”
Тоні Гоар, винахідник null, сказав таке:
Я називаю це своєю помилкою вартістю в мільярд доларів. Тоді я проєктував першу комплексну систему типів для посилань в об’єктно-орієнтованій мові. Моєю метою було забезпечити, щоб усі використання посилань були абсолютно безпечними, із перевіркою, що виконується автоматично компілятором. Але я не втримався від спокуси додати нульове посилання, просто тому, що його було так легко реалізувати. Це призвело до незліченних помилок, вразливостей і системних збоїв, які, ймовірно, завдали мільярдів доларів шкоди та збитків протягом останніх сорока років.
Проблема зі значеннями null полягає в тому, що якщо ви намагаєтеся
використати значення null як значення не-null, ви отримаєте помилку
якогось типу. Оскільки ця властивість null або не-null є повсюдною,
надзвичайно легко припуститися помилки такого роду.
Однак концепція, яку null намагається виразити, усе ще є корисною: null —
це значення, яке наразі є недійсним або відсутнім з певної причини.
Проблема не зовсім у концепції, а в конкретній реалізації. Тому Rust не має
null, але має перелічення, яке може кодувати концепцію присутності або відсутності
значення. Це перелічення — Option<T>, і воно [визначене стандартною бібліотекою]
option ось так:
#![allow(unused)]
fn main() {
enum Option<T> {
None,
Some(T),
}
}Перелічення Option<T> настільки корисне, що його навіть включено до prelude; вам
не потрібно явно вводити його в область видимості. Його варіанти також включено
до prelude: Ви можете використовувати Some і None безпосередньо без
префікса Option::. Перелічення Option<T> і далі є звичайним переліченням, а
Some(T) і None усе ще є варіантами типу Option<T>.
Синтаксис <T> — це можливість Rust, про яку ми ще не говорили. Це параметр
узагальненого типу, і ми розглянемо узагальнені типи детальніше в Розділі 10. Наразі
вам потрібно знати лише те, що <T> означає, що варіант Some перелічення
Option може містити один фрагмент даних будь-якого типу, а кожен конкретний
тип, який використовується замість T, робить загальний тип Option<T>
іншим типом. Ось кілька прикладів використання значень Option для зберігання
числових типів і типів char:
fn main() {
let some_number = Some(5);
let some_char = Some('e');
let absent_number: Option<i32> = None;
}Тип some_number — це Option<i32>. Тип some_char — це Option<char>,
який є іншим типом. Rust може вивести ці типи, тому що ми вказали значення
всередині варіанта Some. Для absent_number Rust вимагає від нас
анотувати загальний тип Option: Компілятор не може вивести тип, який
відповідний варіант Some буде містити, дивлячись лише на значення None.
Тут ми повідомляємо Rust, що маємо на увазі absent_number типу Option<i32>.
Коли в нас є значення Some, ми знаємо, що значення присутнє, і це значення
міститься всередині Some. Коли в нас є значення None, у певному сенсі це
означає те саме, що й null: У нас немає дійсного значення. То чому ж
Option<T> кращий за null?
Коротко кажучи, тому що Option<T> і T (де T може бути будь-яким типом)
є різними типами, компілятор не дозволить нам використовувати значення
Option<T> так, ніби воно точно є дійсним значенням. Наприклад, цей код не
скомпілюється, тому що він намагається додати i8 до Option<i8>:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}Якщо ми запустимо цей код, то отримаємо повідомлення про помилку на кшталт цього:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
`&i8` implements `Add<i8>`
`&i8` implements `Add`
`i8` implements `Add<&i8>`
`i8` implements `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Вражаюче! Фактично це повідомлення про помилку означає, що Rust не розуміє, як
додати i8 і Option<i8>, тому що це різні типи. Коли в нас у Rust є значення
типу i8, компілятор гарантуватиме, що ми завжди маємо дійсне значення. Ми
можемо впевнено продовжувати без необхідності перевіряти null перед
використанням цього значення. Лише коли в нас є Option<i8> (або будь-який
інший тип значення, з яким ми працюємо), нам потрібно турбуватися про можливу
відсутність значення, і компілятор подбає про те, щоб ми обробили цей випадок
перед використанням значення.
Іншими словами, ви маєте перетворити Option<T> на T перед тим, як зможете
виконувати з ним операції T. Загалом це допомагає виявити одну з найпоширеніших
проблем із null: припущення, що щось не є null, тоді як насправді це так.
Усунення ризику помилкового припущення про значення не-null допомагає вам
бути впевненішими у своєму коді. Щоб мати значення, яке потенційно може бути
null, ви повинні явно погодитися на це, зробивши тип цього значення
Option<T>. Потім, коли ви використовуєте це значення, ви зобов’язані явно
обробити випадок, коли значення є null. У будь-якому місці, де значення має
тип, який не є Option<T>, ви можете безпечно припустити, що значення не є
null. Це було свідоме рішення в дизайні Rust, щоб обмежити повсюдність null
та підвищити безпеку коду Rust.
То як же отримати значення T із варіанта Some, коли у вас є значення типу
Option<T>, щоб ви могли використати це значення? Перелічення Option<T> має
велике число методів, корисних у різних ситуаціях; ви можете ознайомитися з ними
в його документації. Ознайомлення з методами Option<T>
буде надзвичайно корисним на вашому шляху з Rust.
Загалом, щоб використовувати значення Option<T>, вам потрібен код, який
оброблятиме кожен варіант. Вам потрібен певний код, який виконуватиметься лише
тоді, коли у вас є значення Some(T), і цей код може використовувати
внутрішнє T. Вам потрібен інший код, який виконуватиметься лише якщо у вас є
значення None, і цей код не має доступного значення T. Вираз match —
це конструкція керування потоком, яка робить саме це, коли використовується з
переліченнями: Він виконуватиме різний код залежно від того, який варіант перелічення
він має, і цей код може використовувати дані всередині значення, що зіставляється.
Конструкція керування потоком match
Конструкція керування потоком match (The match Control Flow Construct)
Rust має надзвичайно потужну конструкцію керування потоком, що називається match, яка
дозволяє вам порівнювати значення з послідовністю шаблонів (patterns) і потім виконувати
код на основі того, який шаблон збігається. Шаблони можуть складатися з літеральних значень,
імен змінних, символів підстановки для будь-чого, і багато чого іншого; Розділ
19 охоплює всі різні види шаблонів
і те, що вони роблять. Сила match походить від виразності
шаблонів і того факту, що компілятор підтверджує, що всі можливі випадки
оброблено.
Уявіть вираз match як схожий на машину для сортування монет: монети ковзають
вниз по доріжці з отворами різного розміру вздовж неї, і кожна монета падає крізь
перший отвір, який вона зустрічає і в який підходить. Так само значення проходять
через кожен шаблон у match, і при першому шаблоні, у який значення “підходить”,
значення падає у пов’язаний блок коду, який буде використано під час виконання.
Якщо вже про монети, давайте використаємо їх як приклад із match! Ми можемо написати
функцію, яка бере невідому монету США і, подібно до машини для підрахунку,
визначає, яка це монета, і повертає її вартість у центах, як показано в Лістингу 6-3.
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}Розберімо match у функції value_in_cents. Спочатку ми записуємо
ключове слово match, за яким іде вираз, яким у цьому випадку є значення
coin. Це здається дуже схожим на умовний вираз, використаний з if, але
є велика різниця: з if умова має обчислюватися до
булевого значення, але тут це може бути будь-який тип. Тип coin у цьому прикладі
— це перелічення Coin, яке ми визначили в першому рядку.
Далі йдуть гілки match. Гілка має дві частини: шаблон і деякий код. Перша
гілка тут має шаблон, який є значенням Coin::Penny, а потім
оператор =>, що відокремлює шаблон і код, який потрібно виконати. Код у цьому випадку
— це просто значення 1. Кожна гілка відокремлюється від наступної комою.
Коли вираз match виконується, він порівнює отримане значення з
шаблоном кожної гілки, по порядку. Якщо шаблон збігається зі значенням, код,
пов’язаний із цим шаблоном, виконується. Якщо цей шаблон не збігається зі
значенням, виконання продовжується до наступної гілки, так само як і в машині для сортування монет.
Ми можемо мати стільки гілок, скільки нам потрібно: у Лістингу 6-3 наш match
має чотири гілки.
Код, пов’язаний із кожною гілкою, є виразом, і отримане значення
виразу у гілці, що збігається, є значенням, яке повертається для
всього виразу match.
Зазвичай ми не використовуємо фігурні дужки, якщо код у гілці match короткий, як у
Лістингу 6-3, де кожна гілка просто повертає значення. Якщо ви хочете виконати кілька
рядків коду в гілці match, ви повинні використовувати фігурні дужки, і тоді кома
після гілки є необов’язковою. Наприклад, наступний код друкує
“Lucky penny!” кожного разу, коли метод викликається з Coin::Penny, але він
все одно повертає останнє значення блоку, 1:
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => {
println!("Lucky penny!");
1
}
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}Шаблони, що прив’язуються до значень
Ще одна корисна можливість гілок match полягає в тому, що вони можуть прив’язуватися до частин значень, які відповідають шаблону. Саме так ми можемо витягувати значення з варіантів перелічення.
Як приклад, давайте змінимо один із варіантів нашого перелічення, щоб він містив дані всередині.
З 1999 по 2008 рік Сполучені Штати карбували монети quarter з різним
дизайном для кожного з 50 штатів на одному боці. Жодні інші монети не мали
дизайну штатів, тож лише quarter мають це додаткове значення. Ми можемо додати цю інформацію до
нашого перелічення (enum), змінивши варіант Quarter, щоб він включав значення UsState,
збережене всередині нього, що ми й зробили в Лістингу 6-4.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {}Уявімо, що друг намагається зібрати всі 50 state quarters. Поки ми сортуємо дріб’язок за типом монети, ми також називатимемо назву штату, пов’язаного з кожною quarter, щоб якщо це одна з тих, якої у нашого друга немає, він міг додати її до своєї колекції.
У виразі match для цього коду ми додаємо змінну під назвою state до
шаблону, який відповідає значенням варіанта Coin::Quarter. Коли
Coin::Quarter збігається, змінна state прив’яжеться до значення штату
цієї quarter. Потім ми можемо використати state у коді для цієї гілки, ось так:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("State quarter from {state:?}!");
25
}
}
}
fn main() {
value_in_cents(Coin::Quarter(UsState::Alaska));
}Якби ми викликали value_in_cents(Coin::Quarter(UsState::Alaska)), coin
було б Coin::Quarter(UsState::Alaska). Коли ми порівнюємо це значення з кожною
із гілок match, жодна з них не збігається, доки ми не досягнемо Coin::Quarter(state). У
цей момент прив’язка для state буде значенням UsState::Alaska. Потім ми можемо
використати цю прив’язку у виразі println!, таким чином отримавши внутрішнє
значення штату з варіанта Coin для Quarter.
Зіставлення match з Option<T>
У попередньому розділі ми хотіли отримати внутрішнє значення T із випадку
Some при використанні Option<T>; ми також можемо обробляти Option<T> за допомогою match, як
ми робили з переліченням Coin! Замість порівняння монет ми будемо порівнювати
варіанти Option<T>, але спосіб роботи виразу match залишається
тим самим.
Припустімо, ми хочемо написати функцію, яка бере Option<i32> і, якщо
всередині є значення, додає 1 до цього значення. Якщо всередині немає значення,
функція має повернути значення None і не намагатися виконувати жодних
операцій.
Цю функцію дуже легко написати завдяки match, і вона виглядатиме як
у Лістингу 6-5.
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Розгляньмо перше виконання plus_one детальніше. Коли ми викликаємо
plus_one(five), змінна x у тілі plus_one матиме
значення Some(5). Потім ми порівнюємо це з кожною гілкою match:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Значення Some(5) не збігається з шаблоном None, тому ми продовжуємо до
наступної гілки:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Чи збігається Some(5) із Some(i)? Так! У нас той самий варіант. i
прив’язується до значення, що міститься в Some, тож i набуває значення 5. Потім
виконується код у гілці match, тож ми додаємо 1 до значення i і створюємо
нове значення Some із нашим підсумком 6 всередині.
Тепер розгляньмо другий виклик plus_one у Лістингу 6-5, де x є
None. Ми входимо в match і порівнюємо з першою гілкою:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Воно збігається! Додавати нема до чого, тож програма зупиняється і повертає
значення None праворуч від =>. Оскільки перша гілка збіглася, жодні інші
гілки не порівнюються.
Поєднання match і перелічень корисне в багатьох ситуаціях. Ви часто бачитимете
цей шаблон у коді Rust: match проти перелічення, прив’язування змінної до
даних всередині, а потім виконання коду на основі цього. Спочатку це трохи складно, але
після того, як ви звикнете до цього, ви захочете мати це в усіх мовах. Це
послідовно є улюбленим серед користувачів.
Зіставлення вичерпне
Є ще один аспект match, про який нам потрібно поговорити: шаблони в гілках мають
охоплювати всі можливості. Розгляньте цю версію нашої функції plus_one,
яка має помилку і не компілюється:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Ми не обробили випадок None, тож цей код спричинить помилку. На щастя, це
помилка, яку Rust уміє виявляти. Якщо ми спробуємо скомпілювати цей код, ми отримаємо таку
помилку:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:593:1
::: /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:597:5
|
= note: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust знає, що ми не охопили кожен можливий випадок, і навіть знає, який
шаблон ми забули! Зіставлення в Rust є вичерпним: ми повинні вичерпати кожну останню
можливість, щоб код був дійсним. Особливо у випадку
Option<T>, коли Rust не дає нам забути явно обробити
випадок None, він захищає нас від припущення, що ми маємо значення, коли ми можемо
мати null, таким чином роблячи неможливою помилку на мільярд доларів, про яку йшлося раніше.
Універсальні шаблони та заповнювач _
Використовуючи перелічення, ми також можемо виконувати спеціальні дії для кількох певних значень,
але для всіх інших значень виконувати одну дію за замовчуванням. Уявімо, що ми реалізуємо гру,
де якщо ви кидаєте 3 під час кидка кубика, ваш гравець не рухається, а натомість
отримує новий модний капелюх. Якщо ви кидаєте 7, ваш гравець втрачає модний капелюх. Для всіх
інших значень ваш гравець рухається на цю кількість клітинок по ігровому полю. Ось
match, який реалізує цю логіку, із результатом кидка кубика
жорстко заданим замість випадкового значення, а вся інша логіка представлена
функціями без тіл, тому що фактична їх реалізація виходить за межі
цього прикладу:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
other => move_player(other),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn move_player(num_spaces: u8) {}
}Для перших двох гілок шаблонами є літеральні значення 3 і 7. Для
останньої гілки, яка охоплює кожне інше можливе значення, шаблон є
змінною, яку ми вирішили назвати other. Код, що виконується для гілки other,
використовує цю змінну, передаючи її до функції move_player.
Цей код компілюється, хоча ми не перелічили всі можливі значення, які може мати u8, тому що
останній шаблон збігатиметься з усіма значеннями, не переліченими явно. Цей універсальний шаблон (catch-all pattern)
виконує вимогу, що match має бути вичерпним. Зверніть увагу, що ми маємо поставити
гілку-заглушку останню, тому що шаблони оцінюються по порядку. Якби ми поставили гілку-заглушку раніше, інші гілки
ніколи б не виконувалися, тож Rust попередить нас, якщо ми додамо гілки після
гілки-заглушки!
У Rust також є шаблон, який ми можемо використовувати, коли хочемо мати заглушку, але не хочемо
використовувати значення в шаблоні-заглушці: _ — це спеціальний шаблон, який збігається з
будь-яким значенням і не прив’язується до цього значення. Це повідомляє Rust, що ми не збираємося
використовувати значення, тож Rust не попереджатиме нас про невикористану змінну.
Давайте змінимо правила гри: тепер, якщо ви кидаєте будь-що, окрім 3 або
7, ви повинні кидати знову. Нам більше не потрібно використовувати значення-заглушку, тож
ми можемо змінити наш код, щоб використовувати _ замість змінної під назвою other:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => reroll(),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn reroll() {}
}Цей приклад також задовольняє вимогу вичерпності, тому що ми явно ігноруємо всі інші значення в останній гілці; ми нічого не забули.
Нарешті, ми ще раз змінимо правила гри так, щоб нічого іншого
не відбувалося під час вашого ходу, якщо ви кидаєте будь-що, окрім 3 або 7. Ми можемо виразити
це, використавши одиничне значення (unit value) (порожній тип кортежу, який ми згадували в розділі 3) як код, що йде з гілкою _:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => (),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
}Тут ми явно повідомляємо Rust, що не збираємося використовувати жодне інше значення, яке не збігається з шаблоном у попередній гілці, і не хочемо виконувати жодного коду в цьому випадку.
Більше про шаблони та зіставлення ми розглянемо в Розділі
19. А зараз ми перейдемо до синтаксису
if let, який може бути корисним у ситуаціях, коли вираз match
трохи багатослівний.
Лаконічне керування потоком за допомогою if let та let...else
Стислий керований потік виконання з if let і let...else (Concise Control Flow with if let and let...else)
Синтаксис if let дає змогу поєднати if і let у менш багатослівний спосіб для
обробки значень, що відповідають одному шаблону, ігноруючи решту. Розгляньте
програму у Лістингу 6-6, яка зіставляє значення Option<u8> у змінній
config_max, але хоче виконати код лише якщо значення — це варіант Some.
fn main() {
let config_max = Some(3u8);
match config_max {
Some(max) => println!("The maximum is configured to be {max}"),
_ => (),
}
}Якщо значення — Some, ми виводимо значення у варіанті Some, зв’язуючи
значення зі змінною max у шаблоні. Ми не хочемо нічого робити зі значенням
None. Щоб задовольнити вираз match, нам доводиться додати _ => () після обробки лише одного варіанта, що є набридливим шаблонним кодом,
який потрібно додавати.
Натомість ми могли б записати це коротшим способом, використовуючи if let.
Наступний код поводиться так само, як match у Лістингу 6-6:
fn main() {
let config_max = Some(3u8);
if let Some(max) = config_max {
println!("The maximum is configured to be {max}");
}
}Синтаксис if let приймає шаблон і вираз, розділені знаком рівності. Він
працює так само, як match, де вираз передається до match, а шаблон є
його першою гілкою. У цьому випадку шаблон — Some(max), а max зв’язується
зі значенням усередині Some. Потім ми можемо використовувати max у тілі
блоку if let так само, як ми використовували max у відповідній гілці
match. Код у блоці if let виконується лише якщо значення відповідає
шаблону.
Використання if let означає менше набору тексту, менше вкладеності та менше
шаблонного коду. Однак ви втрачаєте повну перевірку, яку забезпечує match
і яка гарантує, що ви не забули обробити жоден випадок. Вибір між match і if let залежить від того, що ви робите у вашій конкретній ситуації, і від того,
чи є отримання лаконічності прийнятним компромісом за втрату повної перевірки.
Іншими словами, ви можете думати про if let як про синтаксичний цукор для
match, який запускає код, коли значення відповідає одному шаблону, а потім
ігнорує всі інші значення.
Ми можемо включити else з if let. Блок коду, що йде з else, такий самий,
як блок коду, що йшов би з випадком _ у виразі match, який еквівалентний
if let і else. Згадайте визначення перелічення Coin у Лістингу 6-4, де варіант
Quarter також містив значення UsState. Якби ми хотіли рахувати всі монети,
що не є quarter, які ми бачимо, одночасно оголошуючи state quarter, ми могли
б зробити це за допомогою виразу match, ось так:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
match coin {
Coin::Quarter(state) => println!("State quarter from {state:?}!"),
_ => count += 1,
}
}Або ми могли б використати вираз if let і else, ось так:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
if let Coin::Quarter(state) = coin {
println!("State quarter from {state:?}!");
} else {
count += 1;
}
}Залишатися на “щасливому шляху” (happy path) з let...else
Поширений шаблон — виконати деяке обчислення, коли значення присутнє, і
повернути значення за замовчуванням інакше. Продовжуючи наш приклад із
монетами зі значенням UsState, якщо ми хотіли б сказати щось смішне залежно
від того, наскільки стара state на quarter була, ми могли б додати метод до
UsState, щоб перевірити вік state, ось так:
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}Потім ми могли б використати if let, щоб зіставити тип монети, створюючи
змінну state у тілі умови, як у Лістингу 6-7.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}Це справляється із завданням, але воно перенесло роботу в тіло оператора if let, і якщо робота, яку потрібно виконати, є складнішою, може бути важко
точно простежити, як пов’язані верхньорівневі гілки. Ми також могли б
скористатися тим фактом, що вирази створюють значення, або щоб отримати
state з if let, або щоб повернутися рано, як у Лістингу 6-8. (Ви могли б
зробити щось подібне і з match.)
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let state = if let Coin::Quarter(state) = coin {
state
} else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}Однак це дещо незручно відстежувати й по-своєму! Одна гілка if let створює значення, а інша повністю повертається з функції.
Щоб зробити цей поширений шаблон приємнішим для вираження, Rust має let...else.
Синтаксис let...else приймає шаблон ліворуч і вираз праворуч, дуже подібно
до if let, але він не має гілки if, лише гілку else. Якщо шаблон
відповідає, він зв’яже значення зі шаблону у зовнішній області видимості. Якщо
шаблон не відповідає, програма перейде до гілки else, яка має повернутися з
функції.
У Лістингу 6-9 ви можете побачити, як виглядає Лістинг 6-8 при використанні
let...else замість if let.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let Coin::Quarter(state) = coin else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}Зверніть увагу, що таким чином у головному тілі функції він залишається на
“щасливому шляху” (happy path), без суттєво відмінного керування потоком виконання для двох
гілок, як це було з if let.
Якщо у вас є ситуація, в якій логіка вашої програми є занадто багатослівною,
щоб виразити її за допомогою match, пам’ятайте, що if let і let...else
також є у вашому інструментарії Rust.
Підсумок
Тепер ми розглянули, як використовувати перелічення для створення власних типів,
які можуть бути одним із набору перелічених значень. Ми показали, як стандартна
бібліотека Option<T> допомагає вам використовувати систему типів, щоб
запобігати помилкам. Коли значення перелічення мають усередині дані, ви можете
використовувати match або if let, щоб витягувати й використовувати ці
значення, залежно від того, скільки випадків вам потрібно обробити.
Ваші програми Rust тепер можуть виражати поняття у вашій предметній області за допомогою структур і перелічень. Створення власних типів для використання у вашому API забезпечує типову безпеку: компілятор подбає, щоб ваші функції отримували лише значення того типу, який очікує кожна функція.
Щоб надати вашим користувачам добре організований API, який є простим у використанні та відкриває рівно те, що потрібно вашим користувачам, тепер перейдемо до модулів Rust.
Керування зростаючими проєктами за допомогою пакетів, крейтів та модулів (Managing Growing Projects with Packages, Crates, and Modules)
Коли ви пишете великі програми, організація вашого коду ставатиме дедалі важливішою. Групуючи пов’язану функціональність і відокремлюючи код з окремими можливостями, ви зробите зрозумілішим, де знайти код, що реалізує певну можливість, і куди звернутися, щоб змінити те, як працює можливість.
Програми, які ми написали досі, були в одному модулі в одному файлі. Коли проект зростає, слід організовувати код, розділяючи його на кілька модулів, а потім на кілька файлів. Пакет може містити кілька двійкових крейтів і, необов’язково, один бібліотечний крейт. Коли пакет зростає, ви можете виділяти частини в окремі крейти, які стають зовнішніми залежностями. Цей розділ охоплює всі ці техніки. Для дуже великих проектів, що складаються з набору взаємопов’язаних пакетів, які розвиваються разом, Cargo надає робочі простори, які ми розглянемо в “Робочі простори Cargo” у розділі 14.
Ми також обговоримо інкапсуляцію деталей реалізації, що дає змогу вам повторно використовувати код на вищому рівні: щойно ви реалізували операцію, інший код може викликати ваш код через його публічний інтерфейс, не маючи потреби знати, як працює реалізація. Те, як ви пишете код, визначає, які частини є публічними для використання іншим кодом, а які частини — приватні деталі реалізації, які ви залишаєте за собою право змінювати. Це ще один спосіб обмежити обсяг деталей, які вам потрібно тримати в голові.
Пов’язане поняття — область видимості: вкладений контекст, у якому написано код, має набір імен, які визначені як “у межах області видимості”. Під час читання, написання та компіляції коду програмістам і компіляторам потрібно знати, чи певне ім’я в певному місці означає змінну, функцію, структуру, перелічення, модуль, константу або інший елемент, і що означає цей елемент. Ви можете створювати області видимості і змінювати, які імена перебувають у межах або поза межами області видимості. Ви не можете мати два елементи з однаковим іменем в одній області видимості; для розв’язання конфліктів імен доступні інструменти.
Rust має низку можливостей, які дають змогу вам керувати організацією вашого коду, зокрема тим, які деталі є доступними, які деталі є приватними, і які імена є в кожній області видимості у ваших програмах. Ці можливості, іноді разом називані системою модулів, включають:
- Пакети (Packages): можливість Cargo, яка дає вам змогу будувати, тестувати і поширювати крейти
- Крейти (Crates): дерево модулів, яке створює бібліотеку або виконуваний файл
- Модулі (Modules) та use: дають вам змогу керувати організацією, областю видимості та приватністю шляхів
- Шляхи (Paths): спосіб іменування елемента, такого як структура, функція або модуль
У цьому розділі ми охопимо всі ці можливості, обговоримо, як вони взаємодіють, і пояснимо, як використовувати їх для керування областю видимості. До кінця ви повинні мати надійне розуміння системи модулів і бути здатними працювати з областями видимості як професіонал!
Пакети та крейти
Пакети та крейти (Packages and Crates)
Перші частини системи модулів, які ми розглянемо, — це пакети та крейти.
Крейт — це найменший обсяг коду, який компілятор Rust розглядає за раз. Навіть якщо ви запускаєте rustc замість cargo і передаєте один файл вихідного коду (як ми робили ще в “Основи програми Rust” у розділі 1), компілятор вважає цей файл крейтом. Крейт може містити модулі, а модулі можуть бути визначені в інших файлах, які компілюються разом із крейтом, як ми побачимо в наступних розділах.
Крейт може бути в одному з двох форматів: бінарний крейт або бібліотечний крейт. Бінарні крейти — це програми, які ви можете скомпілювати у виконуваний файл, який можна запускати, наприклад програму командного рядка або сервер. Кожен має містити функцію під назвою main, яка визначає, що відбувається під час запуску виконуваного файлу. Усі крейти, які ми створили дотепер, були бінарними крейтами.
Бібліотечні крейти не мають функції main і не компілюються у виконуваний файл. Натомість вони визначають функціональність, призначену для спільного використання з кількома проєктами. Наприклад, крейт rand, який ми використовували в розділі 2, надає функціональність, що генерує випадкові числа. Найчастіше, коли растацеанці (Rustaceans) кажуть “крейт”, вони мають на увазі бібліотечний крейт, і використовують “крейт” як взаємозамінне з загальним програмним поняттям “бібліотеки”.
Корінь крейту — це файл вихідного коду, з якого компілятор Rust починає роботу і який утворює кореневий модуль вашого крейту (ми детально пояснимо модулі в “Визначення модулів для керування областю видимості та приватністю”).
Пакет — це набір одного або кількох крейтів, що надає набір функціональності. Пакет містить файл Cargo.toml, який описує, як зібрати ці крейти. Cargo насправді є пакетом, який містить бінарний крейт для інструмента командного рядка, яким ви користувалися для збирання свого коду. Пакет Cargo також містить бібліотечний крейт, від якого залежить бінарний крейт. Інші проєкти можуть залежати від бібліотечного крейту Cargo, щоб використовувати ту саму логіку, яку використовує інструмент командного рядка Cargo.
Пакет може містити скільки завгодно бінарних крейтів, але не більше одного бібліотечного крейту. Пакет має містити принаймні один крейт, чи то бібліотечний, чи то бінарний.
Давайте розглянемо, що відбувається, коли ми створюємо пакет. Спочатку ми вводимо команду cargo new my-project:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
Після того як ми запускаємо cargo new my-project, ми використовуємо ls, щоб побачити, що створює Cargo. У каталозі my-project є файл Cargo.toml, який дає нам пакет. Також є каталог src, що містить main.rs. Відкрийте Cargo.toml у своєму текстовому редакторі та зауважте, що там немає згадки про src/main.rs. Cargo дотримується домовленості, що src/main.rs — це корінь крейту бінарного крейту з тією самою назвою, що й пакет. Аналогічно, Cargo знає, що якщо каталог пакета містить src/lib.rs, пакет містить бібліотечний крейт з тією самою назвою, що й пакет, а src/lib.rs — це його корінь крейту. Cargo передає файли кореня крейту до rustc, щоб зібрати бібліотеку або бінарний файл.
Тут у нас є пакет, який містить лише src/main.rs, тобто він містить лише бінарний крейт під назвою my-project. Якщо пакет містить src/main.rs і src/lib.rs, він має два крейти: бінарний і бібліотечний, обидва з тією самою назвою, що й пакет. Пакет може мати кілька бінарних крейтів, якщо розмістити файли в каталозі src/bin: кожен файл буде окремим бінарним крейтом.
Керуйте областю видимості та приватністю за допомогою модулів
Визначення модулів для керування областю видимості та приватністю (Defining Modules to Control Scope and Privacy)
У цьому розділі ми поговоримо про модулі та інші частини системи модулів,
а саме шляхи (paths), які дають змогу називати елементи; ключове слово use, яке
вводить шлях (path) в область видимості; і ключове слово pub, щоб робити елементи
публічними. Ми також обговоримо ключове слово as, зовнішні пакети та glob-оператор.
Шпаргалка з модулів
Перш ніж ми перейдемо до деталей модулів і шляхів, тут ми наводимо коротку
довідку про те, як модулі, шляхи, ключове слово use і ключове слово pub
працюють у компіляторі, і як більшість розробників організовують свій код. Ми
розглядатимемо приклади кожного з цих правил протягом цього розділу, але це
чудове місце, куди можна звернутися як до нагадування про те, як працюють модулі.
- Починайте з кореня крейту: Під час компіляції крейта компілятор спочатку шукає в файлі кореня крейту (зазвичай src/lib.rs для бібліотечного крейта і src/main.rs для бінарного крейта) код для компіляції.
- Оголошення модулів: У файлі кореня крейта ви можете оголошувати нові модулі;
скажімо, ви оголошуєте модуль “garden” за допомогою
mod garden;. Компілятор шукатиме код модуля в таких місцях:- Вбудовано, всередині фігурних дужок, які замінюють крапку з комою після
mod garden - У файлі src/garden.rs
- У файлі src/garden/mod.rs
- Вбудовано, всередині фігурних дужок, які замінюють крапку з комою після
- Оголошення підмодулів: У будь-якому файлі, окрім кореня крейту, ви можете
оголошувати підмодулі. Наприклад, ви можете оголосити
mod vegetables;у src/garden.rs. Компілятор шукатиме код підмодуля всередині каталогу, названого на честь батьківського модуля, у таких місцях:- Вбудовано, безпосередньо після
mod vegetables, у фігурних дужках замість крапки з комою - У файлі src/garden/vegetables.rs
- У файлі src/garden/vegetables/mod.rs
- Вбудовано, безпосередньо після
- Шляхи (paths) до коду в модулях: Після того як модуль став частиною вашого крейта,
ви можете посилатися на код у цьому модулі з будь-якого іншого місця в тому
самому крейті, якщо правила приватності це дозволяють, використовуючи шлях (path) до
коду. Наприклад, тип
Asparagusу модулі garden vegetables буде знайдено за адресоюcrate::garden::vegetables::Asparagus. - Приватне проти публічного: Код у межах модуля за замовчуванням є приватним
для його батьківських модулів. Щоб зробити модуль публічним, оголосіть його з
pub modзамістьmod. Щоб зробити елементи всередині публічного модуля також публічними, використовуйтеpubперед їхніми оголошеннями. - Ключове слово
use: В межах області видимості ключове словоuseстворює скорочення для елементів, щоб зменшити повторення довгих шляхів (paths). У будь-якій області видимості, яка може посилатися наcrate::garden::vegetables::Asparagus, ви можете створити скорочення за допомогоюuse crate::garden::vegetables::Asparagus;, і відтоді вам потрібно буде лише писатиAsparagus, щоб використовувати цей тип у цій області видимості.
Тут ми створюємо бінарний крейт з назвою backyard, який ілюструє ці правила.
Каталог крейта, який також називається backyard, містить такі файли та
каталоги:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
Файл кореня крейта в цьому випадку — src/main.rs, і він містить:
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("I'm growing {plant:?}!");
}Рядок pub mod garden; каже компілятору включити код, який він знаходить у
src/garden.rs, а саме:
pub mod vegetables;Тут pub mod vegetables; означає, що код у src/garden/vegetables.rs
також включається. Цей код такий:
#[derive(Debug)]
pub struct Asparagus {}Тепер давайте перейдемо до деталей цих правил і продемонструємо їх у дії!
Групування пов’язаного коду в модулях
Модулі дають змогу нам організовувати код у межах крейта для зручності читання та простого повторного використання. Модулі також дають змогу нам керувати приватністю елементів, оскільки код у модулі за замовчуванням є приватним. Приватні елементи — це внутрішні деталі реалізації, недоступні для зовнішнього використання. Ми можемо вибрати зробити модулі та елементи всередині них публічними, що відкриває їх, щоб зовнішній код міг використовувати їх і залежати від них.
Як приклад, давайте напишемо бібліотечний крейт, який надає функціональність ресторану. Ми визначимо сигнатури функцій, але залишимо їхні тіла порожніми, щоб зосередитися на організації коду, а не на реалізації ресторану.
У ресторанній індустрії деякі частини ресторану називають front of house, а інші — back of house. Front of house — це місце, де перебувають клієнти; це охоплює те, де хости саджають клієнтів, офіціанти приймають замовлення та оплату, а бармени готують напої. Back of house — це місце, де шеф-кухарі та кухарі працюють на кухні, посудомийники прибирають, а менеджери виконують адміністративну роботу.
Щоб структурувати наш крейт у такий спосіб, ми можемо організувати його функції
у вкладені модулі. Створіть новий бібліотечний крейт під назвою restaurant,
виконавши cargo new restaurant --lib. Потім внесіть код з Лістингу 7-1 у
src/lib.rs, щоб визначити деякі модулі та сигнатури функцій; цей код є
розділом front of house.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}Ми визначаємо модуль за допомогою ключового слова mod, після якого йде назва
модуля (у цьому випадку front_of_house). Тіло модуля потім розміщується
всередині фігурних дужок. Усередині модулів ми можемо розміщувати інші модулі,
як у цьому випадку з модулями hosting і serving. Модулі також можуть
містити оголошення інших елементів, таких як структури, перелічення, константи,
трейти і, як у Лістингу 7-1, функції.
Використовуючи модулі, ми можемо групувати пов’язані оголошення разом і називати, чому вони пов’язані. Програмісти, які використовують цей код, можуть пересуватися кодом на основі груп, а не читати всі оголошення, що полегшує пошук потрібних їм оголошень. Програмісти, які додають нову функціональність до цього коду, знатимуть, куди розмістити код, щоб зберегти програму організованою.
Раніше ми згадували, що src/main.rs і src/lib.rs називаються коренями
крейту. Причина їхньої назви в тому, що вміст будь-якого з цих двох файлів
утворює модуль із назвою crate у корені модульної структури крейта, відомої як
дерево модулів.
Лістинг 7-2 показує дерево модулів для структури в Лістингу 7-1.
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
Це дерево показує, як деякі модулі вкладені в інші модулі; наприклад,
hosting вкладений у front_of_house. Дерево також показує, що деякі модулі
є сусідніми, тобто вони визначені в одному модулі; hosting і serving
є сусідніми, визначеними всередині front_of_house. Якщо модуль A міститься
всередині модуля B, ми кажемо, що модуль A є дочірнім модулю B, а модуль B є
батьківським модулю A. Зверніть увагу, що все дерево модулів має корінь під
неявним модулем із назвою crate.
Дерево модулів може нагадати вам дерево каталогів файлової системи на вашому комп’ютері; це дуже влучне порівняння! Так само як каталоги у файловій системі, ви використовуєте модулі для організації свого коду. І так само як файли в каталозі, нам потрібен спосіб знаходити наші модулі.
Шляхи для посилання на елемент у дереві модулів
Шляхи для посилання на елемент у дереві модулів (Paths for Referring to an Item in the Module Tree)
Щоб показати Rust, де знайти елемент у дереві модулів, ми використовуємо шлях так само, як використовуємо шлях під час навігації файловою системою. Щоб викликати функцію, нам потрібно знати її шлях.
Шлях може мати дві форми:
- Абсолютний шлях — це повний шлях, що починається від кореня крейту; для коду із зовнішнього крейту абсолютний шлях починається з назви крейту, а для коду з поточного крейту він починається з літерала
crate. - Відносний шлях починається з поточного модуля і використовує
self,superабо ідентифікатор у поточному модулі.
І за абсолютним, і за відносним шляхом ідуть один або кілька ідентифікаторів, розділених подвійними двокрапками (::).
Повертаючись до Лістингу 7-1, скажімо, ми хочемо викликати функцію add_to_waitlist. Це те саме, що запитати: який шлях у функції add_to_waitlist? Лістинг 7-3 містить Лістинг 7-1 із вилученими деякими модулями та функціями.
Ми покажемо два способи викликати функцію add_to_waitlist з нової функції, eat_at_restaurant, визначеної в корені крейту. Ці шляхи правильні, але залишається ще одна проблема, через яку цей приклад не скомпілюється в такому вигляді. Невдовзі ми пояснимо чому.
Функція eat_at_restaurant є частиною нашого публічного API бібліотечного крейту, тому ми позначаємо її ключовим словом pub. У розділі “Відкриття шляхів за допомогою ключового слова pub” ми детальніше розглянемо pub.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}Перший раз, коли ми викликаємо функцію add_to_waitlist у eat_at_restaurant, ми використовуємо абсолютний шлях. Функція add_to_waitlist визначена в тому самому крейті, що й eat_at_restaurant, а це означає, що ми можемо використати ключове слово crate, щоб почати абсолютний шлях. Потім ми включаємо кожен із наступних модулів, доки не дійдемо до add_to_waitlist. Ви можете уявити ту саму структуру у файловій системі: ми б вказали шлях /front_of_house/hosting/add_to_waitlist, щоб запустити програму add_to_waitlist; використання назви crate для початку від кореня крейту — це як використання / для початку від кореня файлової системи у вашій оболонці.
Другий раз, коли ми викликаємо add_to_waitlist у eat_at_restaurant, ми використовуємо відносний шлях. Шлях починається з front_of_house, назви модуля, визначеного на тому самому рівні дерева модулів, що й eat_at_restaurant. Тут файловим еквівалентом було б використання шляху front_of_house/hosting/add_to_waitlist. Починати з назви модуля означає, що шлях є відносним.
Вибір між відносним і абсолютним шляхом — це рішення, яке ви прийматимете залежно від вашого проєкту, і воно залежить від того, чи з більшою ймовірністю ви будете переміщувати код визначення елемента окремо від коду, що використовує елемент, чи разом із ним. Наприклад, якщо ми перемістимо модуль front_of_house і функцію eat_at_restaurant у модуль із назвою customer_experience, нам потрібно буде оновити абсолютний шлях до add_to_waitlist, але відносний шлях усе ще буде дійсним. Однак якщо ми перемістимо функцію eat_at_restaurant окремо в модуль із назвою dining, абсолютний шлях до виклику add_to_waitlist залишиться тим самим, але відносний шлях потрібно буде оновити. Загалом ми надаємо перевагу вказуванню абсолютних шляхів, тому що, ймовірно, ми захочемо переміщувати визначення коду та виклики елементів незалежно одне від одного.
Спробуймо скомпілювати Лістинг 7-3 і з’ясуємо, чому він ще не компілюється! Помилки, які ми отримаємо, показані в Лістингу 7-4.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Повідомлення про помилки кажуть, що модуль hosting є приватним. Іншими словами, ми маємо правильні шляхи для модуля hosting і функції add_to_waitlist, але Rust не дозволить нам використовувати їх, тому що він не має доступу до приватних секцій. У Rust усі елементи (функції, методи, структури, перелічення, модулі та константи) за замовчуванням є приватними для батьківських модулів. Якщо ви хочете зробити елемент, наприклад функцію або структуру, приватним, ви поміщаєте його в модуль.
Елементи в батьківському модулі не можуть використовувати приватні елементи всередині дочірніх модулів, але елементи в дочірніх модулях можуть використовувати елементи у своїх модулів-предків. Це тому, що дочірні модулі обгортають і приховують деталі своєї реалізації, але дочірні модулі можуть бачити контекст, у якому вони визначені. Продовжуючи нашу метафору, подумайте про правила приватності як про службове приміщення ресторану: те, що там відбувається, є приватним для відвідувачів ресторану, але офісні менеджери можуть бачити і робити все в ресторані, яким вони керують.
Rust вирішив, щоб система модулів працювала саме так, аби приховування внутрішніх деталей реалізації було типовою поведінкою. Таким чином ви знаєте, які частини внутрішнього коду можете змінювати, не ламаючи зовнішній код. Однак Rust таки надає вам можливість відкривати внутрішні частини коду дочірніх модулів для зовнішніх модулів-предків, використовуючи ключове слово pub, щоб зробити елемент публічним.
Відкриття шляхів за допомогою ключового слова pub
Повернімося до помилки в Лістингу 7-4, яка сказала нам, що модуль hosting є приватним. Ми хочемо, щоб функція eat_at_restaurant у батьківському модулі мала доступ до функції add_to_waitlist у дочірньому модулі, тому ми позначаємо модуль hosting ключовим словом pub, як показано в Лістингу 7-5.
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}На жаль, код у Лістингу 7-5 усе ще призводить до помилок компілятора, як показано в Лістингу 7-6.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:10:37
|
10 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:13:30
|
13 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Що сталося? Додавання ключового слова pub перед mod hosting робить модуль публічним. З цією зміною, якщо ми можемо отримати доступ до front_of_house, ми можемо отримати доступ до hosting. Але вміст hosting усе ще приватний; зробити модуль публічним не означає зробити публічним його вміст. Ключове слово pub для модуля лише дозволяє коду в його модулях-предках посилатися на нього, але не отримувати доступ до його внутрішнього коду. Оскільки модулі є контейнерами, мало що можна зробити, лише зробивши модуль публічним; нам потрібно піти далі й обрати також зробити один або кілька елементів усередині модуля публічними.
Помилки в Лістингу 7-6 кажуть, що функція add_to_waitlist є приватною. Правила приватності застосовуються також до структур, перелічень, функцій і методів, а також до модулів.
Давайте також зробимо функцію add_to_waitlist публічною, додавши ключове слово pub перед її визначенням, як у Лістингу 7-7.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}Тепер код скомпілюється! Щоб побачити, чому додавання ключового слова pub дозволяє нам використовувати ці шляхи в eat_at_restaurant з погляду правил приватності, давайте подивимося на абсолютний і відносний шляхи.
В абсолютному шляху ми починаємо з crate, кореня дерева модулів нашого крейту. Модуль front_of_house визначений у корені крейту. Хоча front_of_house не є публічним, оскільки функція eat_at_restaurant визначена в тому самому модулі, що й front_of_house (тобто eat_at_restaurant і front_of_house є сусідніми), ми можемо посилатися на front_of_house із eat_at_restaurant. Далі йде модуль hosting, позначений pub. Ми можемо отримати доступ до батьківського модуля hosting, тож ми можемо отримати доступ до hosting. Нарешті, функція add_to_waitlist позначена pub, і ми можемо отримати доступ до її батьківського модуля, тож цей виклик функції працює!
У відносному шляху логіка така сама, як і в абсолютному шляху, за винятком першого кроку: замість початку від кореня крейту шлях починається з front_of_house. Модуль front_of_house визначений у тому самому модулі, що й eat_at_restaurant, тому відносний шлях, що починається з модуля, у якому визначено eat_at_restaurant, працює. Потім, оскільки hosting і add_to_waitlist позначені pub, решта шляху працює, і цей виклик функції є дійсним!
Якщо ви плануєте поширювати свій бібліотечний крейт так, щоб інші проєкти могли використовувати ваш код, ваш публічний API є вашим контрактом із користувачами вашого крейту, який визначає, як вони можуть взаємодіяти з вашим кодом. Існує багато міркувань щодо керування змінами у вашому публічному API, щоб людям було легше залежати від вашого крейту. Ці міркування виходять за межі цього підручника; якщо вас цікавить ця тема, дивіться Rust API Guidelines.
Найкращі практики для пакетів із бінарним і бібліотечним крейтом
Ми згадували, що пакет може містити як корінь бінарного крейту src/main.rs, так і корінь бібліотечного крейту src/lib.rs, і обидва крейти за замовчуванням матимуть назву пакета. Зазвичай пакети з таким шаблоном, що містять і бібліотечний, і бінарний крейт, матимуть лише стільки коду в бінарному крейді, щоб запустити виконуваний файл, який викликає код, визначений у бібліотечному крейді. Це дає змогу іншим проєктам отримати користь від максимальної функціональності, яку надає пакет, тому що код бібліотечного крейту можна спільно використовувати.
Дерево модулів слід визначати в src/lib.rs. Потім будь-які публічні елементи можна використовувати в бінарному крейді, починаючи шляхи з назви пакета. Бінарний крейт стає користувачем бібліотечного крейту так само, як повністю зовнішній крейт використовував би бібліотечний крейт: він може використовувати лише публічний API. Це допомагає вам проєктувати хороший API; ви не лише автор, а й клієнт!
У Розділі 12 ми продемонструємо цю організаційну практику на програмі командного рядка, яка міститиме і бінарний крейт, і бібліотечний крейт.
Початок відносних шляхів із super
Ми можемо конструювати відносні шляхи, які починаються в батьківському модулі, а не в поточному модулі чи корені крейту, використовуючи super на початку шляху. Це схоже на початок шляху файлової системи з синтаксисом .., який означає перехід до батьківського каталогу. Використання super дає нам змогу посилатися на елемент, який, як ми знаємо, є в батьківському модулі, що може полегшити впорядкування дерева модулів, коли модуль тісно пов’язаний із батьківським, але сам батьківський модуль у майбутньому може бути переміщений в інше місце в дереві модулів.
Розгляньте код у Лістингу 7-8, який моделює ситуацію, коли кухар виправляє неправильне замовлення і особисто приносить його клієнту. Функція fix_incorrect_order, визначена в модулі back_of_house, викликає функцію deliver_order, визначену в батьківському модулі, вказуючи шлях до deliver_order, що починається з super.
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}Функція fix_incorrect_order знаходиться в модулі back_of_house, тому ми можемо використати super, щоб перейти до батьківського модуля back_of_house, яким у цьому випадку є crate, корінь. Звідти ми шукаємо deliver_order і знаходимо його. Успіх! Ми вважаємо, що модуль back_of_house і функція deliver_order імовірно залишаться в тому самому взаємозв’язку один з одним і будуть переміщені разом, якщо ми вирішимо реорганізувати дерево модулів крейту. Тому ми використали super, щоб у майбутньому нам потрібно було оновлювати менше місць у коді, якщо цей код буде переміщено в інший модуль.
Зроблення структур і перелічень публічними
Ми також можемо використовувати pub, щоб позначати структури й перелічення як публічні, але є кілька додаткових деталей використання pub зі структурами й переліченнями. Якщо ми використовуємо pub перед визначенням структури, ми робимо структуру публічною, але поля структури все ще будуть приватними. Ми можемо робити кожне поле публічним або ні в кожному окремому випадку. У Лістингу 7-9 ми визначили публічну структуру back_of_house::Breakfast із публічним полем toast і приватним полем seasonal_fruit. Це моделює випадок у ресторані, коли клієнт може вибрати тип хліба, що подається до страви, але кухар вирішує, який фрукт супроводжує страву, залежно від того, що є в сезоні та в наявності. Доступний фрукт швидко змінюється, тому клієнти не можуть вибрати фрукт або навіть побачити, який фрукт вони отримають.
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast.
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like.
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compile if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal.
// meal.seasonal_fruit = String::from("blueberries");
}Оскільки поле toast у структурі back_of_house::Breakfast є публічним, у eat_at_restaurant ми можемо записувати і читати поле toast, використовуючи крапкову нотацію. Зверніть увагу, що ми не можемо використовувати поле seasonal_fruit у eat_at_restaurant, тому що seasonal_fruit є приватним. Спробуйте розкоментувати рядок, що змінює значення поля seasonal_fruit, щоб побачити, яку помилку ви отримаєте!
Також зверніть увагу, що оскільки back_of_house::Breakfast має приватне поле, структура має надати публічну асоційовану функцію, яка створює екземпляр Breakfast (ми назвали її summer). Якби Breakfast не мала такої функції, ми не змогли б створити екземпляр Breakfast у eat_at_restaurant, тому що ми не могли б встановити значення приватного поля seasonal_fruit у eat_at_restaurant.
На відміну від цього, якщо ми робимо перелічення публічним, усі його варіанти тоді є публічними. Нам потрібно лише pub перед ключовим словом enum, як показано в Лістингу 7-10.
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}Оскільки ми зробили перелічення Appetizer публічним, ми можемо використовувати варіанти Soup і Salad у eat_at_restaurant.
Перелічення не дуже корисні, якщо їхні варіанти не є публічними; було б незручно щоразу позначати всі варіанти перелічення pub, тому типовим значенням для варіантів перелічення є публічність. Структури часто корисні без публічності їхніх полів, тому поля структур підпорядковуються загальному правилу: усе за замовчуванням приватне, якщо не позначено pub.
Є ще одна ситуація, пов’язана з pub, яку ми не розглядали, і це наша остання можливість системи модулів: ключове слово use. Спочатку ми окремо розглянемо use, а потім покажемо, як поєднати pub і use.
Введення шляхів в область видимості за допомогою ключового слова use
Додавання шляхів до області видимості за допомогою ключового слова use (Bringing Paths into Scope with the use Keyword)
Необхідність виписувати шляхи для виклику функцій може здаватися незручною і
повторюваною. У Лістингу 7-7, незалежно від того, чи обрали ми абсолютний чи
відносний шлях до функції add_to_waitlist, кожного разу, коли ми хотіли
викликати add_to_waitlist, нам також доводилося вказувати front_of_house
і hosting. На щастя, є спосіб спростити цей процес: ми можемо один раз
створити скорочення до шляху за допомогою ключового слова use, а потім
використовувати коротшу назву всюди ще в межах області видимості.
У Лістингу 7-11 ми додаємо модуль crate::front_of_house::hosting до області
видимості функції eat_at_restaurant, так що нам потрібно вказувати лише
hosting::add_to_waitlist, щоб викликати функцію add_to_waitlist у
eat_at_restaurant.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Додавання use і шляху до області видимості подібне до створення символічного
посилання у файловій системі. Додавши use crate::front_of_house::hosting у
корені крейту, hosting тепер є дійсною назвою в цій області видимості, ніби
модуль hosting було визначено в корені крейту. Шляхи, додані до області
видимості за допомогою use, також перевіряють приватність, як і будь-які
інші шляхи.
Зверніть увагу, що use створює скорочення лише для конкретної області
видимості, в якій відбувається use. Лістинг 7-12 переміщує функцію
eat_at_restaurant до нового дочірнього модуля на ім’я customer, який
тоді є іншою областю видимості, ніж оператор use, тому тіло функції не
скомпілюється.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}Повідомлення компілятора про помилку показує, що скорочення більше не
застосовується всередині модуля customer:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of unresolved module or unlinked crate `hosting`
|
= help: if you wanted to use a crate named `hosting`, use `cargo add hosting` to add it to your `Cargo.toml`
help: consider importing this module through its public re-export
|
10 + use crate::hosting;
|
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
Зверніть увагу, що також є попередження про те, що use більше не
використовується у своїй області видимості! Щоб виправити цю проблему,
перемістіть use також усередину модуля customer, або зверніться до
скорочення в батьківському модулі за допомогою super::hosting всередині
дочірнього модуля customer.
Створення ідіоматичних шляхів use
У Лістингу 7-11 ви могли замислитися, чому ми вказали use crate::front_of_house::hosting, а потім викликали hosting::add_to_waitlist
у eat_at_restaurant, замість того щоб вказати шлях use аж до функції
add_to_waitlist, щоб досягти того самого результату, як у Лістингу 7-13.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}Хоча і Лістинг 7-11, і Лістинг 7-13 виконують одне й те саме завдання,
Лістинг 7-11 є ідіоматичним способом додати функцію до області видимості за
допомогою use. Додавання до області видимості батьківського модуля функції
за допомогою use означає, що під час виклику функції нам доводиться
вказувати батьківський модуль. Вказування батьківського модуля під час
виклику функції робить зрозумілим, що функція не визначена локально, і водночас
мінімізує повторення повного шляху. Код у Лістингу 7-13 не дає зрозуміти, де
визначено add_to_waitlist.
З іншого боку, коли за допомогою use додаються структури, перелічення та інші
елементи, ідіоматично вказувати повний шлях. Лістинг 7-14 показує ідіоматичний
спосіб додати структуру HashMap зі стандартної бібліотеки до області
видимості бінарного крейту.
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert(1, 2);
}За цим ідіомом немає якоїсь сильної причини: це просто конвенція, що склалася, і люди звикли читати та писати код Rust саме так.
Виняток із цього ідіому — якщо ми додаємо до області видимості за допомогою
операторів use два елементи з однаковою назвою, тому що Rust не дозволяє
цього. Лістинг 7-15 показує, як додати до області видимості два типи
Result, що мають однакову назву, але різні батьківські модулі, і як на них
посилатися.
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}Як бачите, використання батьківських модулів розрізняє два типи Result.
Якби натомість ми вказали use std::fmt::Result і use std::io::Result,
у нас було б два типи Result в одній і тій самій області видимості, і Rust
не знав би, який саме з них ми маємо на увазі, коли використовуємо Result.
Надання нових назв за допомогою ключового слова as
Існує ще одне рішення проблеми додавання двох типів з однаковою назвою до
однієї й тієї самої області видимості за допомогою use: після шляху ми можемо
вказати as і нову локальну назву, або псевдонім, для типу. Лістинг 7-16
показує інший спосіб написати код із Лістингу 7-15, перейменувавши один із
двох типів Result за допомогою as.
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}У другому операторі use ми вибрали нову назву IoResult для типу
std::io::Result, яка не конфліктуватиме з Result зі std::fmt, який ми
також додали до області видимості. Лістингу 7-15 і Лістингу 7-16 вважаються
ідіоматичними, тож вибір за вами!
Повторне виведення назв за допомогою pub use
Коли ми додаємо назву до області видимості за допомогою ключового слова use,
ця назва є приватною для області видимості, до якої ми її імпортували. Щоб
дати змогу коду поза цією областю видимості посилатися на цю назву так, ніби
вона була визначена в цій області видимості, ми можемо поєднати pub і use.
Ця техніка називається повторним виведенням, тому що ми додаємо елемент до
області видимості, а також робимо цей елемент доступним для інших, щоб вони
могли додати його до своєї області видимості.
Лістинг 7-17 показує код із Лістингу 7-11, у якому use у кореневому модулі
змінено на pub use.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}До цієї зміни зовнішній код мав би викликати функцію add_to_waitlist,
використовуючи шлях restaurant::front_of_house::hosting::add_to_waitlist(),
що також вимагало б, щоб модуль front_of_house було позначено як pub.
Тепер, коли цей pub use повторно вивів модуль hosting з кореневого модуля,
зовнішній код може натомість використовувати шлях
restaurant::hosting::add_to_waitlist().
Повторне виведення корисне, коли внутрішня структура вашого коду відрізняється
від того, як програмісти, що викликають ваш код, сприймали б цю предметну
область. Наприклад, у цій метафорі з рестораном люди, які керують
ресторанами, думають про “front of house” і “back of house”. Але відвідувачі
ресторану, ймовірно, не думатимуть про частини ресторану в таких термінах. За
допомогою pub use ми можемо писати наш код з однією структурою, але
експонувати іншу структуру. Це робить нашу бібліотеку добре організованою
як для програмістів, що працюють над бібліотекою, так і для програмістів, що
викликають бібліотеку. Ми розглянемо ще один приклад pub use і те, як це
впливає на документацію вашого крейту в “Експортування зручного публічного
API” у розділі 14.
Використання зовнішніх пакетів
У розділі 2 ми створили проєкт гри в вгадування, який використовував зовнішній
пакет під назвою rand, щоб отримувати випадкові числа. Щоб використати
rand у нашому проєкті, ми додали цей рядок до Cargo.toml:
rand = "0.8.5"
Додавання rand як залежності в Cargo.toml каже Cargo завантажити пакет
rand і будь-які залежності з crates.io та зробити
rand доступним для нашого проєкту.
Потім, щоб додати визначення rand до області видимості нашого пакета, ми
додали рядок use, що починається з назви крейту, rand, і перелічили
елементи, які хотіли додати до області видимості. Згадайте, що в
“Generating a Random Number” у розділі 2 ми додали
трейт Rng до області видимості і викликали функцію rand::thread_rng:
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Члени спільноти Rust зробили багато пакетів доступними на
crates.io, і додавання будь-якого з них до вашого
пакета передбачає ті самі кроки: перелічити їх у файлі Cargo.toml вашого
пакета і використовувати use, щоб додати елементи з їхніх крейтів до
області видимості.
Зверніть увагу, що стандартна бібліотека std також є крейтом, який є
зовнішнім щодо нашого пакета. Оскільки стандартна бібліотека постачається
разом із мовою Rust, нам не потрібно змінювати Cargo.toml, щоб включити
std. Але нам потрібно посилатися на неї за допомогою use, щоб додати
елементи звідти до області видимості нашого пакета. Наприклад, для HashMap
ми б використали цей рядок:
#![allow(unused)]
fn main() {
use std::collections::HashMap;
}Це абсолютний шлях, що починається з std, назви крейту стандартної бібліотеки.
Використання вкладених шляхів для впорядкування списків use
Якщо ми використовуємо кілька елементів, визначених в одному й тому самому
крейді або модулі, перелік кожного елемента в окремому рядку може зайняти
багато вертикального місця у наших файлах. Наприклад, ці два оператори use,
які були в нас у грі в вгадування у Лістингу 2-4, додають елементи зі std
до області видимості:
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Натомість ми можемо використовувати вкладені шляхи, щоб додати ті самі елементи до області видимості в одному рядку. Ми робимо це, вказуючи спільну частину шляху, за якою йдуть дві двокрапки, а потім фігурні дужки навколо списку частин шляхів, що відрізняються, як показано у Лістингу 7-18.
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}У більших програмах додавання багатьох елементів до області видимості з того
самого крейту або модуля за допомогою вкладених шляхів може значно зменшити
кількість окремих операторів use, які потрібні!
Ми можемо використовувати вкладений шлях на будь-якому рівні в шляху, що
корисно, коли поєднуються два оператори use, які мають спільний підшлях.
Наприклад, Лістинг 7-19 показує два оператори use: один, що додає std::io
до області видимості, і один, що додає std::io::Write до області
видимості.
use std::io;
use std::io::Write;Спільною частиною цих двох шляхів є std::io, і це повний перший шлях. Щоб
об’єднати ці два шляхи в один оператор use, ми можемо використати self у
вкладеному шляху, як показано у Лістингу 7-20.
use std::io::{self, Write};Цей рядок додає std::io і std::io::Write до області видимості.
Імпортування елементів за допомогою оператора glob
Якщо ми хочемо додати до області видимості всі публічні елементи, визначені
в шляху, ми можемо вказати цей шлях, за яким іде оператор glob *:
#![allow(unused)]
fn main() {
use std::collections::*;
}Цей оператор use додає всі публічні елементи, визначені в
std::collections, до поточної області видимості. Будьте обережні, коли
використовуєте оператор glob! Glob може ускладнити визначення того, які назви
є в області видимості і де було визначено назву, використану у вашій програмі.
Крім того, якщо залежність змінює свої визначення, імпортоване вами теж
змінюється, що може призвести до помилок компілятора під час оновлення
залежності, якщо залежність додасть визначення з такою самою назвою, як і
визначення вашого коду в тій самій області видимості, наприклад.
Оператор glob часто використовується під час тестування, щоб додати все, що
тестується, до модуля tests; ми поговоримо про це в “Як писати
тести” у розділі 11. Оператор glob також
іноді використовується як частина шаблону prelude: див. документацію
стандартної бібліотеки
для отримання додаткової інформації про цей шаблон.
Розділення модулів на різні файли
Розділення модулів у різні файли (Separating Modules into Different Files)
Поки що всі приклади в цьому розділі визначали кілька модулів в одному файлі. Коли модулі стають великими, ви можете захотіти перемістити їхні визначення до окремого файлу, щоб зробити код легшим для навігації.
Наприклад, давайте почнемо з коду в Лістингу 7-17, який мав кілька модулів ресторану. Ми витягнемо модулі у файли замість того, щоб усі модулі були визначені у файлі кореня крейту. У цьому випадку файл кореня крейту — це src/lib.rs, але ця процедура також працює з бінарними крейтами, чий файл кореня крейту — src/main.rs.
Спочатку ми витягнемо модуль front_of_house у його власний файл. Видаліть
код усередині фігурних дужок для модуля front_of_house, залишивши лише
оголошення mod front_of_house;, так щоб src/lib.rs містив код,
показаний у Лістингу 7-21. Зверніть увагу, що це не скомпілюється, доки ми не створимо
файл src/front_of_house.rs у Лістингу 7-22.
mod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Далі помістіть код, що був у фігурних дужках, у новий файл із назвою
src/front_of_house.rs, як показано у Лістингу 7-22. Компілятор знає, що потрібно дивитися
у цей файл, тому що він натрапив на оголошення модуля в корені крейту
з назвою front_of_house.
pub mod hosting {
pub fn add_to_waitlist() {}
}Зверніть увагу, що вам потрібно завантажити файл за допомогою оголошення mod лише один раз у вашому
дереві модулів. Після того як компілятор знає, що файл є частиною проєкту (і знає,
де в дереві модулів розташований код через те, де ви розмістили
оператор mod), інші файли у вашому проєкті повинні посилатися на код завантаженого файлу,
використовуючи шлях до того місця, де він був оголошений, як описано в розділі “Шляхи для посилання
на елемент у дереві модулів”. Іншими словами,
mod — це не операція “include”, яку ви могли бачити в інших
мовах програмування.
Далі ми витягнемо модуль hosting у його власний файл. Процес трохи
відрізняється, тому що hosting — це дочірній модуль front_of_house, а не
кореневого модуля. Ми розмістимо файл для hosting у новому каталозі, який буде
названо за його предками в дереві модулів, у цьому випадку src/front_of_house.
Щоб почати переміщення hosting, ми змінюємо src/front_of_house.rs, щоб він містив лише
оголошення модуля hosting:
pub mod hosting;Потім ми створюємо каталог src/front_of_house і файл hosting.rs, щоб
містився код, визначений у модулі hosting:
pub fn add_to_waitlist() {}Якби ми натомість помістили hosting.rs у каталог src, компілятор би
очікував, що код hosting.rs буде в модулі hosting, оголошеному в корені крейту,
а не оголошеному як дочірній елемент модуля front_of_house. Правила
компілятора щодо того, які файли перевіряти для коду яких модулів, означають, що
каталоги й файли тісніше відповідають дереву модулів.
Альтернативні шляхи до файлів
Поки що ми охопили найбільш ідіоматичні шляхи до файлів, які використовує компілятор Rust, але Rust також підтримує старіший стиль шляху до файлу. Для модуля з назвою
front_of_house, оголошеного в корені крейту, компілятор шукатиме код модуля в:
- src/front_of_house.rs (те, що ми охопили)
- src/front_of_house/mod.rs (старіший стиль, шлях, що все ще підтримується)
Для модуля з назвою
hosting, який є підмодулемfront_of_house, компілятор шукатиме код модуля в:
- src/front_of_house/hosting.rs (те, що ми охопили)
- src/front_of_house/hosting/mod.rs (старіший стиль, шлях, що все ще підтримується)
Якщо ви використовуєте обидва стилі для одного й того самого модуля, ви отримаєте помилку компілятора. Використання змішування обох стилів для різних модулів у тому самому проєкті є дозволеним, але може бути незрозумілим для людей, які навігують вашим проєктом.
Основний недолік стилю, який використовує файли з назвою mod.rs, полягає в тому, що ваш проєкт може закінчитися багатьма файлами з назвою mod.rs, що може стати заплутаним, коли ви маєте їх відкритими у вашому редакторі одночасно.
Ми перемістили код кожного модуля до окремого файлу, і дерево модулів залишається
тим самим. Виклики функцій у eat_at_restaurant працюватимуть без будь-яких
змін, навіть попри те, що визначення знаходяться в різних файлах. Ця
техніка дає змогу переміщати модулі до нових файлів у міру їхнього зростання в розмірі.
Зверніть увагу, що оператор pub use crate::front_of_house::hosting у
src/lib.rs також не змінився, і use також не впливає на те, які файли
компілюються як частина крейту. Ключове слово mod оголошує модулі, а Rust
шукає у файлі з тим самим іменем, що й модуль, код, який потрапляє в цей
модуль.
Підсумок
Rust дає змогу розділити пакет на кілька крейтів і крейт на модулі, щоб
ви могли посилатися на елементи, визначені в одному модулі, з іншого модуля.
Ви можете робити це, вказуючи абсолютні або відносні шляхи. Ці шляхи можна
ввести в область видимості за допомогою оператора use, щоб ви могли використовувати коротший шлях
для кількох використань елемента в цій області видимості. Код модуля за замовчуванням є приватним, але
ви можете зробити визначення публічними, додавши ключове слово pub.
У наступному розділі ми розглянемо деякі структури даних колекцій у стандартній бібліотеці, які ви можете використовувати у вашому акуратно організованому коді.
Загальні колекції (Common Collections)
Стандартна бібліотека Rust містить низку дуже корисних структур даних, які називаються колекціями. Більшість інших типів даних представляють одне конкретне значення, але колекції можуть містити кілька значень. На відміну від вбудованих типів масиву та кортежу, дані, на які вказують ці колекції, зберігаються на купі, що означає, що обсяг даних не потрібно знати під час компіляції, і він може зростати або зменшуватися під час виконання програми. Кожен вид колекції має різні можливості та витрати, і вибір відповідної для вашої поточної ситуації — це навичка, яку ви розвиватимете з часом. У цьому розділі ми обговоримо три колекції, які дуже часто використовуються в програмах Rust:
- вектор дозволяє вам зберігати змінну кількість значень поруч одне з одним.
- рядок — це колекція символів. Ми вже згадували тип
Stringраніше, але в цьому розділі ми поговоримо про нього докладно. - хеш-мапа дозволяє вам асоціювати значення з певним ключем. Це конкретна реалізація більш загальної структури даних, яка називається мапа.
Щоб дізнатися про інші види колекцій, які надає стандартна бібліотека, дивіться документацію.
Ми обговоримо, як створювати та оновлювати вектори, рядки та хеш-мапи, а також що робить кожну з них особливою.
Зберігання списків значень за допомогою векторів
Зберігання списків значень за допомогою векторів
Першим типом колекції, який ми розглянемо, є Vec<T>, також відомий як вектор.
Вектори дозволяють вам зберігати більше ніж одне значення в одній структурі даних, яка
розміщує всі значення поруч одне з одним у пам’яті. Вектори можуть зберігати лише значення
одного й того самого типу. Вони корисні, коли у вас є список елементів, таких як
рядки тексту у файлі або ціни елементів у кошику покупок.
Створення нового вектора
Щоб створити новий, порожній вектор, ми викликаємо функцію Vec::new, як показано в
Лістингу 8-1.
fn main() {
let v: Vec<i32> = Vec::new();
}Зверніть увагу, що ми додали тут анотацію типу. Оскільки ми не вставляємо жодних
значень у цей вектор, Rust не знає, який саме тип елементів ми маємо намір
зберігати. Це важливий момент. Вектори реалізовано за допомогою узагальнених типів;
ми розглянемо, як використовувати узагальнені типи у ваших власних типах, у Розділі 10. Поки що
знайте, що тип Vec<T>, наданий стандартною бібліотекою, може містити будь-який тип.
Коли ми створюємо вектор для зберігання певного типу, ми можемо вказати тип у
кутових дужках. У Лістингу 8-1 ми повідомили Rust, що Vec<T> у v буде
містити елементи типу i32.
Частіше ви створюватимете Vec<T> з початковими значеннями, і Rust виведе
тип значення, яке ви хочете зберігати, тож вам рідко потрібно робити цю анотацію
типу. Rust зручно надає макрос vec!, який створить
новий вектор, що містить значення, які ви йому дасте. Лістинг 8-2 створює новий
Vec<i32>, що містить значення 1, 2 і 3. Цілий тип є i32,
тому що це типовий цілий тип, як ми обговорювали в розділі “Типи даних” Розділу 3.
fn main() {
let v = vec![1, 2, 3];
}Оскільки ми надали початкові значення i32, Rust може вивести, що тип v
є Vec<i32>, і анотація типу не потрібна. Далі ми розглянемо, як
змінювати вектор.
Оновлення вектора
Щоб створити вектор, а потім додати до нього елементи, ми можемо використати метод push,
як показано в Лістингу 8-3.
fn main() {
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
}Як і для будь-якої змінної, якщо ми хочемо мати змогу змінювати її значення, нам потрібно
зробити її змінною за допомогою ключового слова mut, як обговорювалося в Розділі 3. Числа
, які ми розміщуємо всередині, усі мають тип i32, і Rust виводить це з даних, тож
нам не потрібна анотація Vec<i32>.
Читання елементів векторів
Є два способи посилатися на значення, що зберігається у векторі: через індексування або
за допомогою методу get. У наведених нижче прикладах ми додали анотації типів
значень, які повертаються з цих функцій, для додаткової ясності.
Лістинг 8-4 показує обидва методи доступу до значення у векторі, із синтаксисом індексування
та методом get.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("The third element is {third}");
let third: Option<&i32> = v.get(2);
match third {
Some(third) => println!("The third element is {third}"),
None => println!("There is no third element."),
}
}Зверніть увагу на кілька деталей тут. Ми використовуємо значення індексу 2, щоб отримати третій елемент
, тому що вектори індексуються за номером, починаючи з нуля. Використання & і []
дає нам посилання на елемент за значенням індексу. Коли ми використовуємо метод get
з переданим як аргумент індексом, ми отримуємо Option<&T>, який можемо
використовувати з match.
Rust надає ці два способи посилання на елемент, щоб ви могли вибирати, як програма поводитиметься, коли ви спробуєте використати значення індексу за межами існуючих елементів. Як приклад, давайте подивимося, що станеться, коли ми маємо вектор із п’яти елементів і потім намагаємося отримати доступ до елемента за індексом 100 обома техніками, як показано в Лістингу 8-5.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let does_not_exist = &v[100];
let does_not_exist = v.get(100);
}Коли ми запускаємо цей код, перший метод [] призведе до паніки програми,
тому що він посилається на неіснуючий елемент. Цей метод найкраще використовувати, коли ви
хочете, щоб ваша програма аварійно завершувалася, якщо є спроба отримати доступ до елемента за межами
кінця вектора.
Коли методу get передається індекс, що лежить поза межами вектора, він повертає
None без паніки. Ви б використовували цей метод, якщо доступ до елемента
поза межами вектора може інколи траплятися за нормальних
обставин. Тоді ваш код матиме логіку для обробки або
Some(&element), або None, як обговорювалося в Розділі 6. Наприклад, індекс
може надходити від людини, яка вводить число. Якщо вона випадково введе
занадто велике число, і програма отримає значення None, ви могли б повідомити
користувачу, скільки елементів є в поточному векторі, і дати йому ще одну спробу
ввести коректне значення. Це було б дружніше до користувача, ніж аварійне завершення програми
через друкарську помилку!
Коли програма має дійсне посилання, перевірник запозичень забезпечує правила володіння та запозичення (розглянуті в Розділі 4), щоб гарантувати, що це посилання та будь-які інші посилання на вміст вектора залишаються дійсними. Пригадайте правило, яке стверджує, що ви не можете мати змінні та незмінні посилання в одній і тій самій області видимості. Це правило застосовується в Лістингу 8-6, де ми тримаємо незмінне посилання на перший елемент у векторі й намагаємося додати елемент до кінця. Ця програма не працюватиме, якщо ми також спробуємо послатися на цей елемент пізніше у функції.
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}Компіляція цього коду призведе до такої помилки:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {first}");
| ----- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Код у Лістингу 8-6 може виглядати так, ніби він мав би працювати: чому посилання на перший елемент має зважати на зміни в кінці вектора? Ця помилка зумовлена тим, як працюють вектори: оскільки вектори розміщують значення поруч одне з одним у пам’яті, додавання нового елемента в кінець вектора може вимагати виділення нової пам’яті та копіювання старих елементів у новий простір, якщо немає достатньо місця, щоб розмістити всі елементи поруч один з одним там, де вектор зараз зберігається. У такому разі посилання на перший елемент буде вказувати на звільнену пам’ять. Правила запозичення запобігають тому, щоб програми опинялися в такій ситуації.
Примітка: Щоб дізнатися більше про деталі реалізації типу
Vec<T>, дивіться “The Rustonomicon”.
Ітерування по значеннях у векторі
Щоб послідовно отримати доступ до кожного елемента у векторі, ми ітерували б по всіх
елементах замість використання індексів для доступу до них по одному. Лістинг 8-7 показує, як
використати цикл for, щоб отримати незмінні посилання на кожен елемент у векторі
значень i32 і вивести їх.
fn main() {
let v = vec![100, 32, 57];
for i in &v {
println!("{i}");
}
}Ми також можемо ітерувати по змінних посиланнях на кожен елемент у змінному векторі,
щоби вносити зміни до всіх елементів. Цикл for у Лістингу 8-8
додасть 50 до кожного елемента.
fn main() {
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
}Щоб змінити значення, на яке вказує змінне посилання, ми маємо використати
оператор розіменування *, щоб дістатися до значення в i, перш ніж ми зможемо використати
оператор +=. Ми ще поговоримо більше про оператор розіменування в розділі “Перехід за посиланням до значення” Розділу 15.
Ітерація по вектору, чи то незмінно, чи то змінно, є безпечною завдяки
правилам перевірника запозичень. Якщо б ми спробували вставити або видалити елементи в тілах
циклу for у Лістингу 8-7 та у Лістингу 8-8, ми б отримали помилку компілятора,
подібну до тієї, яку отримали з кодом у Лістингу 8-6. Посилання на
вектор, яке тримає цикл for, запобігає одночасному зміненню всього вектора.
Використання перелічення для зберігання кількох типів
Вектори можуть зберігати лише значення одного й того самого типу. Це може бути незручно; безумовно, є випадки використання, коли потрібно зберігати список елементів різних типів. На щастя, варіанти перелічення визначаються під тим самим типом перелічення, тож коли нам потрібен один тип для представлення елементів різних типів, ми можемо визначити й використати перелічення!
Наприклад, скажімо, ми хочемо отримати значення з рядка в електронній таблиці, в якому деякі стовпці в рядку містять цілі числа, деякі числа з плаваючою комою, а деякі рядки. Ми можемо визначити перелічення, чиї варіанти зберігатимуть різні типи значень, і всі варіанти перелічення вважатимуться одним і тим самим типом: типом перелічення. Потім ми можемо створити вектор для зберігання цього перелічення і, таким чином, зрештою, зберігати різні типи. Ми продемонстрували це у Лістингу 8-9.
fn main() {
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("blue")),
SpreadsheetCell::Float(10.12),
];
}Rust потрібно знати, які типи будуть у векторі під час компіляції, щоб він
знав точно, скільки пам’яті на купі буде потрібно для зберігання кожного елемента.
Ми також маємо явно вказати, які типи дозволені в цьому векторі. Якби Rust
дозволив вектору містити будь-який тип, існувала б імовірність, що один або більше
типів спричинять помилки з операціями, виконаними над елементами
вектора. Використання перелічення разом із виразом match означає, що Rust забезпечить
під час компіляції, щоб було оброблено кожен можливий випадок, як обговорювалося в Розділі 6.
Якщо ви не знаєте повного набору типів, які програма отримає під час виконання, щоб зберегти їх у векторі, техніка з переліченням не працюватиме. Натомість ви можете використати об’єкт трейту, який ми розглянемо в Розділі 18.
Тепер, коли ми обговорили деякі з найпоширеніших способів використання векторів, обов’язково
перегляньте документацію API для всіх численних
корисних методів, визначених для Vec<T> стандартною бібліотекою. Наприклад, окрім
push, метод pop видаляє й повертає останній елемент.
Звільнення вектора звільняє його елементи
Як і будь-яка інша struct, вектор звільняється, коли виходить з області видимості, як
позначено у Лістингу 8-10.
fn main() {
{
let v = vec![1, 2, 3, 4];
// do stuff with v
} // <- v goes out of scope and is freed here
}Коли вектор звільняється, весь його вміст також звільняється, тобто цілі числа, які він містить, будуть очищені. Перевірник запозичень гарантує, що будь-які посилання на вміст вектора використовуються лише тоді, коли сам вектор є дійсним.
Перейдемо до наступного типу колекції: String!
Зберігання тексту в кодуванні UTF-8 за допомогою рядків
Зберігання UTF-8-кодованого тексту за допомогою String
Ми говорили про рядки в Розділі 4, але зараз розглянемо їх детальніше. Нові растацеанці (Rustaceans) часто застрягають на рядках з поєднання трьох причин: схильність Rust виявляти можливі помилки, рядки є складнішою структурою даних, ніж багато програмістів вважають, і UTF-8. Ці чинники поєднуються так, що це може здаватися складним, коли ви переходите з інших мов програмування.
Ми обговорюємо рядки в контексті колекцій, тому що рядки реалізовані як колекція байтів, плюс деякі методи, щоб забезпечити корисну функціональність, коли ці байти інтерпретуються як текст. У цьому розділі ми поговоримо про операції над String, які є в кожного типу колекції, такі як створення, оновлення та читання. Ми також обговоримо способи, у які String відрізняється від інших колекцій, а саме — як індексування в String ускладнюється відмінностями між тим, як люди та комп’ютери інтерпретують дані String.
Визначення рядків (Strings)
Спочатку ми визначимо, що мається на увазі під терміном string. Rust має лише один тип рядка в основній мові, а саме слайс рядка str, який зазвичай бачать у його запозиченій формі, &str. У розділі 4 ми говорили про слайси рядків, які є посиланнями на деякі UTF-8-кодовані дані рядка, що зберігаються в іншому місці. Рядкові літерали, наприклад, зберігаються в бінарному файлі програми і, отже, є слайсами рядка.
Тип String, який надається стандартною бібліотекою Rust, а не вбудований в основну мову, — це зростаючий, змінний, власний UTF-8-кодований тип рядка. Коли растацеанці (Rustaceans) кажуть про “strings” у Rust, вони можуть мати на увазі або тип String, або слайс рядка &str, а не лише один із цих типів. Хоча цей розділ здебільшого про String, обидва типи широко використовуються в стандартній бібліотеці Rust, і і String, і слайси рядка є UTF-8-кодованими.
Створення нового String
Багато з тих самих операцій, доступних з Vec<T>, також доступні з String, тому що String насправді реалізований як обгортка навколо вектора байтів із деякими додатковими гарантіями, обмеженнями та можливостями. Прикладом функції, яка працює так само з Vec<T> і String, є функція new для створення екземпляра, показана в Лістингу 8-11.
fn main() {
let mut s = String::new();
}Цей рядок створює новий порожній рядок під назвою s, у який ми потім можемо завантажити дані. Часто в нас буде деякі початкові дані, з яких ми хочемо почати рядок. Для цього ми використовуємо метод to_string, який доступний для будь-якого типу, що реалізує трейт Display, як це роблять рядкові літерали. Лістинг 8-12 показує два приклади.
fn main() {
let data = "initial contents";
let s = data.to_string();
// The method also works on a literal directly:
let s = "initial contents".to_string();
}Цей код створює рядок, що містить initial contents.
Ми також можемо використати функцію String::from, щоб створити String із рядкового літерала. Код у Лістингу 8-13 еквівалентний коду в Лістингу 8-12, який використовує to_string.
fn main() {
let s = String::from("initial contents");
}Оскільки рядки використовуються для дуже багатьох речей, ми можемо використовувати багато різних узагальнених API для рядків, що надає нам багато варіантів. Деякі з них можуть здаватися надлишковими, але кожен має своє місце! У цьому випадку String::from і to_string роблять одне й те саме, тож який із них ви оберете — це питання стилю та читабельності.
Пам’ятайте, що рядки є UTF-8-кодованими, тож ми можемо включати в них будь-які правильно закодовані дані, як показано у Лістингу 8-14.
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Усі ці значення є дійсними String.
Оновлення String
String може збільшуватися в розмірі, і його вміст може змінюватися, так само як вміст Vec<T>, якщо ви додаєте в нього більше даних. Крім того, ви можете зручно використовувати оператор + або макрос format!, щоб конкатенувати значення String.
Додавання за допомогою push_str або push
Ми можемо збільшувати String, використовуючи метод push_str для додавання слайса рядка, як показано у Лістингу 8-15.
fn main() {
let mut s = String::from("foo");
s.push_str("bar");
}Після цих двох рядків s міститиме foobar. Метод push_str приймає слайс рядка, тому що ми не обов’язково хочемо брати володіння над параметром. Наприклад, у коді у Лістингу 8-16 ми хочемо мати змогу використовувати s2 після додавання його вмісту до s1.
fn main() {
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("s2 is {s2}");
}Якби метод push_str брав володіння над s2, ми не змогли б надрукувати його значення в останньому рядку. Однак цей код працює так, як ми й очікували!
Метод push приймає один символ як параметр і додає його до String. Лістинг 8-17 додає літеру l до String за допомогою методу push.
fn main() {
let mut s = String::from("lo");
s.push('l');
}У результаті s міститиме lol.
Конкатенація за допомогою + або format!
Часто вам потрібно буде об’єднати два наявні рядки. Один зі способів зробити це — використати оператор +, як показано у Лістингу 8-18.
fn main() {
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used
}Рядок s3 міститиме Hello, world!. Причина, чому s1 більше не є дійсним після додавання, і причина, чому ми використали посилання на s2, пов’язані з сигнатурою методу, який викликається, коли ми використовуємо оператор +. Оператор + використовує метод add, сигнатура якого виглядає приблизно так:
fn add(self, s: &str) -> String {У стандартній бібліотеці ви побачите, що add визначено з використанням узагальнених типів і асоційованих типів. Тут ми підставили конкретні типи, що і відбувається, коли ми викликаємо цей метод зі значеннями String. Ми обговоримо узагальнені типи в Розділі 10. Ця сигнатура дає нам підказки, потрібні для того, щоб зрозуміти складні моменти оператора +.
По-перше, s2 має &, що означає, що ми додаємо посилання на другий рядок до першого рядка. Це пов’язано з параметром s у функції add: ми можемо додати лише слайс рядка до String; ми не можемо додати два значення String разом. Але зачекайте — тип &s2 є &String, а не &str, як зазначено в другому параметрі add. Тож чому Лістингу 8-18 компілюється?
Причина, через яку ми можемо використати &s2 у виклику add, полягає в тому, що компілятор може перетворити аргумент &String на &str. Коли ми викликаємо метод add, Rust використовує приведення при розіменуванні (deref coercion), яке тут перетворює &s2 на &s2[..]. Ми обговоримо приведення при розіменуванні детальніше в Розділі 15. Оскільки add не бере володіння над параметром s, s2 усе ще буде дійсним String після цієї операції.
По-друге, ми можемо побачити в сигнатурі, що add бере володіння над self, тому що self не має &. Це означає, що s1 у Лістингу 8-18 буде переміщено в виклик add і більше не буде дійсним після цього. Отже, хоча let s3 = s1 + &s2; виглядає так, ніби воно скопіює обидва рядки та створить новий, цей оператор насправді бере володіння над s1, додає копію вмісту s2, а потім повертає володіння над результатом. Іншими словами, виглядає так, ніби він робить багато копій, але це не так; реалізація ефективніша за копіювання.
Якщо нам потрібно конкатенувати кілька рядків, поведінка оператора + стає громіздкою:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;
}На цьому етапі s буде tic-tac-toe. З усіма символами + і " важко зрозуміти, що відбувається. Для об’єднання рядків більш складними способами ми натомість можемо використати макрос format!:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{s1}-{s2}-{s3}");
}Цей код також встановлює s у tic-tac-toe. Макрос format! працює як println!, але замість того, щоб друкувати вивід на екран, він повертає String із вмістом. Версія коду з використанням format! набагато легше читається, а код, згенерований макросом format!, використовує посилання, тож цей виклик не бере володіння над жодним зі своїх параметрів.
Індексування в рядках
У багатьох інших мовах програмування доступ до окремих символів у рядку шляхом посилання на них за індексом є дійсною і поширеною операцією. Однак якщо ви спробуєте отримати доступ до частин String за допомогою синтаксису індексування в Rust, ви отримаєте помилку. Розгляньте недійсний код у Лістингу 8-19.
fn main() {
let s1 = String::from("hi");
let h = s1[0];
}Цей код призведе до такої помилки:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:16
|
3 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the following other types implement trait `SliceIndex<T>`:
`usize` implements `SliceIndex<ByteStr>`
`usize` implements `SliceIndex<[T]>`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Помилка розповідає історію: рядки Rust не підтримують індексування. Але чому? Щоб відповісти на це запитання, нам потрібно обговорити, як Rust зберігає рядки в пам’яті.
Внутрішнє представлення
String — це обгортка над Vec<u8>. Розгляньмо деякі наші правильно закодовані приклади UTF-8-рядків із Лістингу 8-14. Спочатку ось цей:
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}У цьому випадку len буде 4, що означає, що вектор, який зберігає рядок "Hola", має довжину 4 байти. Кожна з цих літер займає 1 байт у кодуванні UTF-8. Наступний рядок, однак, може вас здивувати (зверніть увагу, що цей рядок починається з великої кириличної літери (Ze) Зе, а не з цифри 3):
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Якби вас запитали, якою є довжина рядка, ви могли б сказати 12. Насправді відповідь Rust — 24: це кількість байтів, потрібних, щоб закодувати “Здравствуйте” у UTF-8, тому що кожне скалярне значення Unicode в цьому рядку займає 2 байти пам’яті. Отже, індекс у байтах рядка не завжди відповідатиме дійсному скалярному значенню Unicode. Щоб продемонструвати це, розгляньте цей недійсний код Rust:
let hello = "Здравствуйте";
let answer = &hello[0];Ви вже знаєте, що answer не буде З, першою літерою. У UTF-8 перший байт З — це 208, а другий — 151, тож може здаватися, що answer насправді має бути 208, але 208 не є дійсним символом сам по собі. Повернення 208 імовірно не було б тим, чого користувач хотів би, якби попросив першу літеру цього рядка; однак це єдині дані, які Rust має в байтовому індексі 0. Користувачі загалом не хочуть, щоб поверталося байтове значення, навіть якщо рядок містить лише латинські літери: якби &"hi"[0] був дійсним кодом, що повертає байтове значення, він повернув би 104, а не h.
Отже, відповідь така: щоб уникнути повернення неочікуваного значення та спричинення помилок, які можуть бути виявлені не одразу, Rust взагалі не компілює цей код і запобігає непорозумінням на ранньому етапі процесу розробки.
Байти, скалярні значення та графемні кластери
Ще один момент про UTF-8 полягає в тому, що насправді є три відповідні способи дивитися на рядки з точки зору Rust: як на байти, скалярні значення та графемні кластери (найближче до того, що ми називали б літерами).
Якщо ми подивимося на хіндійське слово “नमस्ते”, написане письмом деванагарі, воно зберігається як вектор значень u8, який виглядає так:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
Це 18 байтів, і саме так комп’ютери зрештою зберігають ці дані. Якщо ми подивимося на них як на скалярні значення Unicode, якими є значення типу char у Rust, ці байти виглядають так:
['न', 'म', 'स', '्', 'त', 'े']
Тут є шість значень char, але четверте і шосте — не літери: це діакритичні знаки, які самі по собі не мають сенсу. Нарешті, якщо ми подивимося на них як на графемні кластери, ми отримаємо те, що людина назвала б чотирма літерами, з яких складається хіндійське слово:
["न", "म", "स्", "ते"]
Rust надає різні способи інтерпретації сирих рядкових даних, які зберігають комп’ютери, щоб кожна програма могла вибрати інтерпретацію, яка їй потрібна, незалежно від того, якою людською мовою є ці дані.
Остання причина, чому Rust не дозволяє нам індексувати в String, щоб отримати символ, полягає в тому, що операції індексування очікуються такими, що завжди займають константний час (O(1)). Але з String неможливо гарантувати таку продуктивність, тому що Rust довелося б пройтися по вмісту від початку до індексу, щоб визначити, скільки було дійсних символів.
Зрізи рядків (String Slicing)
Індексування в рядку часто є поганою ідеєю, тому що незрозуміло, яким має бути тип повернення операції індексування рядка: байтове значення, символ, графемний кластер чи слайс рядка. Тому, якщо вам справді потрібно використовувати індекси для створення слайсів рядка, Rust просить вас бути точнішими.
Замість індексування за допомогою [] з одним числом, ви можете використовувати [] з діапазоном, щоб створити слайс рядка, що містить певні байти:
#![allow(unused)]
fn main() {
let hello = "Здравствуйте";
let s = &hello[0..4];
}Тут s буде &str, що містить перші 4 байти рядка. Раніше ми згадували, що кожен із цих символів мав 2 байти, а це означає, що s буде Зд.
Якби ми спробували зробити слайс лише частини байтів символу за допомогою чогось на кшталт &hello[0..1], Rust би згенерував паніку під час виконання так само, як це було б при доступі до недійсного індексу у векторі:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Ви повинні бути обережні, коли створюєте слайси рядка за допомогою діапазонів, тому що це може призвести до аварійного завершення вашої програми.
Ітерування по рядках
Найкращий спосіб працювати з частинами рядків — чітко визначити, чи ви хочете символи, чи байти. Для окремих скалярних значень Unicode використовуйте метод chars. Виклик chars для “Зд” розділяє та повертає два значення типу char, і ви можете ітерувати по результату, щоб отримати доступ до кожного елемента:
#![allow(unused)]
fn main() {
for c in "Зд".chars() {
println!("{c}");
}
}Цей код надрукує таке:
З
д
Альтернативно, метод bytes повертає кожен сирий байт, що може бути доречним для вашої предметної області:
#![allow(unused)]
fn main() {
for b in "Зд".bytes() {
println!("{b}");
}
}Цей код надрукує 4 байти, з яких складається цей рядок:
208
151
208
180
Але не забудьте, що дійсні скалярні значення Unicode можуть складатися більш ніж з 1 байта.
Отримання графемних кластерів із рядків, як у письмі деванагарі, є складним, тому ця функціональність не надається стандартною бібліотекою. Крейтів доступно на crates.io, якщо це потрібна вам функціональність.
Обробка складнощів рядків
Підсумовуючи, рядки складні. Різні мови програмування роблять різний вибір щодо того, як показувати цю складність програмісту. Rust обрав зробити правильну обробку даних String поведінкою за замовчуванням для всіх програм Rust, що означає, що програмістам доводиться заздалегідь більше думати про обробку UTF-8-даних. Цей компроміс виявляє більше складності рядків, ніж це видно в інших мовах програмування, але він позбавляє вас необхідності пізніше у вашому життєвому циклі розробки обробляти помилки, пов’язані з не-ASCII-символами.
Добра новина полягає в тому, що стандартна бібліотека пропонує багато функціональності, побудованої на типах String і &str, щоб правильно допомагати обробляти такі складні ситуації. Обов’язково перегляньте документацію для корисних методів, таких як contains для пошуку в рядку та replace для заміни частин рядка іншим рядком.
Давайте перейдемо до чогось трохи менш складного: хеш-мапи!
Зберігання ключів із пов'язаними значеннями в hash map
Зберігання ключів із пов’язаними значеннями в хеш-мапах (Storing Keys with Associated Values in Hash Maps)
Останньою з наших загальних колекцій є хеш-мапа. Тип HashMap<K, V>
зберігає відображення ключів типу K у значення типу V, використовуючи функцію
хешування, яка визначає, як вона розміщує ці ключі та значення в пам’яті.
Багато мов програмування підтримують цей вид структури даних, але вони часто
використовують іншу назву, наприклад hash, map, object, hash table,
dictionary або associative array, щоб назвати лише деякі.
Хеш-мапи корисні, коли ви хочете шукати дані не за індексом, як це можна робити з векторами, а за ключем, який може бути будь-якого типу. Наприклад, у грі ви могли б відстежувати рахунок кожної команди в хеш-мапі, у якій кожен ключ — це назва команди, а значення — це рахунок кожної команди. Маючи назву команди, ви можете отримати її рахунок.
У цьому розділі ми розглянемо базовий API хеш-мап, але багато інших переваг
приховано у функціях, визначених для HashMap<K, V> стандартною бібліотекою.
Як завжди, дивіться документацію стандартної бібліотеки для отримання додаткової інформації.
Створення нової хеш-мапи
Один зі способів створити порожню хеш-мапу — це використати new і додавати елементи за допомогою
insert. У Лістингу 8-20 ми відстежуємо рахунки двох команд, чиї
назви — Blue та Yellow. Команда Blue починає з 10 очок, а
команда Yellow починає з 50.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
}Зверніть увагу, що спочатку нам потрібно use HashMap із розділу колекцій
стандартної бібліотеки. Із наших трьох загальних колекцій ця використовується
найрідше, тому вона не входить до можливостей, які автоматично
підключаються в область видимості в prelude. Хеш-мапи також мають меншу
підтримку з боку стандартної бібліотеки; наприклад, для їх створення немає вбудованого макроса.
Так само, як і вектори, хеш-мапи зберігають свої дані в купі. Ця HashMap має
ключі типу String і значення типу i32. Як і вектори, хеш-мапи є
однорідними: усі ключі мають мати той самий тип, і всі значення
мають мати той самий тип.
Доступ до значень у хеш-мапі
Ми можемо отримати значення з хеш-мапи, передавши її ключ у метод get,
як показано у Лістингу 8-21.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
let team_name = String::from("Blue");
let score = scores.get(&team_name).copied().unwrap_or(0);
}Тут score матиме значення, пов’язане з командою Blue, і
результат буде 10. Метод get повертає Option<&V>; якщо для цього ключа в хеш-мапі
немає значення, get поверне None. Ця програма
обробляє Option, викликаючи copied, щоб отримати Option<i32> замість
Option<&i32>, а потім unwrap_or, щоб встановити score у нуль, якщо scores не
має запису для цього ключа.
Ми можемо ітеруватися по кожній парі ключ-значення в хеш-мапі подібним способом,
як це робимо з векторами, використовуючи цикл for:
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
for (key, value) in &scores {
println!("{key}: {value}");
}
}Цей код надрукує кожну пару в довільному порядку:
Yellow: 50
Blue: 10
Керування володінням в хеш-мапах
Для типів, що реалізують трейт Copy, як-от i32, значення копіюються
в хеш-мапу. Для значень, що належать комусь, як-от String, значення будуть переміщені, і
хеш-мапа буде володільцем цих значень, як показано у Лістингу 8-22.
fn main() {
use std::collections::HashMap;
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value);
// field_name and field_value are invalid at this point, try using them and
// see what compiler error you get!
}Ми не можемо використовувати змінні field_name і field_value після
того, як їх було переміщено в хеш-мапу під час виклику insert.
Якщо ми вставляємо посилання на значення в хеш-мапу, значення не будуть переміщені в хеш-мапу. Значення, на які вказують посилання, мають бути дійсними протягом принаймні такого самого часу, як і хеш-мапа. Ми ще поговоримо про ці питання в “Validating References with Lifetimes” у Розділі 10.
Оновлення хеш-мапи
Хоча кількість пар ключів і значень може збільшуватися, кожен унікальний ключ може
мати лише одне значення, пов’язане з ним, у певний момент часу (але не навпаки: наприклад,
і команда Blue, і команда Yellow могли б мати значення 10,
збережене в хеш-мапі scores).
Коли ви хочете змінити дані в хеш-мапі, ви маєте вирішити, як обробити випадок, коли ключ уже має призначене значення. Ви можете замінити старе значення новим, повністю ігноруючи старе значення. Ви можете залишити старе значення та ігнорувати нове, додаючи нове значення лише якщо ключ не вже має значення. Або ви можете поєднати старе значення і нове значення. Давайте подивимося, як зробити кожен із цих варіантів!
Перезапис значення
Якщо ми вставляємо ключ і значення в хеш-мапу, а потім вставляємо той самий ключ
з іншим значенням, значення, пов’язане з цим ключем, буде замінено.
Хоча код у Лістингу 8-23 двічі викликає insert, хеш-мапа
міститиме лише одну пару ключ-значення, тому що ми вставляємо значення для ключа
команди Blue обидва рази.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 25);
println!("{scores:?}");
}Цей код надрукує {"Blue": 25}. Початкове значення 10 було
перезаписано.
Додавання ключа і значення лише якщо ключ відсутній
Часто потрібно перевірити, чи існує певний ключ уже в хеш-мапі зі значенням, а потім виконати такі дії: якщо ключ дійсно існує в хеш-мапі, наявне значення має залишитися без змін; якщо ключ не існує, вставте його та значення для нього.
Хеш-мапи мають для цього спеціальний API під назвою entry, який приймає ключ,
який ви хочете перевірити, як параметр. Значення, що повертається методом entry, — це перелічення
під назвою Entry, який представляє значення, яке може існувати або не існувати. Припустімо,
ми хочемо перевірити, чи має ключ для команди Yellow пов’язане з ним
значення. Якщо ні, ми хочемо вставити значення 50, і те саме для
команди Blue. Використовуючи API entry, код виглядає як у Лістингу 8-24.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.entry(String::from("Yellow")).or_insert(50);
scores.entry(String::from("Blue")).or_insert(50);
println!("{scores:?}");
}Метод or_insert у Entry визначено так, що він повертає змінне посилання на
значення для відповідного ключа Entry, якщо цей ключ існує, а якщо ні, він
вставляє параметр як нове значення для цього ключа і повертає змінне
посилання на нове значення. Ця техніка набагато чистіша, ніж написання
логіки самостійно, і, крім того, краще узгоджується з перевірником запозичень.
Запуск коду у Лістингу 8-24 надрукує {"Yellow": 50, "Blue": 10}. Перший
виклик entry вставить ключ для команди Yellow зі значенням
50, тому що команда Yellow уже не має значення. Другий виклик
entry не змінить хеш-мапу, тому що команда Blue уже має
значення 10.
Оновлення значення на основі старого значення
Інший поширений випадок використання хеш-мап — це пошук значення ключа, а потім
оновлення його на основі старого значення. Наприклад, у Лістингу 8-25 показано код, який
підраховує, скільки разів кожне слово з’являється в певному тексті, використовуючи
хеш-мапу, де ключі — це слова, а значення — це кількість входжень для
цього слова. Якщо це перший раз, коли ми бачимо слово, ми спочатку вставимо
значення 0.
fn main() {
use std::collections::HashMap;
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1;
}
println!("{map:?}");
}Цей код надрукує {"world": 2, "hello": 1, "wonderful": 1}. Ви можете побачити
ті самі пари ключ-значення, надруковані в іншому порядку: пригадайте з “Доступ до значень у хеш-мапі”, що ітерація по хеш-мапі
відбувається в довільному порядку.
Метод split_whitespace повертає ітератор по підзрізах, розділених
пробільними символами, значення в text. Метод or_insert повертає змінне
посилання (&mut V) на значення для вказаного ключа. Тут ми зберігаємо це
змінне посилання в змінній count, тож щоб присвоїти це значення,
ми спочатку маємо розіменувати count за допомогою зірочки (*). Змінне
посилання виходить з області видимості наприкінці циклу for, тому всі ці
зміни є безпечними й дозволеними правилами запозичення.
Функції хешування
За замовчуванням HashMap використовує функцію хешування під назвою SipHash, яка може забезпечити
захист від атак відмови в обслуговуванні (DoS), пов’язаних із хеш-таблицями1. Це не
найшвидший доступний алгоритм хешування, але компроміс заради кращої безпеки, який
супроводжується падінням продуктивності, того вартий. Якщо ви профілюєте свій код і виявите, що
типова функція хешування занадто повільна для ваших потреб, ви можете переключитися на іншу функцію,
вказавши інший хешер. Хешер — це тип, який реалізує
трейт BuildHasher. Ми поговоримо про трейти та про те, як їх реалізовувати, у
Розділі 10. Вам не обов’язково реалізовувати
власний хешер з нуля; crates.io
має бібліотеки, якими діляться інші користувачі Rust і які надають хешери, що реалізують багато
поширених алгоритмів хешування.
Підсумок
Вектори, рядки та хеш-мапи надають велику кількість функціональності, необхідної в програмах, коли вам потрібно зберігати, отримувати доступ і змінювати дані. Ось кілька вправ, які тепер ви маєте змогу розв’язати:
- Маючи список цілих чисел, використайте вектор і поверніть медіану (після сортування значення в серединній позиції) і моду (значення, яке трапляється найчастіше; тут буде корисною хеш-мапа) списку.
- Перетворіть рядки на Pig Latin. Першу приголосну кожного слова переміщено в кінець слова, і додається ay, тож first стає irst-fay. Слова, що починаються з голосної, натомість отримують додане в кінці hay (apple стає apple-hay). Пам’ятайте про деталі кодування UTF-8!
- Використовуючи хеш-мапу та вектори, створіть текстовий інтерфейс, щоб дозволити користувачу додавати імена працівників до відділу в компанії; наприклад, “Add Sally to Engineering” або “Add Amir to Sales.” Потім дозвольте користувачу отримати список усіх людей у відділі або всіх людей у компанії за відділами, відсортований за абеткою.
Документація API стандартної бібліотеки описує методи, які мають вектори, рядки та хеш-мапи, і які будуть корисні для цих вправ!
Ми переходимо до складніших програм, у яких операції можуть зазнавати збоїв, тож це ідеальний час, щоб обговорити обробку помилок. Далі ми зробимо саме це!
Обробка помилок (Error Handling)
Помилки — це факт життя в програмному забезпеченні, тому Rust має низку можливостей для обробки ситуацій, у яких щось іде не так. У багатьох випадках Rust вимагає від вас визнати можливість помилки та вжити певних дій, перш ніж ваш код буде скомпільовано. Ця вимога робить вашу програму надійнішою, гарантуючи, що ви виявите помилки й обробите їх належним чином до того, як розгорнете ваш код у промислове середовище (production)!
Rust поділяє помилки на дві основні категорії: відновлювані та невідновлювані помилки. Для відновлюваної помилки, такої як помилка file not found, ми найімовірніше просто хочемо повідомити про проблему користувачу та повторити операцію. Невідновлювані помилки завжди є симптомами багів, таких як спроба отримати доступ до розташування за межами кінця масиву, і тому ми хочемо негайно зупинити програму.
Більшість мов не розрізняють ці два види помилок і обробляють
обидва однаково, використовуючи механізми на кшталт виключень (exceptions). У Rust немає
виключень (exceptions). Натомість він має тип Result<T, E> для відновлюваних помилок і
макрос panic!, який зупиняє виконання, коли програма стикається з
невідновлюваною помилкою. У цьому розділі спочатку розглядається виклик panic!, а потім
говориться про повернення значень Result<T, E>. Додатково ми дослідимо
міркування під час визначення, чи намагатися відновитися після помилки, чи зупинити
виконання.
Невідновлювані помилки з panic!
Невідновлювані помилки з panic!
Іноді у вашому коді трапляються погані речі, і ви нічого не можете з цим
зробити. У цих випадках у Rust є макрос panic!. У практиці є два способи
спричинити паніку: вчинити дію, яка спричиняє паніку нашого коду (наприклад,
звернення до масиву за його межами) або явно викликати макрос panic!.
В обох випадках ми спричиняємо паніку в нашій програмі. За замовчуванням ці
паніки друкуватимуть повідомлення про збій, розгортатимуться, очищатимуть
стек і завершуватимуть роботу. Через змінну середовища ви також можете
змусити Rust показувати зворотне трасування (backtrace) стека викликів, коли трапляється паніка, щоб легше
було відстежити джерело паніки.
Розгортання стека або аварійне завершення у відповідь на паніку
За замовчуванням, коли трапляється паніка, програма починає розгортання, що означає, що Rust рухається назад угору по стеку й очищає дані з кожної функції, яку зустрічає. Однак рух назад і очищення — це багато роботи. Тому Rust дає вам змогу вибрати альтернативу негайного аварійного завершення, яке завершує програму без очищення.
Пам’ять, яку програма використовувала, тоді потрібно буде очистити операційній системі. Якщо у вашому проєкті вам потрібно зробити отриманий двійковий файл якомога меншим, ви можете перемкнутися з розгортання на аварійне завершення під час паніки, додавши
panic = 'abort'до відповідних розділів[profile]у вашому файлі Cargo.toml. Наприклад, якщо ви хочете аварійно завершуватися під час паніки в фінальному (release) режимі, додайте це:[profile.release] panic = 'abort'
Спробуймо викликати panic! у простій програмі:
fn main() {
panic!("crash and burn");
}Коли ви запустите програму, ви побачите щось подібне до цього:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
crash and burn
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Виклик panic! спричиняє повідомлення про помилку, що міститься в останніх
двох рядках. Перший рядок показує наше повідомлення про паніку і місце у нашому
вихідному коді, де сталася паніка: src/main.rs:2:5 означає, що це другий
рядок, п’ятий символ нашого файлу src/main.rs.
У цьому випадку вказаний рядок є частиною нашого коду, і якщо ми перейдемо до
цього рядка, то побачимо виклик макроса panic!. В інших випадках виклик
panic! може бути в коді, який викликає наш код, і назва файлу та номер рядка,
зазначені в повідомленні про помилку, будуть кодом когось іншого, де
викликається макрос panic!, а не рядком нашого коду, який зрештою призвів
до виклику panic!.
Ми можемо використати зворотне трасування (backtrace) функцій, з яких було викликано panic!, щоб
з’ясувати ту частину нашого коду, яка спричиняє проблему. Щоб зрозуміти, як
використовувати зворотне трасування (backtrace) panic!, давайте подивимося на ще один приклад і
побачимо, як це виглядає, коли виклик panic! надходить з бібліотеки через
помилку в нашому коді, а не від прямого виклику макроса нашим кодом. Лістинг 9-1 містить код, який намагається звернутися до індексу в векторі за межами
діапазону допустимих індексів.
fn main() {
let v = vec![1, 2, 3];
v[99];
}Тут ми намагаємося отримати доступ до 100-го елемента нашого вектора (який
знаходиться за індексом 99, оскільки індексація починається з нуля), але
вектор має лише три елементи. У цій ситуації Rust панікуватиме. Використання
[] має повертати елемент, але якщо ви передаєте недійсний індекс, тут немає
елемента, який Rust міг би повернути і який був би правильним.
У C спроба прочитати за кінцем структури даних є невизначеною поведінкою (undefined behavior). Ви можете отримати те, що знаходиться в розташуванні в пам’яті, яке відповідало б цьому елементу в структурі даних, навіть якщо ця пам’ять не належить цій структурі. Це називається читанням за межами буфера (buffer overread) і може призвести до вразливостей безпеки, якщо зловмисник може маніпулювати індексом так, щоб прочитати дані, до яких йому не слід мати доступу, і які зберігаються після структури даних.
Щоб захистити вашу програму від такого роду вразливості, якщо ви спробуєте прочитати елемент за неіснуючим індексом, Rust зупинить виконання і відмовиться продовжувати. Спробуймо це і подивімося:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Ця помилка вказує на рядок 4 нашого main.rs, де ми намагаємося отримати
доступ до індексу 99 вектора в v.
Рядок note: повідомляє нам, що ми можемо встановити змінну середовища
RUST_BACKTRACE, щоб отримати зворотне трасування (backtrace) того, що саме сталося і спричинило
помилку. Зворотне трасування (backtrace) — це список усіх функцій, які було викликано, щоб
дійти до цього моменту. Зворотне трасування в Rust працює так само, як і в інших
мовах: ключ до читання зворотного трасування — почати зверху й читати, доки ви не побачите
файли, які написали ви. Це місце, де виникла проблема. Рядки вище цього місця —
це код, який викликав ваш код; рядки нижче — це код, який викликав ваш код. Ці
рядки до і після можуть включати код core Rust, код стандартної бібліотеки або
крейти, які ви використовуєте. Спробуймо отримати зворотне трасування, встановивши змінну
середовища RUST_BACKTRACE у будь-яке значення, крім 0. Лістинг 9-2 показує
вивід, подібний до того, який ви побачите.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
Це багато виводу! Точний вивід, який ви бачите, може відрізнятися залежно від
вашої операційної системи та версії Rust. Щоб отримувати зворотне трасування (backtrace) з цією
інформацією, мають бути увімкнені символи налагодження. Символи налагодження
вмикаються за замовчуванням під час використання cargo build або cargo run
без прапорця --release, як ми робимо тут.
У виводі у Лістингу 9-2 рядок 6 зворотного трасування вказує на рядок у нашому проєкті, який спричиняє проблему: рядок 4 у src/main.rs. Якщо ми не хочемо, щоб наша програма панікувала, ми маємо почати наше розслідування з місця, на яке вказує перший рядок, що згадує файл, який ми написали. У Лістингу 9-1, де ми навмисно написали код, який панікуватиме, способом виправити паніку є не запитувати елемент за межами діапазону індексів вектора. Коли ваш код у майбутньому панікуватиме, вам потрібно буде з’ясувати, яку дію код виконує і з якими значеннями, щоб спричинити паніку, і що код має робити замість цього.
Ми повернемося до panic! і до того, коли ми повинні і коли не повинні
використовувати panic! для обробки умов помилок, у розділі “Панікувати чи не
панікувати” пізніше в цьому
розділі. Далі ми подивимося, як відновитися після помилки за допомогою Result.
Відновлювані помилки з Result
Відновлювані помилки з Result
Більшість помилок недостатньо серйозні, щоб вимагати повної зупинки програми. Іноді, коли функція завершується невдачею, це відбувається з причини, яку ви можете легко інтерпретувати і на яку можете відповісти. Наприклад, якщо ви намагаєтеся відкрити файл і ця операція завершується невдачею, тому що файл не існує, ви можете захотіти створити файл замість завершення процесу.
Пригадайте з “Обробка можливої невдачі за допомогою Result” у Розділі 2, що перелічення Result визначено як такий, що має два
варіанти, Ok і Err, ось так:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}T і E — це узагальнені (generic) параметри типу: ми докладніше обговоримо узагальнені
типи в Розділі 10. Що вам потрібно знати зараз, так це те, що T представляє
тип значення, яке буде повернено в разі успіху у варіанті Ok, а E
представляє тип помилки, яка буде повернена в разі невдачі у варіанті Err.
Оскільки Result має ці узагальнені параметри типу, ми можемо використовувати
тип Result і функції, визначені для нього, в багатьох різних ситуаціях, де
значення успіху і значення помилки, які ми хочемо повернути, можуть
відрізнятися.
Давайте назвемо функцію, яка повертає значення Result, такою, що може
завершитися невдачею. У Лістингу 9-3 ми намагаємося відкрити файл.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
}Тип повернення File::open — Result<T, E>. Узагальнений параметр T був
заповнений реалізацією File::open типом значення успіху, std::fs::File,
який є файловим дескриптором. Тип E, що використовується у значенні помилки,
— std::io::Error. Цей тип повернення означає, що виклик File::open може
завершитися успіхом і повернути файловий дескриптор, з якого ми можемо читати
або в який можемо записувати. Виклик функції також може завершитися невдачею:
наприклад, файл може не існувати, або ми можемо не мати дозволу на доступ до
файлу. Функція File::open потребує способу повідомити нам, чи вона
завершилася успіхом, чи невдачею, і водночас дати нам або файловий дескриптор,
або інформацію про помилку. Саме цю інформацію і передає перелічення Result.
У випадку, коли File::open завершується успіхом, значення в змінній
greeting_file_result буде екземпляром Ok, що містить файловий дескриптор.
У випадку, коли вона завершується невдачею, значення в greeting_file_result
буде екземпляром Err, що містить більше інформації про тип помилки, яка
виникла.
Нам потрібно додати до коду в Лістингу 9-3, щоб виконувати різні дії залежно
від значення, яке повертає File::open. Лістинг 9-4 показує один зі способів
обробити Result за допомогою базового інструмента — виразу match, про який
ми говорили в Розділі 6.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => panic!("Problem opening the file: {error:?}"),
};
}Зверніть увагу, що, як і перелічення Option, перелічення Result і його варіанти
були внесені в область видимості завдяки prelude, тож нам не потрібно
вказувати Result:: перед варіантами Ok і Err у гілках match.
Коли результат — Ok, цей код поверне внутрішнє значення file з варіанта
Ok, і тоді ми присвоїмо це значення файлового дескриптора змінній
greeting_file. Після match ми можемо використовувати файловий дескриптор
для читання або запису.
Інша гілка match обробляє випадок, коли ми отримуємо значення Err від
File::open. У цьому прикладі ми вирішили викликати макрос panic!. Якщо в
нашому поточному каталозі немає файлу з назвою hello.txt і ми запустимо цей
код, ми побачимо такий вивід від макроса panic!:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at src/main.rs:8:23:
Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Як зазвичай, цей вивід точно повідомляє нам, що саме пішло не так.
Зіставлення з різними помилками
Код у Лістингу 9-4 викличе panic! незалежно від того, чому File::open
завершився невдачею.
Однак ми хочемо виконувати різні дії для різних причин невдачі. Якщо
File::open завершився невдачею тому, що файл не існує, ми хочемо створити
файл і повернути дескриптор нового файлу. Якщо File::open завершився
невдачею з будь-якої іншої причини — наприклад, тому що ми не мали дозволу на
відкриття файлу — ми все одно хочемо, щоб код викликав panic! так само, як
це було у Лістингу 9-4. Для цього ми додаємо внутрішній вираз match, як
показано у Лістингу 9-5.
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {e:?}"),
},
_ => {
panic!("Problem opening the file: {error:?}");
}
},
};
}Тип значення, яке File::open повертає всередині варіанта Err, — io::Error,
який є структурою, наданою стандартною бібліотекою. Ця структура має метод
kind, який ми можемо викликати, щоб отримати значення io::ErrorKind.
Перелічення io::ErrorKind надається стандартною бібліотекою і має варіанти, що
представляють різні види помилок, які можуть виникнути під час операції io.
Варіант, який ми хочемо використати, — ErrorKind::NotFound, що вказує, що
файл, який ми намагаємося відкрити, ще не існує. Отже, ми виконуємо зіставлення
на greeting_file_result, але також маємо внутрішнє зіставлення на
error.kind().
Умова, яку ми хочемо перевірити у внутрішньому match, полягає в тому, чи
є значення, повернуте error.kind(), варіантом NotFound перелічення
ErrorKind. Якщо так, ми намагаємося створити файл за допомогою File::create.
Однак, оскільки File::create також може завершитися невдачею, нам потрібна
друга гілка у внутрішньому виразі match. Коли файл не вдається створити,
виводиться інше повідомлення про помилку. Друга гілка зовнішнього match
залишається тією ж, тож програма завершується панікою для будь-якої помилки,
окрім помилки відсутнього файлу.
Альтернативи використанню
matchзResult<T, E>Це багато
match! Виразmatchдуже корисний, але також дуже примітивний. У Розділі 13 ви дізнаєтеся про замикання, які використовуються з багатьма методами, визначеними наResult<T, E>. Ці методи можуть бути лаконічнішими, ніж використанняmatch, під час обробки значеньResult<T, E>у вашому коді.Наприклад, ось ще один спосіб записати ту саму логіку, що показана в Лістингу 9-5, цього разу використовуючи замикання і метод
unwrap_or_else:use std::fs::File; use std::io::ErrorKind; fn main() { let greeting_file = File::open("hello.txt").unwrap_or_else(|error| { if error.kind() == ErrorKind::NotFound { File::create("hello.txt").unwrap_or_else(|error| { panic!("Problem creating the file: {error:?}"); }) } else { panic!("Problem opening the file: {error:?}"); } }); }Хоча цей код має таку саму поведінку, як у Лістингу 9-5, він не містить жодних виразів
matchі є чистішим для читання. Поверніться до цього прикладу після того, як прочитаєте Розділ 13, і пошукайте методunwrap_or_elseу документації стандартної бібліотеки. Є ще багато таких методів, які можуть прибрати величезні вкладені виразиmatch, коли ви працюєте з помилками.
Скорочені способи викликати паніку при помилці
Використання match працює достатньо добре, але це може бути дещо
багатослівним і не завжди добре передає намір. Тип Result<T, E> має багато
допоміжних методів, визначених для нього, щоб виконувати різні, більш
специфічні завдання. Метод unwrap — це метод-швидкий спосіб, реалізований
точно так само, як вираз match, який ми написали у Лістингу 9-4. Якщо
значення Result є варіантом Ok, unwrap поверне значення всередині Ok.
Якщо Result є варіантом Err, unwrap викличе для нас макрос panic!.
Ось приклад unwrap у дії:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt").unwrap();
}Якщо ми запустимо цей код без файлу hello.txt, ми побачимо повідомлення про
помилку від виклику panic!, який робить метод unwrap:
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Аналогічно, метод expect також дає нам змогу обрати повідомлення про помилку
для panic!. Використання expect замість unwrap і надання добрих
повідомлень про помилки може передати ваш намір і полегшити пошук джерела
паніки. Синтаксис expect виглядає так:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")
.expect("hello.txt should be included in this project");
}Ми використовуємо expect так само, як unwrap: щоб повернути файловий
дескриптор або викликати макрос panic!. Повідомлення про помилку, яке
expect використовує у своєму виклику panic!, буде параметром, який ми
передаємо до expect, а не стандартним повідомленням panic!, яке
використовує unwrap. Ось як це виглядає:
thread 'main' panicked at src/main.rs:5:10:
hello.txt should be included in this project: Os { code: 2, kind: NotFound, message: "No such file or directory" }
У коді промислової якості більшість растацеанців (Rustaceans) обирають expect, а не
unwrap, і дають більше контексту про те, чому операція, як очікується, має
завжди завершуватися успіхом. Так, якщо ваші припущення коли-небудь виявляться
хибними, у вас буде більше інформації для налагодження.
Поширення помилок
Коли реалізація функції викликає щось, що може завершитися невдачею, замість обробки помилки всередині самої функції ви можете повернути помилку коду, що викликає, щоб він міг вирішити, що робити. Це відомо як поширення помилки і дає більше контролю коду, що викликає, де може бути більше інформації або логіки, яка визначає, як слід обробити помилку, ніж та, що є у вас у контексті вашого коду.
Наприклад, Лістинг 9-6 показує функцію, яка читає ім’я користувача з файлу. Якщо файл не існує або його неможливо прочитати, ця функція поверне ці помилки коду, що викликав функцію.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let username_file_result = File::open("hello.txt");
let mut username_file = match username_file_result {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut username = String::new();
match username_file.read_to_string(&mut username) {
Ok(_) => Ok(username),
Err(e) => Err(e),
}
}
}Цю функцію можна написати значно коротше, але ми почнемо з того, що зробимо
багато чого вручну, щоб дослідити обробку помилок; наприкінці ми покажемо
коротший спосіб. Спершу погляньмо на тип повернення функції:
Result<String, io::Error>. Це означає, що функція повертає значення типу
Result<T, E>, де узагальнений параметр T було заповнено конкретним типом
String, а узагальнений тип E було заповнено конкретним типом
io::Error.
Якщо ця функція завершується успіхом без будь-яких проблем, код, що викликає
цю функцію, отримає значення Ok, яке містить String — username, яке ця
функція прочитала з файлу. Якщо ця функція стикається з будь-якими
проблемами, код, що викликає, отримає значення Err, яке містить екземпляр
io::Error, що містить більше інформації про те, якими були проблеми. Ми
обрали io::Error як тип повернення цієї функції, тому що саме такий тип має
значення помилки, яке повертається обома операціями, які ми викликаємо в тілі
цієї функції і які можуть завершитися невдачею: функцією File::open і
методом read_to_string.
Тіло функції починається з виклику функції File::open. Потім ми обробляємо
значення Result за допомогою match, подібного до match у Лістингу 9-4.
Якщо File::open завершується успіхом, файловий дескриптор у шаблонній
змінній file стає значенням у змінній username_file, і функція
продовжується. У випадку Err, замість виклику panic!, ми використовуємо
ключове слово return, щоб достроково вийти з функції повністю і передати
значення помилки з File::open, тепер у шаблонній змінній e, назад коду,
що викликає, як значення помилки цієї функції.
Отже, якщо ми маємо файловий дескриптор у username_file, функція потім
створює новий String у змінній username і викликає метод read_to_string
на файловому дескрипторі в username_file, щоб прочитати вміст файлу в
username. Метод read_to_string також повертає Result, тому що він може
завершитися невдачею, навіть якщо File::open завершився успіхом. Отже, нам
потрібен ще один match, щоб обробити цей Result: якщо read_to_string
завершується успіхом, тоді наша функція завершується успіхом, і ми повертаємо
ім’я користувача з файлу, яке тепер у username, загорнуте в Ok. Якщо
read_to_string завершується невдачею, ми повертаємо значення помилки так
само, як ми повертали значення помилки в match, який обробляв повернене
значення File::open. Однак нам не потрібно явно писати return, тому що
це останній вираз у функції.
Код, що викликає цей код, потім оброблятиме отримання або значення Ok, яке
містить ім’я користувача, або значення Err, яке містить io::Error. Саме
коду, що викликає, вирішувати, що робити з цими значеннями. Якщо код, що
викликає, отримує значення Err, він може викликати panic! і аварійно
завершити програму, використати стандартне ім’я користувача або, наприклад,
шукати ім’я користувача десь, крім файлу. У нас недостатньо інформації про
те, що саме намагається зробити код, що викликає, тому ми поширюємо всю
інформацію про успіх або помилку вгору, щоб він обробив її належним чином.
Цей шаблон поширення помилок настільки поширений у Rust, що Rust надає
оператор питання ?, щоб спростити це.
Скорочений спосіб поширення помилок: оператор ?
Лістинг 9-7 показує реалізацію read_username_from_file, яка має ту саму
функціональність, що й у Лістингу 9-6, але ця реалізація використовує
оператор ?.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username_file = File::open("hello.txt")?;
let mut username = String::new();
username_file.read_to_string(&mut username)?;
Ok(username)
}
}?, поставлений після значення Result, визначено так, щоб працювати майже
так само, як вирази match, які ми визначили для обробки значень Result у
Лістингу 9-6. Якщо значення Result — Ok, значення всередині Ok буде
повернено з цього виразу, і програма продовжить виконання. Якщо значення —
Err, Err буде повернено з усієї функції так, ніби ми використали ключове
слово return, щоб значення помилки було поширено до коду, що викликає.
Існує різниця між тим, що робить вираз match з Лістингу 9-6, і тим, що робить
оператор ?: значення помилки, до яких застосовано оператор ?, проходять
через функцію from, визначену в трейті From у стандартній бібліотеці, яка
використовується для перетворення значень з одного типу в інший. Коли оператор
? викликає функцію from, отриманий тип помилки перетворюється на тип
помилки, визначений у типі повернення поточної функції. Це корисно, коли
функція повертає один тип помилки, щоб представити всі способи, якими функція
може завершитися невдачею, навіть якщо окремі частини можуть завершитися
невдачею з багатьох різних причин.
Наприклад, ми могли б змінити функцію read_username_from_file у Лістингу 9-7,
щоб вона повертала власний тип помилки з назвою OurError, який ми визначаємо.
Якщо ми також визначимо impl From<io::Error> for OurError, щоб створювати
екземпляр OurError з io::Error, тоді виклики оператора ? у тілі
read_username_from_file викликатимуть from і перетворюватимуть типи
помилок без потреби додавати ще якийсь код до функції.
У контексті Лістингу 9-7, ? у кінці виклику File::open поверне значення
всередині Ok у змінну username_file. Якщо виникне помилка, оператор ?
достроково поверне її з усієї функції і передасть будь-яке значення Err
коду, що викликає. Те саме стосується ? у кінці виклику read_to_string.
Оператор ? усуває багато шаблонного коду і робить реалізацію цієї функції
простішою. Ми навіть могли б ще скоротити цей код, безпосередньо
ланцюжуючи виклики методів після ?, як показано у Лістингу 9-8.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username = String::new();
File::open("hello.txt")?.read_to_string(&mut username)?;
Ok(username)
}
}Ми перенесли створення нового String у username на початок функції; ця
частина не змінилася. Замість створення змінної username_file ми
безпосередньо приєднали виклик read_to_string до результату
File::open("hello.txt")?. У нас усе ще є ? у кінці виклику read_to_string,
і ми все ще повертаємо значення Ok, що містить username, коли і
File::open, і read_to_string завершуються успіхом, а не повертають
помилки. Функціональність знову та сама, що й у Лістингу 9-6 і у Лістингу 9-7;
це просто інший, більш зручний спосіб записати це.
Лістинг 9-9 показує спосіб зробити це ще коротшим, використовуючи
fs::read_to_string.
#![allow(unused)]
fn main() {
use std::fs;
use std::io;
fn read_username_from_file() -> Result<String, io::Error> {
fs::read_to_string("hello.txt")
}
}Читання файлу в рядок — це досить поширена операція, тож стандартна бібліотека
надає зручну функцію fs::read_to_string, яка відкриває файл, створює новий
String, читає вміст файлу, поміщає вміст у цей String і повертає його.
Звісно, використання fs::read_to_string не дає нам можливості пояснити всю
обробку помилок, тож спочатку ми зробили це довшим способом.
Де можна використовувати оператор ?
Оператор ? можна використовувати лише у функціях, тип повернення яких
сумісний зі значенням, на якому використовується ?. Це тому, що оператор ?
визначено так, щоб виконувати дострокове повернення значення з функції, так
само, як і вираз match, який ми визначили у Лістингу 9-6. У Лістингу 9-6
match використовував значення Result, а гілка дострокового повернення
повертала значення Err(e). Тип повернення функції має бути Result, щоб
він був сумісний з цим return.
У Лістингу 9-10 подивімося на помилку, яку ми отримаємо, якщо використаємо
оператор ? у функції main з типом повернення, несумісним із типом
значення, на якому ми використовуємо ?.
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")?;
}Цей код відкриває файл, що може завершитися невдачею. Оператор ? іде після
значення Result, поверненого File::open, але ця функція main має тип
повернення (), а не Result. Коли ми компілюємо цей код, ми отримуємо таке
повідомлення про помилку:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let greeting_file = File::open("hello.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` (bin "error-handling") due to 1 previous error
Ця помилка вказує, що нам дозволено використовувати оператор ? лише у
функції, яка повертає Result, Option або інший тип, що реалізує
FromResidual.
Щоб виправити помилку, у вас є два варіанти. Один варіант — змінити тип
повернення вашої функції так, щоб він був сумісний зі значенням, на якому ви
використовуєте оператор ?, якщо вас нічого не обмежує. Інший варіант — це
використати match або один із методів Result<T, E>, щоб обробити
Result<T, E> у будь-який відповідний спосіб.
У повідомленні про помилку також згадувалося, що ? можна використовувати і
зі значеннями Option<T>. Як і у випадку використання ? з Result, ви
можете використовувати ? на Option лише у функції, яка повертає
Option. Поведінка оператора ?, коли його застосовують до Option<T>, подібна до його поведінки, коли його застосовують до Result<T, E>: якщо значення — None, Noneбуде повернено достроково з функції в цій точці. Якщо значення —Some, значення всередині Some` є результатним значенням
виразу, і функція продовжується. Лістинг 9-11 містить приклад функції, яка
знаходить останній символ першого рядка в заданому тексті.
fn last_char_of_first_line(text: &str) -> Option<char> {
text.lines().next()?.chars().last()
}
fn main() {
assert_eq!(
last_char_of_first_line("Hello, world\nHow are you today?"),
Some('d')
);
assert_eq!(last_char_of_first_line(""), None);
assert_eq!(last_char_of_first_line("\nhi"), None);
}Ця функція повертає Option<char>, тому що там може бути символ, але також
може і не бути. Цей код бере аргумент-зріз рядка text і викликає на ньому
метод lines, який повертає ітератор по рядках у рядку. Оскільки ця функція
хоче розглянути перший рядок, вона викликає next на ітераторі, щоб отримати
перше значення з ітератора. Якщо text — порожній рядок, цей виклик next
поверне None, і в такому разі ми використовуємо ?, щоб зупинитися і
повернути None з last_char_of_first_line. Якщо text не є порожнім
рядком, next поверне значення Some, що містить зріз рядка першого рядка в
text.
? витягує зріз рядка, і ми можемо викликати chars на цьому зрізі рядка,
щоб отримати ітератор його символів. Нас цікавить останній символ у цьому
першому рядку, тож ми викликаємо last, щоб повернути останній елемент з
ітератора. Це Option, тому що можливо, що перший рядок є порожнім рядком;
наприклад, якщо text починається з порожнього рядка, але має символи в
інших рядках, як у "\nhi". Однак якщо в першому рядку є останній символ,
він буде повернений у варіанті Some. Оператор ? посередині дає нам
лаконічний спосіб виразити цю логіку, дозволяючи реалізувати функцію в один
рядок. Якби ми не могли використовувати оператор ? на Option, нам би
довелося реалізовувати цю логіку за допомогою більшої кількості викликів
методів або виразу match.
Зверніть увагу, що ви можете використовувати оператор ? на Result у
функції, яка повертає Result, і ви можете використовувати оператор ? на
Option у функції, яка повертає Option, але ви не можете їх змішувати. Оператор
? не перетворює автоматично Result на Option або навпаки; у таких
випадках ви можете використовувати методи на кшталт ok на Result або
ok_or на Option, щоб виконати перетворення явно.
Поки що всі функції main, які ми використовували, повертають (). Функція
main є особливою, тому що вона є точкою входу і точкою виходу виконуваної
програми, і існують обмеження щодо того, яким може бути її тип повернення,
щоб програма поводилася так, як очікується.
На щастя, main також може повертати Result<(), E>. Лістинг 9-12 містить
код із Лістингу 9-10, але ми змінили тип повернення main на
Result<(), Box<dyn Error>> і додали значення повернення Ok(()) у кінець.
Тепер цей код скомпілюється.
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}Тип Box<dyn Error> — це об’єкт трейту, про який ми поговоримо в “Використання
трейт-об’єктів для абстрагування над спільною поведінкою”
у Розділі 18. Поки що ви можете читати Box<dyn Error> як “будь-який тип
помилки”. Використання ? на значенні Result у функції main з типом
помилки Box<dyn Error> дозволено, тому що це дає змогу будь-якому значенню
Err бути поверненим достроково. Хоча тіло цієї функції main завжди
повертатиме лише помилки типу std::io::Error, якщо вказати
Box<dyn Error>, цей сигнатурний тип залишатиметься правильним навіть якщо
до тіла main буде додано більше коду, який повертає інші помилки.
Коли функція main повертає Result<(), E>, виконуваний файл завершить
роботу зі значенням 0, якщо main поверне Ok(()), і завершить роботу з
ненульовим значенням, якщо main поверне значення Err. Виконувані файли,
написані в C, повертають цілі числа під час завершення: програми, що
завершуються успішно, повертають ціле число 0, а програми, що завершуються
з помилкою, повертають деяке ціле число, відмінне від 0. Rust також
повертає цілі числа з виконуваних файлів, щоб бути сумісним із цією
конвенцією.
Функція main може повертати будь-які типи, які реалізують трейт
std::process::Termination, що містить функцію
report, яка повертає ExitCode. Зверніться до документації стандартної
бібліотеки для отримання додаткової інформації про реалізацію трейту
Termination для власних типів.
Тепер, коли ми обговорили деталі виклику panic! або повернення Result,
давайте повернемося до теми того, як вирішити, що саме доречно використовувати
в яких випадках.
panic! чи не panic!
До panic! чи не до panic!
Отже, як вирішити, коли слід викликати panic!, а коли слід повертати
Result? Коли код панікує, відновитися немає жодного способу. Ви могли б
викликати panic! для будь-якої ситуації з помилкою, незалежно від того, чи
є можливий спосіб відновитися, але тоді ви ухвалюєте рішення, що ситуація є
невідновлюваною, замість викликаючого коду. Коли ви вирішуєте повертати
значення Result, ви даєте викликаючому коду варіанти. Викликаючий код міг би
обрати спробу відновитися способом, який відповідає його ситуації, або міг би
вирішити, що значення Err у цьому випадку є невідновлюваним, тож він може
викликати panic! і перетворити вашу відновлювану помилку на невідновлювану.
Отже, повернення Result — це гарний вибір за замовчуванням, коли ви
визначаєте функцію, яка може зазнати невдачі.
У ситуаціях, таких як приклади, код прототипу та тести, доречніше писати код,
який панікує, замість повернення Result. Дослідимо, чому, а потім
обговоримо ситуації, у яких компілятор не може сказати, що збій неможливий,
але ви як людина — можете. Розділ завершиться деякими загальними
рекомендаціями щодо того, як вирішити, чи панікувати в коді бібліотеки.
Приклади, код прототипу та тести
Коли ви пишете приклад, щоб проілюструвати певну концепцію, додавання також
надійного коду обробки помилок може зробити приклад менш зрозумілим. У
прикладах вважається, що виклик методу на кшталт unwrap, який може
панікувати, призначений як заповнювач для того способу, яким ви хотіли б, щоб
ваша програма обробляла помилки, а це може відрізнятися залежно від того, що
робить решта вашого коду.
Так само методи unwrap і expect дуже зручні, коли ви створюєте прототип і
ще не готові вирішити, як обробляти помилки. Вони залишають у вашому коді
чіткі позначки на той момент, коли ви будете готові зробити вашу програму
більш надійною.
Якщо виклик методу зазнає невдачі в тесті, ви хотіли б, щоб уся перевірка
зазнала невдачі, навіть якщо цей метод не є функціональністю, яку тестують.
Оскільки panic! — це спосіб позначити тест як невдалий, виклик unwrap або
expect є саме тим, що має статися.
Коли ви маєте більше інформації, ніж компілятор
Також було б доречно викликати expect, коли у вас є якась інша логіка, що
гарантує, що Result матиме значення Ok, але ця логіка не є чимось, що
розуміє компілятор. У вас усе ще буде значення Result, з яким вам потрібно
обійтися: будь-яка операція, яку ви викликаєте, усе ще загалом має можливість
зазнати невдачі, навіть якщо у вашій конкретній ситуації це логічно
неможливо. Якщо ви можете переконатися шляхом ручної перевірки коду, що у вас
ніколи не буде варіанта Err, цілком прийнятно викликати expect і
документувати причину, чому ви вважаєте, що у вас ніколи не буде варіанта
Err, у тексті аргументу. Ось приклад:
fn main() {
use std::net::IpAddr;
let home: IpAddr = "127.0.0.1"
.parse()
.expect("Hardcoded IP address should be valid");
}Ми створюємо екземпляр IpAddr шляхом розбору жорстко заданого рядка. Ми
бачимо, що 127.0.0.1 — це дійсна IP-адреса, тож тут прийнятно використати
expect. Однак наявність жорстко заданого, дійсного рядка не змінює
тип повернення методу parse: ми все ще отримуємо значення Result, і
компілятор усе ще змушуватиме нас обробляти Result, ніби варіант Err
є можливим, тому що компілятор недостатньо розумний, щоб побачити, що цей
рядок завжди є дійсною IP-адресою. Якби рядок IP-адреси надходив від
користувача, а не був жорстко заданий у програмі і тому дійсно мав би
можливість збою, ми б однозначно хотіли обробляти Result більш надійним
способом. Згадування припущення, що ця IP-адреса є жорстко заданою, спонукатиме
нас змінити expect на кращий код обробки помилок, якщо в майбутньому нам
потрібно буде отримувати IP-адресу з іншого джерела.
Рекомендації щодо обробки помилок
Бажано, щоб ваш код панікував, коли є можливість, що ваш код може опинитися в поганому стані. У цьому контексті поганий стан — це коли порушено деяке припущення, гарантію, контракт або інваріант, наприклад, коли недійсні значення, суперечливі значення або відсутні значення передаються вашому коду — плюс одна або більше з наведених далі умов:
- Поганий стан — це щось несподіване, на відміну від чогось, що, ймовірно, час від часу траплятиметься, як-от коли користувач вводить дані в неправильному форматі.
- Ваш код після цього моменту має покладатися на те, що не перебуває в цьому поганому стані, а не перевіряти наявність проблеми на кожному кроці.
- Немає хорошого способу закодувати цю інформацію в типах, які ви використовуєте. Ми розглянемо приклад того, що саме мається на увазі, у «Кодування станів і поведінки як типів» у Розділі 18.
Якщо хтось викликає ваш код і передає значення, які не мають сенсу, найкраще
повернути помилку, якщо ви можете, щоб користувач бібліотеки міг вирішити,
що він хоче зробити в такому випадку. Однак у випадках, коли продовження
може бути небезпечним або шкідливим, найкращим вибором може бути виклик
panic! і повідомлення людині, яка використовує вашу бібліотеку, про
помилку в її коді, щоб вона могла виправити це під час розробки. Так само
panic! часто доречний, якщо ви викликаєте зовнішній код, який не
підконтрольний вам, і він повертає недійсний стан, який ви не можете
виправити.
Однак, коли збій є очікуваним, доречніше повертати Result, а не робити
виклик panic!. Приклади включають аналізатор (parser), якому передають пошкоджені дані,
або HTTP-запит, який повертає статус, що вказує на те, що ви досягли
обмеження частоти. У цих випадках повернення Result вказує, що збій — це
очікувана можливість, яку викликаючий код має вирішити, як обробити.
Коли ваш код виконує операцію, яка може наразити користувача на ризик, якщо
її викликати з недійсними значеннями, ваш код повинен спочатку перевірити,
що значення дійсні, і панікувати, якщо значення недійсні. Це переважно з
міркувань безпеки: спроба виконати операцію над недійсними даними може
відкрити ваш код для вразливостей. Це головна причина, чому стандартна
бібліотека викличе panic!, якщо ви спробуєте доступ до пам’яті за межами
обмежень: спроба отримати доступ до пам’яті, яка не належить поточній
структурі даних, є поширеною проблемою безпеки. Функції часто мають
контракти: їхня поведінка гарантується лише тоді, коли вхідні дані
відповідають певним вимогам. Панікувати, коли контракт порушено, має сенс,
тому що порушення контракту завжди вказує на помилку з боку викликача, і це
не той тип помилки, який ви хочете, щоб викликаючий код мав явно обробляти.
Насправді, немає розумного способу для викликаючого коду відновитися; викликаючі
програмісти мають виправити код. Контракти для функції, особливо коли
порушення спричинятиме паніку, слід пояснювати в документації API для цієї
функції.
Однак наявність багатьох перевірок помилок у всіх ваших функціях була б
багатослівною й дратівливою. На щастя, ви можете використовувати систему типів
Rust (а отже, і перевірку типів, яку виконує компілятор), щоб виконати багато
перевірок за вас. Якщо ваша функція має певний тип як параметр, ви можете
продовжувати логіку вашого коду, знаючи, що компілятор уже переконався, що
у вас є дійсне значення. Наприклад, якщо у вас є тип, а не Option, ваша
програма очікує мати щось, а не нічого. Тоді вашому коду не потрібно
обробляти два випадки для варіантів Some і None: у нього буде лише один
випадок для напевно наявного значення. Код, який намагається передати нічого
вашій функції, навіть не скомпілюється, тож вашій функції не потрібно
перевіряти цей випадок під час виконання. Інший приклад — використання
типу цілого числа без знака, наприклад u32, який гарантує, що параметр
ніколи не буде від’ємним.
Створення власних типів для перевірки
Давайте розвинемо ідею використання системи типів Rust для забезпечення того, що ми маємо дійсне значення, на один крок далі й подивимося на створення власного типу для перевірки. Згадайте гру в вгадування з Розділі 2, у якій наш код просив користувача вгадати число від 1 до 100. Ми ніколи не перевіряли, чи була здогадка користувача в межах цих чисел, перед тим як порівнювати її з нашим таємним числом; ми лише перевіряли, що здогадка була додатною. У цьому випадку наслідки були не дуже серйозними: наш вивід «Занадто велике» або «Занадто мале» все одно був би правильним. Але було б корисним удосконаленням спрямовувати користувача до дійсних здогадок і мати різну поведінку, коли користувач вгадує число поза діапазоном, порівняно з тим, коли користувач вводить, наприклад, літери.
Один зі способів зробити це — розбирати здогадку як i32 замість лише u32,
щоб дозволити потенційно від’ємні числа, а потім додати перевірку того, що
число перебуває в діапазоні, ось так:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Вираз if перевіряє, чи є наше значення поза діапазоном, повідомляє
користувача про проблему та викликає continue, щоб почати наступну ітерацію
циклу й попросити ще одну здогадку. Після виразу if ми можемо продовжити
порівняння між guess і таємним числом, знаючи, що guess перебуває між 1
і 100.
Однак це не ідеальне рішення: якби було абсолютно критично, щоб програма працювала лише зі значеннями від 1 до 100, і вона мала багато функцій із цією вимогою, наявність такої перевірки в кожній функції була б виснажливою (і могла б вплинути на продуктивність).
Замість цього ми можемо створити новий тип у спеціальному модулі й помістити
перевірки у функцію для створення екземпляра типу, а не повторювати
перевірки всюди. Таким чином, функціям безпечно використовувати новий тип у
своїх сигнатурах і впевнено використовувати значення, які вони отримують.
У Лістингу 9-13 показано один зі способів визначити тип Guess, який створюватиме
екземпляр Guess лише якщо функція new отримує значення між 1 і 100.
#![allow(unused)]
fn main() {
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
pub fn value(&self) -> i32 {
self.value
}
}
}Зверніть увагу, що цей код у src/guessing_game.rs залежить від додавання
оголошення модуля mod guessing_game; у src/lib.rs, яке ми тут не
показували. Усередині файла цього нового модуля ми визначаємо структуру з
назвою Guess, яка має поле з назвою value, що містить i32. Тут буде
зберігатися число.
Потім ми реалізуємо пов’язану функцію (associated function) з назвою new для Guess, яка
створює екземпляри значень Guess. Функцію new визначено так, що вона має
один параметр з назвою value типу i32 і повертає Guess. Код у тілі
функції new перевіряє value, щоб переконатися, що воно між 1 і 100. Якщо
value не проходить цю перевірку, ми робимо виклик panic!, який
повідомить програміста, що пише викликаючий код, про помилку, яку йому
потрібно виправити, тому що створення Guess зі значенням value поза
цим діапазоном порушило б контракт, на який покладається Guess::new.
Умови, за яких Guess::new може панікувати, слід обговорити в її
публічній документації API; ми розглянемо домовленості щодо документації,
які вказують на можливість panic! у документації API, яку ви створюєте, у
Розділі 14. Якщо value проходить перевірку, ми створюємо новий Guess,
у якого поле value встановлено в параметр value, і повертаємо Guess.
Далі ми реалізуємо метод з назвою value, який запозичує self, не має
жодних інших параметрів і повертає i32. Такий метод іноді називають
гетер (getter), тому що його мета — отримати деякі дані з його полів і повернути
їх. Цей публічний метод необхідний, тому що поле value структури Guess
є приватним. Важливо, щоб поле value було приватним, щоб код, який
використовує структуру Guess, не міг встановлювати value безпосередньо:
код поза модулем guessing_game повинен використовувати функцію
Guess::new, щоб створити екземпляр Guess, тим самим гарантуючи, що
немає способу для Guess мати value, яке не було перевірене умовами у
функції Guess::new.
Функція, яка має параметр або повертає лише числа між 1 і 100, тоді могла б
оголосити в своїй сигнатурі, що вона приймає або повертає Guess, а не i32,
і не потребувала б жодних додаткових перевірок у своєму тілі.
Підсумок
Можливості обробки помилок Rust розроблено, щоб допомогти вам писати
надійніший код. Макрос panic! сигналізує, що ваша програма перебуває в
стані, з яким вона не може впоратися, і дає вам змогу наказати процесу
стані, з яким вона не може впоратися, і дає вам змогу наказати процесу
зупинитися замість спроби продовжувати з недійсними або неправильними
значеннями. Лістинг 9-13 використовує систему типів Rust, щоб вказати, що
операції можуть зазнати невдачі способом, від якого ваш код міг би
відновитися. Ви можете використовувати Result, щоб повідомити коду, який
викликає ваш код, що йому також потрібно обробляти можливий успіх або збій.
Використання panic! і Result у відповідних ситуаціях зробить ваш код
надійнішим перед неминучими проблемами.
Тепер, коли ви побачили корисні способи, якими стандартна бібліотека
використовує узагальнені типи з переліченнями Option і Result, ми поговоримо
про те, як працюють узагальнені (generic) типи і як ви можете використовувати їх у
своєму коді.
Узагальнені типи, трейти та часи життя
Кожна мова програмування має інструменти для ефективної обробки дублювання понять. У Rust одним із таких інструментів є узагальнення (generics): абстрактні замінники для конкретних типів або інших властивостей. Ми можемо виразити поведінку узагальнень (generics) або те, як вони пов’язані з іншими узагальненнями (generics), не знаючи, що буде на їхньому місці під час компіляції та виконання коду.
Функції можуть приймати параметри деякого узагальненого типу, замість конкретного типу
на кшталт i32 або String, так само як вони приймають параметри з невідомими
значеннями, щоб запускати той самий код на кількох конкретних значеннях. Насправді ми вже
використовували узагальнення (generics) у Розділі 6 з Option<T>, у Розділі 8 з Vec<T> і
HashMap<K, V>, а також у Розділі 9 з Result<T, E>. У цьому розділі ви
дізнаєтеся, як визначати власні типи, функції та методи з узагальненнями (generics)!
Спочатку ми переглянемо, як виділити функцію, щоб зменшити дублювання коду. Потім ми використаємо ту саму техніку, щоб створити узагальнену функцію з двох функцій, які відрізняються лише типами своїх параметрів. Ми також пояснимо, як використовувати узагальнені типи у визначеннях структур і переліків.
Потім ви дізнаєтеся, як використовувати трейти для визначення поведінки узагальненим способом. Ви можете поєднувати трейти з узагальненими типами, щоб обмежити узагальнений тип приймати лише ті типи, які мають певну поведінку, на відміну від будь-якого типу.
Нарешті, ми обговоримо часи життя: різновид узагальнень (generics), який надає компілятору інформацію про те, як посилання пов’язані одне з одним. Часи життя дозволяють нам дати компілятору достатньо інформації про запозичені значення, щоб він міг гарантувати, що посилання будуть дійсними в більшій кількості ситуацій, ніж це було б без нашої допомоги.
Усунення дублювання шляхом виділення функції
Узагальнення (generics) дозволяють нам замінювати конкретні типи заповнювачем, який представляє кілька типів, щоб усунути дублювання коду. Перш ніж занурюватися в синтаксис узагальнень (generics), спочатку подивімося, як усунути дублювання способом, що не передбачає узагальнені типи, шляхом виділення функції, яка замінює конкретні значення заповнювачем, що представляє кілька значень. Потім ми застосуємо ту саму техніку, щоб виділити узагальнену функцію! Розглядаючи, як розпізнати дубльований код, який можна виділити у функцію, ви почнете розпізнавати дубльований код, який може використовувати узагальнення (generics).
Ми почнемо з короткої програми в Лістингу 10-1, яка знаходить найбільше число в списку.
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
assert_eq!(*largest, 100);
}Ми зберігаємо список цілих чисел у змінній number_list і поміщаємо посилання
на перше число в списку у змінну з назвою largest. Потім ми ітеруємося
через усі числа в списку, і якщо поточне число більше за число, збережене в largest,
ми замінюємо посилання в цій змінній. Однак якщо поточне число менше або дорівнює
найбільшому числу, побаченому досі, змінна не змінюється, і код переходить до наступного числа
в списку. Після розгляду всіх чисел у списку largest має
посилатися на найбільше число, яким у цьому випадку є 100.
Тепер перед нами поставлено завдання знайти найбільше число у двох різних списках чисел. Щоб зробити це, ми можемо вирішити дублювати код у Лістингу 10-1 і використовувати ту саму логіку у двох різних місцях програми, як показано в Лістингу 10-2.
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
}Хоча цей код працює, дублювання коду є виснажливим і схильним до помилок. Нам також доводиться пам’ятати про оновлення коду в кількох місцях, коли ми хочемо його змінити.
Щоб усунути це дублювання, ми створимо абстракцію, визначивши функцію, яка працює з будь-яким списком цілих чисел, переданим як параметр. Це рішення робить наш код зрозумілішим і дозволяє нам виразити поняття пошуку найбільшого числа в списку абстрактно.
У Лістингу 10-3 ми виділяємо код, який знаходить найбільше число, у
функцію з назвою largest. Потім ми викликаємо цю функцію, щоб знайти найбільше число
у двох списках з Лістингу 10-2. Ми також могли б використати цю функцію для будь-якого іншого
списку значень i32, який у нас може з’явитися в майбутньому.
fn largest(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 100);
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let result = largest(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 6000);
}Функція largest має параметр під назвою list, який представляє будь-який
конкретний зріз (slice) значень i32, який ми можемо передати у функцію. У результаті,
коли ми викликаємо функцію, код виконується на конкретних значеннях, які ми передаємо
в неї.
Підсумовуючи, ось кроки, які ми виконали, щоб змінити код з Лістингу 10-2 на Лістинг 10-3:
- Визначте дубльований код.
- Виділіть дубльований код у тіло функції та вкажіть вхідні дані й значення, що повертаються цим кодом, у сигнатурі функції.
- Оновіть два випадки дубльованого коду, щоб замість нього викликати функцію.
Далі ми використаємо ті самі кроки з узагальненнями (generics), щоб зменшити дублювання коду. У
той самий спосіб, у який тіло функції може працювати з абстрактним list
замість конкретних значень, узагальнення (generics) дозволяють коду працювати з абстрактними типами.
Наприклад, припустімо, що в нас є дві функції: одна, яка знаходить найбільший елемент у
зрізі значень i32, і одна, яка знаходить найбільший елемент у зрізі значень char.
Як би ми усунули це дублювання? Давайте з’ясуємо!
Узагальнені типи даних
Узагальнені типи даних
Ми використовуємо узагальнення (generics) для створення визначень для таких елементів, як сигнатури функцій або структури, які потім можемо використовувати з багатьма різними конкретними типами даних. Спочатку подивімося, як визначати функції, структури, переліки та методи за допомогою узагальнень (generics). Потім ми обговоримо, як узагальнення (generics) впливають на продуктивність коду.
У визначеннях функцій
Коли ми визначаємо функцію, що використовує узагальнення (generics), ми розміщуємо узагальнення (generics) у сигнатурі функції там, де зазвичай указували б типи даних параметрів і поверненого значення. Роблячи так, ми робимо наш код гнучкішим і надаємо більше функціональності викликачам нашої функції, водночас запобігаючи дублюванню коду.
Продовжуючи нашу функцію largest, у Лістингу 10-4 показано дві функції, які
обидві знаходять найбільше значення в зрізі. Потім ми об’єднаємо їх в одну
функцію, що використовує узагальнення (generics).
fn largest_i32(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn largest_char(list: &[char]) -> &char {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest_i32(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 100);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest_char(&char_list);
println!("The largest char is {result}");
assert_eq!(*result, 'y');
}Функція largest_i32 — це та, яку ми виділили в Лістингу 10-3 і яка знаходить
найбільший i32 у зрізі. Функція largest_char знаходить найбільший char
в зрізі. Тіла функцій мають однаковий код, тож усуньмо дублювання, увівши
узагальнений параметр типу в одну функцію.
Щоб параметризувати типи в новій одній функції, нам потрібно назвати параметр
типу так само, як ми робимо для параметрів значень функції. Ви можете
використовувати будь-який ідентифікатор як назву параметра типу. Але ми
використаємо T, тому що за домовленістю назви параметрів типу в Rust короткі,
часто лише одна літера, а конвенція найменування типів у Rust — UpperCamelCase.
Скорочення від type, T — це типовий вибір більшості програмістів Rust.
Коли ми використовуємо параметр у тілі функції, ми маємо оголосити ім’я
параметра в сигнатурі, щоб компілятор знав, що означає це ім’я. Так само,
коли ми використовуємо ім’я параметра типу в сигнатурі функції, ми маємо
оголосити ім’я параметра типу до того, як використаємо його. Щоб визначити
узагальнену функцію largest, ми розміщуємо оголошення імен типів всередині
кутових дужок, <>, між назвою функції та списком параметрів, ось так:
fn largest<T>(list: &[T]) -> &T {Ми читаємо це визначення як «Функція largest є узагальненою за деяким типом
T». Ця функція має один параметр на ім’я list, який є зрізом значень
типу T. Функція largest повертатиме посилання на значення того самого
типу T.
Лістинг 10-5 показує об’єднане визначення функції largest, що використовує
узагальнений тип даних у своїй сигнатурі. У списку також показано, як можна
викликати функцію зі зрізом значень i32 або значень char. Зверніть увагу,
що цей код ще не скомпілюється.
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {result}");
}Якщо ми скомпілюємо цей код просто зараз, отримаємо таку помилку:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Текст підказки згадує std::cmp::PartialOrd, який є трейтом (trait), і ми
поговоримо про трейти (traits) в наступному розділі. Поки що знайте, що ця помилка
стверджує: тіло largest не працюватиме для всіх можливих типів, якими може
бути T. Оскільки ми хочемо порівнювати значення типу T у тілі, ми можемо
використовувати лише ті типи, значення яких можна впорядкувати. Щоб увімкнути
порівняння, стандартна бібліотека має трейт std::cmp::PartialOrd, який ви
можете реалізувати для типів (див. Додаток C для більшої інформації про цей
трейт). Щоб виправити Лістинг 10-5, ми можемо скористатися пропозицією з
тексту підказки та обмежити типи, допустимі для T, лише тими, що
реалізують PartialOrd. Після цього список скомпілюється, тому що стандартна
бібліотека реалізує PartialOrd і для i32, і для char.
У визначеннях структур
Ми також можемо визначати структури так, щоб вони використовували узагальнений
параметр типу в одному або кількох полях, використовуючи синтаксис <>.
Listing 10-6 визначає структуру Point<T>, щоб зберігати значення координат
x і y будь-якого типу.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
}Синтаксис використання узагальнень (generics) у визначеннях структур подібний до того, що використовується у визначеннях функцій. Спочатку ми оголошуємо ім’я параметра типу всередині кутових дужок одразу після імені структури. Потім ми використовуємо узагальнений тип у визначенні структури там, де інакше вказували б конкретні типи даних.
Зверніть увагу: оскільки ми використали лише один узагальнений тип для
визначення Point<T>, це визначення каже, що структура Point<T> є
узагальненою за деяким типом T, а поля x і y є обидва саме цим самим
типом, яким би цей тип не був. Якщо ми створимо екземпляр Point<T>, який
має значення різних типів, як у Лістингу 10-7, наш код не скомпілюється.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}У цьому прикладі, коли ми присвоюємо цілочисельне значення 5 до x, ми
даємо компілятору знати, що узагальнений тип T буде цілочисельним для цього
екземпляра Point<T>. Потім, коли ми вказуємо 4.0 для y, яке ми
визначили як таке, що має той самий тип, що й x, ми отримаємо помилку
невідповідності типів, подібну до цієї:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Щоб визначити структуру Point, де x і y обидва є generics, але можуть
мати різні типи, ми можемо використовувати кілька узагальнених параметрів
типу. Наприклад, у Лістингу 10-8 ми змінюємо визначення Point, щоб воно було
узагальненим за типами T і U, де x має тип T, а y має тип U.
struct Point<T, U> {
x: T,
y: U,
}
fn main() {
let both_integer = Point { x: 5, y: 10 };
let both_float = Point { x: 1.0, y: 4.0 };
let integer_and_float = Point { x: 5, y: 4.0 };
}Тепер усі показані екземпляри Point дозволені! Ви можете використовувати
скільки завгодно узагальнених параметрів типу у визначенні, але використання
більш ніж кількох ускладнює читання вашого коду. Якщо ви бачите, що вам
потрібно багато узагальнених типів у вашому коді, це може вказувати на те, що
код потребує перебудови в менші частини.
У визначеннях переліків
Як і у випадку зі структурами, ми можемо визначати переліки, щоб зберігати
узагальнені типи даних у їхніх варіантах. Ще раз погляньмо на перелік
Option<T>, який надає стандартна бібліотека і який ми використовували в
Розділі 6:
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
}Тепер це визначення має для вас більше сенсу. Як бачите, перелік
Option<T> є узагальненим за типом T і має два варіанти: Some, який
зберігає одне значення типу T, і варіант None, який не зберігає жодного
значення. Використовуючи перелік Option<T>, ми можемо виразити абстрактне
поняття необов’язкового значення, і оскільки Option<T> є узагальненим, ми
можемо використовувати цю абстракцію незалежно від того, який тип має
необов’язкове значення.
Переліки також можуть використовувати кілька узагальнених типів. Визначення
переліку Result, яке ми використовували в Розділі 9, — один із прикладів:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}Перелік Result є узагальненим за двома типами, T і E, і має два
варіанти: Ok, який зберігає значення типу T, і Err, який зберігає
значення типу E. Це визначення робить зручним використання переліку
Result будь-де, де ми маємо операцію, що може або завершитися успіхом
(повернути значення певного типу T), або завершитися помилкою (повернути
помилку певного типу E). Власне, саме це ми використали, щоб відкрити
файл у Лістингу 9-3, де T було підставлено типом std::fs::File, коли
файл було відкрито успішно, а E було підставлено типом std::io::Error,
коли виникали проблеми з відкриттям файлу.
Коли ви розпізнаєте у вашому коді ситуації з кількома визначеннями структур або переліків, що відрізняються лише типами значень, які вони зберігають, ви можете уникнути дублювання, використовуючи замість цього узагальнені типи.
У визначеннях методів
Ми можемо реалізовувати методи для структур і переліків (як ми робили в Розділі 5) і використовувати
узагальнені типи в їхніх визначеннях також. Лістинг 10-9 показує структуру
Point<T>, яку ми визначили в Лістингу 10-6, з методом на ім’я x,
реалізованим для неї.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}Тут ми визначили метод на ім’я x для Point<T>, який повертає посилання
на дані в полі x.
Зверніть увагу, що ми маємо оголосити T одразу після impl, щоб ми могли
використовувати T для вказівки, що ми реалізуємо методи для типу
Point<T>. Оголошуючи T як узагальнений тип після impl, Rust може
визначити, що тип у кутових дужках у Point є узагальненим типом, а не
конкретним типом. Ми могли б вибрати іншу назву для цього узагальненого
параметра, ніж та, що оголошена у визначенні структури, але використання тієї
самої назви є загальноприйнятим. Якщо ви пишете метод усередині impl, який
оголошує узагальнений тип, цей метод буде визначено для будь-якого екземпляра
типу, незалежно від того, який конкретний тип зрештою підставляється замість
узагальненого типу.
Ми також можемо вказувати обмеження для узагальнених типів під час визначення
методів для типу. Наприклад, ми могли б реалізувати методи лише для
екземплярів Point<f32>, а не для екземплярів Point<T> з будь-яким
узагальненим типом. У Лістингу 10-10 ми використовуємо конкретний тип f32,
тобто не оголошуємо жодних типів після impl.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
impl Point<f32> {
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}Цей код означає, що тип Point<f32> матиме метод distance_from_origin;
інші екземпляри Point<T>, де T не має типу f32, не матимуть
визначеного цього методу. Метод вимірює, як далеко наша точка знаходиться від
точки з координатами (0.0, 0.0), і використовує математичні операції, які
доступні лише для типів із плаваючою комою.
Узагальнені параметри типу у визначенні структури не завжди збігаються з тими,
які ви використовуєте в сигнатурах методів цієї самої структури. Лістинг 10-11
використовує узагальнені типи X1 і Y1 для структури Point та X2 і
Y2 для сигнатури методу mixup, щоб зробити приклад зрозумілішим. Метод
створює новий екземпляр Point зі значенням x з Point self (типу X1)
та значенням y з переданого Point (типу Y2).
struct Point<X1, Y1> {
x: X1,
y: Y1,
}
impl<X1, Y1> Point<X1, Y1> {
fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Hello", y: 'c' };
let p3 = p1.mixup(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}У main ми визначили Point, який має i32 для x (зі значенням 5)
та f64 для y (зі значенням 10.4). Змінна p2 — це структура Point,
яка має рядковий зріз для x (зі значенням "Hello") і char для y
(зі значенням c). Виклик mixup для p1 з аргументом p2 дає нам p3,
який матиме i32 для x, тому що x походив із p1. Змінна p3 матиме
char для y, тому що y походив із p2. Виклик макросу println!
надрукує p3.x = 5, p3.y = c.
Мета цього прикладу — продемонструвати ситуацію, у якій деякі узагальнені
параметри оголошуються з impl, а деякі — з визначенням методу. Тут
узагальнені параметри X1 і Y1 оголошені після impl, тому що вони
належать до визначення структури. Узагальнені параметри X2 і Y2
оголошені після fn mixup, тому що вони стосуються лише методу.
Продуктивність коду, що використовує generics
Ви можете замислитися, чи є під час використання узагальнених параметрів типу витрати під час виконання. Добра новина полягає в тому, що використання узагальнених типів не зробить вашу програму повільнішою, ніж вона була б із конкретними типами.
Rust досягає цього, виконуючи мономорфізацію коду, що використовує узагальнення (generics), під час компіляції. Мономорфізація (monomorphization) — це процес перетворення узагальненого коду на специфічний код шляхом підставляння конкретних типів, які використовуються під час компіляції. У цьому процесі компілятор робить протилежне крокам, які ми використовували для створення узагальненої функції в Listing 10-5: компілятор дивиться на всі місця, де викликається узагальнений код, і генерує код для конкретних типів, з якими викликається узагальнений код.
Подивімося, як це працює, використовуючи узагальнений перелік стандартної
бібліотеки Option<T>:
#![allow(unused)]
fn main() {
let integer = Some(5);
let float = Some(5.0);
}Коли Rust компілює цей код, він виконує мономорфізацію. Під час цього
процесу компілятор читає значення, які було використано в екземплярах
Option<T>, і визначає два види Option<T>: один — i32, а інший —
f64. Таким чином, він розгортає узагальнене визначення Option<T> у два
визначення, спеціалізовані для i32 і f64, замінюючи узагальнене
визначення конкретними.
Мономорфізована версія коду виглядає подібно до такого (компілятор використовує інші назви, ніж ті, що ми використовуємо тут для ілюстрації):
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}Узагальнений Option<T> замінюється конкретними визначеннями, створеними
компілятором. Оскільки Rust компілює узагальнений код у код, що вказує тип у
кожному екземплярі, ми не сплачуємо витрат під час виконання за
використання узагальнень (generics). Коли код виконується, він працює так само, як працював
би, якби ми вручну дублювали кожне визначення. Процес мономорфізації робить
узагальнення (generics) у Rust надзвичайно ефективними під час виконання.
Визначення спільної поведінки за допомогою трейтів
Визначення спільної поведінки за допомогою трейтів
Трейт визначає функціональність, яку має певний тип і яку він може ділити з іншими типами. Ми можемо використовувати трейти для визначення спільної поведінки абстрактним способом. Ми можемо використовувати обмеження трейтів (trait bounds), щоб вказати, що узагальнений тип може бути будь-яким типом, який має певну поведінку.
Примітка: Трейти подібні до можливості, яку в інших мовах часто називають інтерфейсами, хоча й з деякими відмінностями.
Визначення трейту
Поведінка типу складається з методів, які ми можемо викликати для цього типу. Різні типи мають ту саму поведінку, якщо ми можемо викликати ті самі методи для всіх цих типів. Визначення трейту — це спосіб згрупувати сигнатури методів разом, щоб визначити набір поведінок, необхідних для досягнення певної мети.
Наприклад, припустімо, що ми маємо кілька структур, які зберігають різні види та
обсяги тексту: структура NewsArticle, яка зберігає новинну історію, подану в
певному місці, і SocialPost, який може мати, максимум, 280 символів разом із
метаданими, що вказують, чи це був новий допис, репост або відповідь на інший
допис.
Ми хочемо створити бібліотечний крейт для медіа-агрегатора під назвою aggregator,
який може відображати короткі підсумки даних, що можуть бути збережені в екземплярі
NewsArticle або SocialPost. Щоб зробити це, нам потрібен підсумок від кожного
типу, і ми запитуватимемо цей підсумок, викликаючи метод summarize на екземплярі.
У Лістингу 10-12 показано визначення публічного трейту Summary, який виражає цю
поведінку.
pub trait Summary {
fn summarize(&self) -> String;
}Тут ми оголошуємо трейт, використовуючи ключове слово trait, а потім ім’я трейту,
яке в цьому випадку є Summary. Ми також оголошуємо трейт як pub, щоб крейти,
які залежать від цього крейту, теж могли використовувати цей трейт, як ми побачимо
в кількох прикладах. Усередині фігурних дужок ми оголошуємо сигнатури методів, які
описують поведінку типів, що реалізують цей трейт, і в цьому випадку це
fn summarize(&self) -> String.
Після сигнатури методу, замість надання реалізації всередині фігурних дужок, ми
використовуємо крапку з комою. Кожен тип, що реалізує цей трейт, має надати власну
користувацьку поведінку для тіла методу. Компілятор забезпечить, щоб будь-який тип,
який має трейт Summary, мав метод summarize, визначений саме з цією сигнатурою.
Трейт може мати кілька методів у своєму тілі: сигнатури методів перелічуються по одній у рядку, і кожен рядок закінчується крапкою з комою.
Реалізація трейту для типу
Тепер, коли ми визначили потрібні сигнатури методів трейту Summary, ми можемо
реалізувати його для типів у нашому медіа-агрегаторі. У Лістингу 10-13 показано
реалізацію трейту Summary для структури NewsArticle, яка використовує заголовок,
автора та місце, щоб створити значення, що повертається summarize. Для структури
SocialPost ми визначаємо summarize як ім’я користувача, за яким іде весь текст
допису, припускаючи, що вміст допису вже обмежено 280 символами.
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Реалізація трейту для типу подібна до реалізації звичайних методів. Різниця полягає
в тому, що після impl ми ставимо ім’я трейту, який хочемо реалізувати, потім
використовуємо ключове слово for, а тоді вказуємо ім’я типу, для якого хочемо
реалізувати трейт. Усередині блоку impl ми розміщуємо сигнатури методів, які
визначені у трейті. Замість додавання крапки з комою після кожної сигнатури ми
використовуємо фігурні дужки та заповнюємо тіло методу конкретною поведінкою, яку
ми хочемо, щоб методи трейту мали для цього конкретного типу.
Тепер, коли бібліотека реалізувала трейт Summary для NewsArticle і SocialPost,
користувачі крейту можуть викликати методи трейту на екземплярах NewsArticle і
SocialPost так само, як ми викликаємо звичайні методи. Єдина різниця полягає в
тому, що користувач має імпортувати трейт в область видимості так само, як і типи.
Ось приклад того, як бінарний крейт може використовувати наш бібліотечний крейт
aggregator:
use aggregator::{SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Цей код виводить 1 new post: horse_ebooks: of course, as you probably already know, people.
Інші крейти, які залежать від крейту aggregator, також можуть імпортувати трейт
Summary в область видимості, щоб реалізувати Summary для власних типів. Одне
обмеження, на яке слід звернути увагу, полягає в тому, що ми можемо реалізувати
трейт для типу лише тоді, коли або трейт, або тип, або обидва є локальними для
нашого крейту. Наприклад, ми можемо реалізувати трейти стандартної бібліотеки, такі
як Display, для власного типу на кшталт SocialPost як частину функціональності
нашого крейту aggregator, тому що тип SocialPost є локальним для нашого крейту
aggregator. Ми також можемо реалізувати Summary для Vec<T> у нашому крейті
aggregator, тому що трейт Summary є локальним для нашого крейту aggregator.
Але ми не можемо реалізовувати зовнішні трейти для зовнішніх типів. Наприклад, ми не
можемо реалізувати трейт Display для Vec<T> у нашому крейті aggregator, тому
що і Display, і Vec<T> визначені в стандартній бібліотеці й не є локальними для
нашого крейту aggregator. Це обмеження є частиною властивості, яка називається
узгодженість (coherence), і точніше правила сироти (orphan rule), так названого тому, що
батьківський тип відсутній. Це правило гарантує, що чужий код не може зламати ваш
код і навпаки. Без цього правила два крейти могли б реалізувати той самий трейт для
того самого типу, і Rust не знав би, яку реалізацію використовувати.
Використання реалізацій за замовчуванням
Іноді корисно мати поведінку за замовчуванням для деяких або всіх методів у трейті замість того, щоб вимагати реалізації для всіх методів у кожному типі. Тоді, коли ми реалізуємо трейт для певного типу, ми можемо зберегти або перевизначити поведінку за замовчуванням для кожного методу.
У Лістингу 10-14 ми вказуємо рядок за замовчуванням для методу summarize трейту
Summary замість того, щоб лише визначати сигнатуру методу, як ми робили в
Лістингу 10-12.
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Щоб використати реалізацію за замовчуванням для підсумовування екземплярів
NewsArticle, ми вказуємо порожній блок impl із impl Summary for NewsArticle {}.
Хоча ми більше не визначаємо метод summarize безпосередньо для NewsArticle, ми
надали реалізацію за замовчуванням і вказали, що NewsArticle реалізує трейт
Summary. У результаті ми все ще можемо викликати метод summarize на екземплярі
NewsArticle, ось так:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}Цей код виводить New article available! (Read more...).
Створення реалізації за замовчуванням не вимагає від нас змінювати щось у реалізації
Summary для SocialPost у Лістингу 10-13. Причина полягає в тому, що синтаксис для
перевизначення реалізації за замовчуванням такий самий, як і синтаксис для реалізації
методу трейту, який не має реалізації за замовчуванням.
Реалізації за замовчуванням можуть викликати інші методи в тому самому трейді, навіть
якщо ті інші методи не мають реалізації за замовчуванням. Таким чином трейт може
надавати багато корисної функціональності й вимагати від тих, хто реалізує його,
вказати лише її невелику частину. Наприклад, ми могли б визначити трейт Summary
так, щоб він мав метод summarize_author, реалізація якого є обов’язковою, а потім
визначити метод summarize, який має реалізацію за замовчуванням, що викликає метод
summarize_author:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Щоб використовувати цю версію Summary, нам потрібно лише визначити
summarize_author, коли ми реалізуємо трейт для типу:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Після того як ми визначимо summarize_author, ми можемо викликати summarize для
екземплярів структури SocialPost, і реалізація summarize за замовчуванням
викличе визначення summarize_author, яке ми надали. Оскільки ми реалізували
summarize_author, трейт Summary надав нам поведінку методу summarize без
необхідності писати ще якийсь код. Ось як це виглядає:
use aggregator::{self, SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Цей код виводить 1 new post: (Read more from @horse_ebooks...).
Зауважте, що неможливо викликати реалізацію за замовчуванням із перевизначеної реалізації того самого методу.
Використання трейтів як параметрів
Тепер, коли ви знаєте, як визначати й реалізовувати трейти, ми можемо дослідити, як
використовувати трейти для визначення функцій, які приймають багато різних типів. Ми
використаємо трейт Summary, який ми реалізували для типів NewsArticle і
SocialPost у Лістингу 10-13, щоб визначити функцію notify, яка викликає метод
summarize для свого параметра item, який має певний тип, що реалізує трейт
Summary. Щоб зробити це, ми використовуємо синтаксис impl Trait, ось так:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}Замість конкретного типу для параметра item ми вказуємо ключове слово impl і
ім’я трейту. Цей параметр приймає будь-який тип, який реалізує вказаний трейт. У
тілі notify ми можемо викликати будь-які методи на item, які походять із трейту
Summary, наприклад summarize. Ми можемо викликати notify і передати будь-який
екземпляр NewsArticle або SocialPost. Код, що викликає цю функцію з будь-яким
іншим типом, таким як String або i32, не скомпілюється, тому що ці типи не
реалізують Summary.
Синтаксис обмеження трейтів
Синтаксис impl Trait працює для простих випадків, але насправді це синтаксичний
цукор (syntactic sugar) для довшої форми, відомої як обмеження трейту (trait bound); вона виглядає
ось так:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}Ця довша форма еквівалентна прикладу в попередньому розділі, але є більш багатослівною. Ми розміщуємо обмеження трейту з оголошенням узагальненого параметра типу після двокрапки та всередині кутових дужок.
Синтаксис impl Trait зручний і робить код коротшим у простих випадках, тоді як
повніший синтаксис обмеження трейту може виражати більшу складність в інших
випадках. Наприклад, ми можемо мати два параметри, які реалізують Summary. Зробити
це за допомогою синтаксису impl Trait виглядає так:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {Використання impl Trait є доречним, якщо ми хочемо, щоб ця функція дозволяла
item1 і item2 мати різні типи (за умови, що обидва типи реалізують Summary).
Однак якщо ми хочемо змусити обидва параметри мати той самий тип, ми маємо
використовувати обмеження трейту, ось так:
pub fn notify<T: Summary>(item1: &T, item2: &T) {Узагальнений тип T, вказаний як тип параметрів item1 і item2, обмежує функцію
так, що конкретний тип значення, переданого як аргумент для item1 і item2, має
бути однаковим.
Кілька обмежень трейтів із синтаксисом +
Ми також можемо вказати більше ніж одне обмеження трейту. Припустімо, ми хочемо, щоб
notify використовувала форматування для відображення, а також summarize для
item: ми вказуємо у визначенні notify, що item має реалізовувати і Display, і
Summary. Ми можемо зробити це, використовуючи синтаксис +:
pub fn notify(item: &(impl Summary + Display)) {Синтаксис + також є чинним для обмежень трейтів у узагальнених типів:
pub fn notify<T: Summary + Display>(item: &T) {Після вказання двох обмежень трейтів тіло notify може викликати summarize і
використовувати {} для форматування item.
Чіткіші обмеження трейтів із реченням where
Використання занадто великої кількості обмежень трейтів має свої недоліки. Кожен
узагальнений тип має власні обмеження трейтів, тому функції з кількома параметрами
узагальнених типів можуть містити багато інформації про обмеження трейтів між
назвою функції та списком її параметрів, що робить сигнатуру функції важкою для
читання. З цієї причини Rust має альтернативний синтаксис для вказання обмежень
трейтів усередині фрази where після сигнатури функції. Тож замість того, щоб
писати це:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {ми можемо використовувати фразу where, ось так:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}Сигнатура цієї функції менш перевантажена: ім’я функції, список параметрів і тип, що повертається, розташовані близько один до одного, подібно до функції без великої кількості обмежень трейтів.
Повернення типів, які реалізують трейти
Ми також можемо використовувати синтаксис impl Trait у позиції повернення, щоб
повернути значення деякого типу, який реалізує трейт, як показано тут:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}Використовуючи impl Summary для типу, що повертається, ми вказуємо, що функція
returns_summarizable повертає деякий тип, який реалізує трейт Summary, не
називаючи конкретний тип. У цьому випадку returns_summarizable повертає
SocialPost, але код, що викликає цю функцію, не має потреби знати це.
Можливість вказати тип, що повертається, лише через трейт, який він реалізує, є
особливо корисною в контексті замикань і ітераторів, які ми розглядаємо в Розділі 13.
Замикання й ітератори створюють типи, які знає лише компілятор, або типи, які дуже
довго вказувати. Синтаксис impl Trait дає змогу стисло вказати, що функція
повертає деякий тип, який реалізує трейт Iterator, без потреби записувати дуже
довгий тип.
Однак ви можете використовувати impl Trait лише якщо повертаєте один тип. Наприклад,
цей код, який повертає або NewsArticle, або SocialPost із типом, що повертається,
вказаним як impl Summary, не працюватиме:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}
}Повернення або NewsArticle, або SocialPost не дозволено через обмеження щодо
того, як синтаксис impl Trait реалізовано в компіляторі. Ми розглянемо, як
написати функцію з такою поведінкою в підрозділі “Використання об’єктів трейтів для абстрагування над спільною поведінкою” Розділу 18.
Використання обмежень трейтів для умовної реалізації методів
Використовуючи обмеження трейту з блоком impl, що використовує узагальнені
параметри типу, ми можемо умовно реалізовувати методи для типів, які реалізують
вказані трейти. Наприклад, тип Pair<T> у Лістингу 10-15 завжди реалізує функцію
new, щоб повертати новий екземпляр Pair<T> (згадайте з Розділу “Синтаксис методів” Розділу 5, що Self — це псевдонім типу для типу
блоку impl, яким у цьому випадку є Pair<T>). Але в наступному блоці impl
Pair<T> реалізує метод cmp_display лише якщо його внутрішній тип T
реалізує трейт PartialOrd, який дає змогу порівняння, і трейт Display, який
дає змогу друкування.
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}Ми також можемо умовно реалізувати трейт для будь-якого типу, який реалізує інший
трейт. Реалізації трейту для будь-якого типу, який задовольняє обмеження трейтів,
називаються загальними реалізаціями (blanket implementations) і широко
використовуються в стандартній бібліотеці Rust. Наприклад, стандартна бібліотека
реалізує трейт ToString для будь-якого типу, який реалізує трейт Display.
Блок impl у стандартній бібліотеці виглядає подібно до цього коду:
impl<T: Display> ToString for T {
// --snip--
}Оскільки стандартна бібліотека має цю загальну реалізацію, ми можемо викликати
метод to_string, визначений трейтом ToString, для будь-якого типу, який
реалізує трейт Display. Наприклад, ми можемо перетворити цілі числа на відповідні
значення String ось так, тому що цілі числа реалізують Display:
#![allow(unused)]
fn main() {
let s = 3.to_string();
}Загальні реалізації з’являються в документації для трейту в розділі “Implementors”.
Трейти та обмеження трейтів дають нам змогу писати код, який використовує узагальнені параметри типу, щоб зменшити дублювання, але також вказує компілятору, що ми хочемо, щоб узагальнений тип мав певну поведінку. Тоді компілятор може використовувати інформацію про обмеження трейтів, щоб перевірити, що всі конкретні типи, які використовуються з нашим кодом, забезпечують правильну поведінку. У мовах із динамічною типізацією ми отримали б помилку під час виконання, якби викликали метод для типу, який не визначає цей метод. Але Rust переносить ці помилки на час компіляції, щоб ми були змушені виправити проблеми ще до того, як наш код узагалі зможе запуститися. Крім того, нам не потрібно писати код, який перевіряє поведінку під час виконання, тому що ми вже перевірили це під час компіляції. Це підвищує продуктивність без необхідності відмовлятися від гнучкості узагальнених типів.
Перевірка посилань за допомогою часів життя
Перевірка посилань за допомогою часів життя (Lifetimes)
Часи життя — це ще один вид узагальненого типу, який ми вже використовували. Замість того, щоб гарантувати, що тип має потрібну нам поведінку, часи життя гарантують, що посилання є дійсними так довго, як нам це потрібно.
Одна деталь, яку ми не обговорювали в розділі “References and Borrowing” у Розділі 4, полягає в тому, що кожне посилання в Rust має час життя, який є областю видимості, у межах якої це посилання є дійсним. Найчастіше часи життя є неявними та виведеними, так само як більшу частину часу виводяться типи. Нам потрібно анотувати типи лише тоді, коли можливі кілька типів. Подібним чином, ми мусимо анотувати часи життя, коли часи життя посилань можуть бути пов’язані кількома різними способами. Rust вимагає, щоб ми анотували ці зв’язки за допомогою узагальнених параметрів часу життя, щоб гарантувати, що фактичні посилання, які використовуються під час виконання, будуть точно дійсними.
Анотування часів життя — це навіть не концепція, яка є в більшості інших мов програмування, тому це буде здаватися незвичним. Хоча в цьому розділі ми не розглядатимемо часи життя в повному обсязі, ми обговоримо поширені способи, у яких ви можете зустріти синтаксис часів життя, щоб ви могли звикнути до цієї концепції.
Висячі посилання
Головна мета часів життя — запобігати висячим посиланням, які, якби їм було дозволено існувати, спричиняли б посилання програми на дані, відмінні від тих даних, на які вона має посилатися. Розгляньте програму в Лістингу 10-16, яка має зовнішню область видимості та внутрішню область видимості.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}Примітка: Приклади в Лістингах 10-16, 10-17 та 10-23 оголошують змінні без надання їм початкового значення, тому ім’я змінної існує в зовнішній області видимості. На перший погляд, це може здатися таким, що суперечить тому, що в Rust немає нульових значень (null). Однак, якщо ми спробуємо використати змінну до того, як надамо їй значення, ми отримаємо помилку компіляції, що показує, що Rust дійсно не дозволяє нульові значення.
Зовнішня область видимості оголошує змінну з ім’ям r без початкового
значення, а внутрішня область видимості оголошує змінну з ім’ям x із
початковим значенням 5. Усередині внутрішньої області видимості ми
намагаємося встановити значення r як посилання на x.
Потім внутрішня область видимості закінчується, і ми намагаємося надрукувати
значення в r. Цей код не скомпілюється, тому що значення, на яке r
посилається, вийшло з області видимості до того, як ми спробували його
використати. Ось повідомлення про помилку:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Повідомлення про помилку каже, що змінна x “does not live long enough.”
Причина в тому, що x буде поза областю видимості, коли внутрішня область
видимості закінчиться на рядку 7. Але r все ще є дійсним для зовнішньої
області видимості; оскільки її область видимості більша, ми кажемо, що вона
“lives longer.” Якби Rust дозволив цьому коду працювати, r посилався б на
пам’ять, яка була деалокована, коли x вийшла з області видимості, і все, що
ми намагалися б зробити з r, не працювало б правильно. Отже, як Rust
визначає, що цей код є недійсним? Він використовує перевірник запозичень.
Перевірник запозичень
Компілятор Rust має borrow checker, який порівнює області видимості, щоб визначити, чи всі запозичення є дійсними. Лістинг 10-17 показує той самий код, що й Лістинг 10-16, але з анотаціями, які показують часи життя змінних.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+Тут ми анотували час життя r як 'a, а час життя x як 'b. Як ви
бачите, внутрішній блок 'b є набагато меншим, ніж зовнішній блок часу життя
'a. Під час компіляції Rust порівнює розмір цих двох часів життя і бачить,
що r має час життя 'a, але що він посилається на пам’ять із часом життя
'b. Програма відхиляється, тому що 'b коротший за 'a: об’єкт, на який
вказує посилання, живе не так довго, як саме посилання.
Лістинг 10-18 виправляє код так, що він не має висячого посилання, і він компілюється без жодних помилок.
fn main() {
let x = 5; // ----------+-- 'b
// |
let r = &x; // --+-- 'a |
// | |
println!("r: {r}"); // | |
// --+ |
} // ----------+Тут x має час життя 'b, який у цьому випадку більший за 'a. Це
означає, що r може посилатися на x, тому що Rust знає, що посилання в r
завжди буде дійсним, поки x є дійсним.
Тепер, коли ви знаєте, де знаходяться часи життя посилань і як Rust аналізує часи життя, щоб гарантувати, що посилання завжди будуть дійсними, давайте дослідимо узагальнені часи життя в параметрах функцій і значеннях, що повертаються.
Узагальнені часи життя у функціях
Ми напишемо функцію, яка повертає довше з двох рядкових зрізів. Ця функція
прийматиме два рядкові зрізи й повертатиме один рядковий зріз. Після того як
ми реалізуємо функцію longest, код у Лістингу 10-19 має надрукувати The longest string is abcd.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}Зверніть увагу, що ми хочемо, щоб функція приймала рядкові зрізи, які є
посиланнями, а не рядки, тому що ми не хочемо, щоб функція longest
отримувала власність над своїми параметрами. Зверніться до розділу “String Slices as
Parameters” в Розділі 4 для
детальнішого обговорення того, чому параметри, які ми використовуємо в Лістингу
10-19, є саме тими, які нам потрібні.
Якщо ми спробуємо реалізувати функцію longest, як показано в Лістингу 10-20,
це не скомпілюється.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}Натомість ми отримаємо таку помилку, яка говорить про часи життя:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Допоміжний текст показує, що тип, що повертається, потребує на собі
узагальненого параметра часу життя, тому що Rust не може сказати, чи
посилання, що повертається, посилається на x, чи на y. Насправді, ми
також цього не знаємо, тому що блок if у тілі цієї функції повертає
посилання на x, а блок else повертає посилання на y!
Коли ми визначаємо цю функцію, ми не знаємо конкретних значень, які будуть
передані в цю функцію, тому ми не знаємо, чи виконається випадок if, чи
випадок else. Ми також не знаємо конкретних часів життя посилань, які
будуть передані, тому ми не можемо подивитися на області видимості так, як це
робили в Listings 10-17 і 10-18, щоб визначити, чи посилання, яке ми
повертаємо, завжди буде дійсним. Перевірник запозичень теж не може це
визначити, тому що він не знає, як часи життя x і y пов’язані з часом
життя значення, що повертається. Щоб виправити цю помилку, ми додамо
узагальнені параметри часу життя, які визначають зв’язок між посиланнями, щоб
перевірник запозичень міг виконати свій аналіз.
Синтаксис анотацій часу життя
Анотації часу життя не змінюють того, як довго живе будь-яке з посилань. Натомість, вони описують зв’язки між часами життя кількох посилань одне з одним, не впливаючи на самі часи життя. Так само як функції можуть приймати будь-який тип, коли сигнатура задає узагальнений параметр типу, функції можуть приймати посилання з будь-яким часом життя, якщо вказати узагальнений параметр часу життя.
Анотації часу життя мають дещо незвичайний синтаксис: імена параметрів часу
життя мають починатися з апострофа (') і зазвичай складаються з малих літер
та є дуже короткими, як і узагальнені типи. Більшість людей використовують
ім’я 'a для першої анотації часу життя. Ми розміщуємо анотації параметра
часу життя після & посилання, використовуючи пробіл, щоб відокремити
анотацію від типу посилання.
Ось кілька прикладів — посилання на i32 без параметра часу життя, посилання
на i32, яке має параметр часу життя з ім’ям 'a, і змінне посилання на
i32, яке також має час життя 'a:
&i32 // a reference
&'a i32 // a reference with an explicit lifetime
&'a mut i32 // a mutable reference with an explicit lifetimeОдна анотація часу життя сама по собі не має великого значення, тому що
анотації призначені для того, щоб показати Rust, як узагальнені параметри
часу життя кількох посилань пов’язані між собою. Давайте розглянемо, як
анотації часу життя пов’язані одна з одною в контексті функції longest.
У сигнатурах функцій
Щоб використовувати анотації часу життя в сигнатурах функцій, нам потрібно оголосити узагальнені параметри часу життя всередині кутових дужок між назвою функції та списком параметрів, так само як ми робили з узагальненими параметрами типу.
Ми хочемо, щоб сигнатура виражала таке обмеження: посилання, що повертається,
буде дійсним, поки дійсні обидва параметри. Це і є зв’язок між часами життя
параметрів і значенням, що повертається. Ми назвемо час життя 'a, а потім
додамо його до кожного посилання, як показано в Лістингу 10-21.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}Цей код має скомпілюватися і дати результат, який ми хочемо, коли ми
використаємо його з функцією main у Listing 10-19.
Тепер сигнатура функції каже Rust, що для деякого часу життя 'a функція
приймає два параметри, обидва з яких є рядковими зрізами, що живуть щонайменше
так довго, як час життя 'a. Сигнатура функції також каже Rust, що рядковий
зріз, який повертається з функції, буде жити щонайменше так довго, як час
життя 'a. На практиці це означає, що час життя посилання, яке повертається
функцією longest, є таким самим, як менший із часів життя значень, на які
посилаються аргументи функції. Саме такі зв’язки ми хочемо, щоб Rust
використовував під час аналізу цього коду.
Пам’ятайте, коли ми вказуємо параметри часу життя в цій сигнатурі функції, ми
не змінюємо час життя жодних переданих або повернених значень. Натомість ми
вказуємо, що перевірник запозичень має відхиляти будь-які значення, які не
дотримуються цих обмежень. Зверніть увагу, що функції longest не потрібно
точно знати, як довго житимуть x і y, лише те, що для 'a може бути
підставлена деяка область видимості, яка задовольнить цю сигнатуру.
Під час анотування часів життя у функціях анотації розміщуються в сигнатурі функції, а не в тілі функції. Анотації часу життя стають частиною контракту функції, так само як типи в сигнатурі. Те, що сигнатури функцій містять контракт часу життя, означає, що аналіз, який виконує компілятор Rust, може бути простішим. Якщо є проблема з тим, як функція анотована або як вона викликається, помилки компілятора можуть точніше вказати на частину нашого коду та на обмеження. Якщо ж компілятор Rust робив би більше висновків про те, якими ми маємо на увазі зв’язки між часами життя, компілятор, можливо, міг би вказати лише на використання нашого коду за багато кроків від причини проблеми.
Коли ми передаємо конкретні посилання до longest, конкретний час життя, який
підставляється замість 'a, є частиною області видимості x, що
перетинається з областю видимості y. Іншими словами, узагальнений час життя
'a отримає конкретний час життя, який дорівнює меншому з часів життя x і
y. Оскільки ми анотували посилання, що повертається, тим самим параметром
часу життя 'a, посилання, що повертається, також буде дійсним протягом
меншого з часів життя x і y.
Давайте подивимося, як анотації часу життя обмежують функцію longest, коли
ми передаємо посилання з різними конкретними часами життя. Лістинг 10-22 —
це простий приклад.
fn main() {
let string1 = String::from("long string is long");
{
let string2 = String::from("xyz");
let result = longest(string1.as_str(), string2.as_str());
println!("The longest string is {result}");
}
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}У цьому прикладі string1 є дійсним до кінця зовнішньої області видимості,
string2 є дійсним до кінця внутрішньої області видимості, а result
посилається на щось, що є дійсним до кінця внутрішньої області видимості.
Запустіть цей код, і ви побачите, що перевірник запозичень схвалює його; він
скомпілюється і надрукує The longest string is long string is long.
Далі давайте спробуємо приклад, який показує, що час життя посилання в
result має бути меншим часом життя з двох аргументів. Ми перемістимо
оголошення змінної result за межі внутрішньої області видимості, але
залишимо присвоєння значення змінній result у межах області з string2.
Потім ми перенесемо println!, який використовує result, за межі внутрішньої
області видимості, після того як внутрішня область видимості закінчиться. Код
у Лістингу 10-23 не скомпілюється.
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}Коли ми намагаємося скомпілювати цей код, ми отримуємо таку помилку:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
5 | let string2 = String::from("xyz");
| ------- binding `string2` declared here
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {result}");
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Помилка показує, що для того, щоб result був дійсним для оператора
println!, string2 мав би бути дійсним до кінця зовнішньої області
видимості. Rust знає це, тому що ми анотували часи життя параметрів функції
та значень, що повертаються, використовуючи той самий параметр часу життя
'a.
Як люди, ми можемо подивитися на цей код і побачити, що string1 довший за
string2, і, отже, result міститиме посилання на string1. Оскільки
string1 ще не вийшов з області видимості, посилання на string1 усе ще
буде дійсним для оператора println!. Однак компілятор не може побачити, що
в цьому випадку посилання є дійсним. Ми сказали Rust, що час життя посилання,
яке повертає функція longest, є таким самим, як менший із часів життя
посилань, що передаються. Тому перевірник запозичень не дозволяє код у
Listing 10-23 як такий, що потенційно має недійсне посилання.
Спробуйте спроєктувати ще експерименти, які змінюють значення та часи життя
посилань, переданих у функцію longest, і спосіб використання посилання, що
повертається. До того, як скомпілювати, висувайте гіпотези про те, чи
пройдуть ваші експерименти перевірку запозичень; потім перевірте, чи ви
маєте рацію!
Мислити категоріями часів життя (Відношення)
Те, як саме вам потрібно вказувати параметри часу життя, залежить від того,
що робить ваша функція. Наприклад, якби ми змінили реалізацію функції
longest так, щоб вона завжди повертала перший параметр, а не найдовший
рядковий зріз, нам не потрібно було б вказувати час життя для параметра y.
Наступний код буде скомпільовано:
fn main() {
let string1 = String::from("abcd");
let string2 = "efghijklmnopqrstuvwxyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &str) -> &'a str {
x
}Ми вказали параметр часу життя 'a для параметра x і типу, що повертається,
але не для параметра y, тому що час життя y не має жодного зв’язку з
часом життя x або значення, що повертається.
Коли повертається посилання з функції, параметр часу життя для типу, що
повертається, має збігатися з параметром часу життя для одного з параметрів.
Якщо посилання, що повертається, не посилається на один із параметрів, воно
має посилатися на значення, створене всередині цієї функції. Однак це було б
висячим посиланням, тому що значення вийде з області видимості в кінці
функції. Розгляньте цю спробу реалізації функції longest, яка не
скомпілюється:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}Тут, хоча ми й вказали параметр часу життя 'a для типу, що повертається,
ця реалізація не зможе скомпілюватися, тому що час життя значення, що
повертається, взагалі не пов’язаний з часами життя параметрів. Ось
повідомлення про помилку, яке ми отримуємо:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return value referencing local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Проблема в тому, що result виходить з області видимості та очищується в
кінці функції longest. Ми також намагаємося повернути з функції посилання
на result. Немає способу, яким ми могли б вказати параметри часу життя, що
змінили б висяче посилання, і Rust не дозволить нам створити висяче
посилання. У цьому випадку найкращим виправленням було б повернути власний
тип даних, а не посилання, щоб функція, яка викликає, потім відповідала за
очищення значення.
Зрештою, синтаксис часу життя — це про з’єднання часів життя різних параметрів і значень, що повертаються, функцій. Після того як вони з’єднані, Rust має достатньо інформації, щоб дозволити безпечні для пам’яті операції та заборонити операції, які створювали б висячі посилання (вказівники) або іншим чином порушували б безпеку пам’яті.
У визначеннях структур
Поки що всі структури, які ми визначили, містять власні типи. Ми можемо
визначати структури, щоб вони містили посилання, але в такому разі нам
потрібно буде додати анотацію часу життя до кожного посилання у визначенні
структури. Лістинг 10-24 містить структуру з назвою ImportantExcerpt, яка
містить рядковий зріз.
struct ImportantExcerpt<'a> {
part: &'a str,
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Ця структура має єдине поле part, яке містить рядковий зріз, тобто
посилання. Як і у випадку з узагальненими типами даних, ми оголошуємо ім’я
узагальненого параметра часу життя всередині кутових дужок після імені
структури, щоб ми могли використовувати параметр часу життя в тілі визначення
структури. Ця анотація означає, що екземпляр ImportantExcerpt не може
пережити посилання, яке він містить у своєму полі part.
Функція main тут створює екземпляр структури ImportantExcerpt, який
містить посилання на перше речення String, що належить змінній novel.
Дані в novel існують до того, як екземпляр ImportantExcerpt буде
створений. Крім того, novel не виходить з області видимості, доки не вийде
з області видимості ImportantExcerpt, тож посилання в екземплярі
ImportantExcerpt є дійсним.
Скорочення часу життя
Ви дізналися, що кожне посилання має час життя і що вам потрібно вказувати параметри часу життя для функцій або структур, які використовують посилання. Однак у нас була функція в Лістингу 4-9, знову показана в Лістингу 10-25, яка скомпілювалася без анотацій часу життя.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// first_word works on slices of `String`s
let word = first_word(&my_string[..]);
let my_string_literal = "hello world";
// first_word works on slices of string literals
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}Причина, чому ця функція компілюється без анотацій часу життя, є історичною: у ранніх версіях Rust (до 1.0) цей код не скомпілювався б, тому що кожне посилання потребувало явного часу життя. На той час сигнатура функції була б написана так:
fn first_word<'a>(s: &'a str) -> &'a str {Після написання великої кількості коду Rust команда Rust виявила, що програмісти Rust у певних ситуаціях знову й знову вводили ті самі анотації часу життя. Ці ситуації були передбачуваними та підкорялися кільком детермінованим шаблонам. Розробники вбудували ці шаблони в код компілятора, щоб перевірник запозичень міг виводити часи життя в цих ситуаціях і не потребував явних анотацій.
Ця частина історії Rust є важливою, тому що цілком можливо, що з’являться нові детерміновані шаблони й будуть додані до компілятора. У майбутньому може знадобитися ще менше анотацій часу життя.
Шаблони, вбудовані в аналіз посилань Rust, називаються правилами скорочення часу життя (lifetime elision rules). Це не правила, яких мають дотримуватися програмісти; це набір окремих випадків, які компілятор розглядатиме, і якщо ваш код підпадає під ці випадки, вам не потрібно явно писати часи життя.
Правила скорочення не забезпечують повного виведення. Якщо після того, як Rust застосує правила, усе ще залишається неоднозначність щодо того, які часи життя мають посилання, компілятор не вгадуватиме, яким має бути час життя решти посилань. Замість здогадування компілятор видасть помилку, яку ви можете усунути, додавши анотації часу життя.
Часи життя для параметрів функції або методу називаються вхідними часами життя (input lifetimes), а часи життя для значень, що повертаються, — вихідними часами життя (output lifetimes).
Компілятор використовує три правила, щоб визначити часи життя посилань, коли
немає явних анотацій. Перше правило застосовується до вхідних часів життя, а
друге і третє — до вихідних часів життя. Якщо компілятор доходить до кінця
трьох правил, а все ще є посилання, для яких він не може визначити часи
життя, компілятор зупиняється з помилкою. Ці правила застосовуються до
визначень fn, а також до блоків impl.
Перше правило полягає в тому, що компілятор призначає параметр часу життя
кожному параметру, який є посиланням. Іншими словами, функція з одним
параметром отримує один параметр часу життя: fn foo<'a>(x: &'a i32); функція
з двома параметрами отримує два окремі параметри часу життя:
fn foo<'a, 'b>(x: &'a i32, y: &'b i32); і так далі.
Друге правило полягає в тому, що якщо існує рівно один вхідний параметр часу
життя, то цей час життя призначається всім вихідним параметрам часу життя:
fn foo<'a>(x: &'a i32) -> &'a i32.
Третє правило полягає в тому, що якщо є кілька вхідних параметрів часу життя,
але один із них — це &self або &mut self, тому що це метод, то час життя
self призначається всім вихідним параметрам часу життя. Це третє правило
робить методи набагато приємнішими для читання та написання, тому що потрібно
менше символів.
Давайте уявімо, що ми — компілятор. Ми застосуємо ці правила, щоб визначити
часи життя посилань у сигнатурі функції first_word у Listing 10-25.
Сигнатура починається без жодних часів життя, пов’язаних із посиланнями:
fn first_word(s: &str) -> &str {Потім компілятор застосовує перше правило, яке визначає, що кожен параметр
отримує свій власний час життя. Ми назвемо його 'a, як зазвичай, тож тепер
сигнатура виглядає так:
fn first_word<'a>(s: &'a str) -> &str {Друге правило застосовується, тому що є рівно один вхідний час життя. Друге правило визначає, що час життя одного вхідного параметра призначається вихідному часу життя, тож тепер сигнатура така:
fn first_word<'a>(s: &'a str) -> &'a str {Тепер усі посилання в цій сигнатурі функції мають часи життя, і компілятор може продовжити свій аналіз без потреби в тому, щоб програміст анотував часи життя в цій сигнатурі функції.
Розгляньмо ще один приклад, цього разу використовуючи функцію longest,
яка не мала параметрів часу життя, коли ми почали працювати з нею в Listing
10-20:
fn longest(x: &str, y: &str) -> &str {Застосуймо перше правило: кожен параметр отримує свій власний час життя. Цього разу в нас два параметри замість одного, тож маємо два часи життя:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {Ви бачите, що друге правило не застосовується, тому що вхідних часів життя
більше ніж один. Третє правило також не застосовується, тому що longest є
функцією, а не методом, тож жоден із параметрів не є self. Після виконання
всіх трьох правил ми все ще не з’ясували, який час життя має тип, що
повертається. Саме тому ми отримали помилку, намагаючись скомпілювати код у
Listing 10-20: компілятор пройшовся правилами скорочення часу життя, але все
ще не зміг визначити всі часи життя посилань в сигнатурі.
Оскільки третє правило справді застосовується лише в сигнатурах методів, далі ми розглянемо часи життя в цьому контексті, щоб побачити, чому третє правило означає, що нам не потрібно дуже часто анотувати часи життя в сигнатурах методів.
У визначеннях методів
Коли ми реалізуємо методи для структури з часами життя, ми використовуємо той самий синтаксис, що й для узагальнених параметрів типу, як показано в Listing 10-11. Те, де ми оголошуємо та використовуємо параметри часу життя, залежить від того, чи пов’язані вони з полями структури, чи з параметрами методу та значеннями, що повертаються.
Імена часів життя для полів структури завжди потрібно оголошувати після
ключового слова impl, а потім використовувати після імені структури, тому
що ці часи життя є частиною типу структури.
У сигнатурах методів усередині блоку impl посилання можуть бути пов’язані з
часом життя посилань у полях структури або можуть бути незалежними. Крім того,
правила скорочення часу життя часто роблять так, що анотації часу життя не є
потрібними в сигнатурах методів. Давайте розглянемо кілька прикладів,
використовуючи структуру з назвою ImportantExcerpt, яку ми визначили в
Listing 10-24.
Спочатку ми використаємо метод з назвою level, єдиним параметром якого є
посилання на self, а значенням, що повертається, є i32, який не є
посиланням на щось:
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Оголошення параметра часу життя після impl і його використання після назви
типу є обов’язковими, але через перше правило скорочення ми не зобов’язані
анотувати час життя посилання на self.
Ось приклад, де застосовується третє правило скорочення часу життя:
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Тут є два вхідні часи життя, тому Rust застосовує перше правило скорочення
часу життя й надає і &self, і announcement власні часи життя. Потім,
оскільки один із параметрів — це &self, тип, що повертається, отримує час
життя &self, і всі часи життя враховано.
Статичний час життя
Один особливий час життя, про який нам потрібно поговорити, — це 'static,
який означає, що відповідне посилання може жити протягом усього часу
виконання програми. Усі рядкові літерали мають час життя 'static, який ми
можемо анотувати так:
#![allow(unused)]
fn main() {
let s: &'static str = "I have a static lifetime.";
}Текст цього рядка зберігається безпосередньо в бінарному файлі програми, який
завжди доступний. Тому час життя всіх рядкових літералів — це 'static.
Ви можете побачити в повідомленнях про помилки пропозиції використовувати час
життя 'static. Але перш ніж вказувати 'static як час життя для
посилання, подумайте, чи справді посилання, яке ви маєте, живе весь час
життя вашої програми, і чи ви цього хочете. Найчастіше повідомлення про
помилку, що пропонує час життя 'static, є результатом спроби створити
висяче посилання або невідповідності доступних часів життя. У таких випадках
рішення полягає у виправленні цих проблем, а не у вказуванні часу життя
'static.
Узагальнені параметри типу, обмеження трейтів та часи життя разом
Давайте коротко подивимося на синтаксис указування узагальнених параметрів типу, обмежень трейту та часів життя — усе в одній функції!
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest_with_an_announcement(
string1.as_str(),
string2,
"Today is someone's birthday!",
);
println!("The longest string is {result}");
}
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(
x: &'a str,
y: &'a str,
ann: T,
) -> &'a str
where
T: Display,
{
println!("Announcement! {ann}");
if x.len() > y.len() { x } else { y }
}Це функція longest з Listing 10-21, яка повертає довше з двох рядкових
зрізів. Але тепер у неї є додатковий параметр з назвою ann узагальненого
типу T, який може бути підставлений будь-яким типом, що реалізує трейт
Display, як визначено в фразі where. Цей додатковий параметр буде
виводитися за допомогою {}, саме тому обмеження трейтів Display є
необхідним. Оскільки часи життя є видом узагальненого типу, оголошення
параметра часу життя 'a та узагальненого параметра типу T розміщуються в
одному списку всередині кутових дужок після імені функції.
Підсумок
У цьому розділі ми охопили багато! Тепер, коли ви знаєте про узагальнені параметри типу, трейти та обмеження трейтів, а також про узагальнені параметри часу життя, ви готові писати код без повторення, який працює в багатьох різних ситуаціях. Узагальнені параметри типу дозволяють застосовувати код до різних типів. Трейти та обмеження трейтів гарантують, що хоча типи й є узагальненими, вони матимуть поведінку, яка потрібна коду. Ви навчилися використовувати анотації часу життя, щоб гарантувати, що цей гнучкий код не матиме висячих посилань. І все це відбувається під час компіляції, що не впливає на продуктивність під час виконання!
Вірте чи ні, але ще багато чого потрібно вивчити на теми, які ми обговорювали в цьому розділі: Розділ 18 розглядає об’єкти трейтів, які є ще одним способом використання трейтів. Також існують складніші сценарії, що стосуються анотацій часу життя, які вам знадобляться лише в дуже просунутих випадках; для них вам слід прочитати Rust Reference. Але далі ви навчитеся писати тести в Rust, щоб переконатися, що ваш код працює так, як повинен.
Написання автоматизованих тестів (Writing Automated Tests)
У своєму есе 1972 року “The Humble Programmer” Едсгер В. Дейкстра сказав, що “Тестування програм може бути дуже ефективним способом показати наявність помилок, але воно безнадійно недостатнє для показу їхньої відсутності.” (“program testing can be a very effective way to show the presence of bugs, but it is hopelessly inadequate for showing their absence.”) Це не означає, що нам не слід намагатися тестувати якнайбільше!
Правильність у наших програмах — це міра того, наскільки наш код робить те, що ми маємо намір, щоб він робив. Rust розроблено з високим рівнем уваги до правильності програм, але правильність є складною і її не так легко довести. Система типів Rust бере на себе величезну частину цього тягаря, але система типів не може вловити все. Тому Rust включає підтримку для написання автоматизованих програмних тестів.
Припустімо, ми пишемо функцію add_two, яка додає 2 до будь-якого числа,
переданого їй. Сигнатура цієї функції приймає ціле число як параметр і
повертає ціле число як результат. Коли ми реалізуємо й компілюємо цю функцію,
Rust виконує всю перевірку типів і перевірку запозичень, яку ви вже вивчили,
щоб переконатися, що, наприклад, ми не передаємо цій функції значення String
або недійсне посилання. Але Rust не може перевірити, що ця функція робитиме
саме те, що ми маємо намір, а саме повертатиме параметр плюс 2, а не, скажімо,
параметр плюс 10 або параметр мінус 50! Саме тут і з’являються тести.
Ми можемо написати тести, які стверджують, наприклад, що коли ми передаємо 3
до функції add_two, то повернене значення є 5. Ми можемо запускати ці тести
кожного разу, коли вносимо зміни до нашого коду, щоб переконатися, що будь-яка
наявна правильна поведінка не змінилася.
Тестування — це складна навичка: хоча ми не можемо в одному розділі охопити всі деталі про те, як писати хороші тести, у цьому розділі ми обговоримо механіку засобів тестування Rust. Ми поговоримо про анотації та макроси, доступні вам під час написання ваших тестів, поведінку за замовчуванням і параметри, надані для запуску ваших тестів, а також про те, як організувати тести в модульні тести (unit tests) та інтеграційні тести (integration tests).
Як писати тести
Як писати тести
Тести — це функції Rust, які перевіряють, що не-тестовий код працює очікуваним чином. Тіла тестових функцій зазвичай виконують ці три дії:
- Налаштовують будь-які потрібні дані або стан.
- Запускають код, який ви хочете протестувати.
- Перевіряють, що результати такі, як ви очікуєте.
Розгляньмо можливості, які Rust надає спеціально для написання тестів, що виконують ці дії, зокрема атрибут test, кілька макросів і атрибут should_panic.
Структурування тестових функцій
У найпростішому вигляді тест у Rust — це функція, позначена атрибутом test. Атрибути — це метадані про частини коду Rust; одним із прикладів є атрибут derive, який ми використовували зі структурами в Розділі 5. Щоб перетворити функцію на тестову функцію, додайте #[test] у рядку перед fn. Коли ви запускаєте тести за допомогою команди cargo test, Rust будує двійковий файл запускника (runner) тестів, який запускає позначені функції та звітує, чи проходить або не проходить кожна тестова функція.
Щоразу, коли ми створюємо новий бібліотечний проєкт за допомогою Cargo, для нас автоматично генерується модуль тестів із тестовою функцією всередині. Цей модуль дає вам шаблон для написання тестів, тож вам не потрібно щоразу, коли ви починаєте новий проєкт, шукати точну структуру та синтаксис. Ви можете додати стільки додаткових тестових функцій і стільки тестових модулів, скільки хочете!
Ми дослідимо деякі аспекти того, як працюють тести, експериментуючи з шаблонним тестом, перш ніж ми насправді протестуємо будь-який код. Потім ми напишемо кілька реальних тестів, які викликають код, що ми написали, і перевіряють, що його поведінка правильна.
Створімо новий бібліотечний проєкт під назвою adder, який додаватиме два числа:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
Вміст файлу src/lib.rs у вашій бібліотеці adder має виглядати як у Лістингу 11-1.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Файл починається з прикладу функції add, щоб у нас було що тестувати.
Наразі зосередьмося лише на функції it_works. Зверніть увагу на анотацію #[test]: цей атрибут указує, що це тестова функція, тож runner тестів знає, що треба розглядати цю функцію як тест. У модулі tests у нас також можуть бути нетестові функції, щоб допомагати налаштовувати спільні сценарії або виконувати спільні операції, тому нам завжди потрібно вказувати, які функції є тестами.
Тіло прикладної функції використовує макрос assert_eq!, щоб перевірити, що result, який містить результат виклику add з 2 і 2, дорівнює 4. Це твердження слугує прикладом формату типового тесту. Запустімо його, щоб побачити, що цей тест проходить.
Команда cargo test запускає всі тести в нашому проєкті, як показано в Listing 11-2.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-01ad14159ff659ab)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo скомпілював і запустив тест. Ми бачимо рядок running 1 test. Наступний рядок показує ім’я згенерованої тестової функції, яка називається tests::it_works, і що результат виконання цього тесту — ok. Загальний підсумок test result: ok. означає, що всі тести пройшли, а частина, де написано 1 passed; 0 failed, підсумовує кількість тестів, що пройшли або не пройшли.
Можна позначити тест як ignored, щоб він не запускався в конкретному випадку; ми розглянемо це в розділі «Ігнорування тестів, якщо явно не запитано» пізніше в цій главі. Оскільки ми цього тут не робили, підсумок показує 0 ignored. Ми також можемо передати аргумент команді cargo test, щоб запускати лише тести, чиї імена збігаються з рядком; це називається filtering, і ми розглянемо це в розділі «Запуск підмножини тестів за іменем». Тут ми не фільтрували тести, які запускаються, тож у кінці підсумку показано 0 filtered out.
Статистика 0 measured призначена для benchmark-тестів, які вимірюють продуктивність. Benchmark-тести, на момент написання цього тексту, доступні лише в нічній (nightly) версії Rust. Докладніше дивіться документацію про benchmark-тести.
Наступна частина виводу тесту, що починається з Doc-tests adder, стосується результатів будь-яких тестів документації (documentation tests). У нас поки що немає тестів документації, але Rust може скомпілювати будь-які приклади коду, що з’являються в нашій документації API. Ця можливість допомагає підтримувати синхронізацію між документацією та кодом! Ми обговоримо, як писати тести документації, у розділі «Коментарі документації як тести» в Розділі 14. Наразі проігноруємо вивід Doc-tests.
Почнімо налаштовувати тест під наші потреби. Спочатку змініть ім’я функції it_works на інше, наприклад exploration, ось так:
Filename: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Потім знову запустіть cargo test. Тепер у виводі показано exploration замість it_works:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Тепер ми додамо ще один тест, але цього разу створимо тест, який не пройде! Тести не проходять, коли щось у тестовій функції спричиняє паніку (panic). Кожен тест запускається в новому потоці (thread), і коли головний потік бачить, що тестовий потік завершився, тест позначається як неуспішний. У Розділі 9 ми говорили про те, що найпростіший спосіб викликати паніку — це викликати макрос panic!. Введіть новий тест як функцію з іменем another, щоб ваш файл src/lib.rs виглядав як у Listing 11-3.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}Запустіть тести знову за допомогою cargo test. Вивід має виглядати як у Listing 11-4, де показано, що наш тест exploration пройшов, а another не пройшов.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at src/lib.rs:17:9:
Make this test fail
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Замість ok рядок test tests::another показує FAILED. Між окремими результатами та підсумком з’являються два нові розділи: перший показує докладну причину кожного невдалого (failure) тесту. У цьому випадку ми отримуємо деталі, що tests::another не пройшов, тому що спричинив паніку (panic) із повідомленням Make this test fail у рядку 17 файлу src/lib.rs. Наступний розділ перелічує лише імена всіх тестів, що не пройшли, що корисно, коли є багато тестів і багато докладного виводу про збої. Ми можемо використати ім’я тесту, що не пройшов, щоб запустити лише цей тест і легше налагодити його; про способи запуску тестів ми ще поговоримо в Розділі «Керування тим, як запускаються тести».
Рядок підсумку відображається наприкінці: загалом наш результат тестів — FAILED. Один тест пройшов і один тест не пройшов.
Тепер, коли ви побачили, як виглядають результати тестів у різних сценаріях, розгляньмо деякі інші макроси, окрім panic!, які корисні в тестах.
Перевірка результатів за допомогою assert!
Макрос assert!, наданий стандартною бібліотекою, корисний, коли ви хочете переконатися, що деяка умова в тесті обчислюється як true. Ми передаємо макросу assert! аргумент, який обчислюється до Boolean. Якщо значення true, нічого не відбувається, і тест проходить. Якщо значення false, макрос assert! викликає panic!, щоб спричинити збій тесту. Використання макроса assert! допомагає нам перевіряти, що наш код працює так, як ми задумали.
У Розділі 5, Listing 5-15, ми використовували структуру Rectangle і метод can_hold, які повторюються тут у Listing 11-5. Помістімо цей код у файл src/lib.rs, а потім напишімо для нього кілька тестів, використовуючи макрос assert!.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}Метод can_hold повертає Boolean, а отже це ідеальний випадок використання макроса assert!. У Лістингу 11-6 ми пишемо тест, який перевіряє метод can_hold, створюючи екземпляр Rectangle з шириною 8 і висотою 7 та стверджуючи, що він може вмістити інший екземпляр Rectangle з шириною 5 і висотою 1.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}Зверніть увагу на рядок use super::*; всередині модуля tests. Модуль tests — це звичайний модуль, який підпорядковується звичайним правилам видимості, які ми розглядали в Розділі 7 у розділі «Шляхи для звернення до елемента в дереві модулів». Оскільки модуль tests є внутрішнім модулем, нам потрібно зробити код, який тестується, у зовнішньому модулі доступним в області видимості внутрішнього модуля. Тут ми використовуємо glob, тож усе, що ми визначимо у зовнішньому модулі, буде доступне цьому модулю tests.
Ми назвали наш тест larger_can_hold_smaller і створили два екземпляри Rectangle, які нам потрібні. Потім ми викликали макрос assert! і передали йому результат виклику larger.can_hold(&smaller). Цей вираз має повертати true, тож наш тест має пройти. Дізнаймося!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Він справді проходить! Додаймо ще один тест, цього разу стверджуючи, що менший прямокутник не може вмістити більший прямокутник:
Filename: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Оскільки правильний результат функції can_hold у цьому випадку — false, нам потрібно заперечити цей результат перед тим, як передати його макросу assert!. У результаті наш тест пройде, якщо can_hold поверне false:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Два тести, що проходять! Тепер подивімося, що станеться з результатами наших тестів, коли ми внесемо помилку в наш код. Ми змінимо реалізацію методу can_hold, замінивши знак більшого (>) на знак меншого (<) під час порівняння ширин:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Запуск тестів тепер дає таке:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at src/lib.rs:28:9:
assertion failed: larger.can_hold(&smaller)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Наші тести виявили помилку! Оскільки larger.width дорівнює 8, а smaller.width дорівнює 5, порівняння ширин у can_hold тепер повертає false: 8 не менше за 5.
Тестування рівності за допомогою assert_eq! і assert_ne!
Поширений спосіб перевірити функціональність — протестувати рівність між результатом коду, що тестується, і значенням, яке, як ви очікуєте, має повернути код. Ви могли б зробити це, використовуючи макрос assert! і передаючи йому вираз, що використовує оператор ==. Однак це такий поширений тест, що стандартна бібліотека надає пару макросів — assert_eq! і assert_ne! — щоб виконувати цю перевірку зручніше. Ці макроси порівнюють два аргументи на рівність або нерівність відповідно. Вони також виводять два значення, якщо перевірка не проходить, що полегшує розуміння, чому тест не пройшов; натомість макрос assert! лише вказує, що він отримав значення false для виразу ==, без виведення значень, які привели до false.
У Лістинг 11-7 ми пишемо функцію з назвою add_two, яка додає 2 до свого параметра, а потім тестуємо цю функцію, використовуючи макрос assert_eq!.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}Перевірмо, що він проходить!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ми створюємо змінну з назвою result, яка містить результат виклику add_two(2). Потім ми передаємо result і 4 як аргументи макросу assert_eq!. Рядок виводу для цього тесту — test tests::it_adds_two ... ok, а текст ok указує, що наш тест пройшов!
Додаймо помилку в наш код, щоб побачити, як виглядає assert_eq!, коли він не проходить. Змініть реалізацію функції add_two, щоб вона замість цього додавала 3:
pub fn add_two(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}Запустіть тести знову:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at src/lib.rs:12:9:
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Наш тест виявив помилку! Тест tests::it_adds_two не пройшов, а повідомлення каже нам, що перевірка, яка не пройшла, була left == right, і які саме значення left та right. Це повідомлення допомагає нам почати налагодження: аргумент left, де був результат виклику add_two(2), був 5, а аргумент right був 4. Можна уявити, що це було б особливо корисно, коли в нас відбувається багато тестів.
Зверніть увагу, що в деяких мовах і тестових фреймворках (frameworks) параметри функцій перевірки рівності називаються expected і actual, і порядок, у якому ми вказуємо аргументи, має значення. Однак у Rust вони називаються left і right, і порядок, у якому ми вказуємо значення, яке очікуємо, та значення, яке створює код, не має значення. Ми могли б написати перевірку в цьому тесті як assert_eq!(4, result), що дало б те саме повідомлення про збій, яке показує assertion `left == right` failed.
Макрос assert_ne! пройде, якщо два значення, які ми йому передаємо, не рівні, і не пройде, якщо вони рівні. Цей макрос найкорисніший у випадках, коли ми не впевнені, яким буде значення, але знаємо, яким воно точно не повинно бути. Наприклад, якщо ми тестуємо функцію, яка гарантовано змінює свій вхід певним чином, але спосіб, у який вхід змінюється, залежить від дня тижня, коли ми запускаємо тести, найкраще було б стверджувати, що вихід функції не дорівнює входу.
На нижчому рівні макроси assert_eq! і assert_ne! використовують оператори == і != відповідно. Коли перевірки не проходять, ці макроси виводять свої аргументи, використовуючи налагоджувальне форматування (debug formatting), що означає, що значення, які порівнюються, повинні реалізовувати трейти PartialEq і Debug. Усі примітивні типи та більшість типів стандартної бібліотеки реалізують ці трейти. Для структур і переліків, які ви визначаєте самі, вам потрібно буде реалізувати PartialEq, щоб перевіряти рівність цих типів. Вам також потрібно буде реалізувати Debug, щоб виводити значення, коли перевірка не проходить. Оскільки обидва трейти можна автоматично вивести (derivable traits), як згадувалося в Лістингу (Listing) 5-12 у Розділі 5, зазвичай це так само просто, як додати анотацію #[derive(PartialEq, Debug)] до визначення вашої структури або переліку. Дивіться Додаток C, «Трейти, які можна вивести», щоб дізнатися більше про ці та інші трейти, які можна вивести.
Додавання власних повідомлень про збій
Ви також можете додати власне повідомлення, яке буде виводитися разом із повідомленням про збій, як необов’язкові аргументи до макросів assert!, assert_eq! і assert_ne!. Будь-які аргументи, вказані після обов’язкових аргументів, передаються далі макросу format! (обговорюється в розділі «Конкатенація за допомогою + або format!» у Розділі 8), тож ви можете передати рядок формату, який містить заповнювачі {}
та значення для цих заповнювачів. Власні повідомлення корисні для документування того, що означає перевірка; коли тест не проходить, у вас буде краще уявлення про те, у чому проблема з кодом.
Наприклад, припустімо, що в нас є функція, яка вітає людей на ім’я, і ми хочемо перевірити, що ім’я, яке ми передаємо у функцію, з’являється у виводі:
Filename: src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {name}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Вимоги до цієї програми ще не узгоджені, і ми досить певні, що текст Hello на початку привітання зміниться. Ми вирішили, що не хочемо оновлювати тест, коли вимоги зміняться, тож замість перевірки точної рівності значенню, яке повертає функція greeting, ми просто стверджуватимемо, що вихід містить текст вхідного параметра.
Тепер додаймо помилку в цей код, змінивши greeting так, щоб він не включав name, і подивімося, як виглядає стандартний збій тесту:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Запуск цього тесту дає таке:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
assertion failed: result.contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Цей результат просто вказує, що перевірка не пройшла, і на якому рядку знаходиться ця перевірка. Корисніше повідомлення про збій вивело б значення з функції greeting. Додаймо власне повідомлення про збій, складене з рядка формату із заповнювачем, заповненим фактичним значенням, яке ми отримали з функції greeting:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{result}`"
);
}
}Тепер, коли ми запустимо тест, отримаємо більш інформативне повідомлення про помилку:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
Greeting did not contain name, value was `Hello!`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Ми бачимо значення, яке насправді отримали у виводі тесту, що допоможе нам налагодити те, що сталося, замість того, що, як ми очікували, мало статися.
Перевірка panic за допомогою should_panic
Окрім перевірки значень, що повертаються, важливо перевіряти, що наш код обробляє умови помилки так, як ми очікуємо. Наприклад, розгляньте тип Guess, який ми створили в Розділі 9, Лістингу (Listing) 9-13. Інший код, що використовує Guess, покладається на гарантію, що екземпляри Guess міститимуть лише значення між 1 і 100. Ми можемо написати тест, який переконується, що спроба створити екземпляр Guess зі значенням поза цим діапазоном спричиняє паніку (panic).
Ми робимо це, додаючи атрибут should_panic до нашої тестової функції. Тест проходить, якщо код усередині функції спричиняє panic; тест не проходить, якщо код усередині функції не спричиняє panic.
Лістинг (Listing) 11-8 показує тест, який перевіряє, що умови помилки Guess::new виникають тоді, коли ми цього очікуємо.
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}Ми розміщуємо атрибут #[should_panic] після атрибута #[test] і перед тестовою функцією, до якої він застосовується. Подивімося на результат, коли цей тест проходить:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Виглядає добре! Тепер додаймо помилку в наш код, видаливши умову, за якої функція new спричинятиме panic, якщо значення більше за 100:
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}Коли ми запустимо тест у Лістингу 11-8, він не пройде:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected at src/lib.rs:21:8
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
У цьому випадку ми не отримуємо дуже корисного повідомлення, але коли дивимося на тестову функцію, бачимо, що вона позначена #[should_panic]. Отриманий нами збій означає, що код у тестовій функції не спричинив паніку (panic).
Тести, які використовують should_panic, можуть бути неточними. Тест should_panic пройде навіть тоді, коли тест спричиняє паніку з іншої причини, ніж та, яку ми очікували. Щоб зробити тести should_panic точнішими, ми можемо додати необов’язковий параметр expected до атрибута should_panic. Тестове середовище (test harness) переконається, що повідомлення про збій містить наданий текст. Наприклад, розгляньте змінений код для Guess у Лістингу 11-9, де функція new спричиняє паніку з різними повідомленнями залежно від того, чи значення надто мале, чи надто велике.
pub struct Guess {
value: i32,
}
// ANCHOR: here
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}
// ANCHOR_END: hereЦей тест пройде, тому що значення, яке ми помістили в параметр expected атрибута should_panic, є підрядком повідомлення, з яким функція Guess::new спричиняє panic. Ми могли б указати й усе повідомлення про panic, яке очікуємо, і в цьому випадку воно було б Guess value must be less than or equal to 100, got 200. Те, що ви обираєте вказувати, залежить від того, яка частина повідомлення про panic є унікальною або динамічною і наскільки точним ви хочете зробити свій тест. У цьому випадку підрядка повідомлення про panic достатньо, щоб переконатися, що код у тестовій функції виконує випадок else if value > 100.
Щоб побачити, що станеться, коли тест should_panic із повідомленням expected не проходить, знову внесімо помилку в наш код, помінявши місцями тіла блоків if value < 1 і else if value > 100:
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}Цього разу, коли ми запустимо тест should_panic, він не пройде:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:12:13:
Guess value must be greater than or equal to 1, got 200.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: "Guess value must be greater than or equal to 1, got 200."
expected substring: "less than or equal to 100"
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Повідомлення про збій вказує, що цей тест справді спричинив panic, як ми й очікували, але повідомлення про panic не містило очікуваного рядка less than or equal to 100. Повідомлення про panic, яке ми отримали в цьому випадку, було Guess value must be greater than or equal to 1, got 200. Тепер ми можемо почати з’ясовувати, де наша помилка!
Використання Result<T, E> у тестах
Усі наші тести досі не проходять, коли виникає паніка (panic). Ми також можемо писати тести, які використовують Result<T, E>! Ось тест із Лістингу 11-1, переписаний так, щоб використовувати Result<T, E> і повертати Err замість спричинення паніки:
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() -> Result<(), String> {
let result = add(2, 2);
if result == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}Функція it_works тепер має тип повернення Result<(), String>. У тілі функції, замість виклику макроса assert_eq!, ми повертаємо Ok(()), коли тест проходить, і Err зі String усередині, коли тест не проходить.
Написання тестів так, щоб вони повертали Result<T, E>, дає змогу використовувати оператор знака питання в тілі тестів, що може бути зручним способом писати тести, які мають не пройти, якщо будь-яка операція всередині них повертає варіант Err.
Ви не можете використовувати анотацію #[should_panic] у тестах, які використовують Result<T, E>. Щоб стверджувати, що операція повертає варіант Err, не використовуйте оператор знака питання для значення Result<T, E>. Замість цього використовуйте assert!(value.is_err()).
Тепер, коли ви знаєте кілька способів писати тести, розгляньмо, що відбувається, коли ми запускаємо наші тести, і дослідимо різні параметри, які ми можемо використовувати з cargo test.
Керування тим, як запускаються тести
Керування тим, як запускаються тести
Так само як cargo run компілює ваш код, а потім запускає отриманий двійковий файл,
cargo test компілює ваш код у режимі тестування і запускає отриманий тестовий
двійковий файл. Поведінка за замовчуванням двійкового файлу, створеного cargo test, полягає в тому, щоб запускати
всі тести паралельно й перехоплювати виведення, згенероване під час запуску тестів,
не дозволяючи відображати це виведення і полегшуючи читання
виведення, пов’язаного з результатами тестів. Однак ви можете вказати параметри командного рядка,
щоб змінити цю поведінку за замовчуванням.
Деякі параметри командного рядка передаються до cargo test, а деякі — до отриманого тестового
двійкового файлу. Щоб відокремити ці два типи аргументів, ви перелічуєте аргументи, які
передаються до cargo test, за якими слідує роздільник --, а потім ті, що
передаються до тестового двійкового файлу. Запуск cargo test --help показує параметри, які ви можете використовувати
з cargo test, а запуск cargo test -- --help показує параметри, які ви
можете використовувати після роздільника. Ці параметри також документовані в Розділі “Tests”
The rustc Book.
Запуск тестів паралельно або послідовно
Коли ви запускаєте кілька тестів, за замовчуванням вони запускаються паралельно, використовуючи потоки, тобто вони завершуються швидше, і ви отримуєте відгук раніше. Оскільки тести виконуються одночасно, ви маєте переконатися, що ваші тести не залежать один від одного або від будь-якого спільного стану, включно зі спільним середовищем, таким як поточний робочий каталог або змінні середовища.
Наприклад, припустімо, що кожен із ваших тестів виконує деякий код, який створює файл на диску з іменем test-output.txt і записує деякі дані в цей файл. Потім кожен тест читає дані в цьому файлі і стверджує, що файл містить певне значення, яке в кожному тесті різне. Оскільки тести виконуються одночасно, один тест може перезаписати файл у проміжку між тим, як інший тест записує і читає файл. Тоді другий тест завершиться помилкою не тому, що код неправильний, а тому, що тести завадили один одному під час паралельного виконання. Одне з рішень — переконатися, що кожен тест записує в окремий файл; інше рішення — запускати тести по одному.
Якщо ви не хочете запускати тести паралельно або якщо ви хочете більш детального
контролю над кількістю потоків, що використовуються, ви можете передати прапорець --test-threads
і кількість потоків, яку ви хочете використовувати, тестовому двійковому файлу. Подивіться на
наступний приклад:
$ cargo test -- --test-threads=1
Ми встановлюємо кількість тестових потоків на 1, кажучи програмі не використовувати ніякої
паралельності. Запуск тестів з використанням одного потоку займе більше часу, ніж запуск
їх паралельно, але тести не заважатимуть один одному, якщо вони мають спільний
стан.
Показ виведення функції
За замовчуванням, якщо тест успішний, тестова бібліотека Rust перехоплює все, що надруковано до
стандартного виведення. Наприклад, якщо ми викликаємо println! у тесті і тест
успішний, ми не побачимо виведення println! у терміналі; ми побачимо лише
рядок, який вказує, що тест успішний. Якщо тест завершується помилкою, ми побачимо все, що було
надруковано до стандартного виведення, разом з рештою повідомлення про помилку.
Як приклад, Listing 11-10 має безглузду функцію, яка друкує значення свого параметра і повертає 10, а також тест, який успішний, і тест, який завершується помилкою.
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(value, 10);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(value, 5);
}
}Коли ми запускаємо ці тести за допомогою cargo test, ми побачимо таке виведення:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Зверніть увагу, що ніде в цьому виведенні ми не бачимо I got the value 4, яке
друкується, коли запускається тест, що успішний. Це виведення було перехоплено. Виведення
від тесту, який завершився помилкою, I got the value 8, з’являється в розділі
підсумкового виведення тестів, який також показує причину невдачі тесту.
Якщо ми хочемо бачити надруковані значення також і для успішних тестів, ми можемо сказати Rust
також показувати виведення успішних тестів за допомогою --show-output:
$ cargo test -- --show-output
Коли ми знову запускаємо тести в Listing 11-10 з прапорцем --show-output, ми
бачимо таке виведення:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Запуск підмножини тестів за назвою
Запуск повного набору тестів іноді може займати багато часу. Якщо ви працюєте над
кодом у певній області, ви можете захотіти запускати лише тести, що стосуються
цього коду. Ви можете вибрати, які тести запускати, передавши cargo test назву
або назви тесту(ів), які ви хочете запустити, як аргумент.
Щоб продемонструвати, як запускати підмножину тестів, спочатку ми створимо три тести для
нашої функції add_two, як показано в Listing 11-11, і виберемо, які з них запускати.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
#[test]
fn add_three_and_two() {
let result = add_two(3);
assert_eq!(result, 5);
}
#[test]
fn one_hundred() {
let result = add_two(100);
assert_eq!(result, 102);
}
}Якщо ми запускаємо тести без передавання будь-яких аргументів, як ми бачили раніше, усі тести будуть запускатися паралельно:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Запуск окремих тестів
Ми можемо передати назву будь-якої тестової функції до cargo test, щоб запустити лише цей тест:
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Запустився лише тест із назвою one_hundred; інші два тести не відповідали
цій назві. Виведення тестів дає нам знати, що в нас було більше тестів, які не запускалися,
показуючи 2 filtered out наприкінці.
Ми не можемо вказати назви кількох тестів таким чином; буде використано лише перше значення,
надане cargo test. Але є спосіб запускати кілька тестів.
Фільтрація для запуску кількох тестів
Ми можемо вказати частину назви тесту, і буде запущено будь-який тест, назва якого відповідає цьому значенню.
Наприклад, оскільки назви двох наших тестів містять add, ми можемо
запустити ці два, виконавши cargo test add:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Ця команда запустила всі тести з add у назві і відфільтрувала тест,
названий one_hundred. Також зверніть увагу, що модуль, у якому з’являється тест, стає
частиною назви тесту, тож ми можемо запустити всі тести в модулі, відфільтрувавши
за назвою модуля.
Ігнорування тестів, якщо їх явно не запрошено
Іноді виконання кількох конкретних тестів може займати дуже багато часу, тож ви
можете захотіти виключити їх під час більшості запусків cargo test. Замість того щоб
перелічувати як аргументи всі тести, які ви хочете запускати, ви можете натомість анотувати
довготривалі тести, використовуючи атрибут ignore, щоб виключити їх, як показано
тут:
Filename: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}
}Після #[test] ми додаємо рядок #[ignore] до тесту, який хочемо виключити.
Тепер, коли ми запускаємо наші тести, it_works запускається, але expensive_test — ні:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::expensive_test ... ignored
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Функція expensive_test перерахована як ignored. Якщо ми хочемо запускати лише
ігноровані тести, ми можемо використати cargo test -- --ignored:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Керуючи тим, які тести запускаються, ви можете переконатися, що результати вашого cargo test
повертатимуться швидко. Коли ви дійдете до моменту, коли має сенс перевірити
результати ignored тестів і у вас є час чекати на результати,
ви можете натомість запустити cargo test -- --ignored. Якщо ви хочете запустити всі тести
незалежно від того, чи вони ігноровані, ви можете запустити cargo test -- --include-ignored.
Організація тестів
Організація тестів
Як згадувалося на початку розділу, тестування є складною дисципліною, і різні люди використовують різну термінологію та організацію. Спільнота Rust розглядає тести в термінах двох основних категорій: модульні тести (unit tests) та інтеграційні тести (integration tests). Модульні тести (unit tests) є невеликими та більш сфокусованими, тестують один модуль ізоляційно за раз і можуть тестувати приватні інтерфейси. Інтеграційні тести (integration tests) є повністю зовнішніми щодо вашої бібліотеки та використовують ваш код так само, як будь-який інший зовнішній код, використовуючи лише публічний інтерфейс і потенційно задіюючи кілька модулів на один тест.
Написання обох видів тестів важливе, щоб переконатися, що частини вашої бібліотеки роблять те, чого ви від них очікуєте, окремо і разом.
Модульні тести (Unit Tests)
Мета модульних тестів (unit tests) полягає в тому, щоб тестувати кожну одиницю коду ізоляційно від
решти коду, щоб швидко визначити, де код працює, а де — ні, як очікується.
Ви розміщуватимете модульні тести (unit tests) у каталозі src у кожному файлі з
кодом, який вони тестують. Зазвичай створюють модуль із назвою tests
у кожному файлі, щоб містити функції тестів, і позначають модуль
cfg(test).
Модуль tests і #[cfg(test)]
Анотація #[cfg(test)] на модулі tests каже Rust компілювати й
запускати код тестів лише коли ви запускаєте cargo test, а не коли ви
запускаєте cargo build. Це заощаджує час компіляції, коли ви лише хочете зібрати
бібліотеку, і заощаджує місце в результативному скомпільованому артефакті,
оскільки тести не включаються. Ви побачите, що оскільки інтеграційні тести (integration tests)
розміщуються в іншому каталозі, їм не потрібна анотація #[cfg(test)].
Однак, оскільки модульні тести (unit tests) перебувають у тих самих файлах, що й код, ви
використовуватимете #[cfg(test)], щоб указати, що їх не слід включати
до скомпільованого результату.
Згадайте, що коли ми згенерували новий проєкт adder у першому розділі
цього розділу, Cargo згенерував для нас цей код:
Filename: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}У автоматично згенерованому модулі tests атрибут cfg означає
configuration і каже Rust, що наступний елемент слід включати
лише за наявності певної опції конфігурації. У цьому випадку опція конфігурації —
test, яку Rust надає для компіляції та запуску тестів. Використовуючи
атрибут cfg, Cargo компілює наш код тестів лише якщо ми активно запускаємо тести
за допомогою cargo test. Це включає будь-які допоміжні функції, які можуть
бути в цьому модулі, на додаток до функцій, позначених #[test].
Тести приватних функцій
У спільноті тестування точаться суперечки про те, чи слід тестувати приватні
функції безпосередньо, і в інших мовах це робить тестування приватних функцій
складним або неможливим. Незалежно від того, якої ідеології тестування ви
дотримуєтеся, правила приватності Rust дозволяють вам тестувати приватні функції.
Розгляньте код у Listing 11-12 із приватною функцією internal_adder.
pub fn add_two(a: u64) -> u64 {
internal_adder(a, 2)
}
fn internal_adder(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
let result = internal_adder(2, 2);
assert_eq!(result, 4);
}
}Зверніть увагу, що функцію internal_adder не позначено як pub. Тести — це просто
код Rust, а модуль tests — це просто ще один модуль. Як ми обговорювали в
“Шляхи для звернення до елемента в дереві модулів”,
елементи в дочірніх модулях можуть використовувати елементи в їхніх предківських модулях. У
цьому тесті ми вводимо всі елементи, що належать предківському модулю модуля tests,
у область видимості за допомогою use super::*, а потім тест може викликати internal_adder.
Якщо ви не вважаєте, що приватні функції слід тестувати, у Rust немає нічого,
що змусило б вас це робити.
Інтеграційні тести (Integration Tests)
У Rust integration tests є повністю зовнішніми щодо вашої бібліотеки. Вони використовують вашу бібліотеку так само, як це робив би будь-який інший код, а це означає, що вони можуть викликати лише функції, які є частиною публічного API вашої бібліотеки. Їхня мета — перевірити, чи багато частин вашої бібліотеки працюють разом коректно. Одиниці коду, які працюють коректно самі по собі, можуть мати проблеми під час інтеграції, тому покриття інтегрованого коду тестами також важливе. Щоб створити інтеграційні тести (integration tests), спочатку вам потрібен каталог tests.
Каталог tests
Ми створюємо каталог tests на верхньому рівні каталогу нашого проєкту, поруч із src. Cargo знає, що слід шукати файли інтеграційних тестів (integration test) у цьому каталозі. Потім ми можемо створити стільки файлів тестів, скільки хочемо, а Cargo компілюватиме кожен із файлів як окремий крейт (crate).
Давайте створимо інтеграційний тест (integration test). Якщо код у Listing 11-12 досі знаходиться у файлі src/lib.rs, створіть каталог tests і створіть новий файл із назвою tests/integration_test.rs. Структура вашого каталогу має виглядати так:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
Введіть код із Listing 11-13 у файл tests/integration_test.rs.
use adder::add_two;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}Кожен файл у каталозі tests є окремим крейтом (crate), тому нам потрібно ввести нашу
бібліотеку в область видимості кожного тестового крейта (test crate). З цієї причини ми додаємо use adder::add_two; на початку коду, чого нам не потрібно було робити в модульних тестах (unit tests).
Нам не потрібно позначати будь-який код у tests/integration_test.rs як
#[cfg(test)]. Cargo особливо обробляє каталог tests і компілює файли
в цьому каталозі лише коли ми запускаємо cargo test. Запустіть cargo test зараз:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Три секції виводу включають модульні тести (unit tests), інтеграційні тести (integration test) і doc tests. Зверніть увагу, що якщо будь-який тест у секції завершується невдачею, наступні секції не будуть запущені. Наприклад, якщо модульний тест (unit test) завершується невдачею, не буде жодного виводу для інтеграційних (integration) і doc tests, тому що ці тести будуть запущені лише якщо всі модульні тести (unit tests) успішно проходять.
Перша секція для модульних тестів (unit tests) така сама, як ми вже бачили: один рядок
для кожного модульного тесту (unit test) (один із назвою internal, який ми додали в Listing 11-12),
а потім підсумковий рядок для модульних тестів (unit tests).
Секція інтеграційних тестів (integration tests) починається з рядка Running tests/integration_test.rs. Далі є рядок для кожної функції тесту в
цьому інтеграційному тесті (integration test) і підсумковий рядок для результатів інтеграційного тесту (integration test)
безпосередньо перед початком секції Doc-tests adder.
Кожен файл інтеграційного тесту (integration test) має власну секцію, тож якщо ми додамо більше файлів у каталог tests, буде більше секцій інтеграційних тестів (integration test).
Ми й надалі можемо запускати певну функцію інтеграційного тесту (integration test), указавши
назву функції тесту як аргумент до cargo test. Щоб запустити всі тести в
певному файлі інтеграційного тесту (integration test), використовуйте аргумент --test команди cargo test
після назви файлу:
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ця команда запускає лише тести у файлі tests/integration_test.rs.
Підмодулі в integration tests
У міру додавання більшої кількості інтеграційних тестів (integration tests), ви можете захотіти створити більше файлів у каталозі tests, щоб допомогти їх організувати; наприклад, ви можете групувати функції тестів за функціональністю, яку вони тестують. Як згадувалося раніше, кожен файл у каталозі tests компілюється як власний окремий крейт (crate), що корисно для створення окремих областей видимості, щоб точніше імітувати спосіб, у який кінцеві користувачі використовуватимуть ваш крейт (crate). Однак це означає, що файли у каталозі tests не розділяють ту саму поведінку, що й файли у src, як ви дізналися в Розділі 7 щодо того, як розділяти код на модулі та файли.
Різна поведінка файлів каталогу tests найбільш помітна, коли у вас є набір
допоміжних функцій для використання в кількох файлах інтеграційних тестів (integration test), і
ви намагаєтеся дотримуватися кроків у розділі “Separating Modules into Different
Files” Розділу 7, щоб
винести їх у спільний модуль. Наприклад, якщо ми створимо tests/common.rs
і розмістимо в ньому функцію з назвою setup, ми можемо додати до setup код,
який хочемо викликати з кількох функцій тестів у кількох файлах тестів:
Filename: tests/common.rs
pub fn setup() {
// setup code specific to your library's tests would go here
}Коли ми знову запустимо тести, ми побачимо нову секцію у виводі тестів для
файлу common.rs, хоча цей файл не містить жодних функцій тестів і ми
не викликали функцію setup звідки-небудь:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Те, що common з’являється в результатах тестів із running 0 tests,
не є тим, чого ми хотіли. Ми просто хотіли поділитися деяким кодом з іншими
файлами integration test. Щоб уникнути появи common у виводі тестів,
замість створення tests/common.rs ми створимо tests/common/mod.rs. Тепер
структура каталогу проєкту виглядає так:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
Це старіша угода про іменування, яку Rust також розуміє, про яку ми згадували
в розділі “Alternate File Paths” у Розділі 7. Називання
файлу таким чином каже Rust не розглядати модуль common як файл інтеграційного тесту (integration test).
Коли ми переносимо код функції setup у tests/common/mod.rs і
видаляємо файл tests/common.rs, секція у виводі тестів більше
не з’являтиметься. Файли в підкаталогах каталогу tests не компілюються як
окремі крейти (crates) і не мають секцій у виводі тестів.
Після того як ми створили tests/common/mod.rs, ми можемо використовувати його з будь-якого
файлу інтеграційного тесту (integration test) як модуль. Ось приклад виклику функції setup
із тесту it_adds_two у tests/integration_test.rs:
Filename: tests/integration_test.rs
use adder::add_two;
mod common;
#[test]
fn it_adds_two() {
common::setup();
let result = add_two(2);
assert_eq!(result, 4);
}Зверніть увагу, що оголошення mod common; є таким самим, як оголошення модуля,
яке ми демонстрували в Listing 7-21. Потім у функції тесту ми можемо викликати
функцію common::setup().
Інтеграційні тести (Integration Tests) для бінарного крейта (binary crate)
Якщо наш проєкт є бінарним крейтом (binary crate), який містить лише файл src/main.rs і
не має файлу src/lib.rs, ми не можемо створити інтеграційні тести (integration tests) у каталозі
tests і ввести функції, визначені у файлі src/main.rs, в область видимості
за допомогою оператора use. Лише бібліотечні крейти (library crates) експонують функції, які інші
крейти (crates) можуть використовувати; бінарні крейти (binary crates) призначені для запуску самостійно.
Це одна з причин, чому проєкти Rust, які надають binary, мають
простий файл src/main.rs який викликає логіку, що живе у файлі
src/lib.rs. Використовуючи таку структуру, інтеграційні тести (integration tests) можуть
тестувати бібліотечний крейт (library crate) за допомогою use, щоб зробити важливу функціональність
доступною. Якщо важлива функціональність працює, невеликий обсяг коду у файлі
src/main.rs також працюватиме, і цей невеликий обсяг коду не потрібно
тестувати.
Підсумок
Можливості тестування Rust надають спосіб указати, як код має функціонувати, щоб гарантувати, що він продовжує працювати так, як ви очікуєте, навіть коли ви вносите зміни. Модульні тести (unit tests) окремо перевіряють різні частини бібліотеки і можуть тестувати приватні деталі реалізації. Інтеграційні тести (integration tests) перевіряють, що багато частин бібліотеки працюють разом коректно, і вони використовують публічний API бібліотеки, щоб тестувати код так само, як зовнішній код використовуватиме його. Хоча система типів Rust і правила власності допомагають запобігати деяким видам помилок, тести все ще важливі, щоб зменшити логічні помилки, пов’язані з тим, як ваш код має поводитися.
Давайте поєднаємо знання, які ви отримали в цьому розділі та в попередніх розділах, щоб попрацювати над проєктом!
Проєкт I/O: Створення програми командного рядка
Цей розділ — це підсумок багатьох навичок, які ви опанували досі, і дослідження ще кількох можливостей стандартної бібліотеки. Ми побудуємо інструмент командного рядка , що взаємодіє з введенням/виведенням файлів і командного рядка, щоб попрактикуватися в деяких із концепцій Rust, які ви тепер маєте у своєму арсеналі.
Швидкість Rust, безпека, вихід одного бінарного файлу та підтримка кросплатформенності роблять його
ідеальною мовою для створення інструментів командного рядка, тож для нашого проєкту ми
зробимо власну версію класичного інструмента пошуку командного рядка grep
(globally search a regular expression and print). У
найпростішому випадку використання grep шукає вказаний файл за вказаним рядком. Щоб
зробити це, grep бере як свої аргументи шлях до файлу та рядок. Потім він читає
файл, знаходить у ньому рядки, що містять аргумент-рядок, і виводить
ці рядки.
У процесі ми покажемо, як змусити наш інструмент командного рядка використовувати можливості термінала,
які використовують багато інших інструментів командного рядка. Ми прочитаємо значення змінної середовища,
щоб дозволити користувачу налаштувати поведінку нашого інструмента.
Ми також виводитимемо повідомлення про помилки до стандартного потоку консолі помилок (stderr)
замість стандартного виведення (stdout), щоб, наприклад, користувач міг
перенаправити успішний вивід до файлу, водночас бачачи повідомлення про помилки на екрані.
Один член спільноти Rust, Andrew Gallant, уже створив повнофункціональну,
дуже швидку версію grep, яка називається ripgrep. Для порівняння, наша
версія буде досить простою, але цей розділ дасть вам деякі
знання про контекст, які потрібні, щоб зрозуміти реальний проєкт, такий як
ripgrep.
Наш проєкт grep поєднає низку концепцій, які ви вже опанували:
- Організація коду (Розділ 7)
- Використання векторів і рядків (Розділ 8)
- Обробка помилок (Розділ 9)
- Використання трейтів і часів життя там, де це доречно (Розділ 10)
- Написання тестів (Розділ 11)
Ми також коротко представимо замикання, ітератори та трейт-об’єкти, які Розділ 13 і Розділ 18 розглянуть детально.
Приймання аргументів командного рядка
Прийняття аргументів командного рядка
Давайте створимо новий пакет за допомогою, як завжди, cargo new. Назвемо наш пакет
minigrep, щоб відрізнити його від інструмента grep, який, можливо, уже є
у вашій системі:
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
Перше завдання — змусити minigrep приймати свої два аргументи командного рядка: шлях
до файлу і рядок для пошуку. Тобто ми хочемо мати змогу запускати нашу
програму за допомогою cargo run, двох дефісів, щоб позначити, що наступні аргументи
призначені для нашої програми, а не для cargo, рядка для пошуку і шляху до
файлу, в якому виконувати пошук, ось так:
$ cargo run -- searchstring example-filename.txt
Наразі програма, згенерована cargo new, не може обробляти аргументи, які ми
їй передаємо. Деякі наявні бібліотеки на Crates.io можуть допомогти
з написанням програми, що приймає аргументи командного рядка, але оскільки ви
лише вивчаєте цю концепцію, давайте реалізуємо цю можливість самостійно.
Читання значень аргументів
Щоб minigrep міг читати значення аргументів командного рядка, які ми передаємо
йому, нам знадобиться функція std::env::args, надана в стандартній
бібліотеці Rust. Ця функція повертає ітератор аргументів командного рядка, переданих
minigrep. Ми повністю розглянемо ітератори в Розділі 13. Наразі вам потрібно знати лише дві деталі про ітератори: ітератори
створюють послідовність значень, і ми можемо викликати метод collect на ітераторі,
щоб перетворити його на колекцію, таку як вектор, яка містить усі елементи,
що їх створює ітератор.
Код у Переліку 12-1 дає змогу вашій програмі minigrep читати будь-які аргументи
командного рядка, передані їй, а потім збирати значення у вектор.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
dbg!(args);
}Спочатку ми вводимо модуль std::env в область видимості за допомогою оператора use, щоб
ми могли використовувати його функцію args. Зверніть увагу, що функція std::env::args
вкладена на два рівні модулів. Як ми обговорювали в Розділі
7, у випадках, коли потрібна функція
вкладена більш ніж в одному модулі, ми вирішили вводити в область видимості батьківський модуль,
а не саму функцію. Роблячи так, ми можемо легко використовувати інші функції
з std::env. Це також менш неоднозначно, ніж додати use std::env::args, а
потім викликати функцію просто як args, тому що args легко можна
помилково сплутати з функцією, визначеною в поточному модулі.
Функція
argsі неприпустимий UnicodeЗверніть увагу, що
std::env::argsпризведе до паніки, якщо будь-який аргумент містить неприпустимий Unicode. Якщо ваша програма повинна приймати аргументи, що містять неприпустимий Unicode, натомість використовуйтеstd::env::args_os. Ця функція повертає ітератор, який створює значенняOsStringзамість значеньString. Ми вирішили використовувати тутstd::env::argsдля простоти, оскільки значенняOsStringвідрізняються залежно від платформи і є складнішими у використанні, ніж значенняString.
У першому рядку main ми викликаємо env::args, і одразу використовуємо
collect, щоб перетворити ітератор на вектор, що містить усі значення, створені
ітератором. Ми можемо використовувати функцію collect для створення багатьох видів
колекцій, тому ми явно вказуємо тип args, щоб зазначити, що
ми хочемо вектор рядків. Хоча вам дуже рідко потрібно вказувати типи в
Rust, collect — це одна з функцій, для якої вам часто потрібно вказувати тип, тому що Rust
не може вивести, який саме тип колекції ви хочете.
Нарешті, ми виводимо вектор за допомогою макроса налагодження. Давайте спробуємо запустити код спочатку без аргументів, а потім із двома аргументами:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
Зверніть увагу, що перше значення у векторі — "target/debug/minigrep", яке є
назвою нашого бінарного файлу. Це відповідає поведінці списку аргументів у C, даючи програмам
використовувати назву, під якою їх було викликано під час виконання.
Часто зручно мати доступ до назви програми, якщо ви хочете
виводити її в повідомленнях або змінювати поведінку програми залежно від того,
який псевдонім командного рядка було використано для виклику програми. Але для цілей цієї
глави ми проігноруємо це і збережемо лише два потрібні нам аргументи.
Збереження значень аргументів у змінних
Наразі програма може отримувати доступ до значень, заданих як аргументи командного рядка. Тепер нам потрібно зберегти значення двох аргументів у змінних, щоб ми могли використовувати ці значення в решті програми. Ми робимо це в Переліку 12-2.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
}Як ми бачили, коли виводили вектор, назва програми займає перше
значення у векторі в args[0], тому ми починаємо аргументи з індексу 1. Перший
аргумент, який приймає minigrep, — це рядок, який ми шукаємо, тому ми поміщаємо
посилання на перший аргумент у змінну query. Другий аргумент
буде шляхом до файлу, тому ми поміщаємо посилання на другий аргумент у
змінну file_path.
Ми тимчасово виводимо значення цих змінних, щоб довести, що код
працює так, як ми задумали. Давайте запустимо цю програму знову з аргументами test
і sample.txt:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
Чудово, програма працює! Значення аргументів, які нам потрібні, зберігаються у правильних змінних. Пізніше ми додамо обробку помилок, щоб впоратися з певними потенційно помилковими ситуаціями, наприклад, коли користувач не надає аргументів; наразі ми проігноруємо цю ситуацію і замість цього попрацюємо над додаванням можливостей читання файлів.
Читання файлу
Читання файлу
Тепер ми додамо функціональність для читання файлу, вказаного в аргументі file_path. Спочатку нам потрібен зразок файлу, щоб протестувати це: ми використаємо файл з невеликою кількістю тексту в кількох рядках із деякими повторюваними словами. У Listing 12-3 є вірш Emily Dickinson, який добре підійде! Створіть файл під назвою poem.txt на кореневому рівні вашого проєкту і введіть вірш “I’m Nobody! Who are you?”
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Коли текст уже на місці, відредагуйте src/main.rs і додайте код для читання файлу, як показано в Listing 12-4.
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}Спочатку ми підключаємо відповідну частину стандартної бібліотеки за допомогою оператора use: нам потрібен std::fs для роботи з файлами.
У main новий оператор fs::read_to_string бере file_path, відкриває цей файл і повертає значення типу std::io::Result<String>, яке містить вміст файлу.
Після цього ми знову додаємо тимчасовий оператор println!, який друкує значення contents після прочитання файлу, щоб ми могли перевірити, що програма поки що працює.
Давайте запустимо цей код з будь-яким рядком як першим аргументом командного рядка (бо ми ще не реалізували частину пошуку) і файлом poem.txt як другим аргументом:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Чудово! Код прочитав і потім надрукував вміст файлу. Але в коді є кілька вад. Наразі функція main має кілька обов’язків: загалом функції зрозуміліші та їх легше підтримувати, якщо кожна функція відповідає лише за одну ідею. Інша проблема полягає в тому, що ми не обробляємо помилки так добре, як могли б. Програма все ще невелика, тож ці вади не є великою проблемою, але в міру зростання програми їх буде важче акуратно виправляти. Це хороша практика — починати рефакторинг на ранньому етапі під час розробки програми, тому що рефакторити менші обсяги коду набагато легше. Далі ми це зробимо.
Рефакторинг для покращення модульності та обробки помилок
Рефакторинг для покращення модульності та обробки помилок
Щоб покращити нашу програму, ми виправимо чотири проблеми, які стосуються
структури програми та того, як вона обробляє можливі помилки. По-перше, наша
функція main тепер виконує дві задачі: вона розбирає аргументи та читає
файли. У міру того як наша програма зростатиме, кількість окремих задач, які
обробляє функція main, збільшуватиметься. Коли функція набуває більше
обов’язків, її стає важче осмислювати, важче тестувати і важче змінювати, не
зламавши одну з її частин. Найкраще розділяти функціональність так, щоб кожна
функція відповідала за одну задачу.
Ця проблема також пов’язана з другою проблемою: хоча query і file_path
є змінними конфігурації нашої програми, такі змінні, як contents,
використовуються для виконання логіки програми. Чим довшою стає main, тим
більше змінних нам потрібно буде вводити в область видимості; чим більше
змінних у нашій області видимості, тим важче буде відстежувати призначення
кожної. Найкраще згрупувати змінні конфігурації в одну структуру, щоб зробити
їхнє призначення зрозумілим.
Третя проблема полягає в тому, що ми використали expect, щоб вивести
повідомлення про помилку, коли читання файлу завершується невдачею, але
повідомлення про помилку просто виводить Should have been able to read the file. Читання файлу може завершитися невдачею з кількох причин: наприклад,
файл може бути відсутнім, або в нас може не бути дозволу на його відкриття.
Зараз, незалежно від ситуації, ми б виводили одне й те саме повідомлення про
помилку для всього, що не дало б користувачеві жодної інформації!
По-четверте, ми використовуємо expect для обробки помилки, і якщо користувач
запустить нашу програму, не вказавши достатньо аргументів, він отримає помилку
index out of bounds від Rust, яка не пояснює проблему зрозуміло. Було б
найкраще, якби весь код обробки помилок був в одному місці, щоб майбутнім
підтримувачам доводилося звертатися лише до одного місця в коді, якщо логіку
обробки помилок потрібно буде змінити. Наявність усього коду обробки помилок в
одному місці також гарантуватиме, що ми виводимо повідомлення, які будуть
зрозумілими для наших кінцевих користувачів.
Давайте розв’яжемо ці чотири проблеми, відрефакторивши наш проєкт.
Розділення відповідальностей у бінарних (binary) проєктах
Організаційна проблема розподілу відповідальності за кілька задач між функцією
main є поширеною для багатьох бінарних (binary) проєктів. У результаті багато
програмістів Rust вважають корисним розділяти окремі відповідальності
бінарної (binary) програми, коли функція main починає ставати великою. Цей процес має
такі кроки:
- Розбийте вашу програму на файл main.rs і файл lib.rs та перенесіть логіку вашої програми до lib.rs.
- Поки ваша логіка розбору командного рядка невелика, вона може залишатися у
функції
main. - Коли логіка розбору командного рядка починає ускладнюватися, виділіть її з
функції
mainв інші функції або типи.
Обов’язки, які залишаються у функції main після цього процесу, мають бути
обмежені такими:
- Виклик логіки розбору командного рядка з переданими значеннями аргументів
- Налаштування будь-якої іншої конфігурації
- Виклик функції
runу lib.rs - Обробка помилки, якщо
runповертає помилку
Цей шаблон стосується розділення відповідальностей: main.rs обробляє запуск
програми, а lib.rs обробляє всю логіку поточної задачі. Оскільки ви не
можете напряму тестувати функцію main, ця структура дає змогу вам тестувати
всю логіку вашої програми, виносячи її з функції main. Код, який залишиться у
функції main, буде достатньо малим, щоб перевірити його правильність,
прочитавши його. Давайте переробимо нашу програму, дотримуючись цього процесу.
Вилучення розбору аргументів
Ми вилучимо функціональність розбору аргументів у функцію, яку викликатиме
main. Список (Listing) 12-5 показує новий початок функції main, яка викликає нову
функцію parse_config, яку ми визначимо в src/main.rs.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}Ми все ще збираємо аргументи командного рядка у вектор, але замість того, щоб
присвоювати значення аргументу з індексом 1 змінній query і значення аргументу
з індексом 2 змінній file_path у функції main, ми передаємо весь вектор у
функцію parse_config. Потім функція parse_config містить логіку, яка
визначає, який аргумент у яку змінну потрапляє, і повертає значення назад до
main. Ми все ще створюємо змінні query і file_path у main, але main
більше не має відповідальності за визначення того, як співвідносяться аргументи
командного рядка та змінні.
Ця переробка може здатися надмірною для нашої малої програми, але ми рефакторимо малими, поступовими кроками. Після внесення цієї зміни запустіть програму знову, щоб перевірити, що розбір аргументів усе ще працює. Добре часто перевіряти свій прогрес, щоб допомогти визначити причину проблем, коли вони виникають.
Групування значень конфігурації
Ми можемо зробити ще один маленький крок, щоб далі покращити функцію
parse_config. На цей момент ми повертаємо кортеж, але потім одразу знову
розбиваємо цей кортеж на окремі частини. Це ознака того, що, можливо, у нас
ще немає правильної абстракції.
Інший показник, який свідчить, що є простір для покращення, — це частина
config у parse_config, яка припускає, що два значення, які ми повертаємо,
пов’язані між собою і є частиною одного значення конфігурації. Наразі ми не
передаємо це значення у структурі даних, окрім як групуючи два значення в
кортеж; натомість ми помістимо два значення в одну структуру і дамо кожному
полю структури змістовну назву. Це полегшить майбутнім підтримувачам цього
коду розуміння того, як різні значення пов’язані одне з одним і яке їхнє
призначення.
Список(Listing) 12-6 показує покращення функції parse_config.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}Ми додали структуру під назвою Config, визначену так, щоб мати поля з
назвами query і file_path. Підпис parse_config тепер вказує, що вона
повертає значення Config. У тілі parse_config, де ми раніше повертали
рядкові зрізи, які посилаються на значення String у args, тепер ми
визначаємо Config як такий, що містить власні значення String. Змінна
args у main є власником значень аргументів і лише дозволяє функції
parse_config запозичити їх, що означає, що ми порушили б правила запозичення
Rust, якби Config спробував узяти власність над значеннями в args.
Є кілька способів, якими ми могли б керувати даними String; найпростіший,
хоча й дещо неефективний, шлях — викликати метод clone для значень. Це
створить повну копію даних, якою володітиме екземпляр Config, що потребує
більше часу та пам’яті, ніж зберігання посилання на дані рядка. Однак
клонування даних також робить наш код дуже прямолінійним, оскільки нам не
потрібно керувати часами життя посилань; за цих обставин пожертвувати трохи
продуктивності заради простоти є виправданим компромісом.
Компроміси використання
cloneСеред багатьох растацеанців (Rustaceans) є тенденція уникати використання
cloneдля виправлення проблем із власністю через його вартість під час виконання. У Розділі 13 ви дізнаєтеся, як використовувати більш ефективні методи в такому типі ситуації. Але поки що нормально копіювати кілька рядків, щоб продовжувати рухатися вперед, тому що ви зробите ці копії лише один раз, а ваш шлях до файлу та рядок запиту дуже малі. Краще мати робочу програму, яка є трохи неефективною, ніж намагатися гіпероптимізувати код із першої спроби. Коли ви станете досвідченішими в Rust, буде легше починати з найефективнішого рішення, але поки що цілком прийнятно викликатиclone.
Ми оновили main так, що тепер він поміщає екземпляр Config, повернений
parse_config, у змінну з назвою config, і ми оновили код, який раніше
використовував окремі змінні query і file_path, так що тепер він
використовує поля структури Config.
Тепер наш код чіткіше передає, що query і file_path пов’язані та що їхнє
призначення — налаштовувати, як працюватиме програма. Будь-який код, який
використовує ці значення, знає, що слід шукати їх в екземплярі config у
полях, названих за їхнім призначенням.
Створення конструктора для Config
Дотепер ми вилучили логіку, відповідальну за розбір аргументів командного
рядка, з main і помістили її у функцію parse_config. Це допомогло нам
побачити, що значення query і file_path були пов’язані, і цей зв’язок
слід передати в нашому коді. Потім ми додали структуру Config, щоб назвати
пов’язане призначення query і file_path і мати можливість повертати
назви значень як назви полів структури з функції parse_config.
Отже, тепер, коли призначення функції parse_config — створювати екземпляр
Config, ми можемо змінити parse_config із простої функції на функцію з
назвою new, яка пов’язана зі структурою Config. Внесення цієї зміни
зробить код більш ідіоматичним. Ми можемо створювати екземпляри типів у
стандартній бібліотеці, таких як String, викликаючи String::new.
Аналогічно, змінивши parse_config на функцію new, пов’язану з Config, ми
зможемо створювати екземпляри Config, викликаючи Config::new. Список (Listing) 12-7
показує зміни, які нам потрібно внести.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}Ми оновили main, де викликали parse_config, так що тепер він викликає
Config::new. Ми змінили назву parse_config на new і перенесли її всередину
блоку impl, який пов’язує функцію new з Config. Спробуйте знову
скомпілювати цей код, щоб переконатися, що він працює.
Виправлення обробки помилок
Тепер ми попрацюємо над виправленням обробки помилок. Згадайте, що спроба
звернутися до значень у векторі args за індексом 1 або індексом 2 призведе
до паніки програми, якщо вектор містить менше ніж три елементи. Спробуйте
запустити програму без будь-яких аргументів; це виглядатиме так:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Рядок index out of bounds: the len is 1 but the index is 1 — це повідомлення
про помилку, призначене для програмістів. Воно не допоможе нашим кінцевим
користувачам зрозуміти, що їм слід зробити натомість. Давайте виправимо це
зараз.
Покращення повідомлення про помилку
У списку (Listing) 12-8 ми додаємо перевірку у функцію new, яка перевірятиме, що
зріз (slice) досить довгий, перш ніж звертатися до індексу 1 та індексу 2. Якщо
зріз недостатньо довгий, програма панікує та відображає краще повідомлення про
помилку.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}Цей код подібний до функції Guess::new, яку ми написали в списку 9-13, де ми викликали panic!, коли аргумент
value виходив за межі допустимих значень. Замість перевірки діапазону значень
тут ми перевіряємо, що довжина args становить принаймні 3, і решта функції
може працювати, припускаючи, що ця умова виконана. Якщо args має менше ніж
три елементи, ця умова буде true, і ми викликаємо макрос panic!, щоб
негайно завершити програму.
З цими кількома додатковими рядками коду в new давайте знову запустимо
програму без жодних аргументів, щоб побачити, як тепер виглядає помилка:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
not enough arguments
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Цей вивід кращий: тепер у нас є розумне повідомлення про помилку. Однак у нас
також є зайва інформація, яку ми не хочемо показувати нашим користувачам.
Можливо, техніка, яку ми використали в списку (Listing) 9-13, не є найкращою для цього
випадку: виклик panic! більше підходить для проблеми програмування, ніж для
проблеми використання, як обговорювалося в Розділі 9. Натомість ми використаємо іншу техніку, про
яку ви дізналися в Розділі 9 — повернення Result,
що вказує або на успіх, або на помилку.
Повернення Result замість виклику panic!
Натомість ми можемо повертати значення Result, яке міститиме екземпляр
Config у випадку успіху та описуватиме проблему у випадку помилки. Ми також
збираємося змінити назву функції з new на build, тому що багато
програмістів очікують, що функції new ніколи не зазнають невдачі. Коли
Config::build передає інформацію до main, ми можемо використовувати тип
Result, щоб сигналізувати, що виникла проблема. Потім ми можемо змінити
main, щоб перетворювати варіант Err на більш практичну помилку для наших
користувачів без навколишнього тексту про thread 'main' і RUST_BACKTRACE,
який спричиняє виклик panic!.
Список (Listing) 12-9 показує зміни, які нам потрібно внести в значення, що
повертається, функції, яку ми тепер називаємо Config::build, і в тіло
функції, потрібне для повернення Result. Зверніть увагу, що це не
скомпілюється, доки ми також не оновимо main, що ми зробимо в наступному
списку (Listing).
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Наша функція build повертає Result з екземпляром Config у випадку успіху
та рядковим літералом у випадку помилки. Наші значення помилок завжди будуть
рядковими літералами, які мають час життя 'static.
Ми внесли дві зміни в тіло функції: замість того, щоб викликати panic!, коли
користувач не передає достатньо аргументів, ми тепер повертаємо значення
Err, і ми обгорнули значення, що повертається Config, у Ok. Ці зміни
роблять функцію такою, що відповідає її новому підпису типу.
Повернення значення Err з Config::build дає змогу функції main
обробляти значення Result, повернуте з функції build, і завершувати процес
більш чисто у випадку помилки.
Виклик Config::build та обробка помилок
Щоб обробити випадок помилки та вивести зрозуміле для користувача повідомлення,
нам потрібно оновити main, щоб він обробляв Result, який повертає
Config::build, як показано в списку (Listing) 12-10. Ми також заберемо в panic!
відповідальність за завершення інструмента командного рядка з ненульовим кодом
помилки і натомість реалізуємо це вручну. Ненульовий статус виходу — це
домовленість, щоб сигналізувати процесу, який викликав нашу програму, що
програма завершилася зі станом помилки.
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}У цьому списку ми використали метод, який ще не розглядали детально:
unwrap_or_else, який визначений у Result<T, E> стандартною бібліотекою.
Використання unwrap_or_else дає нам змогу визначити власну обробку помилок
без panic!. Якщо Result є значенням Ok, поведінка цього методу подібна
до unwrap: він повертає внутрішнє значення, яке обгортає Ok. Однак якщо
значення є Err, цей метод викликає код у замиканні, яке є анонімною функцією,
що ми визначаємо і передаємо як аргумент unwrap_or_else. Ми детальніше
розглядатимемо замикання в Розділі 13. Поки що вам
потрібно лише знати, що unwrap_or_else передасть внутрішнє значення Err,
яким у цьому випадку є статичний рядок "not enough arguments", який ми
додали в списку (Listing) 12-9, нашому замиканню в аргументі err, що з’являється між
вертикальними рисками. Код у замиканні потім може використовувати значення
err, коли він виконується.
Ми додали новий рядок use, щоб ввести process зі стандартної бібліотеки в
область видимості. Код у замиканні, який буде виконано у випадку помилки,
складається лише з двох рядків: ми виводимо значення err, а потім викликаємо
process::exit. Функція process::exit негайно зупинить програму і поверне
число, яке було передано як код статусу виходу. Це подібно до обробки на
основі panic!, яку ми використали в списку (Listing) 12-8, але тепер ми більше не
отримуємо весь додатковий вивід. Спробуймо:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
Чудово! Цей вивід набагато зручніший для наших користувачів.
Вилучення логіки з main
Тепер, коли ми завершили рефакторинг розбору конфігурації, перейдемо до
логіки програми. Як ми зазначили в «Розділення відповідальностей у бінарних (binary) проєктах», ми
вилучимо функцію run, яка міститиме всю логіку, що зараз є у функції main
і не пов’язана з налаштуванням конфігурації чи обробкою помилок. Коли ми
закінчимо, функція main буде лаконічною і її буде легко перевірити візуально,
а для всієї іншої логіки ми зможемо написати тести.
Список (Listing) 12-11 показує невелике, поступове покращення шляхом вилучення функції
run.
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Тепер функція run містить усю решту логіки з main, починаючи з читання
файлу. Функція run приймає екземпляр Config як аргумент.
Повернення помилок з run
Після того як решту логіки програми відокремлено у функцію run, ми можемо
покращити обробку помилок, як ми це зробили з Config::build у списку(Listing) 12-9.
Замість того щоб дозволяти програмі панікувати шляхом виклику expect,
функція run повертатиме Result<T, E>, коли щось піде не так. Це дасть нам
змогу далі консолідувати логіку обробки помилок у main у зручний для
користувача спосіб. Список (Listing) 12-12 показує зміни, які нам потрібно внести в
підпис і тіло run.
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Ми внесли тут три суттєві зміни. По-перше, ми змінили тип повернення функції
run на Result<(), Box<dyn Error>>. Раніше ця функція повертала
unit-тип (), і ми зберігаємо його як значення, яке повертається у випадку
Ok.
Для типу помилки ми використали трейт-об’єкт Box<dyn Error> (і ми ввели
std::error::Error в область видимості за допомогою use на початку). Ми
розглядатимемо трейт-об’єкти в розділі 18. Поки що
достатньо знати, що Box<dyn Error> означає, що функція повертатиме тип, який
реалізує трейт Error, але нам не потрібно вказувати, який саме тип буде
повернене значення. Це дає нам гнучкість повертати значення помилок, які
можуть бути різних типів у різних випадках помилок. Ключове слово dyn є
скороченням від dynamic.
По-друге, ми вилучили виклик expect на користь оператора ?, як ми
обговорювали в розділі 9. Замість того щоб
викликати panic! при помилці, ? поверне значення помилки з поточної
функції, щоб викликач міг його обробити.
По-третє, функція run тепер повертає значення Ok у випадку успіху. Ми
оголосили успішний тип функції run як () у підписі, що означає, що нам
потрібно обгорнути значення unit-типу у значення Ok. Цей синтаксис
Ok(()) може спершу здаватися дещо дивним. Але використання () таким
чином — це ідіоматичний спосіб показати, що ми викликаємо run лише заради
її побічних ефектів; вона не повертає значення, яке нам потрібно.
Коли ви запустите цей код, він скомпілюється, але покаже попередження:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = run(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust повідомляє нам, що наш код проігнорував значення Result, і значення
Result може вказувати на те, що сталася помилка. Але ми не перевіряємо, чи
була помилка, і компілятор нагадує нам, що, ймовірно, ми мали тут якийсь код
обробки помилок! Давайте зараз виправимо цю проблему.
Обробка помилок, повернених з run, у main
Ми перевіримо наявність помилок і обробимо їх, використовуючи техніку, подібну
до тієї, яку ми використовували з Config::build у списку (Listing) 12-10, але з
невеликою різницею:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Ми використовуємо if let замість unwrap_or_else, щоб перевірити, чи
run повертає значення Err, і викликати process::exit(1), якщо так.
Функція run не повертає значення, яке ми хочемо unwrap так само, як
Config::build повертає екземпляр Config. Оскільки run повертає () у
випадку успіху, нас цікавить лише виявлення помилки, тож нам не потрібно,
щоб unwrap_or_else повертав розгорнуте значення, яким було б лише ().
Тіла if let і функції unwrap_or_else однакові в обох випадках: ми
виводимо помилку і завершуємо роботу.
Розбиття коду на бібліотечний крейт (library crate)
Наш проєкт minigrep виглядає добре! Тепер ми розділимо файл src/main.rs
та помістимо частину коду у файл src/lib.rs. Таким чином ми зможемо
тестувати код і матимемо файл src/main.rs з меншою кількістю обов’язків.
Давайте визначимо код, відповідальний за пошук тексту, у src/lib.rs, а не в
src/main.rs, що дасть змогу нам (або будь-кому іншому, хто використовує
наш бібліотечний крейт (library crate) minigrep) викликати функцію пошуку з більшої
кількості контекстів, ніж наш бінарний (binary) minigrep.
Спочатку давайте визначимо підпис функції search у src/lib.rs, як показано
в списку (Listing) 12-13, з тілом, яке викликає макрос unimplemented!. Ми докладніше
пояснимо підпис, коли реалізуємо його.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}Ми використали ключове слово pub у визначенні функції, щоб позначити search
як частину публічного API нашого бібліотечного крейту (library crate). Тепер у нас є
бібліотечний крейт (library crate), який ми можемо використовувати з нашого бінарного крейту (binary crate)
та який ми можемо тестувати!
Тепер нам потрібно ввести код, визначений у src/lib.rs, в область видимості бінарного крейту (binary crate) в src/main.rs і викликати його, як показано в списку (Listing) 12-14.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// --snip--
use minigrep::search;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}Ми додаємо рядок use minigrep::search, щоб ввести функцію search з
бібліотечного крейту в область видимості бінарного крейту. Потім, у функції
run, замість того щоб виводити вміст файлу, ми викликаємо функцію search
і передаємо значення config.query і contents як аргументи. Далі run
використовуватиме цикл for, щоб вивести кожен рядок, повернений search,
який відповідав запиту. Це також вдалий момент, щоб видалити виклики println!
у функції main, які показували запит і шлях до файлу, щоб наша програма
виводила лише результати пошуку (якщо не виникає помилок).
Зверніть увагу, що функція пошуку збиратиме всі результати у вектор, який повертає, ще до того, як відбудеться будь-який вивід. Така реалізація може повільно показувати результати під час пошуку у великих файлах, тому що результати не виводяться в міру їх знаходження; можливий спосіб виправити це за допомогою ітераторів ми обговоримо в розділі 13.
Фух! Це була велика робота, але ми підготували себе до успіху в майбутньому. Тепер обробляти помилки набагато простіше, і ми зробили код більш модульним. Відтепер майже вся наша робота буде у src/lib.rs.
Скористаймося цією новонабутою модульністю, зробивши те, що було б складно зі старим кодом, але легко з новим: напишімо кілька тестів!
Додавання функціональності за допомогою розробки через тестування
Додавання функціональності за допомогою розробки через тести (TDD)
Тепер, коли ми маємо пошукову логіку в src/lib.rs окремо від функції main,
нам набагато легше писати тести для основної функціональності нашого коду. Ми
можемо безпосередньо викликати функції з різними аргументами та перевіряти
повернені значення, не викликаючи наш бінарний файл із командного рядка.
У цьому розділі ми додамо логіку пошуку до програми minigrep, використовуючи
процес розробки через тести (TDD) за такими кроками:
- Написати тест, який не проходить, і запустити його, щоб переконатися, що він не проходить з тієї причини, яку ви очікуєте.
- Написати або змінити рівно стільки коду, щоб новий тест почав проходити.
- Рефакторити код, який ви щойно додали або змінили, і переконатися, що тести продовжують проходити.
- Повторити з кроку 1!
Хоча це лише один із багатьох способів писати програмне забезпечення, TDD може допомогти керувати дизайном коду. Написання тесту перед тим, як ви напишете код, що робить тест таким, що проходить, допомагає підтримувати високе покриття тестами протягом усього процесу.
Ми протестуємо реалізацію функціональності, яка фактично виконуватиме пошук
рядка запиту в вмісті файлу та формуватиме список рядків, що відповідають
запиту. Ми додамо цю функціональність у функцію під назвою search.
Написання тесту, що не проходить
У src/lib.rs ми додамо модуль tests із тестовою функцією, як ми зробили в
Розділі 11. Тестова функція задає поведінку, яку
ми хочемо, щоб мала функція search: вона прийматиме запит і текст для пошуку
та повертатиме лише ті рядки з тексту, які містять запит. У Cписку(Listing) 12-15
показано цей тест.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// --snip--
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Цей тест шукає рядок "duct". Текст, у якому ми шукаємо, складається з трьох
рядків, лише один з яких містить "duct" (зверніть увагу, що зворотна похила
риска після відкривної подвійної лапки повідомляє Rust не ставити символ нового
рядка на початку вмісту цього рядкового літерала). Ми стверджуємо, що значення,
повернене функцією search, містить лише той рядок, який ми очікуємо.
Якщо ми запустимо цей тест, він наразі завершиться невдало, тому що макрос
unimplemented! викликає паніку з повідомленням “not implemented”. Відповідно
до принципів TDD, ми зробимо маленький крок і додамо рівно стільки коду, щоб
тест не викликав паніку під час виклику функції, визначивши функцію search
так, щоб вона завжди повертала порожній вектор, як показано в списку(Listing) 12-16.
Тоді тест має скомпілюватися і завершитися невдало, тому що порожній вектор не
відповідає вектору, що містить рядок "safe, fast, productive.".
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Тепер обговорімо, чому нам потрібно визначити явний час життя 'a у сигнатурі
search і використати цей час життя з аргументом contents та значенням
повернення. Пригадайте в Розділі 10, що
параметри часу життя вказують, який час життя аргументу пов’язаний із часом
життя значення повернення. У цьому випадку ми вказуємо, що повернений вектор
має містити зрізи рядків, які посилаються на зрізи аргументу contents
(а не аргументу query).
Іншими словами, ми повідомляємо Rust, що дані, повернені функцією search,
житимуть так само довго, як дані, передані у функцію search в аргументі
contents. Це важливо! Дані, на які посилається зріз, мають бути дійсними,
щоб посилання було дійсним; якщо компілятор припустить, що ми створюємо
зрізи рядків з query, а не з contents, він виконуватиме перевірку
безпеки неправильно.
Якщо ми забудемо позначення часу життя та спробуємо скомпілювати цю функцію, ми отримаємо цю помилку:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
1 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
Rust не може знати, який із двох параметрів нам потрібен для виводу, тож
ми маємо сказати йому це явно. Зверніть увагу, що текст підказки пропонує
вказати той самий параметр часу життя для всіх параметрів і типу виводу, що
неправильно! Оскільки contents — це параметр, який містить увесь наш текст,
і ми хочемо повернути частини цього тексту, що відповідають, ми знаємо, що
contents — це єдиний параметр, який слід пов’язати зі значенням повернення
за допомогою синтаксису часу життя.
Інші мови програмування не вимагають від вас пов’язувати аргументи зі значеннями повернення в сигнатурі, але з часом ця практика стане легшою. Ви можете захотіти порівняти цей приклад із прикладами в розділі “Validating References with Lifetimes” у Розділі 10.
Написання коду для проходження тесту
Наразі наш тест завершується невдало, тому що ми завжди повертаємо порожній
вектор. Щоб виправити це та реалізувати search, нашій програмі потрібно
виконати такі кроки:
- Пройти по кожному рядку вмісту.
- Перевірити, чи містить рядок наш рядок запиту.
- Якщо так, додати його до списку значень, які ми повертаємо.
- Якщо ні, нічого не робити.
- Повернути список результатів, що відповідають.
Давайте пройдемося по кожному кроку, починаючи з ітерації по рядках.
Ітерація по рядках за допомогою методу lines
Rust має корисний метод для обробки покрокової ітерації рядків, який зручно
називається lines, і який працює так, як показано в списку(Listing) 12-17. Зверніть
увагу, що це ще не скомпілюється.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Метод lines повертає ітератор. Ми докладно поговоримо про ітератори в
Розділі 13. Але пригадайте, що ви бачили такий
спосіб використання ітератора в Listing 3-5, де ми
використовували цикл for з ітератором, щоб виконувати певний код для кожного
елемента в колекції.
Пошук у кожному рядку на відповідність запиту
Далі ми перевіримо, чи містить поточний рядок наш рядок запиту. На щастя,
рядки мають корисний метод під назвою contains, який робить це за нас!
Додайте виклик методу contains у функцію search, як показано в списку (Listing)
12-18. Зверніть увагу, що це все ще не скомпілюється.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}На даний момент ми нарощуємо функціональність. Щоб код скомпілювався, нам потрібно повернути значення з тіла, як ми й зазначили в сигнатурі функції.
Збереження рядків, що відповідають
Щоб завершити цю функцію, нам потрібен спосіб зберігати рядки, що відповідають,
які ми хочемо повернути. Для цього ми можемо створити змінний вектор перед
циклом for і викликати метод push, щоб зберегти line у векторі. Після
циклу for ми повертаємо вектор, як показано в списку(Listing) 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Тепер функція search має повертати лише ті рядки, які містять query, і
наш тест має пройти. Давайте запустимо тест:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Наш тест пройшов, тож ми знаємо, що це працює!
На цьому етапі ми могли б розглянути можливості для рефакторингу реалізації функції пошуку, зберігаючи тести такими, що проходять, щоб підтримувати ту саму функціональність. Код у функції пошуку не надто поганий, але він не використовує деякі корисні можливості ітераторів. Ми повернемося до цього прикладу в Розділі 13, де детально дослідимо ітератори та подивимося, як його покращити.
Тепер уся програма має працювати! Спробуймо її, спершу зі словом, яке має повернути рівно один рядок із вірша Емілі Дікінсон: frog.
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
Класно! Тепер спробуймо слово, яке збігатиметься з кількома рядками, як-от body:
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
І нарешті, переконаймося, що ми не отримаємо жодного рядка, коли шукаємо слово, якого немає ніде в вірші, наприклад monomorphization:
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
Чудово! Ми створили власну мініверсію класичного інструмента і багато чого дізналися про те, як структурувати програми. Ми також трохи дізналися про ввід і вивід файлів, часи життя, тестування та розбір командного рядка.
Щоб завершити цей проєкт, ми коротко покажемо, як працювати зі змінними середовища та як друкувати в стандартний потік помилок; обидва ці прийоми корисні, коли ви пишете програми командного рядка.
Робота зі змінними середовища
Робота з змінними середовища
Ми покращимо двійковий(бінарний) файл minigrep, додавши додаткову можливість: опцію для пошуку без урахування регістру, яку користувач може ввімкнути через змінну середовища. Ми могли б зробити цю можливість опцією командного рядка і вимагати, щоб користувачі вводили її щоразу, коли хочуть, щоб вона застосовувалася, але замість цього, зробивши її змінною середовища, ми дозволяємо нашим користувачам один раз встановити змінну середовища і мати всі їхні пошуки без урахування регістру в межах цієї сесії термінала.
Написання тесту, що не проходить, для пошуку без урахування регістру
Спочатку ми додаємо нову функцію search_case_insensitive до бібліотеки minigrep, яка буде викликатися, коли змінна середовища має значення. Ми й надалі будемо дотримуватися процесу TDD, тож перший крок знову — написати тест, що не проходить (failing test). Ми додамо новий тест для нової функції search_case_insensitive і перейменуємо наш старий тест з one_result на case_sensitive, щоб прояснити відмінності між двома тестами, як показано в Listing 12-20.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Зверніть увагу, що ми також відредагували contents старого тесту. Ми додали новий рядок із текстом "Duct tape." з великою D, який не повинен збігатися із запитом "duct", коли ми виконуємо пошук із урахуванням регістру. Зміна старого тесту таким чином допомагає переконатися, що ми випадково не зламаємо функціональність пошуку з урахуванням регістру, яку ми вже реалізували. Цей тест має проходити зараз і має продовжувати проходити, поки ми працюємо над пошуком без урахування регістру.
Новий тест для пошуку без урахування регістру використовує "rUsT" як свій запит. У функції search_case_insensitive, яку ми збираємося додати, запит "rUsT" має збігатися з рядком, що містить "Rust:" з великою R, і збігатися з рядком "Trust me.", хоча в обох випадках регістр відрізняється від запиту. Це наш тест, що не проходить (failing test), і він не зможе скомпілюватися, тому що ми ще не визначили функцію search_case_insensitive. За бажанням можете додати заглушку реалізації, яка завжди повертає порожній вектор, подібно до того, як ми зробили для функції search у Listing 12-16, щоб побачити, як тест скомпілюється і провалиться.
Реалізація функції search_case_insensitive
Функція search_case_insensitive, показана в Listing 12-21, буде майже такою самою, як функція search. Єдина відмінність полягає в тому, що ми переведемо в нижній регістр query і кожен line, щоб незалежно від регістру вхідних аргументів вони були в одному регістрі, коли ми перевірятимемо, чи містить рядок запит.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Спочатку ми переводимо рядок query у нижній регістр і зберігаємо його в новій змінній з тією самою назвою, затіняючи початковий query. Виклик to_lowercase для запиту є необхідним, щоб незалежно від того, чи запит користувача — "rust", "RUST", "Rust" або "rUsT", ми трактували запит так, ніби це "rust", і не враховували регістр. Хоча to_lowercase оброблятиме базовий Unicode, він не буде на 100 відсотків точним. Якби ми писали справжній застосунок, нам би довелося зробити тут трохи більше, але цей розділ про змінні середовища, а не про Unicode, тож ми залишимо це так.
Зверніть увагу, що query тепер є String, а не зрізом рядка, тому що виклик to_lowercase створює нові дані, а не посилається на наявні дані. Скажімо, для прикладу, запит — це "rUsT": цей зріз рядка не містить нижньорегістрованого u або t, які ми могли б використати, тож нам потрібно виділити новий String, що містить "rust". Коли ми тепер передаємо query як аргумент методу contains, нам потрібно додати амперсанд, тому що сигнатура contains визначена так, щоб приймати зріз рядка.
Далі ми додаємо виклик to_lowercase до кожного line, щоб перевести всі символи в нижній регістр. Тепер, коли ми перетворили line і query у нижній регістр, ми знаходитимемо збіги незалежно від того, який регістр має запит.
Давайте подивимося, чи проходить ця реалізація тести:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Чудово! Вони пройшли. Тепер викличмо нову функцію search_case_insensitive із функції run. Спочатку ми додамо опцію конфігурації до структури Config, щоб перемикатися між пошуком із урахуванням регістру та без урахування регістру. Додавання цього поля призведе до помилок компілятора, тому що ми ще ніде не ініціалізуємо це поле:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Ми додали поле ignore_case, яке містить Boolean. Далі нам потрібно, щоб функція run перевірила значення поля ignore_case і використала його, щоб вирішити, чи викликати функцію search, чи функцію search_case_insensitive, як показано в Listing 12-22. Це все ще не скомпілюється.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Нарешті, нам потрібно перевірити змінну середовища. Функції для роботи зі змінними середовища є в модулі env у стандартній бібліотеці, який уже є в області видимості на початку src/main.rs. Ми використаємо функцію var із модуля env, щоб перевірити, чи було задано будь-яке значення для змінної середовища з назвою IGNORE_CASE, як показано в Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Тут ми створюємо нову змінну ignore_case. Щоб встановити її значення, ми викликаємо функцію env::var і передаємо їй ім’я змінної середовища IGNORE_CASE. Функція env::var повертає Result, який буде успішним варіантом Ok, що містить значення змінної середовища, якщо змінну середовища встановлено в будь-яке значення. Вона поверне варіант Err, якщо змінну середовища не встановлено.
Ми використовуємо метод is_ok на Result, щоб перевірити, чи встановлено змінну середовища, що означає, що програма має виконати пошук без урахування регістру. Якщо змінну середовища IGNORE_CASE не встановлено ні в яке значення, is_ok поверне false, і програма виконає пошук з урахуванням регістру. Нас не цікавить значення змінної середовища, лише те, встановлена вона чи ні, тож ми перевіряємо is_ok замість використання unwrap, expect чи будь-якого з інших методів, які ми бачили на Result.
Ми передаємо значення у змінній ignore_case екземпляру Config, щоб функція run могла прочитати це значення і вирішити, чи викликати search_case_insensitive, чи search, як ми реалізували в Listing 12-22.
Давайте спробуємо! Спочатку ми запустимо нашу програму без встановленої змінної середовища і з запитом to, який має збігатися з будь-яким рядком, що містить слово to в нижньому регістрі:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
Схоже, це все ще працює! Тепер запустімо програму з IGNORE_CASE, встановленою в 1, але з тим самим запитом to:
$ IGNORE_CASE=1 cargo run -- to poem.txt
Якщо ви використовуєте PowerShell, вам потрібно буде встановити змінну середовища і запустити програму як окремі команди:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
Це зробить так, що IGNORE_CASE залишатиметься встановленою протягом решти вашої сесії оболонки. Її можна зняти за допомогою командлета (cmdlet) Remove-Item:
PS> Remove-Item Env:IGNORE_CASE
Ми маємо отримати рядки, які містять to і можуть мати великі літери:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
Чудово, ми також отримали рядки, що містять To! Наша програма minigrep тепер може виконувати пошук без урахування регістру, керований змінною середовища. Тепер ви знаєте, як керувати опціями, встановленими або за допомогою аргументів командного рядка, або за допомогою змінних середовища.
Деякі програми дозволяють використовувати аргументи і змінні середовища для тієї самої конфігурації. У таких випадках програми вирішують, що одне або інше має пріоритет. Для ще однієї вправи самостійно спробуйте керувати чутливістю до регістру або через аргумент командного рядка, або через змінну середовища. Вирішіть, чи має аргумент командного рядка, чи змінна середовища мати пріоритет, якщо програму запущено з одним встановленим у режим урахування регістру, а іншим — у режим ігнорування регістру.
Модуль std::env містить ще багато корисних можливостей для роботи зі змінними середовища: перегляньте його документацію, щоб побачити, що доступно.
Переспрямування помилок до стандартного потоку помилок
Перенаправлення помилок до стандартного потоку помилок
На даний момент ми записуємо весь наш вивід до термінала за допомогою
макроса println!. У більшості терміналів є два види виводу: стандартний
вивід (stdout) для загальної інформації та стандартний потік помилок
(stderr) для повідомлень про помилки. Це розрізнення дає змогу користувачам
обирати: перенаправити успішний вивід програми до файла, але все ще виводити
повідомлення про помилки на екран.
Макрос println! здатний друкувати лише до стандартного виводу, тож нам
потрібно використати щось інше, щоб друкувати до стандартного потоку помилок.
Перевірка того, куди записуються помилки
Спочатку давайте подивимося, як вміст, що друкується minigrep, наразі
записується до стандартного виводу, включно з будь-якими повідомленнями про
помилки, які ми хочемо записувати до стандартного потоку помилок замість цього.
Ми зробимо це, перенаправивши потік стандартного виводу до файла, навмисно
спричинивши помилку. Ми не будемо перенаправляти потік стандартного потоку
помилок, тож будь-який вміст, надісланий до стандартного потоку помилок,
продовжить відображатися на екрані.
Від командних рядків програм очікується, що вони надсилатимуть повідомлення про помилки до потоку стандартного потоку помилок, щоб ми все ще могли бачити повідомлення про помилки на екрані навіть якщо ми перенаправимо потік стандартного виводу до файла. Наша програма наразі поводиться не надто добре: зараз ми побачимо, що вона зберігає вивід повідомлення про помилку до файла замість цього!
Щоб продемонструвати таку поведінку, ми запустимо програму з > та шляхом до
файла, output.txt, до якого ми хочемо перенаправити потік стандартного
виводу. Ми не передаватимемо жодних аргументів, що має спричинити помилку:
$ cargo run > output.txt
Синтаксис > підказує оболонці записати вміст стандартного виводу до
output.txt замість екрана. Ми не побачили повідомлення про помилку, яке
очікували побачити на екрані, тож це означає, що воно мусило потрапити до
файла. Ось що містить output.txt:
Problem parsing arguments: not enough arguments
Ага, наше повідомлення про помилку друкується до стандартного виводу. Такі повідомлення про помилки значно корисніше друкувати до стандартного потоку помилок, щоб у файл потрапляли лише дані з успішного запуску. Ми це змінимо.
Друкування помилок до стандартного потоку помилок
Ми використаємо код у Listing 12-24, щоб змінити спосіб друкування повідомлень
про помилки. Через рефакторинг, який ми зробили раніше в цьому розділі, весь код,
що друкує повідомлення про помилки, міститься в одній функції, main.
Стандартна бібліотека надає макрос eprintln!, який друкує до стандартного
потоку помилок, тож давайте змінимо два місця, де ми викликали println! для
друку помилок, на використання eprintln! замість цього.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Тепер давайте знову запустимо програму тим самим способом, без жодних аргументів
і з перенаправленням стандартного виводу за допомогою >:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
Тепер ми бачимо помилку на екрані, а output.txt не містить нічого, що є поведінкою, яку ми очікуємо від командних рядків програм.
Давайте знову запустимо програму з аргументами, які не спричиняють помилку, але все ще перенаправимо стандартний вивід до файла, ось так:
$ cargo run -- to poem.txt > output.txt
Ми не побачимо жодного виводу в терміналі, а output.txt міститиме наші результати:
Filename: output.txt
Are you nobody, too?
How dreary to be somebody!
Це демонструє, що тепер ми використовуємо стандартний вивід для успішного виводу та стандартний потік помилок для виводу помилок, як і належить.
Підсумок
У цьому розділі ми підсумували деякі з основних концептів, які ви вже вивчили, і
розглянули, як виконувати поширені операції I/O у Rust. Використовуючи
аргументи командного рядка, файли, змінні середовища та макрос eprintln! для
друку помилок, ви тепер готові писати програми командного рядка. У поєднанні
з концептами з попередніх розділів ваш код буде добре організованим, ефективно
зберігатиме дані у відповідних структурах даних, гарно оброблятиме помилки та
буде добре протестованим.
Далі ми розглянемо деякі можливості Rust, на які вплинули функціональні мови: замикання та ітератори.
Функціональні мовні можливості: ітератори та замикання
Дизайн Rust був натхненний багатьма наявними мовами та техніками, і одним із значних впливів є функціональне програмування. Програмування у функціональному стилі часто включає використання функцій як значень шляхом передавання їх як аргументів, повернення їх з інших функцій, присвоювання їх змінним для подальшого виконання тощо.
У цій главі ми не будемо дискутувати про те, що таке функціональне програмування, а що ні, а натомість обговоримо деякі можливості Rust, які подібні до можливостей у багатьох мовах, що часто називають функціональними.
Точніше, ми розглянемо:
- Замикання, конструкцію, схожу на функцію, яку ви можете зберігати у змінній
- Ітератори, спосіб обробки серії елементів
- Як використовувати замикання та ітератори для поліпшення проєкту I/O у главі 12
- Продуктивність замикань та ітераторів (спойлер: вони швидші, ніж ви могли б подумати!)
Ми вже розглянули деякі інші можливості Rust, такі як зіставлення зі зразком (pattern matching) і переліки, на які також вплинув функціональний стиль. Оскільки опанування замикань та ітераторів є важливою частиною написання швидкого, ідіоматичного коду Rust, ми присвятимо цю главу повністю їм.
Замикання
Замикання
Замикання Rust — це анонімні функції, які ви можете зберегти у змінній або передати як аргументи іншим функціям. Ви можете створити замикання в одному місці, а потім викликати замикання в іншому, щоб обчислити його в іншому контексті. На відміну від функцій, замикання можуть захоплювати значення з області видимості, у якій їх визначено. Ми продемонструємо, як ці можливості замикань дозволяють повторно використовувати код і налаштовувати поведінку.
Захоплення середовища
Спершу ми розглянемо, як можна використовувати замикання, щоб захоплювати значення з середовища, у якому їх визначено, для подальшого використання. Ось сценарій: час від часу наша компанія футболок роздає ексклюзивну футболку обмеженої серії комусь зі списку розсилки як промоакцію. Люди зі списку розсилки можуть за бажанням додати у свій профіль улюблений колір. Якщо в людини, обраної для безплатної футболки, задано улюблений колір, вона отримає футболку цього кольору. Якщо людина не вказала улюблений колір, вона отримає той колір, якого в компанії зараз найбільше.
Є багато способів реалізувати це. У цьому прикладі ми використаємо
enum під назвою ShirtColor, який має варіанти Red і Blue (для
простоти обмеживши кількість доступних кольорів). Ми представляємо
запаси компанії за допомогою структури Inventory, яка має поле під назвою shirts,
що містить Vec<ShirtColor>, який представляє кольори футболок, що зараз є на складі.
Метод giveaway, визначений для Inventory, отримує необов’язкову перевагу
щодо кольору футболки від переможця безплатної футболки та повертає колір футболки, який
отримає людина. Ця схема показана у Listing 13-1.
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"The user with preference {:?} gets {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"The user with preference {:?} gets {:?}",
user_pref2, giveaway2
);
}store, визначений у main, має дві сині футболки й одну червону футболку, що залишилися
для розподілу в межах цієї акції з обмеженою серією. Ми викликаємо метод giveaway
для користувача з перевагою щодо червоної футболки та для користувача без жодної переваги.
Знову ж таки, цей код можна реалізувати багатьма способами, і тут, щоб зосередитися на
замиканнях, ми залишили лише концепції, які ви вже вивчили, за винятком тіла
методу giveaway, що використовує замикання. У методі giveaway ми отримуємо
перевагу користувача як параметр типу Option<ShirtColor> і викликаємо метод
unwrap_or_else на user_preference. Метод unwrap_or_else для
Option<T> визначений стандартною бібліотекою.
Він приймає один аргумент: замикання без аргументів, яке повертає значення T
(той самий тип, що зберігається у варіанті Some типу Option<T>, у цьому випадку
ShirtColor). Якщо Option<T> є варіантом Some, unwrap_or_else
повертає значення зсередини Some. Якщо Option<T> є варіантом None,
unwrap_or_else викликає замикання і повертає значення, яке повертає
замикання.
Ми вказуємо вираз замикання || self.most_stocked() як аргумент до
unwrap_or_else. Це замикання, яке само не приймає жодних параметрів (якби
замикання мало параметри, вони з’явилися б між двома вертикальними рисками). Тіло
замикання викликає self.most_stocked(). Ми визначаємо замикання
тут, а реалізація unwrap_or_else обчислить замикання
пізніше, якщо результат буде потрібен.
Під час запуску цього коду буде надруковано таке:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
Один цікавий аспект тут полягає в тому, що ми передали замикання, яке викликає
self.most_stocked() на поточному екземплярі Inventory. Стандартній бібліотеці
не потрібно було знати нічого про типи Inventory або ShirtColor, які ми
визначили, чи про логіку, яку ми хочемо використати в цій ситуації. Замикання захоплює
незмінне посилання на екземпляр self типу Inventory і передає його разом із
кодом, який ми вказуємо, методу unwrap_or_else. Функції, з іншого боку,
не здатні захоплювати своє середовище таким чином.
Виведення та анотування типів замикань
Є ще відмінності між функціями та замиканнями. Замикання зазвичай не
вимагають від вас анотувати типи параметрів або тип значення, що повертається,
як це роблять функції fn. Анотації типів потрібні для функцій, тому що
типи є частиною явного інтерфейсу, відкритого вашим користувачам. Чітке визначення
цього інтерфейсу важливе для того, щоб усі погоджувалися, які типи
значень функція використовує і повертає. Замикання, з іншого боку, не використовуються
в такому відкритому інтерфейсі: вони зберігаються у змінних і
використовуються без іменування та відкриття для користувачів нашої бібліотеки.
Замикання зазвичай короткі й релевантні лише в межах вузького контексту, а не в будь-якому довільному сценарії. У межах цих обмежених контекстів компілятор може вивести типи параметрів і тип значення, що повертається, подібно до того, як він може виводити типи більшості змінних (є рідкісні випадки, коли компілятору також потрібні анотації типів замикання).
Як і для змінних, ми можемо додати анотації типів, якщо хочемо підвищити явність і зрозумілість ціною більшої багатослівності, ніж це суворо необхідно. Анотування типів для замикання виглядало б так, як визначення, показане в Listing 13-2. У цьому прикладі ми визначаємо замикання й зберігаємо його у змінній, а не визначаємо замикання в тому місці, де передаємо його як аргумент, як ми зробили в Listing 13-1.
use std::thread;
use std::time::Duration;
fn generate_workout(intensity: u32, random_number: u32) {
let expensive_closure = |num: u32| -> u32 {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};
if intensity < 25 {
println!("Today, do {} pushups!", expensive_closure(intensity));
println!("Next, do {} situps!", expensive_closure(intensity));
} else {
if random_number == 3 {
println!("Take a break today! Remember to stay hydrated!");
} else {
println!(
"Today, run for {} minutes!",
expensive_closure(intensity)
);
}
}
}
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}Після додавання анотацій типів синтаксис замикань виглядає більше схожим на синтаксис функцій. Тут ми визначаємо функцію, яка додає 1 до свого параметра, і замикання, яке має таку саму поведінку, для порівняння. Ми додали деякі пробіли, щоб вирівняти відповідні частини. Це ілюструє, наскільки синтаксис замикання подібний до синтаксису функції, за винятком використання вертикальних рисок і того, скільки синтаксису є необов’язковим:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;Перший рядок показує визначення функції, а другий рядок показує повністю
анотоване визначення замикання. У третьому рядку ми прибираємо анотації типів
з визначення замикання. У четвертому рядку ми прибираємо дужки, які
є необов’язковими, тому що тіло замикання містить лише один вираз. Усі ці
визначення є дійсними й дадуть однакову поведінку під час виклику. Рядки
add_one_v3 і add_one_v4 вимагають, щоб замикання було обчислене, щоб
код міг скомпілюватися, тому що типи буде виведено з їх використання. Це
подібно до того, як let v = Vec::new(); потребує або анотацій типів, або значень деякого
типу, які потрібно вставити у Vec, щоб Rust міг вивести тип.
Для визначень замикань компілятор виведе один конкретний тип для кожного
з їхніх параметрів і для їхнього значення, що повертається. Наприклад, Listing 13-3 показує
визначення короткого замикання, яке просто повертає значення, що отримує як
параметр. Це замикання не дуже корисне, окрім як для цілей цього
прикладу. Зауважте, що ми не додали жодних анотацій типів до визначення.
Оскільки немає анотацій типів, ми можемо викликати замикання з будь-яким типом,
що ми тут і зробили зі String уперше. Якщо потім ми спробуємо викликати
example_closure з цілим числом, ми отримаємо помилку.
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}Компілятор видає нам цю помилку:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| --------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = example_closure(String::from("hello"));
| --------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let example_closure = |x| x;
| ^
help: try using a conversion method
|
5 | let n = example_closure(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` (bin "closure-example") due to 1 previous error
Першого разу, коли ми викликаємо example_closure зі значенням String,
компілятор виводить тип x і тип значення, що повертається, для замикання як String.
Потім ці типи закріплюються в замиканні в example_closure, і ми отримуємо помилку
типу, коли наступного разу намагаємося використати інший тип із тим самим замиканням.
Захоплення посилань або переміщення власності
Замикання можуть захоплювати значення зі свого середовища трьома способами, які безпосередньо відповідають трьом способам, якими функція може приймати параметр: запозиченням незмінно, запозиченням змінно та прийняттям власності. Замикання вирішить, який із цих способів використати, на основі того, що робить тіло функції із захопленими значеннями.
У Listing 13-4 ми визначаємо замикання, яке захоплює незмінне посилання на
вектор під назвою list, тому що йому потрібне лише незмінне посилання, щоб надрукувати
значення.
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
let only_borrows = || println!("From closure: {list:?}");
println!("Before calling closure: {list:?}");
only_borrows();
println!("After calling closure: {list:?}");
}Цей приклад також ілюструє, що змінна може прив’язуватися до визначення замикання, а потім ми можемо викликати замикання, використовуючи ім’я змінної та дужки так, ніби ім’я змінної було ім’ям функції.
Оскільки ми можемо мати кілька незмінних посилань на list одночасно,
list усе ще доступний з коду до визначення замикання, після
визначення замикання, але до виклику замикання, і після виклику замикання.
Цей код компілюється, виконується і друкує:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
Before calling closure: [1, 2, 3]
From closure: [1, 2, 3]
After calling closure: [1, 2, 3]
Далі, у Listing 13-5, ми змінюємо тіло замикання так, щоб воно додавало елемент до
вектора list. Тепер замикання захоплює змінне посилання.
fn main() {
let mut list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
let mut borrows_mutably = || list.push(7);
borrows_mutably();
println!("After calling closure: {list:?}");
}Цей код компілюється, виконується і друкує:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
After calling closure: [1, 2, 3, 7]
Зауважте, що між визначенням і викликом замикання borrows_mutably більше немає println!: коли borrows_mutably визначено, воно захоплює
змінне посилання на list. Ми не використовуємо замикання знову після того, як
замикання викликано, тож змінне запозичення закінчується. Між визначенням
замикання і викликом замикання друкувати через незмінне запозичення не можна,
тому що коли є змінне запозичення, жодні інші
запозичення не дозволені. Спробуйте додати тут println!, щоб побачити, яке повідомлення про помилку ви отримаєте!
Якщо ви хочете примусити замикання прийняти власність над значеннями, які воно використовує
в середовищі, навіть якщо тіло замикання суворо не потребує
власності, ви можете використати ключове слово move перед списком параметрів.
Цей прийом здебільшого корисний, коли замикання передають новому потоку, щоб перемістити
дані так, щоб вони належали новому потоку. Ми детально обговоримо потоки й те, чому
ви хотіли б використовувати їх, у Розділі 16, коли говоритимемо про
конкурентність, але наразі коротко розглянемо створення нового потоку, використовуючи
замикання, якому потрібне ключове слово move. Listing 13-6 показує Listing 13-4,
змінений так, щоб друкувати вектор у новому потоці, а не в головному потоці.
use std::thread;
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
thread::spawn(move || println!("From thread: {list:?}"))
.join()
.unwrap();
}Ми створюємо новий потік, передаючи потоку замикання для виконання як аргумент.
Тіло замикання друкує список. У Listing 13-4 замикання захоплювало лише list
за допомогою незмінного посилання, тому що це найменший обсяг доступу до list,
який потрібен, щоб надрукувати його. У цьому прикладі, хоча тіло замикання
все ще потребує лише незмінного посилання, нам потрібно вказати, що list слід
перемістити в замикання, розмістивши ключове слово move на початку
визначення замикання. Якби головний потік виконував більше операцій перед
викликом join у новому потоці, новий потік міг би завершитися до того, як закінчиться решта
головного потоку, або головний потік міг би завершитися першим. Якби головний потік
зберігав власність над list, але завершився раніше за новий потік і знищив би
list, незмінне посилання в потоці стало б недійсним. Тому
компілятор вимагає, щоб list було переміщено в замикання, передане новому потоку,
щоб посилання було дійсним. Спробуйте прибрати ключове слово move або використати
list у головному потоці після того, як замикання визначено, щоб побачити, які
помилки компілятора ви отримаєте!
Переміщення захоплених значень із замикань
Після того як замикання захопило посилання або захопило власність над значенням із середовища, де замикання визначено (тим самим впливаючи на те, що, якщо взагалі щось, переміщується в замикання), код у тілі замикання визначає, що стається з посиланнями або значеннями, коли замикання буде обчислено пізніше (тим самим впливаючи на те, що, якщо взагалі щось, переміщується з замикання).
Тіло замикання може робити будь-що з наведеного: перемістити захоплене значення з замикання, змінити захоплене значення, ні переміщувати, ні змінювати значення або спочатку не захоплювати нічого із середовища.
Те, як замикання захоплює та обробляє значення зі середовища, впливає на
те, які трейт-и реалізує замикання, а трейт-и — це те, як функції та структури
можуть вказувати, які саме замикання вони можуть використовувати. Замикання автоматично
реалізовуватимуть один, два або всі три ці трейт-и Fn, у додатковій
манері, залежно від того, як тіло замикання обробляє значення:
FnOnceзастосовується до замикань, які можна викликати один раз. Усі замикання реалізують принаймні цей трейт, тому що всі замикання можна викликати. Замикання, яке переміщує захоплені значення зсередини свого тіла, реалізовуватиме лишеFnOnceі жоден з інших трейт-івFn, тому що його можна викликати лише один раз.FnMutзастосовується до замикань, які не переміщують захоплені значення з їхнього тіла, але можуть змінювати захоплені значення. Такі замикання можна викликати більше ніж один раз.Fnзастосовується до замикань, які не переміщують захоплені значення з їхнього тіла і не змінюють захоплені значення, а також до замикань, які нічого не захоплюють зі свого середовища. Такі замикання можна викликати більше ніж один раз без зміни їхнього середовища, що важливо в таких випадках, як одночасний багаторазовий виклик замикання.
Погляньмо на визначення методу unwrap_or_else для Option<T>, яке
ми використовували в Listing 13-1:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Пам’ятайте, що T — це узагальнений тип, який представляє тип значення у
варіанті Some Option. Цей тип T також є типом значення, що повертається,
функції unwrap_or_else: код, який викликає unwrap_or_else на
Option<String>, наприклад, отримає String.
Далі зауважте, що функція unwrap_or_else має додатковий узагальнений параметр типу
F. Тип F — це тип параметра під назвою f, який є
замиканням, яке ми надаємо під час виклику unwrap_or_else.
Обмеження трейт-у, вказане для узагальненого типу F, — FnOnce() -> T, що
означає, що F має бути здатним бути викликаним один раз, не приймати аргументів
і повертати T. Використання FnOnce в обмеженні трейт-у виражає
обмеження, що unwrap_or_else не викликатиме f більше ніж один раз. У тілі
unwrap_or_else ми бачимо, що якщо Option є Some, f не буде
викликано. Якщо Option є None, f буде викликано один раз. Оскільки всі
замикання реалізують FnOnce, unwrap_or_else приймає всі три види
замикань і є настільки гнучким, наскільки це можливо.
Примітка: Якщо те, що ми хочемо зробити, не потребує захоплення значення з середовища, ми можемо використовувати ім’я функції замість замикання там, де нам потрібно щось, що реалізує один із трейт-ів
Fn. Наприклад, для значенняOption<Vec<T>>ми могли б викликатиunwrap_or_else(Vec::new), щоб отримати новий порожній вектор, якщо значення єNone. Компілятор автоматично реалізує той із трейт-івFn, який застосовний для визначення функції.
Тепер погляньмо на метод стандартної бібліотеки sort_by_key, визначений для зрізів,
щоб побачити, чим він відрізняється від unwrap_or_else і чому sort_by_key
використовує FnMut, а не FnOnce, для обмеження трейт-у. Замикання отримує один аргумент
у формі посилання на поточний елемент у зрізі, який розглядається,
і повертає значення типу K, яке можна впорядкувати. Ця функція корисна
коли ви хочете відсортувати зріз за певним атрибутом кожного елемента. У
Listing 13-7 у нас є список екземплярів Rectangle, і ми використовуємо sort_by_key,
щоб упорядкувати їх за атрибутом width від меншого до більшого.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
list.sort_by_key(|r| r.width);
println!("{list:#?}");
}Цей код друкує:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
Причина, чому sort_by_key визначено так, щоб приймати замикання FnMut, полягає в тому, що він викликає
замикання багаторазово: один раз для кожного елемента в зрізі. Замикання |r| r.width не захоплює, не змінює і не переміщує нічого зі свого середовища, тому
воно відповідає вимогам обмеження трейт-у.
На відміну від цього, Listing 13-8 показує приклад замикання, яке реалізує лише
трейт FnOnce, тому що воно переміщує значення з середовища. Компілятор
не дозволить нам використати це замикання з sort_by_key.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("closure called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{list:#?}");
}Це надуманий, заплутаний спосіб (який не працює) спробувати підрахувати
кількість разів, коли sort_by_key викликає замикання під час сортування list.
Цей код намагається зробити цей підрахунок, поміщаючи value — String із середовища
замикання — у вектор sort_operations. Замикання захоплює value, а
потім переміщує value із замикання, передаючи власність над value у
вектор sort_operations. Це замикання можна викликати один раз; спроба викликати
його вдруге не спрацювала б, тому що value уже не було б у
середовищі, щоб знову помістити його в sort_operations! Тому це замикання
реалізує лише FnOnce. Коли ми намагаємося скомпілювати цей код, ми отримуємо цю помилку,
що value не можна перемістити з замикання, тому що замикання має
реалізовувати FnMut:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("closure called");
| ----- ------------------------------ move occurs because `value` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | sort_operations.push(value);
| ^^^^^ `value` is moved here
|
help: consider cloning the value if the performance cost is acceptable
|
18 | sort_operations.push(value.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` (bin "rectangles") due to 1 previous error
Помилка вказує на рядок у тілі замикання, який переміщує value із
середовища. Щоб виправити це, нам потрібно змінити тіло замикання так, щоб воно не
переміщувало значення з середовища. Утримувати лічильник у середовищі й
збільшувати його значення в тілі замикання — це більш прямий спосіб
порахувати кількість викликів замикання. Замикання в Listing 13-9
працює з sort_by_key, тому що воно лише захоплює змінне посилання на
лічильник num_sort_operations і тому може бути викликане більше ніж один раз.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut num_sort_operations = 0;
list.sort_by_key(|r| {
num_sort_operations += 1;
r.width
});
println!("{list:#?}, sorted in {num_sort_operations} operations");
}Трейт-и Fn важливі під час визначення або використання функцій чи типів, які
використовують замикання. У наступному розділі ми обговоримо ітератори. Багато
методів ітераторів приймають замикання як аргументи, тож пам’ятайте про ці деталі
замикань, коли ми рухатимемося далі!
Обробка послідовності елементів за допомогою ітераторів
Обробка серії елементів за допомогою iterator
Шаблон iterator дає змогу виконувати певне завдання над послідовністю елементів по черзі. За логіку проходження по кожному елементу та визначення моменту, коли послідовність завершилася, відповідає iterator. Коли ви використовуєте iterator, вам не потрібно реалізовувати цю логіку самостійно.
У Rust iterator-и є ледачими, тобто вони не мають жодного ефекту, доки ви не викличете методи, які споживають iterator, щоб використати його. Наприклад, код у Listing 13-10 створює iterator над елементами у векторі v1, викликаючи метод iter, визначений на Vec<T>. Сам по собі цей код нічого корисного не робить.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
}Iterator зберігається у змінній v1_iter. Після того як ми створили iterator, ми можемо використовувати його різними способами. У Listing 3-5 ми проходили по масиву за допомогою циклу for, щоб виконати певний код над кожним його елементом. Під капотом це неявно створювало, а потім споживало iterator, але до цього моменту ми не заглиблювалися в те, як саме це працює.
У прикладі в Listing 13-11 ми відокремлюємо створення iterator від використання iterator у циклі for. Коли цикл for викликається з використанням iterator у v1_iter, кожен елемент у iterator використовується в одній ітерації циклу, яка виводить кожне значення.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
for val in v1_iter {
println!("Got: {val}");
}
}У мовах, які не мають iterator-ів, наданих їхніми стандартними бібліотеками, ви, ймовірно, реалізували б цю саму функціональність, започаткувавши змінну з індексу 0, використовуючи цю змінну для індексування у векторі, щоб отримати значення, і збільшуючи значення змінної в циклі, доки воно не досягне загальної кількості елементів у векторі.
Iterator-и виконують усю цю логіку за вас, скорочуючи повторюваний код, у якому ви потенційно могли б помилитися. Iterator-и дають вам більше гнучкості для використання тієї самої логіки з багатьма різними видами послідовностей, а не лише зі структурами даних, у які можна індексуватися, як-от вектори. Розгляньмо, як iterator-и це роблять.
Трейт Iterator і метод next
Усі iterator-и реалізують трейт під назвою Iterator, який визначено у стандартній бібліотеці. Визначення трейт має такий вигляд:
#![allow(unused)]
fn main() {
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// methods with default implementations elided
}
}Зверніть увагу, що це визначення використовує новий синтаксис: type Item і Self::Item, які визначають асоційований тип із цим трейт. Ми детально поговоримо про асоційовані типи в Chapter 20. Наразі вам потрібно знати лише те, що цей код означає: реалізація трейт Iterator вимагає, щоб ви також визначили тип Item, і цей тип Item використовується в типі повернення методу next. Іншими словами, тип Item буде типом, що повертається з iterator.
Трейт Iterator вимагає від реалізаторів визначити лише один метод: метод next, який повертає один елемент iterator за раз, загорнутий у Some, а коли ітерація завершена, повертає None.
Ми можемо викликати метод next на iterator безпосередньо; Listing 13-12 демонструє, які значення повертаються з повторних викликів next на iterator, створеному з вектора.
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}Зверніть увагу, що нам потрібно було зробити v1_iter змінною: виклик методу next на iterator змінює внутрішній стан, який iterator використовує, щоб відстежувати, де він перебуває в послідовності. Іншими словами, цей код споживає iterator, або використовує його цілком. Кожен виклик next забирає один елемент з iterator. Нам не потрібно було робити v1_iter змінною, коли ми використовували цикл for, тому що цикл взяв v1_iter у власність і зробив його змінним приховано.
Також зверніть увагу, що значення, які ми отримуємо з викликів next, є незмінними посиланнями на значення у векторі. Метод iter створює iterator за незмінними посиланнями. Якщо ми хочемо створити iterator, який бере вектор v1 у власність і повертає власні значення, ми можемо викликати into_iter замість iter. Аналогічно, якщо ми хочемо ітерувати за змінними посиланнями, ми можемо викликати iter_mut замість iter.
Методи, що споживають iterator
Трейт Iterator має низку різних методів із реалізаціями за замовчуванням, наданими стандартною бібліотекою; ви можете дізнатися про ці методи, переглянувши документацію API стандартної бібліотеки для трейт Iterator. Деякі з цих методів викликають метод next у своєму визначенні, тому від вас і вимагається реалізувати метод next, коли ви реалізуєте трейт Iterator.
Методи, що викликають next, називаються адаптерами, що споживають, тому що їхній виклик використовує iterator цілком. Один із прикладів — метод sum, який бере iterator у власність і проходить крізь елементи, неодноразово викликаючи next, таким чином споживаючи iterator. Під час ітерації він додає кожен елемент до поточної суми та повертає цю суму, коли ітерація завершена. Listing 13-13 містить тест, що ілюструє використання методу sum.
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}Ми не маємо права використовувати v1_iter після виклику sum, тому що sum бере у власність iterator, на якому ми його викликаємо.
Методи, що створюють інші iterator
Адаптери iterator — це методи, визначені на трейт Iterator, які не споживають iterator. Натомість вони створюють різні iterator-и, змінюючи певний аспект оригінального iterator.
Listing 13-14 показує приклад виклику методу-адаптера iterator map, який приймає замикання, що викликається для кожного елемента під час проходження по елементах. Метод map повертає новий iterator, який видає змінені елементи. Замикання тут створює новий iterator, у якому кожен елемент з вектора буде збільшено на 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1);
}Однак цей код породжує попередження:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Код у Listing 13-14 нічого не робить; замикання, яке ми вказали, ніколи не викликається. Попередження нагадує нам, чому: адаптери iterator є ледачими, і тут нам потрібно спожити iterator.
Щоб виправити це попередження і спожити iterator, ми використаємо метод collect, який ми застосовували з env::args у Listing 12-1. Цей метод споживає iterator і збирає отримані значення в тип даних колекції.
У Listing 13-15 ми збираємо результати ітерації по iterator, що повертається з виклику map, у вектор. Цей вектор зрештою міститиме кожен елемент з оригінального вектора, збільшений на 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
assert_eq!(v2, vec![2, 3, 4]);
}Оскільки map приймає замикання, ми можемо вказати будь-яку операцію, яку хочемо виконати над кожним елементом. Це чудовий приклад того, як замикання дають змогу налаштувати певну поведінку, повторно використовуючи поведінку ітерації, яку надає трейт Iterator.
Ви можете ланцюжком викликати кілька адаптерів iterator, щоб виконувати складні дії у зрозумілий спосіб. Але оскільки всі iterator-и є ледачими, вам потрібно викликати один із методів адаптера, що споживає, щоб отримати результати з викликів адаптерів iterator.
Замикання, що захоплюють своє середовище
Багато адаптерів iterator приймають замикання як аргументи, і зазвичай замикання, які ми вказуватимемо як аргументи адаптерів iterator, будуть замиканнями, що захоплюють своє середовище.
Для цього прикладу ми використаємо метод filter, який приймає замикання. Замикання отримує елемент з iterator і повертає bool. Якщо замикання повертає true, значення буде включено в ітерацію, створену filter. Якщо замикання повертає false, значення не буде включено.
У Listing 13-16 ми використовуємо filter із замиканням, яке захоплює змінну shoe_size зі свого середовища, щоб ітерувати по колекції екземплярів структури Shoe. Воно поверне лише взуття вказаного розміру.
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}Функція shoes_in_size бере у власність вектор взуття та розмір взуття як параметри. Вона повертає вектор, що містить лише взуття вказаного розміру.
У тілі shoes_in_size ми викликаємо into_iter, щоб створити iterator, який бере вектор у власність. Потім ми викликаємо filter, щоб адаптувати цей iterator у новий iterator, який містить лише елементи, для яких замикання повертає true.
Замикання захоплює параметр shoe_size із середовища та порівнює значення з розміром кожної пари взуття, залишаючи лише взуття вказаного розміру. Нарешті, виклик collect збирає значення, повернуті адаптованим iterator, у вектор, який повертається функцією.
Тест показує, що коли ми викликаємо shoes_in_size, то отримуємо назад лише взуття, яке має той самий розмір, що й вказане нами значення.
Покращення нашого проєкту I/O
Покращення нашого I/O-проєкту
З цим новим знанням про ітератори ми можемо покращити I/O-проєкт у
Розділі 12, використовуючи ітератори, щоб зробити місця в коді зрозумілішими й
лаконічнішими. Давайте подивимося, як ітератори можуть покращити нашу реалізацію
функції Config::build і функції search.
Видалення clone за допомогою ітератора
У Listing 12-6 ми додали код, який брав зріз значень String і створював
екземпляр структури Config, індексуючись у зріз і клонуючи
значення, що дозволяло структурі Config володіти цими значеннями. У Listing 13-17
ми відтворили реалізацію функції Config::build так, як вона була
у Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Тоді ми сказали не хвилюватися через неефективні виклики clone, тому що
ми приберемо їх у майбутньому. Що ж, цей час настав!
Нам був потрібен clone тут, тому що ми маємо зріз з елементами String у
параметрі args, але функція build не володіє args. Щоб повернути
власність над екземпляром Config, нам довелося клонувати значення з полів
query і file_path структури Config, щоб екземпляр Config міг володіти
своїми значеннями.
З нашим новим знанням про ітератори ми можемо змінити функцію build, щоб
брати у володіння ітератор як свій аргумент замість запозичення зрізу.
Ми використаємо функціональність ітератора замість коду, який перевіряє довжину
зрізу та індексується в конкретні місця. Це прояснить, що саме робить функція
Config::build, тому що ітератор отримуватиме доступ до значень.
Щойно Config::build почне брати у володіння ітератор і перестане використовувати
операції індексування, які запозичують, ми зможемо переміщувати значення String
з ітератора в Config замість виклику clone і створення нового виділення.
Безпосереднє використання поверненого ітератора
Відкрийте файл src/main.rs вашого I/O-проєкту, який має виглядати так:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Спочатку ми змінимо початок функції main, який був у Listing
12-24, на код у Listing 13-18, який цього разу використовує ітератор.
Це не скомпілюється, доки ми не оновимо також Config::build.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Функція env::args повертає ітератор! Замість того, щоб збирати
значення ітератора у вектор, а потім передавати зріз до Config::build, тепер
ми передаємо у володіння ітератор, повернений з env::args, безпосередньо до
Config::build.
Далі нам потрібно оновити визначення Config::build. Давайте змінимо
сигнатуру Config::build так, щоб вона виглядала як у Listing 13-19. Це все ще
не скомпілюється, тому що нам потрібно оновити тіло функції.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Документація стандартної бібліотеки для функції env::args показує, що
тип ітератора, який вона повертає, — це std::env::Args, і цей тип реалізує
трейт Iterator та повертає значення String.
Ми оновили сигнатуру функції Config::build так, що
параметр args має узагальнений тип з обмеженнями трейту impl Iterator<Item = String> замість &[String]. Це використання синтаксису impl Trait, яке ми
обговорювали в розділі “Using Traits as Parameters”
Розділу 10, означає, що args може бути будь-яким типом, який реалізує
трейт Iterator і повертає елементи String.
Оскільки ми беремо у володіння args і будемо змінювати args, ітеруючись
по ньому, ми можемо додати ключове слово mut у специфікацію
параметра args, щоб зробити його змінним.
Використання методів трейту Iterator
Далі ми виправимо тіло Config::build. Оскільки args реалізує
трейт Iterator, ми знаємо, що можемо викликати на ньому метод next! Listing 13-20
оновлює код з Listing 12-23, щоб використовувати метод next.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Пам’ятайте, що перше значення у значенні, яке повертає env::args, — це ім’я
програми. Ми хочемо проігнорувати його й дійти до наступного значення, тому спочатку ми викликаємо
next і нічого не робимо з поверненим значенням. Потім ми викликаємо next, щоб отримати
значення, яке хочемо помістити в поле query структури Config. Якщо next повертає
Some, ми використовуємо match, щоб витягти значення. Якщо він повертає None, це означає
що передано недостатньо аргументів, і ми завчасно повертаємо Err. Ми робимо
те саме для значення file_path.
Уточнення коду за допомогою адаптерів ітератора
Ми також можемо скористатися перевагами ітераторів у функції search у нашому I/O
проєкті, яка відтворена тут у Listing 13-21 так, як вона була у Listing 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Ми можемо написати цей код лаконічніше, використовуючи методи адаптера ітератора.
Роблячи так, ми також можемо уникнути змінного проміжного вектора results. Стиль
функціонального програмування надає перевагу мінімізації кількості змінного стану, щоб
зробити код зрозумілішим. Видалення змінного стану може дати змогу майбутньому вдосконаленню
зробити пошук паралельним, тому що нам не доведеться керувати
конкурентним доступом до вектора results. Listing 13-22 показує цю зміну.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Пригадайте, що мета функції search — повернути всі рядки в
contents, які містять query. Подібно до прикладу filter у Listing
13-16, цей код використовує адаптер filter, щоб залишити лише ті рядки, для яких
line.contains(query) повертає true. Потім ми збираємо відповідні рядки в
інший вектор за допомогою collect. Набагато простіше! За бажанням ви можете зробити таку саму зміну,
щоб використовувати методи ітератора також у функції search_case_insensitive.
Для подальшого покращення поверніть ітератор з функції search, прибравши
виклик collect і змінивши тип повернення на impl Iterator<Item = &'a str>, щоб функція стала адаптером ітератора.
Зверніть увагу, що вам також потрібно оновити тести! Пошукайте у великому файлі
за допомогою вашого інструмента minigrep до і після внесення цієї зміни, щоб спостерігати
різницю в поведінці. До цієї зміни програма не друкуватиме жодних результатів
доти, доки не збере всі результати, але після зміни результати
друкуватимуться в міру знаходження кожного відповідного рядка, тому що цикл for
у функції run може скористатися лінивістю ітератора.
Вибір між циклами та ітераторами
Наступне логічне питання — який стиль ви повинні вибрати у власному коді і чому: оригінальну реалізацію в Listing 13-21 чи версію, що використовує ітератори в Listing 13-22 (припускаючи, що ми збираємо всі результати перед поверненням їх, а не повертаємо ітератор). Більшість програмістів Rust віддають перевагу стилю ітератора. Спочатку до нього трохи важче звикнути, але коли ви відчуєте різні адаптери ітератора та те, що вони роблять, ітератори можуть бути зрозумілішими. Замість того, щоб возитися з різними частинами циклу та побудовою нових векторів, код зосереджується на високорівневій меті циклу. Це абстрагує деякий звичайний код, щоб було легше побачити концепції, які є унікальними для цього коду, такі як умова фільтрації, яку кожен елемент в ітераторі повинен пройти.
Але чи є ці дві реалізації справді еквівалентними? Інтуїтивне припущення може бути таким, що нижчорівневий цикл буде швидшим. Давайте поговоримо про продуктивність.
Продуктивність у циклах порівняно з ітераторами
Продуктивність у циклах vs. ітераторах
Щоб визначити, чи використовувати цикли або ітератори, вам потрібно знати, яка
реалізація є швидшою: версія функції search з явним циклом for або версія з ітераторами.
Ми провели benchmark, завантаживши весь вміст Пригоди Шерлока Холмса сера Артура Конана Дойла в String і шукаючи
слово the у вмісті. Ось результати benchmark для
версії search, що використовує цикл for, і версії, що використовує ітератори:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
Дві реалізації мають подібну продуктивність! Ми не будемо пояснювати код benchmark тут, тому що мета не в тому, щоб довести, що дві версії еквівалентні, а в тому, щоб отримати загальне уявлення про те, як ці дві реалізації порівнюються за продуктивністю.
Для більш комплексного benchmark ви повинні перевіряти, використовуючи різні тексти
різного розміру як contents, різні слова та слова різної довжини
як query, і всілякі інші варіації. Суть у тому:
ітератори, хоча й є абстракцією високого рівня, компілюються приблизно в той самий
код, ніби ви написали нижчорівневий код самостійно. Ітератори — це одна
з абстракцій нульової вартості Rust, під чим ми маємо на увазі, що використання цієї абстракції
не накладає жодних додаткових runtime-витрат. Це аналогічно тому, як Б’ярне
Страуструп, оригінальний дизайнер і реалізатор C++, визначає
zero-overhead у своїй ключовій доповіді ETAPS 2012 року “Foundations of C++”:
Загалом, реалізації C++ дотримуються принципу zero-overhead: За те, чим ви не користуєтеся, ви не платите. І далі: Те, чим ви користуєтеся, ви не змогли б вручну написати краще.
У багатьох випадках код Rust, що використовує ітератори, компілюється в той самий assembly, який би ви написали вручну. Такі оптимізації, як розгортання циклів і усунення перевірки обмежень під час доступу до масивів, застосовуються й роблять отриманий код надзвичайно ефективним. Тепер, коли ви це знаєте, ви можете використовувати ітератори та замикання без страху! Вони роблять код схожим на вищорівневий, але не накладають runtime-покарання за це.
Підсумок
Замикання та ітератори — це можливості Rust, натхненні ідеями мов функціонального програмування. Вони сприяють здатності Rust чітко виражати ідеї високого рівня з продуктивністю низького рівня. Реалізації замикань та ітераторів такі, що runtime-продуктивність не зазнає впливу. Це частина мети Rust — прагнути надавати абстракції нульової вартості.
Тепер, коли ми покращили виразність нашого проєкту I/O, давайте розглянемо
деякі інші можливості cargo, які допоможуть нам поділитися проєктом зі
світом.
Більше про Cargo та Crates.io
Дотепер ми використовували лише найосновніші можливості Cargo для збирання, запуску й тестування нашого коду, але він може робити набагато більше. У цьому розділі ми обговоримо деякі з його інших, більш просунутих можливостей, щоб показати вам, як робити таке:
- Налаштовувати вашу збірку через профілі випуску.
- Публікувати бібліотеки на crates.io.
- Організовувати великі проєкти за допомогою робочих просторів.
- Встановлювати бінарні файли з crates.io.
- Розширювати Cargo за допомогою користувацьких команд.
Cargo може робити навіть більше, ніж функціональність, яку ми охоплюємо в цьому розділі, тож для повного пояснення всіх його можливостей дивіться його документацію.
Налаштування збірок за допомогою профілів release
Налаштування збірок за допомогою профілів релізу
У Rust, профілі релізу — це попередньо визначені, налаштовувані профілі з різними конфігураціями, які дають змогу програмісту мати більше контролю над різними параметрами для компіляції коду. Кожен профіль налаштовується незалежно від інших.
Cargo має два основні профілі: профіль dev, який Cargo використовує, коли ви запускаєте cargo build, і профіль release, який Cargo використовує, коли ви запускаєте cargo build --release. Профіль dev визначено з хорошими типовими значеннями для розробки,
а профіль release має хороші типові значення для збірок релізу.
Ці назви профілів можуть бути знайомі з виводу ваших збірок:
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
dev і release — це ці різні профілі, які використовуються компілятором.
Cargo має типові налаштування для кожного з профілів, які застосовуються, коли ви не
додали явно жодних секцій [profile.*] у файл Cargo.toml вашого проєкту.
Додаючи секції [profile.*] для будь-якого профілю, який ви хочете налаштувати, ви
перевизначаєте будь-яку підмножину типових налаштувань. Наприклад, ось типові
значення для налаштування opt-level для профілів dev і release:
Filename: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
Налаштування opt-level керує кількістю оптимізацій, які Rust застосує до
вашого коду, у діапазоні від 0 до 3. Застосування більшої кількості оптимізацій збільшує
час компіляції, тож якщо ви перебуваєте в розробці й часто компілюєте свій код,
ви захочете менше оптимізацій, щоб компілювати швидше, навіть якщо результатний код
працює повільніше. Типове значення opt-level для dev тому — 0. Коли ви
готові випустити свій код, найкраще витратити більше часу на компіляцію. Ви лише
один раз скомпілюєте в режимі release, але запускатимете скомпільовану програму багато разів,
тому режим release обмінює довший час компіляції на код, який працює швидше. Саме
тому типове значення opt-level для профілю release — 3.
Ви можете перевизначити типове налаштування, додавши для нього інше значення в Cargo.toml. Наприклад, якщо ми хочемо використовувати рівень оптимізації 1 у профілі розробки, ми можемо додати ці два рядки до файла Cargo.toml нашого проєкту:
Filename: Cargo.toml
[profile.dev]
opt-level = 1
Цей код перевизначає типове налаштування 0. Тепер, коли ми запускаємо cargo build,
Cargo використовуватиме типові значення для профілю dev плюс наше налаштування
opt-level. Оскільки ми встановили opt-level на 1, Cargo застосує більше
оптимізацій, ніж за замовчуванням, але не так багато, як у збірці release.
Повний список параметрів конфігурації та типових значень для кожного профілю дивіться в документації Cargo.
Публікація крейта на Crates.io
Публікація крейту на Crates.io
Ми використовували пакети з crates.io як залежності нашого проєкту, але ви також можете ділитися своїм кодом з іншими людьми шляхом публікації власних пакетів. Реєстр крейтів на crates.io поширює вихідний код ваших пакетів, тому він передусім розміщує код, який є відкритим.
Rust і Cargo мають можливості, які роблять ваш опублікований пакет простішим для людей у пошуку та використанні. Далі ми поговоримо про деякі з цих можливостей, а потім пояснимо, як опублікувати пакет.
Створення корисних коментарів документації
Точне документування ваших пакетів допоможе іншим користувачам знати, коли і як їх
використовувати, тож варто витратити час на написання документації. У Розділі
3 ми обговорювали, як коментувати код Rust за допомогою двох скісних рисок, //. Rust також має
особливий вид коментарів для документації, відомий, цілком доречно, як
коментар документації, який згенерує HTML-документацію. HTML
відображає вміст коментарів документації для публічних елементів API, призначених
для програмістів, зацікавлених у тому, щоб знати, як використовувати ваш крейт, на відміну від того,
як ваш крейт реалізовано.
Коментарі документації використовують три скісні риски, ///, замість двох і підтримують
синтаксис Markdown для форматування тексту. Розміщуйте коментарі документації безпосередньо
перед елементом, який вони документують. Перелік 14-1 показує коментарі документації
для функції add_one у крейті з назвою my_crate.
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Тут ми наводимо опис того, що робить функція add_one, починаємо
розділ із заголовком Examples, а потім надаємо код, який демонструє,
як використовувати функцію add_one. Ми можемо згенерувати HTML-документацію з
цього коментаря документації, запустивши cargo doc. Ця команда запускає інструмент
rustdoc, що поширюється разом із Rust, і розміщує згенеровану HTML-документацію
у каталозі target/doc.
Для зручності запуск cargo doc --open збудує HTML для документації
вашого поточного крейту (а також документацію для всіх залежностей вашого
крейту) і відкриє результат у веббраузері. Перейдіть до функції
add_one, і ви побачите, як текст у коментарях документації
відтворюється, як показано на Рисунку 14-1.
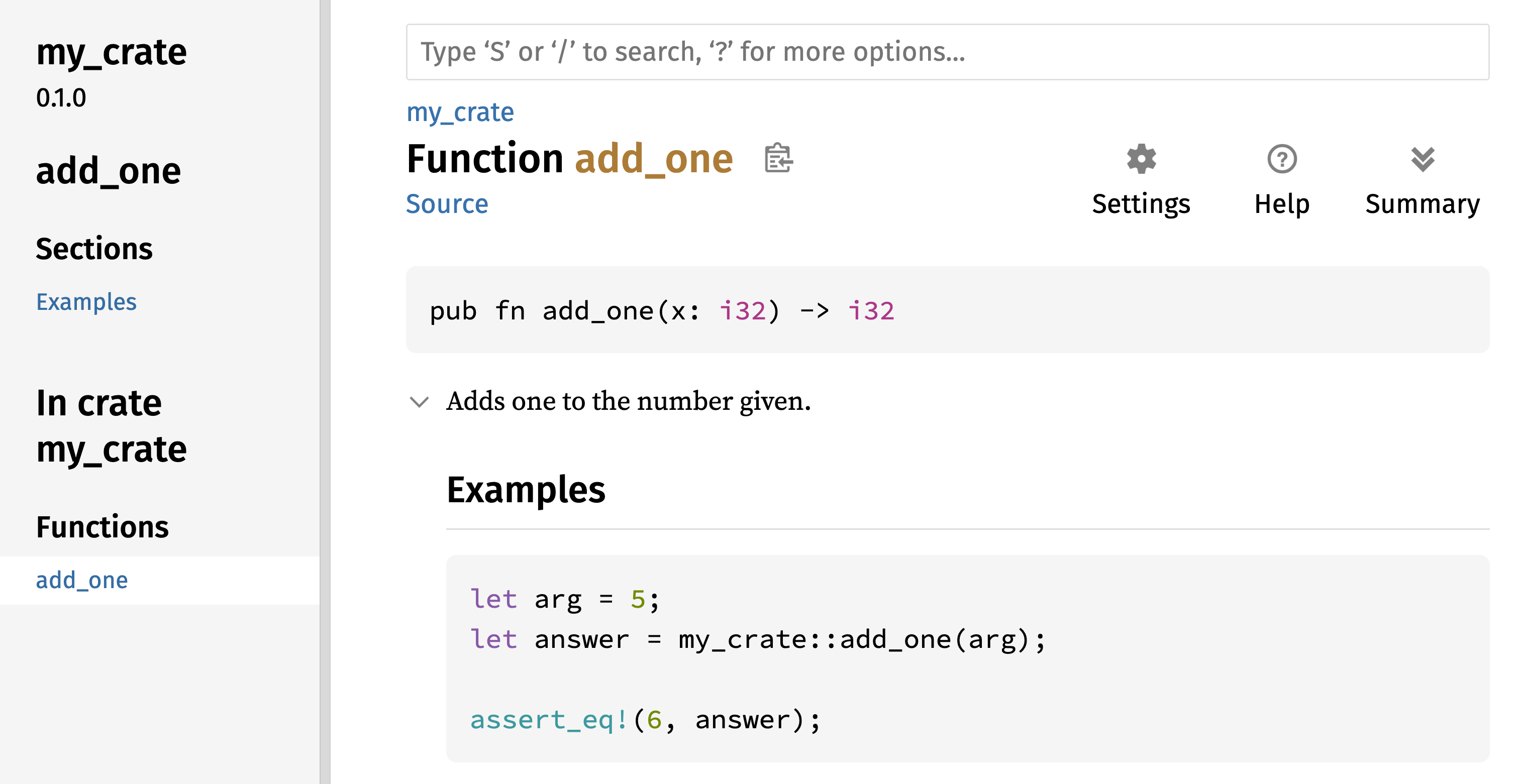
Рисунок 14-1: HTML-документація для функції add_one
Часто використовувані розділи
Ми використали заголовок Markdown # Examples у Переліку 14-1, щоб створити розділ
в HTML із заголовком “Examples.” Ось деякі інші розділи, які автори крейтів
зазвичай використовують у своїй документації:
- Panics: Це сценарії, за яких функція, що документується, може викликати паніку. Виклики функції, які не хочуть, щоб їхні програми викликали паніку, мають переконатися, що вони не викликають функцію в цих ситуаціях.
- Errors: Якщо функція повертає
Result, опис типів помилок, які можуть виникнути, і умов, які можуть спричинити повернення цих помилок, може бути корисним для тих, хто викликає, щоб вони могли писати код для обробки різних типів помилок різними способами. - Safety: Якщо виклик функції є
unsafe(ми обговорюємо unsafety у Розділі 20), має бути розділ, який пояснює, чому функція є unsafe, і охоплює інваріанти, яких функція очікує від викликів дотримуватися.
Більшості коментарів документації не потрібні всі ці розділи, але це добрий чекліст, щоб нагадати вам про аспекти вашого коду, які користувачів зацікавить знати.
Коментарі документації як тести
Додавання блоків прикладів коду у ваші коментарі документації може допомогти продемонструвати,
як використовувати вашу бібліотеку, і має додатковий бонус: запуск cargo test запустить
приклади коду у вашій документації як тести! Немає нічого кращого за
документацію з прикладами. Але немає нічого гіршого за приклади, які не працюють,
бо код змінився відтоді, як документацію було написано. Якщо ми запустимо
cargo test із документацією для функції add_one з Переліку
14-1, ми побачимо розділ у результатах тестів, який виглядає ось так:
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Тепер, якщо ми змінимо або функцію, або приклад так, що assert_eq!
у прикладі викличе паніку, і знову запустимо cargo test, ми побачимо, що doc-тести
виявляють, що приклад і код більше не синхронізовані між собою!
Коментарі для елементів, що містять інші елементи
Стиль коментаря документації //! додає документацію до елемента, який містить
коментарі, а не до елементів, що йдуть після коментарів. Зазвичай ми
використовуємо ці коментарі документації всередині файла кореня крейту (src/lib.rs за домовленістю)
або всередині модуля, щоб документувати крейт або модуль у цілому.
Наприклад, щоб додати документацію, яка описує призначення крейту my_crate,
що містить функцію add_one, ми додаємо коментарі документації, які
починаються з //!, на початок файла src/lib.rs, як показано в Переліку
14-2.
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Зверніть увагу, що після останнього рядка, який починається з //!, немає жодного коду. Оскільки
ми почали коментарі з //! замість ///, ми документуємо елемент,
який містить цей коментар, а не елемент, що йде після цього коментаря. У
цьому випадку цим елементом є файл src/lib.rs, який є коренем крейту. Ці
коментарі описують увесь крейт.
Коли ми запускаємо cargo doc --open, ці коментарі відображатимуться на головній сторінці
документації для my_crate над списком публічних елементів у
крейтіні, як показано на Рисунку 14-2.
Коментарі документації всередині елементів особливо корисні для опису крейтів і модулів. Використовуйте їх, щоб пояснити загальне призначення контейнера, щоб допомогти вашим користувачам зрозуміти організацію крейту.
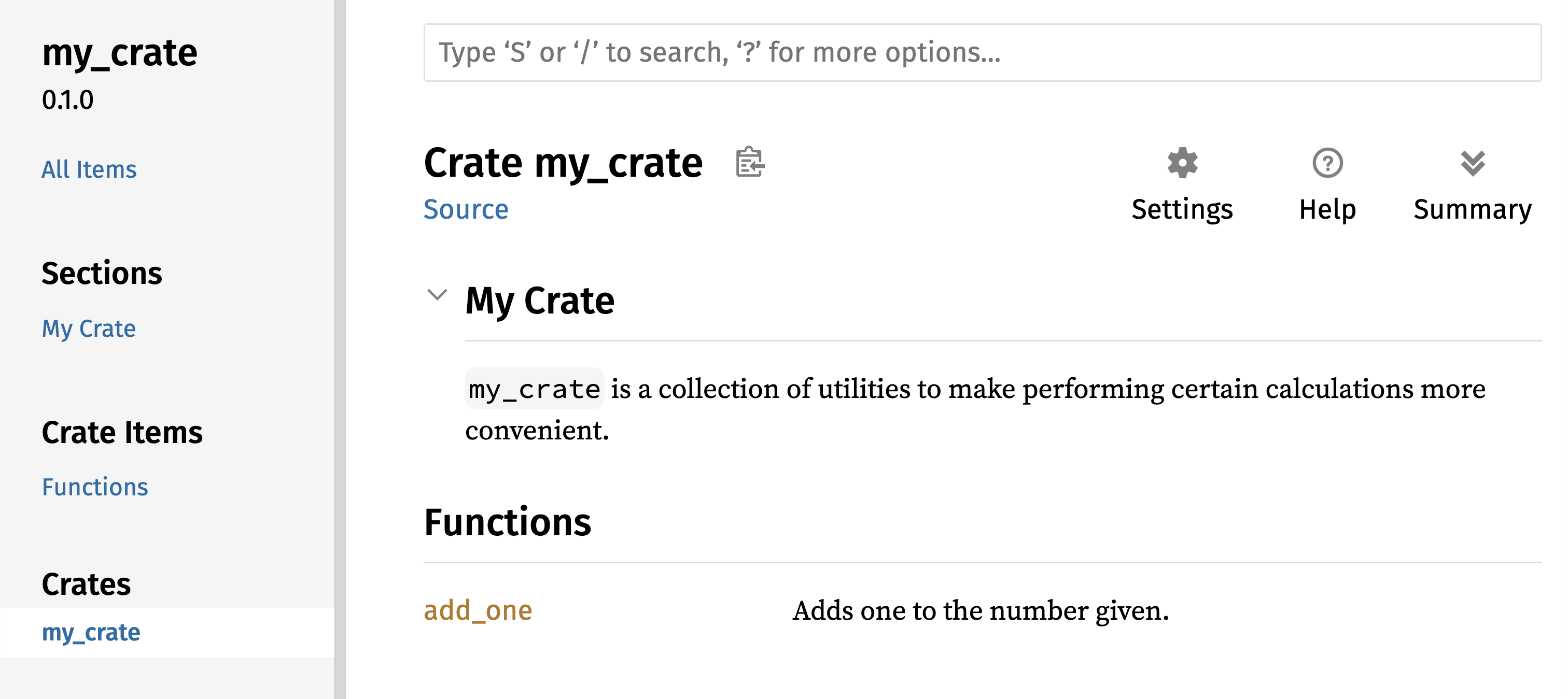
Рисунок 14-2: Відтворена документація для my_crate,
включно з коментарем, що описує крейт у цілому
Експорт зручного публічного API
Структура вашого публічного API є важливим чинником під час публікації крейту. Люди, які використовують ваш крейт, менш знайомі зі структурою, ніж ви, і можуть мати труднощі з пошуком частин, які хочуть використовувати, якщо ваш крейт має велику ієрархію модулів.
У Розділі 7 ми розглянули, як робити елементи публічними за допомогою ключового слова pub, і
як вводити елементи в область видимості за допомогою ключового слова use. Однак структура,
яка має сенс для вас під час розробки крейту, може бути не дуже
зручною для ваших користувачів. Ви можете захотіти організувати свої структури в
ієрархію, що містить кілька рівнів, але тоді людям, які хочуть використовувати тип,
визначений вами глибоко в ієрархії, може бути важко дізнатися, що такий тип
існує. Їм також може не подобатися, що потрібно вводити use my_crate::some_module::another_module::UsefulType; замість use my_crate::UsefulType;.
Добра новина полягає в тому, що якщо структура не є зручною для використання іншими
з іншої бібліотеки, вам не потрібно перебудовувати вашу внутрішню організацію:
замість цього ви можете повторно експортувати елементи, щоб створити публічну структуру, яка відрізняється
від вашої приватної структури, використовуючи pub use. Повторний експорт бере публічний
елемент в одному місці і робить його публічним в іншому місці, ніби він був
визначений у цьому іншому місці.
Наприклад, припустімо, ми створили бібліотеку під назвою art для моделювання художніх концепцій.
Усередині цієї бібліотеки є два модулі: модуль kinds, що містить два переліки
з назвами PrimaryColor і SecondaryColor, та модуль utils, що містить
функцію з назвою mix, як показано в Переліку 14-3.
//! # Art
//!
//! A library for modeling artistic concepts.
pub mod kinds {
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}Рисунок 14-3 показує, як виглядала б головна сторінка документації для цього крейту,
згенерована cargo doc.
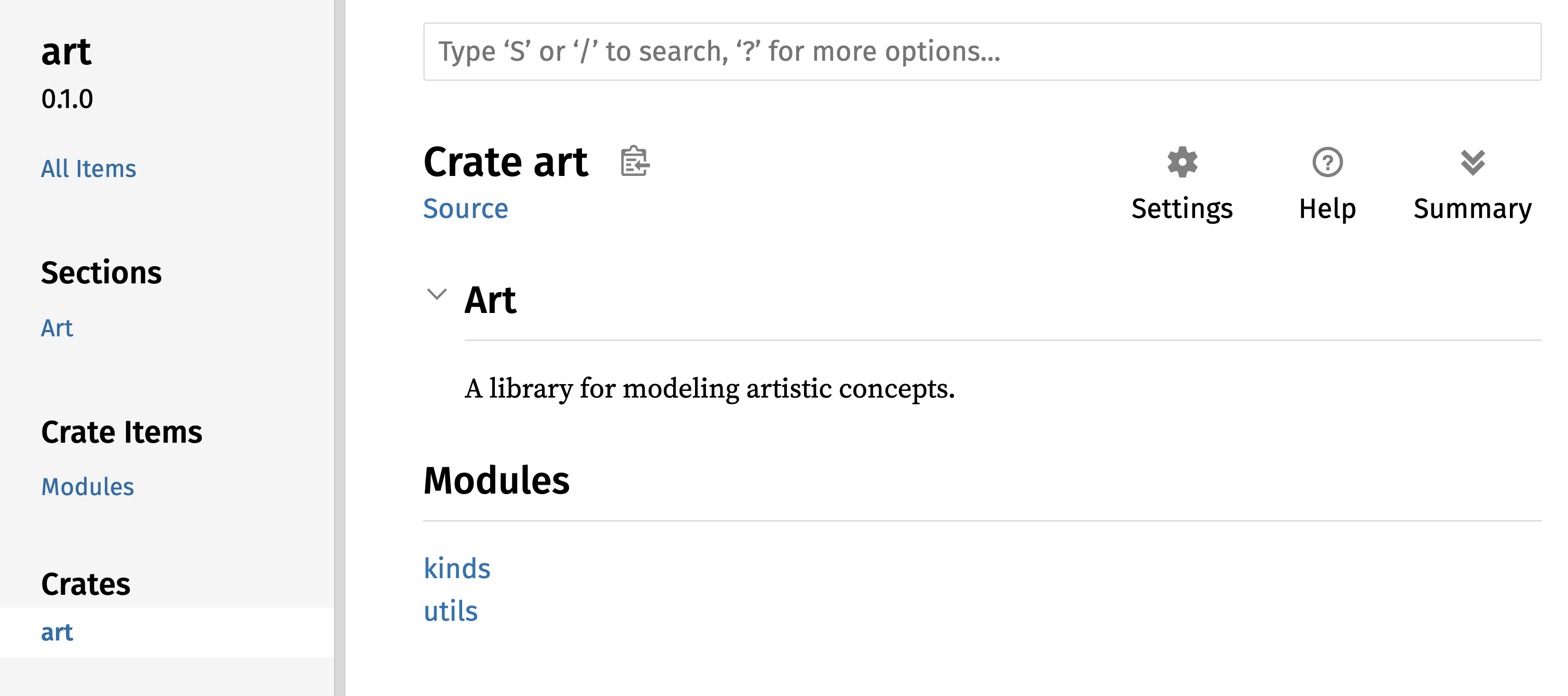
Рисунок 14-3: Головна сторінка документації для art,
яка перелічує модулі kinds і utils
Зверніть увагу, що типи PrimaryColor і SecondaryColor не перелічені на
головній сторінці, як і функція mix. Нам потрібно клацнути kinds і utils, щоб
побачити їх.
Іншому крейту, що залежить від цієї бібліотеки, знадобляться оператори use, які
вводять елементи з art в область видимості, вказуючи поточну визначену
структуру модулів. Перелік 14-4 показує приклад крейту, який використовує
елементи PrimaryColor і mix з крейту art.
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}Автор коду в Переліку 14-4, який використовує крейт art, мав
з’ясувати, що PrimaryColor знаходиться в модулі kinds, а mix — у
модулі utils. Структура модулів крейту art є більш релевантною для
розробників, які працюють над крейтом art, ніж для тих, хто його використовує. Внутрішня
структура не містить жодної корисної інформації для того, хто намагається
зрозуміти, як використовувати крейт art, а радше спричиняє плутанину, тому що
розробники, які його використовують, мають з’ясувати, де шукати, і повинні вказувати
імена модулів в операторах use.
Щоб прибрати внутрішню організацію з публічного API, ми можемо змінити код
крейту art у Переліку 14-3, додавши оператори pub use для повторного експорту
елементів на верхньому рівні, як показано в Переліку 14-5.
//! # Art
//!
//! A library for modeling artistic concepts.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}Документація API, яку cargo doc згенерує для цього крейту, тепер перелічуватиме
і посилатиметься на повторні експорти на головній сторінці, як показано на Рисунку 14-4, роблячи
типи PrimaryColor і SecondaryColor, а також функцію mix простішими для пошуку.
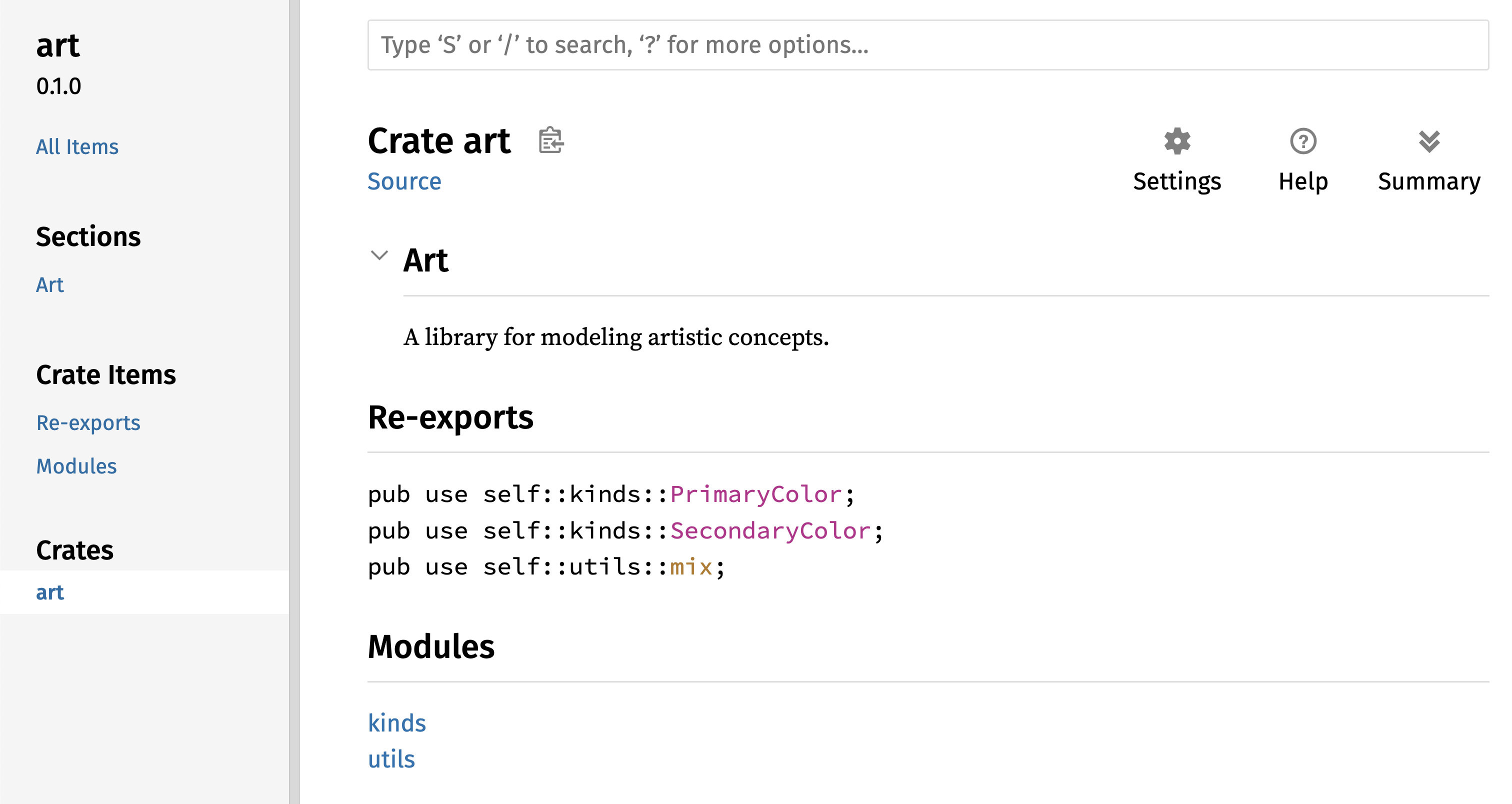
Рисунок 14-4: Головна сторінка документації для art,
яка перелічує повторні експорти
Користувачі крейту art усе ще можуть бачити і використовувати внутрішню структуру з Переліку
14-3, як продемонстровано в Переліку 14-4, або вони можуть використовувати більш зручну
структуру з Переліку 14-5, як показано в Переліку 14-6.
use art::PrimaryColor;
use art::mix;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}У випадках, коли є багато вкладених модулів, повторний експорт типів на верхньому
рівні за допомогою pub use може значно поліпшити досвід людей, які використовують крейт. Інше поширене використання pub use — повторно експортувати
визначення залежності в поточному крейті, щоб зробити ці визначення частиною публічного API вашого крейту.
Створення корисної структури публічного API — це більше мистецтво, ніж наука, і
ви можете ітерувати, щоб знайти API, який найкраще працює для ваших користувачів. Вибір pub use
дає вам гнучкість у тому, як ви структуруєте свій крейт внутрішньо, і відокремлює
цю внутрішню структуру від того, що ви показуєте своїм користувачам. Подивіться на деякий
код крейтів, які ви встановили, щоб побачити, чи відрізняється їхня внутрішня структура
від їхнього публічного API.
Налаштування облікового запису на Crates.io
Перш ніж ви зможете публікувати будь-які крейти, вам потрібно створити обліковий запис на
crates.io і отримати API token. Для цього
відвідайте головну сторінку на crates.io і увійдіть
через обліковий запис GitHub. (Обліковий запис GitHub наразі є обов’язковою вимогою, але
сайт може підтримувати інші способи створення облікового запису в майбутньому.) Після того як
ви ввійдете, перейдіть до налаштувань свого облікового запису на
https://crates.io/me/ і отримайте свій
API key. Потім запустіть команду cargo login і вставте свій API key, коли буде запропоновано, ось так:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
Ця команда повідомить Cargo про ваш API token і збереже його локально у ~/.cargo/credentials.toml. Зверніть увагу, що цей token є секретом: не діліться ним з кимось іншим. Якщо ви все ж поділитеся ним з кимось з будь-якої причини, ви повинні негайно відкликати його і згенерувати новий token на crates.io.
Додавання метаданих до нового крейту
Припустімо, у вас є крейт, який ви хочете опублікувати. Перед публікацією вам потрібно буде
додати деякі метадані в розділ [package] файла Cargo.toml
крейту.
Ваш крейт потребуватиме унікальної назви. Поки ви працюєте над крейтом локально,
ви можете назвати крейт як завгодно. Однак назви крейтів на
crates.io розподіляються за принципом «хто перший прийшов, того й обслужили». Як тільки назву крейту
зайнято, ніхто інший не може опублікувати крейт із цією назвою. Перед спробою
опублікувати крейт, знайдіть назву, яку хочете використовувати. Якщо назву вже
використано, вам потрібно буде знайти іншу назву і відредагувати поле name у файлі Cargo.toml у
розділі [package], щоб використовувати нову назву для публікації, ось так:
Filename: Cargo.toml
[package]
name = "guessing_game"
Навіть якщо ви вибрали унікальну назву, коли ви зараз запустите cargo publish, щоб опублікувати
крейт, ви отримаєте попередження, а потім помилку:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
Це завершується помилкою, тому що вам бракує деякої критично важливої інформації: Потрібні
опис і ліцензія, щоб люди знали, що робить ваш крейт і на яких
умовах вони можуть його використовувати. У Cargo.toml додайте опис, який є лише одним або двома реченнями, тому що
він відображатиметься разом із вашим крейтом у результатах пошуку. Для поля license вам потрібно
вказати значення ідентифікатора ліцензії. Software Package Data Exchange (SPDX) Фонду Linux
перелічує ідентифікатори, які ви можете використовувати для цього значення. Наприклад, щоб указати, що
ви ліцензували свій крейт за ліцензією MIT, додайте ідентифікатор MIT:
Filename: Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
Якщо ви хочете використовувати ліцензію, якої немає в SPDX, вам потрібно розмістити
текст цієї ліцензії у файлі, включити цей файл у ваш проєкт, а потім
використати license-file, щоб указати ім’я цього файла замість використання
ключа license.
Роз’яснення того, яка ліцензія підходить для вашого проєкту, виходить за межі
цієї книги. Багато людей у спільноті Rust ліцензують свої проєкти
так само, як Rust, використовуючи подвійну ліцензію MIT OR Apache-2.0. Ця практика
демонструє, що ви також можете вказати кілька ідентифікаторів ліцензій, розділених
OR, щоб мати кілька ліцензій для вашого проєкту.
З унікальною назвою, версією, вашим описом і доданою ліцензією, файл Cargo.toml для проєкту, який готовий до публікації, може виглядати так:
Filename: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
description = "A fun game where you guess what number the computer has chosen."
license = "MIT OR Apache-2.0"
[dependencies]
Документація Cargo описує інші метадані, які ви можете вказати, щоб інші могли легше знаходити і використовувати ваш крейт.
Публікація на Crates.io
Тепер, коли ви створили обліковий запис, зберегли свій API token, вибрали назву для вашого крейту і вказали необхідні метадані, ви готові до публікації! Публікація крейту завантажує певну версію на crates.io для використання іншими.
Будьте обережні, тому що публікація є незворотною. Версію ніколи не можна перезаписати, а код не може бути видалений, окрім певних обставин. Одна з головних цілей Crates.io — діяти як постійний архів коду, щоб збірки всіх проєктів, що залежать від крейтів з crates.io, продовжували працювати. Дозвіл видалення версій унеможливив би досягнення цієї мети. Однак кількість версій крейту, які ви можете опублікувати, не обмежена.
Запустіть команду cargo publish ще раз. Тепер вона має виконатися успішно:
$ cargo publish
Updating crates.io index
Packaging guessing_game v0.1.0 (file:///projects/guessing_game)
Packaged 6 files, 1.2KiB (895.0B compressed)
Verifying guessing_game v0.1.0 (file:///projects/guessing_game)
Compiling guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading guessing_game v0.1.0 (file:///projects/guessing_game)
Uploaded guessing_game v0.1.0 to registry `crates-io`
note: waiting for `guessing_game v0.1.0` to be available at registry
`crates-io`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published guessing_game v0.1.0 at registry `crates-io`
Вітаємо! Тепер ви поділилися своїм кодом зі спільнотою Rust, і будь-хто може легко додати ваш крейт як залежність свого проєкту.
Публікація нової версії наявного крейту
Коли ви внесли зміни до свого крейту і готові випустити нову версію,
ви змінюєте значення version, указанe у вашому файлі Cargo.toml, і
публікуєте повторно. Використовуйте правила семантичного версіонування, щоб вирішити, яким
має бути наступний номер версії, на основі типів змін, які ви внесли.
Потім запустіть cargo publish, щоб завантажити нову версію.
Виведення версій з ужитку на Crates.io
Хоча ви не можете видалити попередні версії крейту, ви можете запобігти тому, щоб будь-які майбутні проєкти додавали їх як нову залежність. Це корисно, коли версія крейту зламана з тієї чи іншої причини. У таких ситуаціях Cargo підтримує yank версії крейту.
Yanking версії запобігає тому, щоб нові проєкти залежали від цієї версії, водночас дозволяючи всім наявним проєктам, які від неї залежать, продовжувати роботу. По суті, yank означає, що всі проєкти з Cargo.lock не зламаються, а будь-які майбутні файли Cargo.lock, які будуть згенеровані, не використовуватимуть yanked версію.
Щоб зробити yank версії крейту, у каталозі крейту, який ви
раніше опублікували, запустіть cargo yank і вкажіть, яку саме версію ви хочете
yankнути. Наприклад, якщо ми опублікували крейт із назвою guessing_game версії
1.0.1 і хочемо зробити її yank, тоді ми запустимо таке в каталозі проєкту
для guessing_game:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank guessing_game@1.0.1
Додавши --undo до команди, ви також можете скасувати yank і дозволити проєктам
знову почати залежати від цієї версії:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank guessing_game@1.0.1
Yank не видаляє жодного коду. Він не може, наприклад, видалити випадково завантажені секрети. Якщо це сталося, ви повинні негайно скинути ці секрети.
Робочі простори Cargo
Робочі області Cargo
У розділі 12 ми зібрали пакет, який включав бінарний крейт і бібліотечний крейт. У міру розвитку вашого проєкту ви можете виявити, що бібліотечний крейт продовжує зростати, і ви хочете далі розділити ваш пакет на кілька бібліотечних крейтів. Cargo пропонує можливість, яка називається робочі області (workspaces), що може допомогти керувати кількома пов’язаними пакетами, які розробляються одночасно.
Створення робочої області
Робоча область — це набір пакетів, які спільно використовують один і той самий Cargo.lock і каталог виводу. Давайте створимо проєкт із використанням робочої області — ми використаємо тривіальний код, щоб могли зосередитися на структурі робочої області. Є кілька способів структурувати робочу область, тому ми покажемо лише один поширений спосіб. У нас буде робоча область, що міститиме бінарний крейт і два бібліотечні крейти. Бінарний крейт, який надаватиме основну функціональність, залежатиме від двох бібліотек. Одна бібліотека надаватиме функцію add_one, а інша бібліотека — функцію add_two. Ці три крейти будуть частиною однієї й тієї самої робочої області. Почнемо зі створення нового каталогу для робочої області:
$ mkdir add
$ cd add
Далі в каталозі add ми створюємо файл Cargo.toml, який налаштовуватиме всю робочу область. У цьому файлі не буде секції [package]. Натомість він починатиметься з секції [workspace], яка дозволить нам додавати учасників до робочої області. Також ми спеціально використаємо найновіший і найкращий алгоритм розв’язувача Cargo у нашій робочій області, встановивши значення resolver у "3":
Filename: Cargo.toml
[workspace]
resolver = "3"
Далі ми створимо бінарний крейт adder, запустивши cargo new всередині каталогу add:
$ cargo new adder
Created binary (application) `adder` package
Adding `adder` as member of workspace at `file:///projects/add`
Запуск cargo new всередині робочої області також автоматично додає щойно створений пакет до ключа members у визначенні [workspace] у кореневому Cargo.toml робочої області, ось так:
[workspace]
resolver = "3"
members = ["adder"]
На цьому етапі ми можемо зібрати робочу область, запустивши cargo build. Файли у вашому каталозі add мають виглядати так:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Робоча область має один каталог target на верхньому рівні, куди будуть поміщені зібрані артефакти; пакет adder не має власного каталогу target. Навіть якщо ми запустимо cargo build із каталогу adder, зібрані артефакти все одно опиняться в add/target, а не в add/adder/target. Cargo структурує каталог target у робочій області саме так, тому що крейти в робочій області призначені для того, щоб залежати один від одного. Якби кожен крейт мав власний каталог target, кожному крейту довелося б перекомпілювати кожен інший крейт у робочій області, щоб помістити артефакти у свій власний каталог target. Спільне використання одного каталогу target дозволяє крейтам уникати непотрібної повторної збірки.
Створення другого пакета в робочій області
Далі створімо ще один пакет-учасник у робочій області й назвімо його add_one. Згенеруйте новий бібліотечний крейт із назвою add_one:
$ cargo new add_one --lib
Created library `add_one` package
Adding `add_one` as member of workspace at `file:///projects/add`
Кореневий Cargo.toml тепер включатиме шлях add_one у список members:
Filename: Cargo.toml
[workspace]
resolver = "3"
members = ["adder", "add_one"]
Тепер ваш каталог add має такі каталоги й файли:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
У файлі add_one/src/lib.rs додаймо функцію add_one:
Filename: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}Тепер ми можемо зробити так, щоб пакет adder із нашим бінарним крейтом залежав від пакета add_one, у якому є наша бібліотека. Спочатку нам потрібно буде додати залежність за шляхом на add_one до adder/Cargo.toml.
Filename: adder/Cargo.toml
[dependencies]
add_one = { path = "../add_one" }
Cargo не припускає, що крейти в робочій області залежатимуть один від одного, тому нам потрібно явно вказати залежності між ними.
Далі давайте використаємо функцію add_one (з крейту add_one) у крейті adder. Відкрийте файл adder/src/main.rs і змініть функцію main, щоб вона викликала функцію add_one, як у Переліку 14-7.
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
}Давайте збудуємо робочу область, запустивши cargo build у верхньому каталозі add!
$ cargo build
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
Щоб запустити бінарний крейт із каталогу add, ми можемо вказати, який пакет у робочій області хочемо запустити, використавши аргумент -p і назву пакета з cargo run:
$ cargo run -p adder
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/adder`
Hello, world! 10 plus one is 11!
Це запускає код у adder/src/main.rs, який залежить від крейту add_one.
Залежність від зовнішнього пакета
Зверніть увагу, що робоча область має лише один файл Cargo.lock на верхньому рівні, а не по одному Cargo.lock у каталозі кожного крейту. Це гарантує, що всі крейти використовують одну й ту саму версію всіх залежностей. Якщо ми додамо пакет rand до файлів adder/Cargo.toml і add_one/Cargo.toml, Cargo розв’яже обидва з них до однієї версії rand і запише це в один Cargo.lock. Використання однакових залежностей для всіх крейтів у робочій області означає, що крейти завжди будуть сумісні один з одним. Додаймо крейт rand до секції [dependencies] у файлі add_one/Cargo.toml, щоб ми могли використовувати крейт rand у крейті add_one:
Filename: add_one/Cargo.toml
[dependencies]
rand = "0.8.5"
Тепер ми можемо додати use rand; до файлу add_one/src/lib.rs, і побудова всієї робочої області шляхом запуску cargo build у каталозі add підтягне й скомпілює крейт rand. Ми отримаємо одне попередження, тому що не звертаємося до rand, який ми ввели в область видимості:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling add_one v0.1.0 (file:///projects/add/add_one)
warning: unused import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `add_one` (lib) generated 1 warning (run `cargo fix --lib -p add_one` to apply 1 suggestion)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
Кореневий Cargo.lock тепер містить інформацію про залежність add_one від rand. Однак, навіть якщо rand використовується десь у робочій області, ми не можемо використовувати його в інших крейтах у робочій області, якщо не додамо rand і до їхніх файлів Cargo.toml. Наприклад, якщо ми додамо use rand; до файлу adder/src/main.rs для пакета adder, ми отримаємо помилку:
$ cargo build
--snip--
Compiling adder v0.1.0 (file:///projects/add/adder)
error[E0432]: unresolved import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Щоб виправити це, відредагуйте файл Cargo.toml для пакета adder і вкажіть, що rand є також його залежністю. Збирання пакета adder додасть rand до списку залежностей для adder у Cargo.lock, але жодних додаткових копій rand не буде завантажено. Cargo гарантує, що кожен крейт у кожному пакеті в робочій області, який використовує пакет rand, використовуватиме ту саму версію, доки вони вказують сумісні версії rand, заощаджуючи нам місце й забезпечуючи сумісність крейтів у робочій області один з одним.
Якщо крейти в робочій області вказують несумісні версії однієї й тієї самої залежності, Cargo розв’яже кожну з них, але все одно намагатиметься розв’язати якомога менше версій.
Додавання тесту до робочої області
Для ще одного вдосконалення давайте додамо тест функції add_one::add_one у крейті add_one:
Filename: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}Тепер запустіть cargo test у верхньому каталозі add. Запуск cargo test у робочій області, структурованій так, як ця, запустить тести для всіх крейтів у робочій області:
$ cargo test
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/adder-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Перша секція виводу показує, що тест it_works у крейті add_one пройшов. Наступна секція показує, що в крейті adder не було знайдено жодного тесту, а остання секція показує, що в крейті add_one не було знайдено жодного документаційного тесту.
Ми також можемо запускати тести для одного конкретного крейту в робочій області з верхнього каталогу, використовуючи прапорець -p і вказуючи назву крейту, який ми хочемо протестувати:
$ cargo test -p add_one
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Цей вивід показує, що cargo test запустив лише тести для крейту add_one і не запускав тести крейту adder.
Якщо ви публікуєте крейти в робочій області на crates.io, кожен крейт у робочій області доведеться публікувати окремо. Як і для cargo test, ми можемо опублікувати певний крейт у нашій робочій області, використовуючи прапорець -p і вказуючи назву крейту, який ми хочемо опублікувати.
Для додаткової практики додайте крейт add_two до цієї робочої області подібним чином, як і крейт add_one!
У міру того як ваш проєкт зростає, розгляньте використання робочої області: вона дає змогу працювати з меншими, легшими для розуміння компонентами, а не з одним великим блоком коду. Крім того, спільне використання крейтів у робочій області може полегшити координацію між крейтами, якщо вони часто змінюються одночасно.
Встановлення бінарних файлів за допомогою cargo install
Встановлення бінарних файлів за допомогою cargo install
Команда cargo install дає змогу встановлювати та використовувати бінарні крейти
локально. Це не призначено для заміни системних пакетів; це має бути
зручним способом для розробників Rust встановлювати інструменти, якими інші поділилися на
crates.io. Зверніть увагу, що ви можете встановлювати лише
пакети, які мають бінарні цілі. Бінарна ціль — це програма, яку можна виконати і яка
створюється, якщо крейт має файл src/main.rs або інший файл, указаний
як бінарний, на відміну від цілі бібліотеки, яку не можна виконати саму по собі, але
яка придатна для включення в інші програми. Зазвичай у файлі README крейти мають
інформацію про те, чи є крейт бібліотекою, чи має
бінарну ціль, чи і те, і інше.
Усі бінарні файли, встановлені за допомогою cargo install, зберігаються в папці bin
кореня встановлення. Якщо ви встановили Rust за допомогою rustup.rs і не маєте
жодних власних конфігурацій, цей каталог буде $HOME/.cargo/bin. Переконайтеся,
що цей каталог є у вашому $PATH, щоб мати змогу запускати програми, які ви встановили
за допомогою cargo install.
Наприклад, у розділі 12 ми згадували, що існує реалізація Rust
інструмента grep, яка називається ripgrep, для пошуку у файлах. Щоб встановити ripgrep,
ми можемо виконати таке:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--snip--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
Передостанній рядок виводу показує розташування та назву
встановленого бінарного файлу, яким у випадку ripgrep є rg. Поки
каталог встановлення є у вашому $PATH, як зазначалося раніше, ви можете
потім виконати rg --help і почати використовувати швидший, більш Rust-орієнтований інструмент для пошуку у файлах!
Розширення Cargo за допомогою власних команд
Розширення Cargo за допомогою користувацьких команд
Cargo спроєктовано так, щоб ви могли розширювати його новими підкомандами, не
потребуючи його модифікувати. Якщо бінарний файл у вашому $PATH називається cargo-something, ви можете
запустити його так, ніби це підкоманда Cargo, виконавши cargo something. Користувацькі
команди на кшталт цієї також перелічуються, коли ви запускаєте cargo --list. Можливість
використовувати cargo install для встановлення розширень, а потім запускати їх так само, як
вбудовані інструменти Cargo, — це надзвичайно зручна перевага дизайну Cargo!
Підсумок
Спільне використання коду з Cargo та crates.io є частиною того, що робить екосистему Rust корисною для багатьох різних завдань. Стандартна бібліотека Rust невелика та стабільна, але крейти легко ділити, використовувати й покращувати в часовій шкалі, відмінній від часової шкали мови. Не соромтеся ділитися кодом, корисним для вас, на crates.io; імовірно, він буде корисним і комусь іншому!
Розумні вказівники (smart pointers)
Вказівник — це загальне поняття для змінної, яка містить адресу в
пам’яті. Ця адреса посилається на деякі інші дані, або «вказує на» них. Найбільш
поширеним видом вказівника в Rust є посилання, про яке ви дізналися в
Розділі 4. Посилання позначаються символом & і запозичують значення, на яке вони
вказують. Вони не мають жодних особливих можливостей, окрім посилання на
дані, і не мають накладних витрат.
Розумні вказівники (smart pointers), з іншого боку, — це структури даних, які поводяться як вказівник, але також мають додаткові метадані та можливості. Концепція розумних вказівників не є унікальною для Rust: розумні вказівники походять із C++ і існують також в інших мовах. Rust має різноманітні розумні вказівники, визначені в стандартній бібліотеці, які надають функціональність понад ту, що надається посиланнями. Щоб дослідити загальне поняття, ми розглянемо кілька різних прикладів розумних вказівників, зокрема тип розумного вказівника з підрахунком посилань (reference counting). Цей вказівник дає змогу дозволити даним мати кількох власників, відстежуючи кількість власників і, коли не залишається жодного власника, очищаючи дані.
У Rust, з його поняттями власності та запозичення, існує додаткова різниця між посиланнями та розумними вказівниками: тоді як посилання лише запозичують дані, у багатьох випадках розумні вказівники володіють даними, на які вони вказують.
Розумні вказівники зазвичай реалізуються за допомогою структур. На відміну від звичайної
структури, розумні вказівники реалізують трейти Deref і Drop. Трейт Deref
дає змогу екземпляру структури розумного вказівника поводитися як посилання,
щоб ви могли писати свій код так, щоб він працював або з посиланнями, або з розумними
вказівниками. Трейт Drop дає змогу вам налаштовувати код, який запускається, коли
екземпляр розумного вказівника виходить з області видимості. У цьому розділі ми обговоримо
обидва ці трейти та продемонструємо, чому вони важливі для розумних вказівників.
З огляду на те, що шаблон розумного вказівника є загальним шаблоном проєктування, який часто використовується в Rust, цей розділ не охопить кожен наявний розумний вказівник. Багато бібліотек мають власні розумні вказівники, і ви навіть можете написати свій. Ми розглянемо найпоширеніші розумні вказівники у стандартній бібліотеці:
Box<T>, для розміщення значень у купіRc<T>, тип із підрахунком посилань, який дає змогу мати множинну власністьRef<T>іRefMut<T>, доступ до яких здійснюється черезRefCell<T>, тип, що забезпечує правила запозичення під час виконання, а не під час компіляції
Крім того, ми розглянемо шаблон внутрішньої змінності (interior mutability), де незмінний тип надає API для змінювання внутрішнього значення. Ми також обговоримо цикли посилань: як вони можуть призводити до витоку пам’яті та як цьому запобігти.
Тож занурмося в це!
Використання Box<T> для вказування на дані в купі
Використання Box<T> для вказування на дані в купі (heap)
Найпростіший розумний вказівник — це box, тип якого записується як
Box<T>. Boxes дають змогу зберігати дані в купі, а не у стеку.
У стеку залишається вказівник на дані в купі. Зверніться до розділу 4,
щоб повторити різницю між стеком і купою.
Boxes не мають накладних витрат на продуктивність, окрім зберігання своїх даних у купі замість стеку. Але вони також не мають багатьох додаткових можливостей. Ви найчастіше використовуватимете їх у таких ситуаціях:
- Коли ви маєте тип, розмір якого неможливо знати під час компіляції, і хочете використати значення цього типу в контексті, який вимагає точного розміру
- Коли ви маєте велику кількість даних і хочете передати власність, але переконатися, що під час цього дані не буде скопійовано
- Коли ви хочете володіти значенням і вам важливо лише, щоб це був тип, який реалізує певний трейт, а не конкретний тип
Ми продемонструємо першу ситуацію в “Увімкнення рекурсивних типів за допомогою Boxes”. У другому випадку передавання власності на велику кількість даних може зайняти багато часу, тому що дані копіюються по стеку. Щоб поліпшити продуктивність у цій ситуації, ми можемо зберігати велику кількість даних у купі в box. Тоді лише невелика кількість даних вказівника копіюється по стеку, тоді як дані, на які він посилається, залишаються в одному місці в купі. Третій випадок відомий як трейт-об’єкт, і “Використання трейт-об’єктів для абстрагування над спільною поведінкою” у розділі 18 присвячений цій темі. Отже, те, що ви дізнаєтеся тут, ви знову застосуєте в тому розділі!
Зберігання даних у купі
Перш ніж ми обговоримо випадок використання Box<T> для зберігання в купі,
ми розглянемо синтаксис і те, як взаємодіяти зі значеннями, що зберігаються
всередині Box<T>.
У переліку 15-1 показано, як використовувати box для зберігання значення
i32 у купі.
fn main() {
let b = Box::new(5);
println!("b = {b}");
}Ми визначаємо змінну b так, щоб вона мала значення Box, який вказує на
значення 5, розміщене в купі. Ця програма виведе b = 5; у цьому випадку
ми можемо отримати доступ до даних у box подібно до того, як ми зробили б це,
якби ці дані були в стеку. Як і будь-яке значення, що ним володіють, коли box
виходить з області видимості, як це відбувається з b наприкінці main, він
буде звільнений. Звільнення відбувається і для box (який зберігається у
стеку), і для даних, на які він вказує (які зберігаються в купі).
Поміщення одного значення в купу не дуже корисне, тому ви нечасто
використовуватимете boxes самі по собі таким чином. У більшості ситуацій
більш доречним є зберігання таких значень, як одне i32, у стеку, де вони за
замовчуванням і зберігаються. Розгляньмо випадок, у якому boxes дають нам
змогу визначати типи, які ми не мали б права визначити, якби в нас не було
boxes.
Увімкнення рекурсивних типів за допомогою Boxes
Значення рекурсивного типу може містити інше значення того самого типу як частину себе. Рекурсивні типи створюють проблему, тому що Rust потрібно знати під час компіляції, скільки місця займає тип. Однак вкладеність значень рекурсивних типів теоретично може продовжуватися нескінченно, тож Rust не може знати, скільки місця потребує значення. Оскільки boxes мають відомий розмір, ми можемо увімкнути рекурсивні типи, вставивши box у визначення рекурсивного типу.
Як приклад рекурсивного типу, розгляньмо cons list. Це тип даних, який зазвичай зустрічається у функціональних мовах програмування. Тип cons list, який ми визначимо, є простим, окрім рекурсії; отже, концепції в прикладі, який ми розглядатимемо, будуть корисні щоразу, коли ви зіткнетеся з більш складними ситуаціями, пов’язаними з рекурсивними типами.
Розуміння Cons List
Cons list — це структура даних, що походить із мови програмування Lisp та її
діалектів, складається зі вкладених пар і є версією зв’язаного списку в Lisp.
Назва походить від функції cons (скорочення від construct function) у
Lisp, яка створює нову пару зі своїх двох аргументів. Викликаючи cons для
пари, що складається зі значення та іншої пари, ми можемо будувати cons lists,
які складаються з рекурсивних пар.
Наприклад, ось псевдокодове представлення cons list, що містить список 1, 2, 3, де кожна пара подана в дужках:
(1, (2, (3, Nil)))
Кожен елемент cons list містить два елементи: значення поточного елемента та
значення наступного елемента. Останній елемент у списку містить лише значення,
яке називається Nil, без наступного елемента. Cons list утворюється
рекурсивним викликом функції cons. Загальноприйнята назва для позначення
базового випадку рекурсії — Nil. Зауважте, що це не те саме, що концепція
“null” або “nil”, про яку йшлося в розділі 6, яка є недійсним або відсутнім
значенням.
Cons list не є поширено використовуваною структурою даних у Rust. У більшості
випадків, коли у вас є список елементів у Rust, кращим вибором є Vec<T>.
Інші, складніші рекурсивні типи даних дійсно корисні в різних ситуаціях, але
починаючи з cons list у цьому розділі, ми можемо дослідити, як boxes дають
нам змогу визначати рекурсивний тип даних без особливих відволікань.
У переліку 15-2 міститься визначення enum для cons list. Зауважте, що цей код
ще не скомпілюється, тому що тип List не має відомого розміру, що ми й
продемонструємо.
enum List {
Cons(i32, List),
Nil,
}
fn main() {}Примітка: Ми реалізуємо cons list, який містить лише значення
i32, для цілей цього прикладу. Ми могли б реалізувати його за допомогою generics, як ми обговорювали в розділі 10, щоб визначити тип cons list, який міг би зберігати значення будь-якого типу.
Використання типу List для зберігання списку 1, 2, 3 виглядало б як код у
переліку 15-3.
enum List {
Cons(i32, List),
Nil,
}
// --snip--
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}Перше значення Cons містить 1 і ще одне значення List. Це значення
List є ще одним значенням Cons, яке містить 2 і ще одне значення List.
Це значення List є ще одним значенням Cons, яке містить 3 і значення
List, яке нарешті є Nil, нерекурсивним варіантом, що сигналізує про
кінець списку.
Якщо ми спробуємо скомпілювати код у переліку 15-3, отримаємо помилку, показану в переліку 15-4.
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
У повідомленні про помилку показано, що цей тип “has infinite size”. Причина
полягає в тому, що ми визначили List з варіантом, який є рекурсивним: він
безпосередньо містить інше значення самого себе. У результаті Rust не може
визначити, скільки місця йому потрібно для зберігання значення List.
Розберімо, чому ми отримуємо цю помилку. Спочатку ми подивимося, як Rust
визначає, скільки місця йому потрібно для зберігання значення нерекурсивного
типу.
Обчислення розміру нерекурсивного типу
Згадайте enum Message, який ми визначили в переліку 6-2, коли обговорювали
визначення enum у розділі 6:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}Щоб визначити, скільки місця виділити для значення Message, Rust проходить
кожен з варіантів, щоб побачити, який варіант потребує найбільше місця. Rust
бачить, що Message::Quit не потребує жодного місця, Message::Move
потребує достатньо місця для зберігання двох значень i32, і так далі.
Оскільки буде використано лише один варіант, найбільше місця, яке знадобиться
значенню Message, — це місце, потрібне для зберігання найбільшого з його
варіантів.
Порівняйте це з тим, що відбувається, коли Rust намагається визначити, скільки
місця потребує рекурсивний тип, такий як enum List у переліку 15-2.
Компілятор починає з варіанта Cons, який містить значення типу i32 і
значення типу List. Отже, Cons потребує обсяг місця, що дорівнює розміру
i32 плюс розмір List. Щоб визначити, скільки пам’яті потребує тип List,
компілятор розглядає варіанти, починаючи з варіанта Cons. Варіант Cons
містить значення типу i32 і значення типу List, і цей процес триває
нескінченно, як показано на рисунку 15-1.

Рисунок 15-1: Нескінченний List, що складається з
нескінченних варіантів Cons
Отримання рекурсивного типу з відомим розміром
Оскільки Rust не може визначити, скільки місця виділити для рекурсивно визначених типів, компілятор видає помилку з такою корисною підказкою:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
У цій підказці indirection означає, що замість безпосереднього зберігання значення ми повинні змінити структуру даних так, щоб зберігати значення непрямо, тобто зберігаючи замість нього вказівник на значення.
Оскільки Box<T> є вказівником, Rust завжди знає, скільки місця потребує
Box<T>: розмір вказівника не змінюється залежно від обсягу даних, на які він
вказує. Це означає, що ми можемо помістити Box<T> всередину варіанта Cons
замість іншого значення List безпосередньо. Box<T> вказуватиме на наступне
значення List, яке буде в купі, а не всередині варіанта Cons.
Концептуально ми все ще маємо список, створений зі списків, що містять інші
списки, але ця реалізація тепер більше схожа на розміщення елементів поруч один
з одним, а не всередині один одного.
Ми можемо змінити визначення enum List у переліку 15-2 і використання List
у переліку 15-3 на код у переліку 15-5, який скомпілюється.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}Варіант Cons потребує розміру i32 плюс місце для зберігання даних
вказівника box. Варіант Nil не зберігає жодних значень, тому йому потрібно
менше місця у стеку, ніж варіанту Cons. Тепер ми знаємо, що будь-яке
значення List займатиме розмір i32 плюс розмір даних вказівника box.
Використовуючи box, ми розірвали нескінченний, рекурсивний ланцюг, тож
компілятор може визначити розмір, потрібний для зберігання значення List.
Рисунок 15-2 показує, як тепер виглядає варіант Cons.

Рисунок 15-2: List, який не має нескінченного розміру,
тому що Cons містить Box
Boxes надають лише непряме зберігання та виділення в купі; вони не мають жодних інших особливих можливостей, як ті, які ми побачимо в інших типах розумних вказівників. Вони також не мають накладних витрат на продуктивність, які спричиняють ці особливі можливості, тому вони можуть бути корисними у випадках, подібних до cons list, де непряме зберігання є єдиною потрібною нам можливістю. Ми розглянемо більше варіантів використання boxes у розділі 18.
Тип Box<T> є розумним вказівником, тому що він реалізує трейт Deref,
який дає змогу розглядати значення Box<T> як посилання. Коли значення
Box<T> виходить з області видимості, дані в купі, на які вказує box, також
очищуються завдяки реалізації трейта Drop. Ці два трейт-и стануть ще
важливішими для функціональності, яку надають інші типи розумних вказівників,
що ми обговоримо в решті цього розділу. Розгляньмо ці два трейт-и докладніше.
Поводження з розумними вказівниками (smart pointers) як зі звичайними посиланнями
Поводження з розумними вказівниками як із звичайними посиланнями
Реалізація трейту Deref дає змогу вам налаштувати поведінку оператора розіменування * (не слід плутати з оператором множення або glob-оператором). Реалізувавши Deref так, щоб розумний вказівник можна було поводити як звичайне посилання, ви можете писати код, який працює з посиланнями, і використовувати цей код також із розумними вказівниками.
Спочатку давайте подивимося, як оператор розіменування працює зі звичайними посиланнями. Потім ми спробуємо визначити власний тип, який поводиться як Box<T>, і побачимо, чому оператор розіменування не працює як посилання на нашому щойно визначеному типі. Ми дослідимо, як реалізація трейту Deref робить можливим для розумних вказівників працювати способами, подібними до посилань. Потім ми розглянемо можливість coercion deref у Rust і те, як вона дає нам змогу працювати або з посиланнями, або з розумними вказівниками.
Слідування за посиланням до значення
Звичайне посилання — це тип вказівника, і один зі способів думати про вказівник — як про стрілку до значення, що зберігається десь іще. У Listing 15-6 ми створюємо посилання на значення i32, а потім використовуємо оператор розіменування, щоб слідувати за посиланням до значення.
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}Змінна x містить значення i32 5. Ми встановлюємо y рівним посиланню на x. Ми можемо стверджувати, що x дорівнює 5. Однак, якщо ми хочемо зробити твердження про значення в y, ми маємо використати *y, щоб слідувати за посиланням до значення, на яке воно вказує (звідси — розіменування), щоб компілятор міг порівняти фактичне значення. Після того як ми розіменуємо y, ми маємо доступ до цілого значення, на яке вказує y, яке ми можемо порівняти з 5.
Якби ми спробували написати assert_eq!(5, y); натомість, ми б отримали цю помилку компіляції:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Порівнювати число і посилання на число не дозволено, тому що це різні типи. Ми маємо використати оператор розіменування, щоб слідувати за посиланням до значення, на яке воно вказує.
Використання Box<T> як посилання
Ми можемо переписати код у Listing 15-6, щоб використовувати Box<T> замість посилання; оператор розіменування, використаний на Box<T> у Listing 15-7, працює так само, як оператор розіменування, використаний на посиланні в Listing 15-6.
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Головна відмінність між Listing 15-7 і Listing 15-6 полягає в тому, що тут ми встановлюємо y як екземпляр box, який вказує на скопійоване значення x, а не як посилання, що вказує на значення x. В останньому твердженні ми можемо використати оператор розіменування, щоб слідувати за вказівником box так само, як ми робили це, коли y було посиланням. Далі ми дослідимо, що особливого в Box<T>, що дає нам змогу використовувати оператор розіменування, визначивши наш власний тип box.
Визначення власного розумного вказівника
Давайте побудуємо тип-обгортку, подібний до типу Box<T>, наданого стандартною бібліотекою, щоб побачити, як типи розумних вказівників поводяться інакше, ніж посилання, за замовчуванням. Потім ми подивимося, як додати можливість використовувати оператор розіменування.
Note: There’s one big difference between the
MyBox<T>type we’re about to build and the realBox<T>: Our version will not store its data on the heap. We are focusing this example onDeref, so where the data is actually stored is less important than the pointer-like behavior.
Тип Box<T> зрештою визначений як кортежна структура з одним елементом, тож Listing 15-8 визначає тип MyBox<T> таким самим чином. Ми також визначимо функцію new, щоб відповідати функції new, визначеній для Box<T>.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {}Ми визначаємо структуру з назвою MyBox і оголошуємо узагальнений параметр T, тому що хочемо, щоб наш тип містив значення будь-якого типу. Тип MyBox — це кортежна структура з одним елементом типу T. Функція MyBox::new приймає один параметр типу T і повертає екземпляр MyBox, який містить передане значення.
Давайте спробуємо додати функцію main із Listing 15-7 до Listing 15-8 і змінити її, щоб використовувати тип MyBox<T>, який ми визначили, замість Box<T>. Код у Listing 15-9 не скомпілюється, тому що Rust не знає, як розіменувати MyBox.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Ось результат помилки компіляції:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^ can't be dereferenced
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Наш тип MyBox<T> не можна розіменувати, тому що ми не реалізували цю можливість для нашого типу. Щоб увімкнути розіменування за допомогою оператора *, ми реалізуємо трейт Deref.
Реалізація трейту Deref
Як обговорювалося в «Реалізація трейту для типу» у розділі 10, щоб реалізувати трейт, нам потрібно надати реалізації для обов’язкових методів трейту. Трейт Deref, наданий стандартною бібліотекою, вимагає від нас реалізувати один метод під назвою deref, який запозичує self і повертає посилання на внутрішні дані. Listing 15-10 містить реалізацію Deref, яку потрібно додати до визначення MyBox<T>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Синтаксис type Target = T; визначає асоційований тип для використання трейтому Deref. Асоційовані типи — це дещо інший спосіб оголошення узагальненого параметра, але вам не потрібно турбуватися про них зараз; ми розглянемо їх докладніше в розділі 20.
Ми заповнюємо тіло методу deref виразом &self.0, щоб deref повертав посилання на значення, до якого ми хочемо отримати доступ за допомогою оператора *; згадайте з «Створення різних типів за допомогою кортежних структур» у розділі 5, що .0 звертається до першого значення в кортежній структурі. Функція main у Listing 15-9, яка викликає * для значення MyBox<T>, тепер компілюється, і твердження виконуються успішно!
Без трейту Deref компілятор може розіменовувати лише &-посилання. Метод deref дає компілятору можливість взяти значення будь-якого типу, який реалізує Deref, і викликати метод deref, щоб отримати посилання, яке він знає, як розіменувати.
Коли ми ввели *y у Listing 15-9, за лаштунками Rust насправді виконав такий код:
*(y.deref())Rust замінює оператор * викликом методу deref, а потім звичайним розіменуванням, щоб нам не доводилося думати про те, чи потрібно викликати метод deref. Ця можливість Rust дає нам змогу писати код, який працює однаково, чи маємо ми звичайне посилання, чи тип, що реалізує Deref.
Причина, чому метод deref повертає посилання на значення, а звичайне розіменування поза дужками в *(y.deref()) усе ще необхідне, пов’язана з системою власності. Якби метод deref повертав значення безпосередньо, а не посилання на значення, значення було б переміщене з self. Ми не хочемо забирати власність на внутрішнє значення всередині MyBox<T> у цьому випадку або в більшості випадків, коли ми використовуємо оператор розіменування.
Зверніть увагу, що оператор * замінюється викликом методу deref, а потім викликом оператора * лише один раз, кожного разу, коли ми використовуємо * у нашому коді. Оскільки підстановка оператора * не рекурсує нескінченно, ми зрештою отримуємо дані типу i32, що відповідає 5 в assert_eq! у Listing 15-9.
Використання coercion deref у функціях і методах
Deref coercion перетворює посилання на тип, який реалізує трейт Deref, на посилання на інший тип. Наприклад, coercion deref може перетворити &String на &str, тому що String реалізує трейт Deref так, що він повертає &str. Deref coercion — це зручність, яку Rust виконує для аргументів функцій і методів, і вона працює лише для типів, що реалізують трейт Deref. Це відбувається автоматично, коли ми передаємо посилання на значення певного типу як аргумент до функції або методу, який не збігається з типом параметра у визначенні функції або методу. Послідовність викликів методу deref перетворює тип, який ми надали, на тип, який потрібен параметру.
Coercion deref було додано до Rust, щоб програмістам, які пишуть виклики функцій і методів, не потрібно було додавати стільки явних посилань і розіменувань за допомогою & і *. Можливість coercion deref також дає нам змогу писати більше коду, який може працювати або з посиланнями, або з розумними вказівниками.
Щоб побачити coercion deref в дії, давайте скористаємося типом MyBox<T>, який ми визначили в Listing 15-8, а також реалізацією Deref, яку ми додали в Listing 15-10. Listing 15-11 показує визначення функції, яка має параметр типу рядкового зрізу.
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {}Ми можемо викликати функцію hello з рядковим зрізом як аргументом, наприклад hello("Rust");. Coercion deref дає змогу викликати hello із посиланням на значення типу MyBox<String>, як показано в Listing 15-12.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
}Тут ми викликаємо функцію hello з аргументом &m, який є посиланням на значення MyBox<String>. Оскільки ми реалізували трейт Deref для MyBox<T> у Listing 15-10, Rust може перетворити &MyBox<String> на &String, викликавши deref. Стандартна бібліотека надає реалізацію Deref для String, яка повертає рядковий зріз, і це є в документації API для Deref. Rust викликає deref ще раз, щоб перетворити &String на &str, що відповідає визначенню функції hello.
Якби Rust не реалізовував coercion deref, нам довелося б написати код у Listing 15-13 замість коду в Listing 15-12, щоб викликати hello зі значенням типу &MyBox<String>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
}(*m) розіменовує MyBox<String> у String. Потім & і [..] беруть рядковий зріз String, який дорівнює всьому рядку, щоб відповідати сигнатурі hello. Цей код без coercion deref важче читати, писати й розуміти з усіма цими символами. Coercion deref дає змогу Rust обробляти ці перетворення за нас автоматично.
Коли трейт Deref визначено для типів, що беруть участь, Rust аналізуватиме типи та використовуватиме Deref::deref стільки разів, скільки потрібно, щоб отримати посилання, яке відповідає типу параметра. Кількість разів, яку потрібно вставити Deref::deref, визначається під час компіляції, тож за використання coercion deref немає жодних витрат під час виконання!
Обробка coercion deref зі змінними посиланнями
Подібно до того, як ви використовуєте трейт Deref, щоб перевизначити оператор * для незмінних посилань, ви можете використовувати трейт DerefMut, щоб перевизначити оператор * для змінних посилань.
Rust виконує coercion deref, коли знаходить типи та реалізації трейтів у трьох випадках:
- З
&Tдо&U, колиT: Deref<Target=U> - З
&mut Tдо&mut U, колиT: DerefMut<Target=U> - З
&mut Tдо&U, колиT: Deref<Target=U>
Перші два випадки однакові, за винятком того, що другий реалізує змінність. Перший випадок стверджує, що якщо у вас є &T, і T реалізує Deref до деякого типу U, ви можете прозоро отримати &U. Другий випадок стверджує, що те саме coercion deref відбувається і для змінних посилань.
Третій випадок складніший: Rust також перетворюватиме змінне посилання на незмінне. Але зворотне неможливе: незмінні посилання ніколи не перетворюються на змінні посилання. Через правила запозичення, якщо у вас є змінне посилання, це змінне посилання має бути єдиним посиланням на ці дані (інакше програма не скомпілюється). Перетворення одного змінного посилання на одне незмінне посилання ніколи не порушить правила запозичення. Перетворення незмінного посилання на змінне посилання вимагало б, щоб початкове незмінне посилання було єдиним незмінним посиланням на ці дані, але правила запозичення цього не гарантують. Отже, Rust не може припускати, що перетворення незмінного посилання на змінне посилання можливе.
Виконання коду під час очищення за допомогою трейта Drop
Запуск коду під час очищення з трейтoм Drop
Другий трейт, важливий для шаблону розумного вказівника, — це Drop, який дає
вам змогу налаштувати, що відбувається, коли значення ось-ось вийде з області видимості. Ви можете
надати реалізацію для трейту Drop для будь-якого типу, і цей код може
використовуватися для звільнення ресурсів, таких як файли або мережеві з’єднання.
Ми вводимо Drop у контексті розумних вказівників, тому що
функціональність трейту Drop майже завжди використовується під час реалізації
розумного вказівника. Наприклад, коли Box<T> видаляється, він звільняє
простір у купі, на який вказує box.
У деяких мовах, для деяких типів, програміст має викликати код для звільнення пам’яті або ресурсів щоразу, коли завершує використання екземпляра цих типів. Приклади включають файлові дескриптори, сокети та блокування. Якщо програміст забуде, система може перевантажитися й аварійно завершити роботу. У Rust ви можете вказати, що певний фрагмент коду має виконуватися щоразу, коли значення виходить з області видимості, і компілятор вставить цей код автоматично. У результаті вам не потрібно бути обережними щодо розміщення коду очищення всюди в програмі, коли роботу з екземпляром певного типу завершено — ви все одно не витечете ресурси!
Ви вказуєте код, який потрібно виконати, коли значення виходить з області видимості, шляхом реалізації
трейту Drop. Трейт Drop вимагає, щоб ви реалізували один метод із назвою
drop, який приймає змінне посилання на self. Щоб побачити, коли Rust викликає drop,
давайте поки що реалізуємо drop із виразами println!.
У списку 15-14 показано структуру CustomSmartPointer, єдина власна
функціональність якої полягає в тому, що вона виводитиме Dropping CustomSmartPointer!, коли
екземпляр виходитиме з області видимості, щоб показати, коли Rust виконує метод drop.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("my stuff"),
};
let d = CustomSmartPointer {
data: String::from("other stuff"),
};
println!("CustomSmartPointers created");
}Трейт Drop входить до prelude, тож нам не потрібно вводити його в
область видимості. Ми реалізуємо трейт Drop для CustomSmartPointer і надаємо
реалізацію для методу drop, який викликає println!. Тіло
методу drop — це місце, куди ви б помістили будь-яку логіку, яку хотіли б
запустити, коли екземпляр вашого типу виходить з області видимості. Тут ми виводимо трохи тексту,
щоб наочно продемонструвати, коли Rust викликатиме drop.
У main ми створюємо два екземпляри CustomSmartPointer, а потім виводимо
CustomSmartPointers created. Наприкінці main наші екземпляри
CustomSmartPointer вийдуть з області видимості, і Rust викличе код, який ми помістили
в метод drop, вивівши наше фінальне повідомлення. Зауважте, що нам не потрібно було
викликати метод drop явно.
Коли ми запустимо цю програму, ми побачимо такий вивід:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
Rust автоматично викликав drop для нас, коли наші екземпляри вийшли з області видимості,
викликавши код, який ми вказали. Змінні видаляються у зворотному порядку
їх створення, тож d було видалено перед c. Мета цього прикладу —
дати вам візуальне уявлення про те, як працює метод drop; зазвичай ви б
вказували код очищення, який має виконати ваш тип, а не
повідомлення для друку.
На жаль, вимкнути автоматичну функціональність drop не так просто. Вимикати drop зазвичай не потрібно; уся суть
трейту Drop у тому, що про це подбано автоматично. Однак інколи
вам може знадобитися очистити значення раніше. Один із прикладів — коли використовуються розумні
вказівники, які керують блокуваннями: вам може знадобитися примусово викликати
метод drop, який звільняє блокування, щоб інший код у тій самій області видимості міг отримати блокування.
Rust не дає вам викликати метод drop трейту Drop вручну; натомість
вам потрібно викликати функцію std::mem::drop, надану стандартною бібліотекою,
якщо ви хочете примусово видалити значення до завершення його області видимості.
Спроба вручну викликати метод drop трейту Drop, змінивши
функцію main зі списку 15-14, не спрацює, як показано у списку 15-15.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
c.drop();
println!("CustomSmartPointer dropped before the end of main");
}Коли ми спробуємо скомпілювати цей код, отримаємо таку помилку:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 - c.drop();
16 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
Це повідомлення про помилку стверджує, що нам не дозволено явно викликати drop. У
повідомленні про помилку використано термін destructor, який є загальним терміном програмування
для функції, що очищає екземпляр. Destructor є аналогом
constructor, який створює екземпляр. Функція drop у Rust — це один
конкретний destructor.
Rust не дає нам явно викликати drop, тому що Rust усе одно
автоматично викликав би drop для значення наприкінці main. Це спричинило б
помилку подвійного звільнення, оскільки Rust намагався б очистити те саме значення двічі.
Ми не можемо вимкнути автоматичне вставлення drop, коли значення виходить з
області видимості, і не можемо викликати метод drop явно. Отже, якщо нам потрібно примусово
очистити значення раніше, ми використовуємо функцію std::mem::drop.
Функція std::mem::drop відрізняється від методу drop у трейті Drop.
Ми викликаємо її, передаючи як аргумент значення, яке хочемо примусово видалити.
Функція є в prelude, тож ми можемо змінити main у списку 15-15, щоб
викликати функцію drop, як показано у списку 15-16.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
drop(c);
println!("CustomSmartPointer dropped before the end of main");
}Запуск цього коду виведе таке:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main
Текст Dropping CustomSmartPointer with data `some data`! виводиться
між текстом CustomSmartPointer created і CustomSmartPointer dropped before the end of main, показуючи, що код методу drop викликається для видалення
c у цей момент.
Ви можете використовувати код, заданий у реалізації трейту Drop, багатьма способами, щоб
зробити очищення зручним і безпечним: наприклад, ви могли б використати його, щоб створити
власний розподілювач пам’яті! Зі трейтoм Drop і системою власності Rust вам
не потрібно пам’ятати про очищення, тому що Rust робить це автоматично.
Вам також не потрібно турбуватися про проблеми, що виникають через випадкове
очищення значень, які все ще використовуються: система власності, яка гарантує,
що посилання завжди дійсні, також забезпечує, що drop викликається лише один раз, коли
значення більше не використовується.
Тепер, коли ми розглянули Box<T> і деякі характеристики розумних
вказівників, давайте подивимося на кілька інших розумних вказівників, визначених у стандартній
бібліотеці.
Rc<T>, розумний вказівник (smart pointer) з підрахунком посилань
Rc<T>, розумний вказівник з підрахунком посилань
У більшості випадків власність є зрозумілою: ви точно знаєте, яка змінна володіє певним значенням. Однак є випадки, коли одне значення може мати кількох власників. Наприклад, у структурах даних графів кілька ребер можуть вказувати на той самий вузол, і цей вузол концептуально належить усім ребрам, які на нього вказують. Вузол не слід очищати, якщо на нього все ще вказують будь-які ребра і, отже, він не має жодних власників.
Ви маєте явно увімкнути множинну власність, використовуючи тип Rust Rc<T>, який є скороченням від reference counting. Тип Rc<T> відстежує кількість посилань на значення, щоб визначити, чи використовується це значення ще. Якщо на значення немає жодного посилання, його можна очистити так, щоб жодне посилання не стало недійсним.
Уявіть Rc<T> як телевізор у вітальні. Коли одна людина заходить подивитися телевізор, вона вмикає його. Інші можуть зайти до кімнати й дивитися телевізор. Коли остання людина виходить із кімнати, вона вимикає телевізор, тому що його більше не використовують. Якби хтось вимкнув телевізор, поки інші все ще дивляться його, це викликало б обурення серед тих, хто ще дивиться телевізор!
Ми використовуємо тип Rc<T>, коли хочемо виділити деякі дані в купі для читання кількома частинами нашої програми і не можемо на етапі компіляції визначити, яка частина завершить використання даних останньою. Якби ми знали, яка частина завершить останньою, ми могли б просто зробити саме її власником даних, і звичайні правила власності, що забезпечуються на етапі компіляції, почали б діяти.
Зауважте, що Rc<T> призначений лише для використання у однопотокових сценаріях. Коли ми обговорюватимемо конкурентність у розділі 16, ми покажемо, як виконувати підрахунок посилань у багатопотокових програмах.
Спільне використання даних
Повернімося до нашого прикладу з cons list у Listing 15-5. Пригадайте, що ми визначили його, використовуючи Box<T>. Цього разу ми створимо два списки, які обидва розділяють власність над третім списком. Концептуально це виглядає подібно до Figure 15-3.

Figure 15-3: Two lists, b and c, sharing ownership of
a third list, a
Ми створимо список a, який містить 5, а потім 10. Потім ми зробимо ще два списки: b, який починається з 3, і c, який починається з 4. Обидва списки b і c потім продовжаться до першого списку a, що містить 5 і 10. Іншими словами, обидва списки розділятимуть перший список, що містить 5 і 10.
Спроба реалізувати цей сценарій, використовуючи наше визначення List з Box<T>, не спрацює, як показано в Listing 15-17.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}Коли ми компілюємо цей код, отримуємо таку помилку:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
|
note: if `List` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Cons(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
Варіанти Cons володіють даними, які вони містять, тому коли ми створюємо список b, a переміщується в b, і b володіє a. Потім, коли ми намагаємося знову використати a під час створення c, нам це заборонено, тому що a було переміщено.
Ми могли б змінити визначення Cons, щоб воно містило посилання, але тоді нам довелося б вказати параметри часу життя. Вказуючи параметри часу життя, ми б вказували, що кожен елемент у списку житиме принаймні так само довго, як і весь список. Це справедливо для елементів і списків у Listing 15-17, але не в кожному сценарії.
Натомість ми змінимо наше визначення List, щоб використовувати Rc<T> замість Box<T>, як показано в Listing 15-18. Кожен варіант Cons тепер міститиме значення та Rc<T>, що вказує на List. Коли ми створюємо b, замість того щоб брати власність над a, ми клонуватимемо Rc<List>, яке містить a, тим самим збільшуючи кількість посилань з одного до двох і дозволяючи a та b розділяти власність над даними в цьому Rc<List>. Ми також клонуватимемо a під час створення c, збільшуючи кількість посилань із двох до трьох. Щоразу, коли ми викликаємо Rc::clone, кількість посилань на дані всередині Rc<List> збільшуватиметься, і дані не буде очищено, якщо на них є хоча б одне посилання.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}Нам потрібно додати оператор use, щоб ввести Rc<T> в область видимості, тому що він не входить до prelude. У main ми створюємо список, що містить 5 і 10, і зберігаємо його в новому Rc<List> у a. Потім, коли ми створюємо b і c, ми викликаємо функцію Rc::clone і передаємо як аргумент посилання на Rc<List> у a.
Ми могли б викликати a.clone() замість Rc::clone(&a), але конвенція Rust у цьому випадку — використовувати Rc::clone. Реалізація Rc::clone не робить глибокого копіювання всіх даних, як це роблять реалізації clone у більшості типів. Виклик Rc::clone лише збільшує кількість посилань, що не займає багато часу. Глибокі копії даних можуть займати багато часу. Використовуючи Rc::clone для підрахунку посилань, ми можемо візуально розрізняти клонування типу глибокого копіювання та клонування, що збільшує кількість посилань. Під час пошуку проблем із продуктивністю в коді нам потрібно враховувати лише клони глибокого копіювання і можемо не брати до уваги виклики Rc::clone.
Клонування для збільшення кількості посилань
Змінимо наш робочий приклад у Listing 15-18 так, щоб ми могли бачити, як змінюється кількість посилань, коли ми створюємо посилання на Rc<List> у a і звільняємо їх.
У Listing 15-19 ми змінимо main так, щоб навколо списку c була внутрішня область видимості; тоді ми зможемо побачити, як змінюється кількість посилань, коли c виходить з області видимості.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
// --snip--
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}У кожний момент у програмі, коли кількість посилань змінюється, ми виводимо кількість посилань, яку отримуємо, викликаючи функцію Rc::strong_count. Ця функція називається strong_count, а не count, тому що тип Rc<T> також має weak_count; ми побачимо, для чого використовується weak_count, у “Preventing Reference Cycles Using Weak<T>”.
Цей код виводить таке:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
Ми бачимо, що Rc<List> у a має початкову кількість посилань 1; потім щоразу, коли ми викликаємо clone, ця кількість збільшується на 1. Коли c виходить з області видимості, кількість зменшується на 1. Нам не потрібно викликати функцію, щоб зменшити кількість посилань, так само як нам потрібно викликати Rc::clone, щоб збільшити кількість посилань: Реалізація трейтa Drop автоматично зменшує кількість посилань, коли значення Rc<T> виходить з області видимості.
Чого ми не бачимо в цьому прикладі, так це того, що коли b, а потім a виходять з області видимості наприкінці main, кількість стає 0, і Rc<List> повністю очищується. Використання Rc<T> дозволяє одному значенню мати кількох власників, а кількість гарантує, що значення залишатиметься дійсним, доки будь-хто з власників ще існує.
Через незмінні посилання Rc<T> дозволяє вам ділитися даними між кількома частинами вашої програми лише для читання. Якби Rc<T> також дозволяв вам мати кілька змінних посилань, ви могли б порушити одне з правил запозичення, обговорених у розділі 4: кілька змінних запозичень до одного й того самого місця можуть спричинити стан гонки даних і непослідовності. Але можливість змінювати дані дуже корисна! У наступному розділі ми обговоримо шаблон внутрішньої змінності та тип RefCell<T>, який ви можете використовувати разом із Rc<T>, щоб працювати з цим обмеженням незмінності.
RefCell<T> і патерн внутрішньої змінності (interior mutability)
RefCell<T> та патерн внутрішньої змінності (Interior mutability)
Внутрішня змінність — це патерн проєктування в Rust, який дозволяє вам змінювати
дані навіть тоді, коли для цих даних існують незмінні посилання; зазвичай ця
дія заборонена правилами запозичення. Щоб змінювати дані, цей патерн використовує
код unsafe усередині структури даних, щоб послабити звичайні правила Rust, які
керують змінністю та запозиченням. Код unsafe показує компілятору, що ми
перевіряємо правила вручну, замість того щоб покладатися на компілятор, який
перевірить їх за нас; про код unsafe ми докладніше поговоримо в розділі 20.
Ми можемо використовувати типи, що застосовують патерн внутрішньої змінності, лише
коли можемо гарантувати, що правила запозичення буде дотримано під час виконання, навіть
якщо компілятор не може цього гарантувати. unsafe-код, що використовується, тоді
обгортається в безпечний API, а зовнішній тип усе ще є незмінним.
Дослідимо цю концепцію, подивившись на тип RefCell<T>, який дотримується
патерну внутрішньої змінності.
Забезпечення правил запозичення під час виконання
На відміну від Rc<T>, тип RefCell<T> представляє єдину власність над даними,
які він зберігає. Отже, що робить RefCell<T> відмінним від типу на кшталт Box<T>?
Згадайте правила запозичення, які ви вивчили в розділі 4:
- У будь-який момент часу ви можете мати або одне змінне посилання, або будь-яку кількість незмінних посилань (але не обидва варіанти одночасно).
- Посилання завжди мають бути дійсними.
З посиланнями та Box<T> інваріанти правил запозичення забезпечуються під час
компіляції. З RefCell<T> ці інваріанти забезпечуються під час виконання.
З посиланнями, якщо ви порушите ці правила, отримаєте помилку компілятора. З
RefCell<T>, якщо ви порушите ці правила, ваша програма завершиться через
panic.
Переваги перевірки правил запозичення під час компіляції полягають у тому, що помилки буде виявлено раніше в процесі розробки, а також у тому, що це не впливає на продуктивність під час виконання, оскільки весь аналіз завершується заздалегідь. З цих причин перевірка правил запозичення під час компіляції є найкращим вибором у більшості випадків, тому це й є типовою поведінкою Rust.
Перевага перевірки правил запозичення під час виконання полягає в тому, що деякі безпечні для пам’яті сценарії тоді дозволяються, хоча їх було б заборонено перевірками під час компіляції. Статичний аналіз, як у компіляторі Rust, за своєю природою є обережним. Деякі властивості коду неможливо виявити, аналізуючи код: найвідоміший приклад — проблема зупинки, яка виходить за межі цієї книги, але є цікавою темою для дослідження.
Оскільки деякий аналіз неможливий, якщо компілятор Rust не може бути певним, що
код відповідає правилам власності, він може відхилити правильну програму; таким
чином він є обережним. Якби Rust прийняв неправильну програму, користувачі не
могли б довіряти гарантіям, які дає Rust. Однак якщо Rust відхиляє правильну
програму, це створить незручності для програміста, але нічого катастрофічного
не станеться. Тип RefCell<T> корисний тоді, коли ви впевнені, що ваш код
дотримується правил запозичення, але компілятор не може це зрозуміти та
гарантувати.
Подібно до Rc<T>, RefCell<T> призначений лише для використання в однопотокових
сценаріях і видасть вам помилку компіляції, якщо ви спробуєте використати його в
багатопотоковому контексті. У розділі 16 ми поговоримо про те, як отримати
функціональність RefCell<T> у багатопотоковій програмі.
Ось короткий підсумок причин обрати Box<T>, Rc<T> або RefCell<T>:
Rc<T>дає змогу кільком власникам мати ті самі дані;Box<T>іRefCell<T>мають одного власника.Box<T>дозволяє незмінні або змінні запозичення, перевірені під час компіляції;Rc<T>дозволяє лише незмінні запозичення, перевірені під час компіляції;RefCell<T>дозволяє незмінні або змінні запозичення, перевірені під час виконання.- Оскільки
RefCell<T>дозволяє змінні запозичення, перевірені під час виконання, ви можете змінювати значення всерединіRefCell<T>навіть тоді, колиRefCell<T>є незмінним.
Змінювання значення всередині незмінного значення — це патерн внутрішньої змінності. Розгляньмо ситуацію, у якій внутрішня змінність корисна, і побачимо, як це можливо.
Використання внутрішньої змінності
Наслідком правил запозичення є те, що коли у вас є незмінне значення, ви не можете запозичити його як змінне. Наприклад, цей код не скомпілюється:
fn main() {
let x = 5;
let y = &mut x;
}Якби ви спробували скомпілювати цей код, ви б отримали таку помилку:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
Однак існують ситуації, у яких було б корисно, щоб значення змінювало саме себе
у своїх методах, але виглядало незмінним для іншого коду. Код поза методами цього
значення не міг би змінювати значення. Використання RefCell<T> — це один зі
способів отримати можливість внутрішньої змінності, але RefCell<T> не обходить
правила запозичення повністю: перевірник запозичень у компіляторі дозволяє цю
внутрішню змінність, а правила запозичення перевіряються під час виконання.
Якщо ви порушите правила, отримаєте panic! замість помилки компілятора.
Давайте розглянемо практичний приклад, де ми можемо використати RefCell<T>, щоб
змінювати незмінне значення, і побачимо, чому це корисно.
Тестування з мок-об’єктами
Іноді під час тестування програміст використовує один тип замість іншого, щоб спостерігати певну поведінку та стверджувати, що вона реалізована правильно. Такий тип-заглушка називається test double. Подумайте про це в сенсі дублера-каскадера у кіно, де людина підміняє актора для виконання особливо складної сцени. Test doubles виступають замість інших типів, коли ми запускаємо тести. Mock objects — це конкретні типи test doubles, які записують те, що відбувається під час тесту, щоб ви могли стверджувати, що відбулися правильні дії.
Rust не має об’єктів у тому ж сенсі, у якому об’єкти є в інших мовах, і Rust не має вбудованої у стандартну бібліотеку функціональності mock objects, як деякі інші мови. Однак ви цілком можете створити структуру, яка виконуватиме ті самі завдання, що й mock object.
Ось сценарій, який ми тестуватимемо: ми створимо бібліотеку, яка відстежує значення відносно максимального значення та надсилає повідомлення залежно від того, наскільки поточне значення близьке до максимального. Цю бібліотеку можна, наприклад, використати для відстеження квоти користувача на кількість API-викликів, які йому дозволено зробити.
Наша бібліотека надаватиме лише функціональність відстеження того, наскільки
значення близьке до максимуму, і якими мають бути повідомлення та коли. Від
застосунків, які використовують нашу бібліотеку, очікуватиметься надання механізму
надсилання повідомлень: застосунок може показувати повідомлення користувачу безпосередньо,
надсилати email, надсилати текстове повідомлення або робити щось інше. Бібліотеці
не потрібно знати цю деталь. Усе, що їй потрібно, — це щось, що реалізує трейт,
який ми надамо, під назвою Messenger. У переліку 15-20 показано код бібліотеки.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}Важливою частиною цього коду є те, що трейт Messenger має один метод,
send, який приймає незмінне посилання на self і текст
повідомлення. Цей трейт — інтерфейс, який наш мок-об’єкт має реалізувати, щоб
мок можна було використовувати так само, як реальний об’єкт. Інша важлива
частина полягає в тому, що ми хочемо протестувати поведінку методу set_value
на LimitTracker. Ми можемо змінювати те, що передаємо для параметра value, але
set_value не повертає нічого, на чому ми могли б зробити ствердження. Ми хочемо
бути в змозі сказати, що якщо ми створимо LimitTracker із чимось, що реалізує
трейт Messenger, і певним значенням для max, то messenger буде наказано
надіслати відповідні повідомлення, коли ми передаємо різні числа для value.
Нам потрібен мок-об’єкт, який замість надсилання email або текстового повідомлення
під час виклику send лише відстежуватиме повідомлення, які йому наказано
надсилати. Ми можемо створити новий екземпляр мок-об’єкта, створити LimitTracker,
який використовує мок-об’єкт, викликати метод set_value на LimitTracker, а
потім перевірити, що мок-об’єкт має повідомлення, яких ми очікуємо. У переліку 15-21
показано спробу реалізувати мок-об’єкт саме для цього, але перевірник запозичень не
дозволить цього.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}Цей тестовий код визначає структуру MockMessenger, яка має поле sent_messages
з Vec значень String для відстеження повідомлень, які їй наказано
надсилати. Ми також визначаємо асоційовану функцію new, щоб було зручно
створювати нові значення MockMessenger, які починаються з порожнього списку повідомлень. Потім
ми реалізуємо трейт Messenger для MockMessenger, щоб ми могли передати
MockMessenger до LimitTracker. У визначенні методу send ми
беремо повідомлення, передане як параметр, і зберігаємо його у списку sent_messages
структури MockMessenger.
У тесті ми перевіряємо, що станеться, коли LimitTracker буде наказано встановити
value у значення, яке перевищує 75 відсотків від значення max. Спочатку ми
створюємо новий MockMessenger, який починатиметься з порожнього списку повідомлень.
Потім ми створюємо новий LimitTracker і даємо йому посилання на новий
MockMessenger та значення max 100. Ми викликаємо метод set_value на
LimitTracker зі значенням 80, яке становить понад 75 відсотків від 100.
Потім ми стверджуємо, що список повідомлень, які відстежує MockMessenger, тепер
має містити одне повідомлення.
Однак у цьому тесті є одна проблема, як показано тут:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn send(&mut self, msg: &str);
3 | }
...
56 | impl Messenger for MockMessenger {
57 ~ fn send(&mut self, message: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
Ми не можемо змінювати MockMessenger, щоб відстежувати повідомлення, тому що
метод send приймає незмінне посилання на self. Ми також не можемо прийняти
пропозицію з тексту помилки використати &mut self і в методі impl, і
в оголошенні трейта. Ми не хочемо змінювати трейт Messenger лише
заради тестування. Натомість нам потрібно знайти спосіб, щоб наш тестовий код
коректно працював із наявним дизайном.
Це ситуація, у якій внутрішня змінність може допомогти! Ми зберігатимемо
sent_messages всередині RefCell<T>, і тоді метод send зможе
змінювати sent_messages, щоб зберігати повідомлення, які ми побачили. У переліку 15-22
показано, як це виглядає.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Поле sent_messages тепер має тип RefCell<Vec<String>> замість
Vec<String>. У функції new ми створюємо новий екземпляр RefCell<Vec<String>>
навколо порожнього вектора.
Для реалізації методу send перший параметр усе ще є незмінним запозиченням
self, що відповідає визначенню трейта. Ми викликаємо borrow_mut на
RefCell<Vec<String>> у self.sent_messages, щоб отримати
змінне посилання на значення всередині RefCell<Vec<String>>, тобто на
вектор. Потім ми можемо викликати push на змінному посиланні на вектор, щоб
відстежувати повідомлення, надіслані під час тесту.
Остання зміна, яку ми маємо зробити, — це в твердженні: щоб побачити, скільки елементів
у внутрішньому векторі, ми викликаємо borrow на RefCell<Vec<String>>, щоб отримати
незмінне посилання на вектор.
Тепер, коли ви побачили, як використовувати RefCell<T>, давайте розберемося, як це працює!
Відстеження запозичень під час виконання
Під час створення незмінних і змінних посилань ми використовуємо синтаксис & і &mut
відповідно. З RefCell<T> ми використовуємо методи borrow і borrow_mut,
які є частиною безпечного API, що належить RefCell<T>. Метод
borrow повертає тип розумного вказівника Ref<T>, а borrow_mut
повертає тип розумного вказівника RefMut<T>. Обидва типи реалізують Deref, тож
ми можемо поводитися з ними як зі звичайними посиланнями.
RefCell<T> відстежує, скільки розумних вказівників Ref<T> і RefMut<T>
зараз активні. Щоразу, коли ми викликаємо borrow, RefCell<T>
збільшує свій лічильник активних незмінних запозичень. Коли значення Ref<T>
виходить з області видимості, кількість незмінних запозичень зменшується на 1. Так
само, як і правила запозичення під час компіляції, RefCell<T> дозволяє нам мати
багато незмінних запозичень або одне змінне запозичення в будь-який момент часу.
Якщо ми спробуємо порушити ці правила, замість помилки компілятора, як це було б
із посиланнями, реалізація RefCell<T> викличе panic під час виконання. У переліку 15-23
показано зміну в реалізації send з переліку 15-22. Ми навмисно
намагаємося створити два активні змінні запозичення для однієї й тієї самої області видимості,
щоб показати, що RefCell<T> запобігає цьому під час виконання.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Ми створюємо змінну one_borrow для розумного вказівника RefMut<T>, який
повертається з borrow_mut. Потім ми створюємо ще одне змінне запозичення таким самим
способом у змінній two_borrow. Це створює два змінні посилання в одній
області видимості, що не дозволено. Коли ми запускаємо тести для нашої бібліотеки,
код у переліку 15-23 скомпілюється без жодних помилок, але тест зазнає
невдачі:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Зверніть увагу, що код викликав panic із повідомленням already borrowed: BorrowMutError. Саме так RefCell<T> обробляє порушення правил запозичення
під час виконання.
Вибір обробляти помилки запозичення під час виконання, а не під час компіляції,
як ми зробили тут, означає, що ви потенційно виявлятимете помилки у своєму коді
пізніше в процесі розробки: можливо, лише після розгортання коду в
продуктивному середовищі. Також ваш код матиме невеликий штраф за продуктивністю
під час виконання через відстеження запозичень під час виконання замість
компіляції. Однак використання RefCell<T> робить можливим написання мок-об’єкта, який
може змінювати сам себе, щоб відстежувати повідомлення, які він бачив, коли ви
використовуєте його в контексті, де дозволені лише незмінні значення. Ви можете
використовувати RefCell<T>, незважаючи на його компроміси, щоб отримати
більше функціональності, ніж надають звичайні посилання.
Дозволення кількох власників змінних даних
Поширений спосіб використання RefCell<T> — у поєднанні з Rc<T>. Згадайте, що
Rc<T> дозволяє вам мати кількох власників деяких даних, але він надає лише незмінний
доступ до цих даних. Якщо у вас є Rc<T>, який містить RefCell<T>, ви можете
отримати значення, яке може мати кількох власників і яке ви можете змінювати!
Наприклад, згадайте приклад cons-списку в переліку 15-18, де ми використали
Rc<T>, щоб дозволити кільком спискам спільно володіти іншим списком. Оскільки
Rc<T> містить лише незмінні значення, ми не можемо змінити жодне зі значень у
списку після їх створення. Додаймо RefCell<T> заради його здатності
змінювати значення в списках. У переліку 15-24 показано, що, використовуючи
RefCell<T> у визначенні Cons, ми можемо змінювати значення, що зберігається в усіх
списках.
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {a:?}");
println!("b after = {b:?}");
println!("c after = {c:?}");
}Ми створюємо значення, яке є екземпляром Rc<RefCell<i32>>, і зберігаємо його в
змінній з назвою value, щоб ми могли надалі звертатися до нього безпосередньо. Потім ми
створюємо List у a з варіантом Cons, який містить value. Нам потрібно клонувати
value, щоб і a, і value мали власність над внутрішнім значенням 5, а не
щоб власність перемістилася від value до a або щоб a запозичувало
з value.
Ми обгортаємо список a в Rc<T>, щоб коли ми створюємо списки b і c,
вони обидва могли посилатися на a, що ми й зробили в переліку 15-18.
Після того як ми створили списки в a, b і c, ми хочемо додати 10 до
значення в value. Ми робимо це, викликаючи borrow_mut на value, що використовує
функцію автоматичного розіменування, яку ми обговорювали в “Де оператор ->?”
у розділі 5, щоб розіменувати Rc<T> до внутрішнього значення RefCell<T>.
Метод borrow_mut повертає розумний вказівник RefMut<T>, і ми використовуємо
оператор розіменування на ньому та змінюємо внутрішнє значення.
Коли ми друкуємо a, b і c, бачимо, що всі вони мають змінене
значення 15 замість 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Ця техніка досить гарна! Використовуючи RefCell<T>, ми маємо зовні
незмінне значення List. Але ми можемо використовувати методи на RefCell<T>, які
надають доступ до його внутрішньої змінності, щоб змінювати наші дані, коли нам
це потрібно. Перевірки правил запозичення під час виконання захищають нас від станів гонки даних,
і іноді варто обміняти трохи швидкості на цю гнучкість у наших структурах даних. Зверніть
увагу, що RefCell<T> не працює для багатопотокового коду!
Mutex<T> — це потокобезпечна версія RefCell<T>, і ми обговоримо
Mutex<T> у розділі 16.
Цикли посилань можуть призводити до витоку пам'яті
Цикли посилань можуть спричинити витік пам’яті
Гарантії безпеки пам’яті Rust ускладнюють, але не унеможливлюють випадкове створення пам’яті, яка ніколи не очищається (це відоме як витік пам’яті).
Повне запобігання витокам пам’яті не є однією з гарантій Rust, тобто витоки пам’яті є безпечними з точки зору пам’яті в Rust. Ми можемо побачити, що Rust допускає витоки пам’яті, використовуючи Rc<T> і RefCell<T>: можливо створити посилання, у яких елементи посилаються один на одного в циклі. Це створює витоки пам’яті, тому що лічильник посилань кожного елемента в циклі ніколи не досягне 0, і значення ніколи не будуть звільнені.
Створення циклу посилань
Давайте подивимося, як може виникнути цикл посилань і як цьому запобігти, починаючи з визначення перелікa List і методу tail у Listing 15-25.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {}Ми використовуємо ще один варіант визначення List з Listing 15-5. Другий елемент у варіанті Cons тепер є RefCell<Rc<List>>, тобто замість можливості змінювати значення i32, як ми робили в Listing 15-24, ми хочемо змінювати значення List, на яке вказує варіант Cons.
Ми також додаємо метод tail, щоб нам було зручно отримувати доступ до другого елемента, якщо в нас є варіант Cons.
У Listing 15-26 ми додаємо функцію main, яка використовує визначення з Listing 15-25. Цей код створює список у a і список у b, який вказує на список у a. Потім він змінює список у a, щоб він вказував на b, створюючи цикл посилань. Тут є оператори println!, які показують, якими є лічильники посилань у різні моменти цього процесу.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// Uncomment the next line to see that we have a cycle;
// it will overflow the stack.
// println!("a next item = {:?}", a.tail());
}Ми створюємо екземпляр Rc<List>, що містить значення List, у змінній a з початковим списком 5, Nil. Потім ми створюємо екземпляр Rc<List>, що містить інше значення List, у змінній b, яке містить значення 10 і вказує на список у a.
Ми змінюємо a, щоб воно вказувало на b замість Nil, створюючи цикл. Ми робимо це, використовуючи метод tail, щоб отримати посилання на RefCell<Rc<List>> у a, яке ми поміщаємо у змінну link. Потім ми використовуємо метод borrow_mut на RefCell<Rc<List>>, щоб змінити значення всередині з Rc<List>, який містить значення Nil, на Rc<List> у b.
Коли ми запускаємо цей код, залишивши останній println! закоментованим на даний момент, ми отримаємо такий вивід:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
Лічильник посилань екземплярів Rc<List> як у a, так і в b дорівнює 2 після того, як ми змінюємо список у a, щоб він вказував на b. Наприкінці main Rust звільняє змінну b, що зменшує лічильник посилань екземпляра b Rc<List> з 2 до 1. Пам’ять, яку Rc<List> має в купі, не буде звільнена на цьому етапі, тому що її лічильник посилань дорівнює 1, а не 0. Потім Rust звільняє a, що також зменшує лічильник посилань екземпляра a Rc<List> з 2 до 1. Цю пам’ять також не можна звільнити, тому що інший екземпляр Rc<List> усе ще посилається на неї. Пам’ять, виділена для списку, залишиться незбираною назавжди. Щоб візуалізувати цей цикл посилань, ми створили діаграму на Figure 15-4.

Figure 15-4: Цикл посилань списків a і b, які вказують одне на одне
Якщо ви розкоментуєте останній println! і запустите програму, Rust спробує надрукувати цей цикл із a, що вказує на b, що вказує на a, і так далі, доки не переповнить стек.
Порівняно зі справжньою програмою наслідки створення циклу посилань у цьому прикладі не дуже серйозні: одразу після того, як ми створюємо цикл посилань, програма завершується. Однак якщо складніша програма виділяла б багато пам’яті в циклі й утримувала б її тривалий час, програма використовувала б більше пам’яті, ніж їй потрібно, і могла б перевантажити систему, спричинивши вичерпання доступної пам’яті.
Створити цикл посилань непросто, але це не неможливо. Якщо у вас є значення RefCell<T>, які містять значення Rc<T>, або подібні вкладені комбінації типів із внутрішньою змінністю та підрахунком посилань, ви мусите переконатися, що не створюєте цикли; ви не можете покладатися на Rust, щоб він їх виявив.
Створення циклу посилань було б логічною помилкою у вашій програмі, яку ви маєте намагатися мінімізувати за допомогою автоматизованих тестів, code review та інших практик розробки програмного забезпечення.
Інше рішення для уникнення циклів посилань — це реорганізувати ваші структури даних так, щоб деякі посилання виражали власність, а деякі — ні. У результаті ви можете мати цикли, складені з деяких відносин власності та деяких відносин без власності, і лише відносини власності впливають на те, чи може значення бути звільнене. У Listing 15-25 ми завжди хочемо, щоб варіанти Cons володіли своїм списком, тому реорганізація структури даних неможлива. Давайте розглянемо приклад із використанням графів, складених із батьківських і дочірніх вузлів, щоб побачити, коли відносини без власності є доречним способом запобігти циклам посилань.
Запобігання циклам посилань за допомогою Weak<T>
Досі ми демонстрували, що виклик Rc::clone збільшує strong_count екземпляра Rc<T>, і екземпляр Rc<T> очищається лише якщо його strong_count дорівнює 0. Ви також можете створити слабке посилання на значення всередині екземпляра Rc<T>, викликавши Rc::downgrade і передавши посилання на Rc<T>. Сильні посилання — це те, як ви можете спільно володіти екземпляром Rc<T>. Слабкі посилання не виражають відносини власності, і їхній лічильник не впливає на те, коли екземпляр Rc<T> очищається. Вони не спричинять цикл посилань, тому що будь-який цикл, що містить деякі слабкі посилання, буде розірваний, щойно сильний лічильник посилань залучених значень стане 0.
Коли ви викликаєте Rc::downgrade, ви отримуєте розумний вказівник типу Weak<T>.
Замість того, щоб збільшувати strong_count в екземплярі Rc<T> на 1, виклик Rc::downgrade збільшує weak_count на 1. Тип Rc<T> використовує weak_count, щоб відстежувати, скільки існує посилань Weak<T>, подібно до strong_count. Різниця в тому, що weak_count не повинен дорівнювати 0, щоб екземпляр Rc<T> був очищений.
Оскільки значення, на яке посилається Weak<T>, могло бути звільнене, щоб робити щось зі значенням, на яке вказує Weak<T>, ви мусите переконатися, що значення все ще існує. Зробіть це, викликавши метод upgrade на екземплярі Weak<T>, який поверне Option<Rc<T>>. Ви отримаєте результат Some, якщо значення Rc<T> ще не було звільнене, і результат None, якщо значення Rc<T> було звільнене. Оскільки upgrade повертає Option<Rc<T>>, Rust забезпечить обробку випадків Some і None, і не буде недійсного вказівника.
Як приклад, замість використання списку, елементи якого знають лише про наступний елемент, ми створимо дерево, елементи якого знають про свої дочірні елементи і про свої батьківські елементи.
Створення структури даних дерева
Для початку ми побудуємо дерево з вузлами, які знають про свої дочірні вузли.
Ми створимо структуру з назвою Node, яка містить власне значення i32, а також посилання на значення своїх дочірніх Node:
Filename: src/main.rs
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}Ми хочемо, щоб Node володів своїми дочірніми елементами, і ми хочемо розділяти цю власність із змінними, щоб ми могли безпосередньо отримувати доступ до кожного Node у дереві. Щоб зробити це, ми визначаємо елементи Vec<T> як значення типу Rc<Node>. Ми також хочемо змінювати, які вузли є дочірніми для іншого вузла, тому ми маємо RefCell<T> у children навколо Vec<Rc<Node>>.
Далі ми використаємо наше визначення структури й створимо один екземпляр Node з ім’ям leaf зі значенням 3 і без дочірніх елементів, а також інший екземпляр branch зі значенням 5 і leaf як одним зі своїх дочірніх елементів, як показано в Listing 15-27.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}Ми клонують Rc<Node> у leaf і зберігаємо це в branch, тобто Node у leaf тепер має двох власників: leaf і branch. Ми можемо дістатися від branch до leaf через branch.children, але немає способу дістатися від leaf до branch. Причина в тому, що leaf не має посилання на branch і не знає, що вони пов’язані. Ми хочемо, щоб leaf знав, що branch є його батьком. Далі ми зробимо саме це.
Додавання посилання від дочірнього елемента до його батька
Щоб зробити дочірній вузол обізнаним про свого батька, нам потрібно додати поле parent до визначення нашої структури Node. Трудність полягає у визначенні того, яким має бути тип parent. Ми знаємо, що він не може містити Rc<T>, тому що це створило б цикл посилань із leaf.parent, що вказує на branch, і branch.children, що вказує на leaf, що спричинило б те, що їхні значення strong_count ніколи не були б 0.
Якщо подумати про відносини по-іншому, батьківський вузол повинен володіти своїми дочірніми елементами: якщо батьківський вузол звільняється, його дочірні вузли також мають бути звільнені. Однак дочірній елемент не повинен володіти своїм батьком: якщо ми звільняємо дочірній вузол, батьківський усе одно має існувати. Це випадок для слабких посилань!
Отже, замість Rc<T> ми зробимо тип parent таким, що використовує Weak<T>, а саме RefCell<Weak<Node>>. Тепер наше визначення структури Node виглядає так:
Filename: src/main.rs
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}Вузол зможе посилатися на свій батьківський вузол, але не володіє своїм батьком. У Listing 15-28 ми оновлюємо main, щоб використовувати це нове визначення, так що вузол leaf матиме спосіб посилатися на свого батька, branch.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}Створення вузла leaf виглядає подібно до Listing 15-27 за винятком поля parent: leaf починається без батька, тому ми створюємо новий порожній екземпляр посилання Weak<Node>.
На цьому етапі, коли ми намагаємося отримати посилання на батька leaf, використовуючи метод upgrade, ми отримуємо значення None. Ми бачимо це у виводі першого оператора println!:
leaf parent = None
Коли ми створюємо вузол branch, він також матиме нове посилання Weak<Node> у полі parent, тому що branch не має батьківського вузла. У нас усе ще є leaf як один із дочірніх елементів branch. Щойно ми маємо екземпляр Node у branch, ми можемо змінити leaf, щоб дати йому посилання Weak<Node> на його батька. Ми використовуємо метод borrow_mut на RefCell<Weak<Node>> у полі parent у leaf, а потім використовуємо функцію Rc::downgrade, щоб створити посилання Weak<Node> на branch з Rc<Node> у branch.
Коли ми знову друкуємо батька leaf, цього разу ми отримаємо варіант Some, що містить branch: тепер leaf може отримати доступ до свого батька! Коли ми друкуємо leaf, ми також уникаємо циклу, який зрештою завершився переповненням стека, як у Listing 15-26; посилання Weak<Node> друкуються як (Weak):
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
Відсутність нескінченного виводу вказує на те, що цей код не створив цикл посилань. Ми також можемо визначити це, подивившись на значення, які отримуємо з виклику Rc::strong_count і Rc::weak_count.
Візуалізація змін strong_count і weak_count
Давайте подивимося, як змінюються значення strong_count і weak_count екземплярів Rc<Node>, створивши нову внутрішню область видимості та перемістивши створення branch у цю область. Зробивши це, ми можемо побачити, що відбувається, коли branch створюється, а потім звільняється, коли виходить з області видимості. Зміни показано в Listing 15-29.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch),
);
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}Після створення leaf його Rc<Node> має сильний лічильник 1 і слабкий лічильник 0. У внутрішній області видимості ми створюємо branch і пов’язуємо його з leaf, після чого, коли ми друкуємо лічильники, Rc<Node> у branch матиме сильний лічильник 1 і слабкий лічильник 1 (за leaf.parent, що вказує на branch з Weak<Node>). Коли ми друкуємо лічильники в leaf, ми побачимо, що він матиме сильний лічильник 2, тому що branch тепер має клон Rc<Node> leaf, збережений у branch.children, але все ще матиме слабкий лічильник 0.
Коли внутрішня область видимості закінчується, branch виходить з області видимості, і сильний лічильник Rc<Node> зменшується до 0, тож його Node звільняється. Слабкий лічильник 1 з leaf.parent не має жодного впливу на те, чи буде Node звільнено, або ні, тож ми не отримуємо жодних витоків пам’яті!
Якщо ми спробуємо отримати доступ до батька leaf після завершення області видимості, ми знову отримаємо None. Наприкінці програми Rc<Node> у leaf має сильний лічильник 1 і слабкий лічильник 0, тому що змінна leaf тепер знову є єдиним посиланням на Rc<Node>.
Уся логіка, що керує лічильниками та звільненням значень, вбудована в Rc<T> і Weak<T> та їхні реалізації трейту Drop. Вказавши, що відношення від дочірнього елемента до його батька має бути посиланням Weak<T> у визначенні Node, ви можете мати батьківські вузли, що вказують на дочірні вузли, і навпаки, без створення циклу посилань і витоків пам’яті.
Підсумок
Цей розділ охоплював, як використовувати розумні вказівники, щоб робити різні гарантії та компроміси порівняно з тими, які Rust робить за замовчуванням зі звичайними посиланнями. Тип Box<T> має відомий розмір і вказує на дані, виділені в купі. Тип Rc<T> відстежує кількість посилань на дані в купі, щоб дані могли мати кількох власників. Тип RefCell<T> з його внутрішньою змінністю дає нам тип, який ми можемо використовувати, коли нам потрібен незмінний тип, але треба змінити внутрішнє значення цього типу; він також забезпечує правила запозичення під час виконання замість часу компіляції.
Також було розглянуто трейти Deref і Drop, які забезпечують багато функціональності розумних вказівників. Ми дослідили цикли посилань, які можуть спричиняти витоки пам’яті, і те, як запобігти їм за допомогою Weak<T>.
Якщо цей розділ викликав у вас інтерес і ви хочете реалізувати власні розумні вказівники, перегляньте “The Rustonomicon” для отримання більш корисної інформації.
Далі ми говоритимемо про конкурентність у Rust. Ви навіть дізнаєтеся про кілька нових розумних вказівників.
Конкурентність без страху (fearless concurrency)
Безпечна та ефективна обробка конкурентного програмування є ще однією з головних цілей Rust. Конкурентне програмування, у якому різні частини програми виконуються незалежно, і паралельне програмування, у якому різні частини програми виконуються одночасно, стають дедалі важливішими, оскільки все більше комп’ютерів використовують свої кілька процесорів. Історично програмування в цих контекстах було складним і схильним до помилок. Rust сподівається змінити це.
Спочатку команда Rust вважала, що забезпечення безпеки пам’яті та запобігання проблемам конкурентності — це дві окремі задачі, які слід розв’язувати різними методами. З часом команда виявила, що системи власності та типів є потужним набором інструментів, які допомагають керувати безпекою пам’яті і проблемами конкурентності! Використовуючи власність і перевірку типів, багато помилок конкурентності в Rust є помилками часу компіляції, а не помилками часу виконання. Тому, замість того щоб змушувати вас витрачати багато часу на відтворення точних обставин, за яких виникає помилка конкурентності часу виконання, неправильний код відмовиться компілюватися і покаже помилку, що пояснює проблему. У результаті ви можете виправити свій код, поки працюєте над ним, а не, можливо, після того, як він уже буде розгорнутий у production. Ми дали цій властивості Rust прізвисько конкурентність без страху (fearless concurrency). Конкурентність без страху дає змогу писати код, позбавлений тонких помилок, і який легко рефакторити, не вводячи нових помилок.
Примітка: Для простоти ми називатимемо багато проблем конкурентними, а не більш точно кажучи конкурентними та/або паралельними. У цій главі, будь ласка, подумки підставляйте конкурентними та/або паралельними щоразу, коли ми використовуємо конкурентними. У наступній главі, де ця відмінність має більше значення, ми будемо точнішими.
Багато мов є догматичними щодо рішень, які вони пропонують для обробки конкурентних проблем. Наприклад, Erlang має елегантну функціональність для конкурентності з передачею повідомлень, але має лише неочевидні способи ділитися станом між потоками. Підтримка лише підмножини можливих рішень є розумною стратегією для мов вищого рівня, тому що мова вищого рівня обіцяє переваги від того, що відмовляється від певного контролю заради отримання абстракцій. Однак від мов нижчого рівня очікується, що вони нададуть рішення з найкращою продуктивністю в будь-якій заданій ситуації і матимуть менше абстракцій над апаратним забезпеченням. Тому Rust пропонує різноманітні інструменти для моделювання проблем у будь-який спосіб, що є доречним для вашої ситуації та вимог.
Ось теми, які ми розглянемо в цій главі:
- Як створювати потоки для одночасного виконання кількох частин коду
- Конкурентність із передачею повідомлень, де канали надсилають повідомлення між потоками
- Конкурентність зі спільним станом, де кілька потоків мають доступ до деякої частини даних
- Трейт
SyncіSend, які поширюють гарантії конкурентності Rust на типи, визначені користувачем, а також на типи, надані стандартною бібліотекою
Використання потоків для одночасного виконання коду
Використання потоків для одночасного виконання коду
У більшості сучасних операційних систем виконуваний код програми запускається в процесі, і операційна система керуватиме кількома процесами одночасно. У межах програми ви також можете мати незалежні частини, які виконуються одночасно. Функції, що запускають ці незалежні частини, називаються потоками. Наприклад, вебсервер може мати кілька потоків, щоб він міг відповідати на більше ніж один запит одночасно.
Розбиття обчислення у вашій програмі на кілька потоків для одночасного виконання кількох завдань може покращити продуктивність, але це також додає складності. Оскільки потоки можуть виконуватися одночасно, немає вбудованої гарантії щодо порядку, у якому частини вашого коду в різних потоках будуть виконуватися. Це може призвести до проблем, таких як:
- Стан гонки даних, коли потоки звертаються до даних або ресурсів у непослідовному порядку
- Взаємне блокування, коли два потоки чекають один на одного, не даючи обом потокам продовжити виконання
- Помилки, які трапляються лише в певних ситуаціях і їх важко надійно відтворити та виправити
Rust намагається пом’якшити негативні наслідки використання потоків, але програмування в багатопотоковому контексті все одно потребує уважного обмірковування і вимагає структури коду, яка відрізняється від програм, що виконуються в одному потоці.
Мови програмування реалізують потоки кількома різними способами, і багато операційних систем надають API, який мова програмування може викликати для створення нових потоків. Стандартна бібліотека Rust використовує модель реалізації потоків 1:1, за якої програма використовує один потік операційної системи на один потік мови. Існують крейти, які реалізують інші моделі потоків, що роблять інші компроміси порівняно з моделлю 1:1. (Система async Rust, яку ми побачимо в наступному розділі, також надає інший підхід до конкурентності.)
Створення нового потоку за допомогою spawn
Щоб створити новий потік, ми викликаємо функцію thread::spawn і передаємо
їй замикання (ми говорили про замикання в розділі 13), що містить код,
який ми хочемо запустити в новому потоці. Приклад у Listing 16-1 виводить
частину тексту з головного потоку та інший текст із нового потоку.
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}Зверніть увагу, що коли головний потік програми Rust завершується, усі створені потоки завершуються, незалежно від того, чи встигли вони завершити виконання. Вивід цієї програми може трохи відрізнятися щоразу, але він виглядатиме приблизно так:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
Виклики thread::sleep змушують потік зупинити своє виконання на короткий
час, дозволяючи іншому потоку виконуватися. Потоки, ймовірно, будуть
чергуватися, але це не гарантується: це залежить від того, як ваша операційна
система планує потоки. У цьому запуску головний потік вивів першим, хоча
оператор виведення з створеного потоку з’являється в коді першим. І хоча ми
сказали створеному потоку виводити до i 9, він дійшов лише до 5
перед тим, як головний потік завершив роботу.
Якщо ви запустите цей код і побачите лише вивід із головного потоку або не побачите жодного накладання, спробуйте збільшити числа в діапазонах, щоб створити більше можливостей для операційної системи перемикатися між потоками.
Очікування завершення всіх потоків
Код у Listing 16-1 не лише передчасно зупиняє створений потік більшу частину часу через завершення головного потоку, але й тому, що немає гарантії щодо порядку, у якому виконуються потоки, ми також не можемо гарантувати, що створений потік взагалі встигне виконатися!
Ми можемо виправити проблему з тим, що створений потік не виконується або
завершується передчасно, зберігши повернене значення thread::spawn у
змінній. Повернений тип thread::spawn — JoinHandle<T>. JoinHandle<T> —
це власницьке значення, яке, коли ми викликаємо на ньому метод join, буде
чекати завершення свого потоку. Listing 16-2 показує, як використовувати
JoinHandle<T> потоку, який ми створили в Listing 16-1, і як викликати join,
щоб переконатися, що створений потік завершиться до виходу з main.
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
handle.join().unwrap();
}Виклик join на обробнику блокує потік, який зараз виконується, доки потік,
представлений обробником, не завершиться. Блокування потоку означає, що
цьому потоку заборонено виконувати роботу або завершуватися. Оскільки ми
помістили виклик join після циклу for головного потоку, запуск Listing 16-2
має дати вивід, подібний до цього:
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
Два потоки продовжують чергуватися, але головний потік чекає через
виклик handle.join() і не завершується, доки створений потік не закінчить
роботу.
Але подивімося, що станеться, коли ми натомість перемістимо handle.join()
перед цикл for у main, ось так:
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
handle.join().unwrap();
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}Головний потік чекатиме, поки створений потік завершиться, а потім виконає
свій цикл for, тож вивід більше не буде перемішаним, як показано тут:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
Невеликі деталі, такі як місце, де викликається join, можуть впливати на
те, чи будуть ваші потоки виконуватися одночасно.
Використання замикань move з потоками
Ми часто використовуватимемо ключове слово move із замиканнями, переданими
до thread::spawn, тому що тоді замикання бере у власність значення, які
воно використовує з оточення, тим самим передаючи власність цих значень з
одного потоку до іншого. У “Capturing References or Moving Ownership” у розділі 13 ми обговорювали move у контексті замикань. Тепер ми
зосередимося більше на взаємодії між move і thread::spawn.
Зверніть увагу в Listing 16-1, що замикання, яке ми передаємо до
thread::spawn, не приймає жодних аргументів: ми не використовуємо жодних
даних із головного потоку в коді створеного потоку. Щоб використати дані з
головного потоку в створеному потоці, замикання створеного потоку має
захопити потрібні йому значення. Listing 16-3 показує спробу створити вектор у
головному потоці та використати його в створеному потоці. Однак це ще не
спрацює, як ви побачите за мить.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}Замикання використовує v, тож воно захопить v і зробить його частиною
середовища замикання. Оскільки thread::spawn запускає це замикання в новому
потоці, ми мали б мати змогу звертатися до v у тому новому потоці. Але коли
ми компілюємо цей приклад, отримуємо таку помилку:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {v:?}");
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust виводить, як саме захопити v, і оскільки println! потрібне лише
посилання на v, замикання намагається позичити v. Однак є проблема: Rust
не може визначити, як довго працюватиме створений потік, тож він не знає, чи
посилання на v завжди буде дійсним.
Listing 16-4 надає сценарій, у якому ймовірніше буде посилання на v, яке
не буде дійсним.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
drop(v); // oh no!
handle.join().unwrap();
}Якби Rust дозволив нам запустити цей код, існувала б можливість, що створений
потік буде негайно переведено у фоновий режим без жодного виконання. У
створеного потоку всередині є посилання на v, але головний потік негайно
скидає v, використовуючи функцію drop, яку ми обговорювали в розділі 15.
Потім, коли створений потік почне виконуватися, v уже не буде дійсним, тож
посилання на нього також буде недійсним. Ой-ой!
Щоб виправити помилку компілятора в Listing 16-3, ми можемо скористатися порадами з повідомлення про помилку:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
Додавши ключове слово move перед замиканням, ми змушуємо замикання
взяти у власність значення, які воно використовує, замість того, щоб Rust
вивів, що воно має позичати ці значення. Зміна до Listing 16-3, показана в
Listing 16-5, скомпілюється і працюватиме так, як ми задумали.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}Ми могли б спробувати те саме, щоб виправити код у Listing 16-4, де головний
потік викликав drop, використавши замикання move. Однак це виправлення не
спрацює, тому що те, що намагається зробити Listing 16-4, заборонено з іншої
причини. Якби ми додали move до замикання, ми б перемістили v у
середовище замикання, і більше не могли б викликати drop для нього в
головному потоці. Замість цього ми отримали б таку помилку компілятора:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = v.clone();
7 ~ let handle = thread::spawn(move || {
8 ~ println!("Here's a vector: {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Правила власності Rust знову нас врятували! Ми отримали помилку з коду в
Listing 16-3, тому що Rust поводився обережно і лише позичав v для потоку,
що означало, що головний потік теоретично міг зробити посилання створеного
потоку недійсним. Сказавши Rust перемістити власність v до створеного
потоку, ми гарантуємо Rust, що головний потік більше не використовуватиме
v. Якщо ми змінимо Listing 16-4 так само, то тоді порушимо правила
власності, коли спробуємо використати v у головному потоці. Ключове слово
move скасовує обережне значення Rust за замовчуванням щодо запозичення; воно
не дає нам порушити правила власності.
Тепер, коли ми розглянули, що таке потоки і які методи надає API потоків, давайте подивимося на деякі ситуації, у яких ми можемо використовувати потоки.
Передавання даних між потоками за допомогою передавання повідомлень
Передавання даних між потоками за допомогою передавання повідомлень
Один дедалі популярніший підхід до забезпечення безпечної конкурентності — передавання повідомлень (message passing), за якого потоки або актори спілкуються, надсилаючи один одному повідомлення, що містять дані. Ось ідея у вигляді гасла з документації мови Go: «Не спілкуйтеся, ділячись пам’яттю; натомість діліться пам’яттю, спілкуючись».
Щоб реалізувати конкурентність із надсиланням повідомлень, стандартна бібліотека Rust надає реалізацію каналів. Канал — це загальна концепція програмування, за допомогою якої дані надсилаються з одного потоку до іншого.
У програмуванні канал можна уявити як спрямований водний канал, наприклад струмок або річку. Якщо ви кинете щось на кшталт гумової качечки в річку, вона попливе вниз за течією до кінця водного шляху.
Канал має дві половини: передавач і приймач. Половина передавача — це верхня за течією локація, куди ви кладете гумову качечку в річку, а половина приймача — це місце нижче за течією, де гумова качечка опиняється. Одна частина вашого коду викликає методи на передавачі з даними, які ви хочете надіслати, а інша частина перевіряє кінцеву точку приймання на наявність повідомлень, що надходять. Про канал кажуть, що він закритий, якщо або половина передавача, або половина приймача видалена.
Тут ми дійдемо до програми, яка має один потік для генерації значень і надсилання їх каналом, та інший потік, який отримуватиме значення й друкуватиме їх. Ми надсилатимемо прості значення між потоками за допомогою каналу, щоб продемонструвати цю можливість. Коли ви ознайомитеся з цією технікою, ви зможете використовувати канали для будь-яких потоків, яким потрібно спілкуватися один з одним, наприклад для чат-системи або системи, де багато потоків виконують частини обчислення й надсилають ці частини одному потоку, який агрегує результати.
Спочатку, у переліку 16-6, ми створимо канал, але нічого з ним не робитимемо. Зверніть увагу, що це ще не скомпілюється, оскільки Rust не може визначити, значення якого типу ми хочемо надсилати через канал.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}Ми створюємо новий канал за допомогою функції mpsc::channel; mpsc означає
multiple producer, single consumer. Коротко кажучи, спосіб, у який стандартна бібліотека Rust
реалізує канали, означає, що канал може мати кілька sending кінців, які створюють значення, але лише один receiving кінець, який споживає ці значення. Уявіть кілька струмків, що впадають в одну велику річку: усе, що надіслано будь-яким зі струмків, опиниться наприкінці в одній річці. Поки що ми почнемо з одного producer, але додамо кількох producers, коли доведемо цей приклад до робочого стану.
Функція mpsc::channel повертає кортеж, перший елемент якого — це кінець надсилання — передавач, а другий елемент — це кінець отримання — приймач. Скорочення tx і rx традиційно використовуються в багатьох сферах для transmitter і receiver, відповідно, тож ми називаємо наші змінні саме так, щоб позначити кожен кінець. Ми використовуємо оператор let із зразком, який деструктурує кортежі; про використання зразків в операторах let і деструктурування ми поговоримо в главі 19. Поки що знайте, що використання оператора let у такий спосіб — це зручний підхід до вилучення частин кортежу, повернутого mpsc::channel.
Давайте перемістимо кінець передавання в створений потік і змусимо його надіслати один рядок, щоб створений потік спілкувався з головним потоком, як показано в переліку 16-7. Це як покласти гумову качечку в річку вище за течією або надіслати чат-повідомлення з одного потоку до іншого.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
}Знову ми використовуємо thread::spawn, щоб створити новий потік, а потім використовуємо move, щоб перемістити tx у замикання, щоб створений потік володів tx. Створений потік повинен володіти передавачем, щоб мати змогу надсилати повідомлення через канал.
У передавача є метод send, який приймає значення, яке ми хочемо надіслати. Метод send повертає тип Result<T, E>, тож якщо приймач уже видалено і нікуди надсилати значення, операція надсилання поверне помилку. У цьому прикладі ми викликаємо unwrap, щоб викликати паніку у разі помилки. Але в реальному застосунку ми обробили б це належним чином: поверніться до глави 9, щоб переглянути стратегії належної обробки помилок.
У переліку 16-8 ми отримаємо значення від приймача в головному потоці. Це як дістати гумову качечку з води наприкінці річки або отримати чат-повідомлення.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}У приймача є два корисні методи: recv і try_recv. Ми використовуємо recv, скорочення від receive, який заблокує виконання головного потоку і чекатиме, доки в канал не буде надіслано значення. Щойно значення буде надіслано, recv поверне його в Result<T, E>. Коли передавач закривається, recv поверне помилку, щоб сигналізувати, що більше значень не надходитиме.
Метод try_recv не блокує, а натомість негайно повертає Result<T, E>: значення Ok, що містить повідомлення, якщо воно доступне, і значення Err, якщо цього разу жодних повідомлень немає. Використання try_recv корисне, якщо цей потік має іншу роботу, поки очікує повідомлень: ми могли б написати цикл, який час від часу викликає try_recv, обробляє повідомлення, якщо воно доступне, а інакше певний час виконує іншу роботу, доки не перевірить знову.
У цьому прикладі ми використали recv для простоти; у головного потоку немає іншої роботи, окрім очікування повідомлень, тож блокування головного потоку є доречним.
Коли ми запустимо код у переліку 16-8, ми побачимо, як значення надруковано з головного потоку:
Got: hi
Чудово!
Передавання власності через канали
Правила власності відіграють життєво важливу роль у надсиланні повідомлень, оскільки вони допомагають вам писати безпечний, конкурентний код. Запобігання помилкам у конкурентному програмуванні — це перевага того, що ви мислите про власність упродовж усіх ваших програм Rust. Давайте проведемо експеримент, щоб показати, як канали й власність працюють разом, щоб запобігати проблемам: ми спробуємо використати значення val у створеному потоці після того, як ми надіслали його каналом. Спробуйте скомпілювати код у переліку 16-9, щоб побачити, чому цей код не дозволений.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {val}");
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}Тут ми намагаємося надрукувати val після того, як надіслали його каналом через tx.send. Дозволити це було б поганою ідеєю: щойно значення надіслано в інший потік, той потік може змінити його або видалити, перш ніж ми спробуємо використати значення знову. Потенційно зміни іншого потоку могли б спричинити помилки або неочікувані результати через несумісні або відсутні дані. Однак Rust видає нам помилку, якщо ми спробуємо скомпілювати код у переліку 16-9:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:27
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {val}");
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` (bin "message-passing") due to 1 previous error
Наша помилка конкурентності спричинила помилку часу компіляції. Функція send приймає власність свого параметра, і коли значення переміщується, приймач бере його у власність. Це зупиняє нас від випадкового повторного використання значення після надсилання; система власності перевіряє, що все гаразд.
Надсилання кількох значень
Код у переліку 16-8 скомпілювався і запрацював, але він не показав нам чітко, що два окремі потоки спілкувалися один з одним через канал.
У переліку 16-10 ми внесли деякі зміни, які доведуть, що код у переліку 16-8 виконується конкурентно: створений потік тепер надсилатиме кілька повідомлень і робитиме паузу на секунду між кожним повідомленням.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
}Цього разу створений потік має вектор рядків, які ми хочемо надіслати в головний потік. Ми ітеруємося по них, надсилаючи кожен окремо, і робимо паузу між кожним, викликаючи функцію thread::sleep зі значенням Duration в одну секунду.
У головному потоці ми більше не викликаємо функцію recv явно: натомість ми розглядаємо rx як ітератор. Для кожного отриманого значення ми його друкуємо. Коли канал закривається, ітерація завершується.
Під час запуску коду в переліку 16-10 ви повинні побачити такий вивід із паузою в одну секунду між кожним рядком:
Got: hi
Got: from
Got: the
Got: thread
Оскільки у нас немає жодного коду, який робить паузу або затримку в циклі for у головному потоці, ми можемо зрозуміти, що головний потік чекає отримання значень від створеного потоку.
Створення кількох producer
Раніше ми згадували, що mpsc — це акронім для multiple producer, single consumer. Давайте застосуємо mpsc на практиці й розширимо код у переліку 16-10, щоб створити кілька потоків, які всі надсилатимуть значення одному й тому самому приймачу. Ми можемо зробити це, клонуючи передавач, як показано в переліку 16-11.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
// --snip--
}Цього разу, перед тим як ми створимо перший створений потік, ми викликаємо clone на передавачі. Це дасть нам новий передавач, який ми зможемо передати першому створеному потоку. Ми передаємо оригінальний передавач другому створеному потоку. Це дає нам два потоки, кожен із яких надсилає різні повідомлення одному приймачу.
Коли ви запустите код, ваш вивід має виглядати приблизно так:
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
Ви можете побачити значення в іншому порядку, залежно від вашої системи. Саме це робить конкурентність цікавою, а також складною. Якщо ви поекспериментуєте з thread::sleep, задаючи йому різні значення в різних потоках, кожен запуск буде більш недетермінованим і щоразу створюватиме інший вивід.
Тепер, коли ми подивилися, як працюють канали, давайте подивимося на інший метод конкурентності.
Конкурентність зі спільним станом
Конкурентність із спільним станом (Shared-State Concurrency)
Передавання повідомлень — це хороший спосіб обробки конкурентності, але це не єдиний спосіб. Інший метод полягає в тому, щоб кілька потоків отримували доступ до тих самих спільних даних. Знову розгляньте цю частину гасла з документації мови Go: “Do not communicate by sharing memory.”
Як би виглядала комунікація через спільне використання пам’яті? Крім того, чому прихильники передавання повідомлень застерігають не використовувати спільне використання пам’яті?
Певним чином канали в будь-якій мові програмування схожі на одиничну власність (ownership), тому що після того, як ви передаєте значення через канал, ви більше не повинні використовувати це значення. Конкурентність із спільною пам’яттю схожа на множинну власність: кілька потоків можуть одночасно отримувати доступ до однієї й тієї самої ділянки пам’яті. Як ви бачили в Розділі 15, де розумні вказівники зробили можливою множинну власність, множинна власність може додавати складності, тому що цими різними власниками потрібно керувати. Система типів Rust і правила власності значною мірою допомагають правильно організувати це керування. Для прикладу, розгляньмо м’ютекси, один із найпоширеніших примітивів конкурентності для спільної пам’яті.
Керування доступом за допомогою м’ютексів
Mutex — це скорочення від mutual exclusion, тобто м’ютекс дозволяє лише одному потоку отримувати доступ до певних даних у будь-який момент часу. Щоб отримати доступ до даних у м’ютексі, потік спочатку має повідомити, що хоче доступу, попросивши захопити блокування м’ютекса. Lock — це структура даних, яка є частиною м’ютекса і відстежує, хто наразі має виключний доступ до даних. Тому про м’ютекс кажуть, що він охороняє дані, які він містить, через систему блокування.
М’ютекси мають репутацію складних у використанні, тому що вам потрібно пам’ятати два правила:
- Ви повинні спробувати захопити блокування перед використанням даних.
- Коли ви закінчили з даними, які охороняє м’ютекс, ви повинні розблокувати дані, щоб інші потоки могли захопити блокування.
Як реальну метафору для м’ютекса уявіть панельну дискусію на конференції лише з одним мікрофоном. Перш ніж учасник панелі зможе говорити, він має попросити або подати сигнал, що хоче використати мікрофон. Коли він отримує мікрофон, він може говорити стільки, скільки хоче, а потім передати мікрофон наступному учаснику панелі, який попросить слова. Якщо учасник панелі забуде передати мікрофон, коли закінчить із ним, ніхто інший не зможе говорити. Якщо керування спільним мікрофоном піде не так, панель не працюватиме згідно з планом!
Керування м’ютексами може бути неймовірно складним, щоб зробити його правильним, саме тому так багато людей захоплюються каналами. Однак завдяки системі типів Rust і правилам власності ви не можете помилитися з блокуванням і розблокуванням.
API Mutex<T>
Як приклад використання м’ютекса, почнімо з використання м’ютекса в однопотоковому контексті, як показано в Listing 16-12.
use std::sync::Mutex;
fn main() {
let m = Mutex::new(5);
{
let mut num = m.lock().unwrap();
*num = 6;
}
println!("m = {m:?}");
}Як і для багатьох типів, ми створюємо Mutex<T> за допомогою асоційованої функції new.
Щоб отримати доступ до даних усередині м’ютекса, ми використовуємо метод lock, щоб захопити
блокування. Цей виклик заблокує поточний потік, тож він не зможе виконувати жодної роботи,
доки не настане наша черга мати блокування.
Виклик lock завершився б помилкою, якби інший потік, що утримує блокування, запанікував. У
такому разі ніхто ніколи не зміг би отримати блокування, тому ми вирішили
unwrap і змусити цей потік запанікувати, якщо ми опинимося в такій ситуації.
Після того як ми захопили блокування, ми можемо поводитися з поверненим значенням, яке тут назване num, як із змінним посиланням на дані всередині. Система типів гарантує, що ми
захоплюємо блокування перед використанням значення в m. Тип m —
Mutex<i32>, а не i32, тож ми маємо викликати lock, щоб мати змогу використати
значення i32. Ми не можемо забути; система типів не дозволить нам інакше
отримати доступ до внутрішнього i32.
Виклик lock повертає тип під назвою MutexGuard, загорнутий у
LockResult, з яким ми впоралися за допомогою виклику unwrap. Тип MutexGuard
реалізує Deref, щоб вказувати на наші внутрішні дані; цей тип також має
реалізацію Drop, яка автоматично звільняє блокування, коли MutexGuard
виходить з області видимості, що відбувається наприкінці внутрішньої області видимості. Як наслідок, ми
не ризикуємо забути звільнити блокування і заблокувати використання м’ютекса
іншими потоками, тому що звільнення блокування відбувається автоматично.
Після скидання блокування ми можемо надрукувати значення м’ютекса і побачити, що змогли
змінити внутрішній i32 на 6.
Спільний доступ до Mutex<T>
Тепер спробуймо поділити значення між кількома потоками за допомогою Mutex<T>. Ми
запустимо 10 потоків і змусимо кожен із них збільшити значення лічильника на 1, тож
лічильник перейде від 0 до 10. Приклад у Listing 16-13 матиме помилку компілятора, і
ми використаємо цю помилку, щоб дізнатися більше про використання Mutex<T> і про те, як
Rust допомагає нам використовувати його правильно.
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Ми створюємо змінну counter, щоб зберігати i32 усередині Mutex<T>, як і в
Listing 16-12. Далі ми створюємо 10 потоків, ітеруючись по діапазону
чисел. Ми використовуємо thread::spawn і даємо всім потокам одне й те саме замикання:
таке, що переміщує counter у потік, захоплює блокування на Mutex<T>, викликаючи
метод lock, а потім додає 1 до значення в м’ютексі. Коли потік
завершує виконання свого замикання, num вийде з області видимості та звільнить
блокування, щоб інший потік міг його захопити.
У головному потоці ми збираємо всі приєднувані дескриптори. Потім, як ми робили в Listing
16-2, ми викликаємо join для кожного дескриптора, щоб переконатися, що всі потоки завершилися. У
цей момент головний потік захопить блокування і надрукує результат цієї
програми.
Ми натякнули, що цей приклад не скомпілюється. Тепер з’ясуймо, чому!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: borrow of moved value: `counter`
--> src/main.rs:21:29
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `std::sync::Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let handle = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Result: {}", *counter.lock().unwrap());
| ^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = counter.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Повідомлення про помилку каже, що значення counter було переміщене під час попередньої
ітерації циклу. Rust повідомляє нам, що ми не можемо перемістити власність на
блокування counter у кілька потоків. Давайте виправимо помилку компілятора за допомогою
методу множинної власності, який ми обговорювали в Розділі 15.
Множинна власність з кількома потоками
У Розділі 15 ми надали значення кільком власникам, використовуючи розумний вказівник
Rc<T> для створення значення з підрахунком посилань. Зробімо те саме тут і подивімося,
що станеться. Ми загорнемо Mutex<T> в Rc<T> у Listing 16-14 і клонуватимемо
Rc<T> перед переміщенням власності до потоку.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Ще раз компілюємо і отримуємо… інші помилки! Компілятор багато чому нас навчає:
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:723:1
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Ого, це повідомлення про помилку дуже багатослівне! Ось на чому важливо зосередитися:
`Rc<Mutex<i32>>` cannot be sent between threads safely. Компілятор
також повідомляє нам причину: the trait `Send` is not implemented for `Rc<Mutex<i32>>`. Про Send ми поговоримо в наступному розділі: це один із
трейтів, які гарантують, що типи, які ми використовуємо з потоками, призначені для використання в
конкурентних ситуаціях.
На жаль, Rc<T> не є безпечним для спільного використання між потоками. Коли Rc<T>
керує лічильником посилань, він додає до лічильника для кожного виклику clone і
віднімає від лічильника, коли кожен клон видаляється. Але він не використовує жодних
примітивів конкурентності, щоб переконатися, що зміни лічильника не можуть бути
перервані іншим потоком. Це може призвести до неправильних лічильників — тонких помилок, які
у свою чергу можуть призвести до витоків пам’яті або до того, що значення буде видалене до того, як ми
з ним закінчимо. Нам потрібен тип, який є точно таким самим, як Rc<T>, але який робить
зміни лічильника посилань у безпечний для потоків спосіб.
Атомарне лічення посилань з Arc<T>
На щастя, Arc<T> є типом, подібним до Rc<T>, який безпечно використовувати в
конкурентних ситуаціях. a означає atomic, тобто це тип із атомарним
підрахунком посилань. Атоміки — це додатковий вид примітива
конкурентності, який ми не будемо детально розглядати тут: дивіться документацію стандартної бібліотеки
для std::sync::atomic для отримання
додаткових відомостей. На цьому етапі вам достатньо знати, що атоміки працюють як примітивні
типи, але безпечні для спільного використання між потоками.
Тоді ви можете спитати, чому всі примітивні типи не є атомарними і чому типи стандартної
бібліотеки не реалізовані так, щоб за замовчуванням використовувати Arc<T>. Причина в тому, що
безпечність для потоків має пов’язаний із нею штраф за продуктивність, який ви хочете платити лише тоді, коли
вам це справді потрібно. Якщо ви просто виконуєте операції над значеннями в межах
одного потоку, ваш код може працювати швидше, якщо йому не потрібно забезпечувати
гарантії, які надають атоміки.
Повернімося до нашого прикладу: Arc<T> і Rc<T> мають той самий API, тож ми виправляємо
нашу програму, змінюючи рядок use, виклик new і виклик clone. Код у Listing 16-15 нарешті скомпілюється і запуститься.
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Цей код виведе таке:
Result: 10
Ми зробили це! Ми порахували від 0 до 10, що може й не здаватися дуже вражаючим, але це
навчило нас багато чому про Mutex<T> і безпечність для потоків. Ви також можете використати структуру цієї програми
для виконання складніших операцій, ніж просто збільшення лічильника. Використовуючи цю стратегію,
ви можете розбити обчислення на незалежні
частини, розподілити ці частини між потоками, а потім використати Mutex<T>, щоб кожен
потік оновлював остаточний результат своєю частиною.
Зауважте, що якщо ви виконуєте прості числові операції, існують типи простіші,
ніж типи Mutex<T>, які надає std::sync::atomic module of the
standard library. Ці типи забезпечують безпечний, конкурентний,
атомарний доступ до примітивних типів. Ми вирішили використати Mutex<T> з примітивним
типом для цього прикладу, щоб зосередитися на тому, як працює Mutex<T>.
Порівняння RefCell<T>/Rc<T> і Mutex<T>/Arc<T>
Ви могли помітити, що counter є незмінним, але ми могли отримати
змінне посилання на значення всередині нього; це означає, що Mutex<T> забезпечує
внутрішню змінність, як і родина Cell. Так само, як ми використовували
RefCell<T> у Розділі 15, щоб мати змогу змінювати вміст усередині Rc<T>, ми
використовуємо Mutex<T> для зміни вмісту усередині Arc<T>.
Ще одна деталь, на яку варто звернути увагу: Rust не може захистити вас від усіх видів логічних
помилок, коли ви використовуєте Mutex<T>. Згадайте з Розділу 15, що використання Rc<T> несло
ризик створення циклів посилань, коли два значення Rc<T> посилаються одне на одне, спричиняючи
витоки пам’яті. Подібним чином Mutex<T> несе ризик створення deadlocks. Вони виникають, коли операції потрібно
заблокувати два ресурси, і два потоки вже захопили по одному з блокувань, через що вони чекають
один на одного вічно. Якщо вас цікавлять deadlocks, спробуйте створити програму Rust, у якій є deadlock; потім
дослідіть стратегії пом’якшення deadlock для м’ютексів у будь-якій мові і спробуйте реалізувати їх у Rust. Документація API стандартної бібліотеки для Mutex<T> і MutexGuard
містить корисну інформацію.
Ми завершимо цей розділ, говорячи про трейт Send і Sync та
про те, як ми можемо використовувати їх із власними типами.
Розширювана конкурентність з Send та Sync
Розширювана конкурентність без страху (fearless concurrency) з Send і Sync
Цікаво, що майже кожна функція конкурентності, про яку ми говорили дотепер у цій главі, була частиною стандартної бібліотеки, а не мови. Ваші варіанти для обробки конкурентності не обмежуються мовою або стандартною бібліотекою; ви можете написати власні функції конкурентності або використовувати ті, що написані іншими.
Однак серед ключових концепцій конкурентності, які вбудовані в мову
замість стандартної бібліотеки, є трейти std::marker Send і Sync.
Передача власності між потоками
Маркований трейт Send вказує, що власність значень типу,
який реалізує Send, може бути передана між потоками. Майже кожен тип Rust
реалізує Send, але є деякі винятки, зокрема Rc<T>: він
не може реалізовувати Send, тому що якщо ви клонували б значення Rc<T> і спробували б
передати власність клону іншому потоку, обидва потоки могли б оновити
лічильник посилань одночасно. З цієї причини Rc<T> реалізовано
для використання в однопотокових ситуаціях, де ви не хочете сплачувати
штраф за продуктивність безпечності потоків.
Отже, система типів Rust і обмеження трейта гарантують, що ви ніколи
випадково не надішлете значення Rc<T> між потоками небезпечно. Коли ми спробували зробити
це у Listing 16-14, ми отримали помилку the trait `Send` is not implemented for `Rc<Mutex<i32>>`. Коли ми перейшли до Arc<T>, який реалізує Send, код скомпілювався.
Будь-який тип, повністю складений із типів Send, автоматично позначається як Send також. Майже всі примітивні типи є Send, за винятком сирих вказівників, про які
ми поговоримо в Chapter 20.
Доступ із кількох потоків
Маркований трейт Sync вказує, що безпечно, коли на тип, який реалізує
Sync, є посилання з кількох потоків. Іншими словами, будь-який тип T
реалізує Sync, якщо &T (незмінне посилання на T) реалізує Send,
тобто посилання можна безпечно надіслати іншому потоку. Подібно до Send,
усі примітивні типи реалізують Sync, і типи, повністю складені з типів, які
реалізують Sync, також реалізують Sync.
Розумний вказівник Rc<T> також не реалізує Sync з тих самих причин,
що й не реалізує Send. Тип RefCell<T> (про який ми говорили
в Chapter 15) і сімейство пов’язаних типів Cell<T> не реалізують
Sync. Реалізація перевірки запозичень, яку RefCell<T> виконує під час виконання,
не є потокобезпечною. Розумний вказівник Mutex<T> реалізує Sync і може бути
використаний для спільного доступу з кількома потоками, як ви бачили в “Shared Access to
Mutex<T>”.
Ручна реалізація Send і Sync є небезпечною
Оскільки типи, повністю складені з інших типів, які реалізують трейти Send і
Sync, також автоматично реалізують Send і Sync, нам не потрібно
реалізовувати ці трейти вручну. Як марковані трейти, вони навіть не мають жодних
методів для реалізації. Вони просто корисні для забезпечення інваріантів, пов’язаних із
конкурентністю.
Ручна реалізація цих трейтів передбачає реалізацію небезпечного коду Rust.
Ми поговоримо про використання небезпечного коду Rust у Chapter 20; наразі важлива
інформація полягає в тому, що побудова нових конкурентних типів, які не складаються з
частин Send і Sync, вимагає уважного обмірковування, щоб зберегти гарантії безпеки. “The
Rustonomicon” містить більше інформації про ці гарантії та про те, як їх
зберігати.
Підсумок
Це не останнє, що ви побачите про конкурентність у цій книзі: наступна глава зосереджується на async-програмуванні, а проєкт у Chapter 21 використовуватиме концепції з цієї глави в більш реалістичній ситуації, ніж менші приклади, обговорені тут.
Як згадувалося раніше, оскільки дуже мало з того, як Rust обробляє конкурентність, є частиною мови, багато рішень для конкурентності реалізовано як крейти. Вони розвиваються швидше, ніж стандартна бібліотека, тож обов’язково шукайте в інтернеті актуальні, найкращі крейти для використання в багатопотокових ситуаціях.
Стандартна бібліотека Rust надає канали для передавання повідомлень і типи
розумних вказівників, такі як Mutex<T> і Arc<T>, які безпечно використовувати в
конкурентних контекстах. Система типів і перевірник запозичень
гарантують, що код, який використовує ці рішення, не матиме станів гонки даних або некоректних посилань.
Коли ви змусите ваш код скомпілюватися, ви можете бути впевнені, що він із задоволенням
працюватиме на кількох потоках без тих видів складних для виявлення помилок, які є поширеними в
інших мовах. Конкурентне програмування більше не є концепцією, якої треба боятися:
Ідіть уперед і робіть ваші програми конкурентними, без страху!
Основи асинхронного програмування: Async, Await, Futures, and Streams
Багато операцій, які ми просимо комп’ютер виконати, можуть займати певний час, щоб завершитися. Було б добре, якби ми могли робити щось інше, поки чекаємо, доки ці довготривалі процеси завершаться. Сучасні комп’ютери пропонують дві техніки для роботи більш ніж над однією операцією одночасно: паралелізм і конкурентність. Логіка наших програм, однак, здебільшого написана лінійно. Ми хотіли б мати змогу задавати операції, які має виконати програма, і точки, в яких функція могла б призупинитися, а натомість могла б виконуватися якась інша частина програми, без потреби заздалегідь точно визначати порядок і спосіб, у яких має виконуватися кожен фрагмент коду. Асинхронне програмування — це абстракція, яка дає змогу нам виражати наш код у термінах потенційних точок призупинення та кінцевих результатів, а далі бере на себе деталі координації за нас.
У цьому розділі ми спираємося на використання потоків для паралелізму і конкурентності з розділу 16, вводячи альтернативний підхід до написання коду: futures, streams у Rust, а також синтаксис async і await, які дають нам змогу виражати, як операції можуть бути асинхронними, і сторонні крейти, що реалізують асинхронні runtime: код, який керує виконанням асинхронних операцій і координує його.
Розгляньмо приклад. Припустімо, ви експортуєте створене вами відео сімейного свята — операцію, яка може тривати від кількох хвилин до кількох годин. Експорт відео використовуватиме стільки потужності CPU і GPU, скільки зможе. Якби у вас було лише одне ядро CPU, а ваша операційна система не призупиняла б цей експорт до його завершення — тобто якби вона виконувала експорт синхронно — ви не могли б робити нічого іншого на своєму комп’ютері, поки виконувалася б ця задача. Це був би доволі дратівливий досвід. На щастя, операційна система вашого комп’ютера може, і робить це, непомітно переривати експорт достатньо часто, щоб ви могли одночасно виконувати іншу роботу.
Тепер припустімо, що ви завантажуєте відео, яким поділилася інша людина, що теж може зайняти певний час, але не потребує стільки CPU. У цьому випадку CPU має чекати, доки дані надійдуть із мережі. Хоча ви можете почати читати дані, щойно вони почнуть надходити, може знадобитися деякий час, щоб з’явилися всі дані. Навіть коли всі дані вже наявні, якщо відео досить велике, може знадобитися принаймні секунда чи дві, щоб завантажити його повністю. Це може звучати не так вже й багато, але для сучасного процесора, який може виконувати мільярди операцій щосекунди, це дуже довгий час. І знову ж таки, ваша операційна система непомітно перерве вашу програму, щоб дозволити CPU виконувати іншу роботу, поки чекає на завершення мережевого виклику.
Експорт відео — це приклад операції, обмеженої CPU або обчислювально обмеженої. Вона обмежена потенційною швидкістю обробки даних комп’ютера в межах CPU або GPU, і тим, яку частину цієї швидкості він може виділити для цієї операції. Завантаження відео — це приклад операції, обмеженої I/O, тому що вона обмежена швидкістю введення-виведення комп’ютера; вона може рухатися лише так швидко, як дані можуть бути надіслані мережею.
У цих двох прикладах непомітні переривання операційної системи забезпечують форму конкурентності. Однак ця конкурентність відбувається лише на рівні всієї програми: операційна система перериває одну програму, щоб дати іншим програмам виконати роботу. У багатьох випадках, оскільки ми розуміємо наші програми на значно більш дрібному рівні, ніж операційна система, ми можемо помітити можливості для конкурентності, яких операційна система не бачить.
Наприклад, якщо ми створюємо інструмент для керування завантаженнями файлів, ми повинні мати змогу написати нашу програму так, щоб запуск одного завантаження не блокував UI, і користувачі мали змогу запускати кілька завантажень одночасно. Проте багато API операційних систем для взаємодії з мережею є блокувальними; тобто вони блокують прогрес програми, доки дані, які вони обробляють, не будуть повністю готові.
Примітка: якщо подумати, саме так працює більшість викликів функцій. Однак термін blocking зазвичай уживають для викликів функцій, що взаємодіють із файлами, мережею чи іншими ресурсами на комп’ютері, тому що саме в цих випадках окрема програма виграє від того, що операція є не-blocking.
Ми могли б уникнути блокування нашого головного потоку, запустивши окремий потік для завантаження кожного файла. Однак накладні витрати системних ресурсів, які використовували б ці потоки, зрештою стали б проблемою. Було б краще, якби виклик не блокував узагалі, і натомість ми могли б визначити певну кількість tasks, які наша програма має завершити, і дозволити runtime обрати найкращий порядок і спосіб, у яких їх запускати.
Саме це й дає нам async Rust (скорочено від asynchronous). У цьому розділі ви дізнаєтеся все про async, коли ми розглянемо такі теми:
- Як використовувати синтаксис Rust
asyncіawaitта виконувати асинхронні функції з runtime - Як використовувати модель async, щоб розв’язати деякі з тих самих завдань, які ми розглядали в розділі 16
- Як багатопотоковість і async забезпечують взаємодоповнювальні рішення, які в багатьох випадках можна поєднувати
Перш ніж ми побачимо, як async працює на практиці, однак, нам потрібно зробити короткий відступ, щоб обговорити відмінності між паралелізмом і конкурентністю.
Паралелізм і конкурентність
Досі ми здебільшого вживали паралелізм і конкурентність як взаємозамінні. Тепер нам потрібно точніше розрізняти їх, тому що ці відмінності стануть помітними, коли ми почнемо працювати.
Розгляньте різні способи, якими команда могла б поділити роботу над проєктом із розробки програмного забезпечення. Ви могли б призначити одному учаснику кілька tasks, призначити кожному учаснику по одній task або використати поєднання цих двох підходів.
Коли окрема людина працює над кількома різними tasks до завершення будь-якої з них, це — конкурентність. Один зі способів реалізувати конкурентність схожий на ситуацію, коли на вашому комп’ютері відкрито два різні проєкти, і коли ви нудьгуєте або застрягаєте на одному проєкті, ви перемикаєтеся на інший. Ви — лише одна людина, тож не можете просуватися в обох tasks одночасно, але можете виконувати кілька справ одночасно, просуваючись по одній за раз шляхом перемикання між ними (див. Рисунок 17-1).

Коли команда ділить групу tasks так, що кожен учасник бере одну task і працює над нею самостійно, це — паралелізм. Кожна людина в команді може просуватися одночасно (див. Рисунок 17-2).

В обох цих робочих процесах вам може знадобитися координувати різні tasks. Можливо, ви думали, що task, призначена одній людині, є повністю незалежною від роботи всіх інших, але насправді для її завершення спочатку потрібно, щоб інша людина в команді завершила свою task. Частину роботи можна було б виконати паралельно, але частина насправді була послідовною: вона могла відбуватися лише в серії, одна task за іншою, як на Рисунку 17-3.

Так само ви можете зрозуміти, що одна з ваших власних tasks залежить від іншої вашої task. Тепер ваша конкурентна робота також стала послідовною.
Паралелізм і конкурентність також можуть перетинатися. Якщо ви дізнаєтеся, що ваш колега застряг, доки ви не завершите одну зі своїх tasks, ви, ймовірно, зосередите всі свої зусилля на цій task, щоб «розблокувати» вашого колегу. Ви і ваш співробітник більше не можете працювати паралельно, і ви також більше не можете працювати конкурентно над власними tasks.
Ті самі базові динаміки мають місце і в програмному та апаратному забезпеченні. На машині з одним ядром CPU процесор може виконувати лише одну операцію за раз, але все одно може працювати конкурентно. Використовуючи такі інструменти, як потоки, процеси та async, комп’ютер може призупинити одну діяльність і переключитися на інші, перш ніж зрештою знову повернутися до тієї першої діяльності. На машині з кількома ядрами CPU він також може виконувати роботу паралельно. Одне ядро може виконувати одну task, тоді як інше ядро виконує зовсім не пов’язану з нею, і ці операції насправді відбуваються одночасно.
Виконання async-коду в Rust зазвичай відбувається конкурентно. Залежно від апаратного забезпечення, операційної системи та async runtime, який ми використовуємо (про async runtime ще трохи згодом), ця конкурентність може також використовувати паралелізм під капотом.
Тепер занурмося в те, як async-програмування в Rust насправді працює.
Futures і синтаксис async
Futures та синтаксис Async
Ключові елементи асинхронного програмування в Rust — це future та ключові слова Rust
async і await.
Future — це значення, яке зараз може бути не готове, але стане готовим у
якийсь момент у майбутньому. (Ця сама концепція трапляється в багатьох мовах, іноді
під іншими назвами, такими як task або promise. ) Rust надає трейт Future
як будівельний блок, щоб різні async-операції можна було реалізовувати з
різними структурами даних, але з єдиним інтерфейсом. У Rust future — це
типи, які реалізують трейт Future. Кожен future містить власну інформацію
про прогрес, який було досягнуто, і про те, що означає «готовий».
Ви можете застосувати ключове слово async до блоків і функцій, щоб вказати, що вони
можуть бути перервані та відновлені. Усередині async-блоку або async-функції ви
можете використовувати ключове слово await, щоб await a future (тобто чекати, поки він стане
готовим). Будь-яка точка, де ви очікуєте future всередині async-блоку або функції, є
потенційним місцем, де цей блок або функція може призупинитися й відновитися. Процес
перевірки future, щоб побачити, чи доступне вже його значення, називається polling.
Деякі інші мови, такі як C# і JavaScript, також використовують ключові слова async і await
для async-програмування. Якщо ви знайомі з цими мовами, ви
можете помітити деякі суттєві відмінності в тому, як Rust обробляє синтаксис. І це недарма, як
ми побачимо!
Коли ми пишемо async Rust, ми здебільшого використовуємо ключові слова async і await.
Rust компілює їх в еквівалентний код, використовуючи трейт Future, так само як
він компілює цикли for в еквівалентний код, використовуючи трейт Iterator.
Оскільки Rust надає трейт Future, ви також можете реалізувати його для
власних типів даних, коли це потрібно. Багато функцій, які ми побачимо
протягом цієї глави, повертають типи з власними реалізаціями
Future. Ми повернемося до визначення трейту наприкінці глави
і глибше розглянемо, як це працює, але цього рівня деталізації достатньо, щоб рухатися
далі.
Усе це може здаватися трохи абстрактним, тож давайте напишемо нашу першу async-програму: невеликий web scraper. Ми передамо два URL з командного рядка, отримаємо обидва конкурентно, і повернемо результат того, який завершиться першим. У цьому прикладі буде чимало нового синтаксису, але не хвилюйтеся — ми пояснимо все, що вам потрібно знати, у процесі.
Наша перша async-програма
Щоб зосередити цю главу на вивченні async, а не на керуванні частинами
екосистеми, ми створили крейт trpl (trpl — скорочення від “The Rust
Programming Language”). Він перевизначає всі типи, трейти й функції, які
вам знадобляться, переважно з крейтів futures і
tokio. Крейт futures — це офіційне місце для експериментів Rust з async-кодом, і
саме там спочатку було розроблено трейт Future. Tokio — це найпоширеніший async runtime в
Rust сьогодні, особливо для web-застосунків. Є й інші чудові runtime
там, і вони можуть бути більш придатними для ваших цілей. Ми використовуємо крейт tokio
під капотом для trpl, тому що він добре протестований і широко використовується.
У деяких випадках trpl також перейменовує або обгортає оригінальні API, щоб ви
зосередилися на деталях, релевантних для цієї глави. Якщо ви хочете зрозуміти, що
робить крейт, ми радимо вам ознайомитися з його вихідним кодом.
Ви зможете побачити, з якого крейта походить кожен re-export, і ми залишили
розгорнуті коментарі, що пояснюють, що робить крейт.
Створіть новий бінарний пакет із назвою hello-async і додайте крейт trpl як
залежність:
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
Тепер ми можемо використовувати різні частини, надані trpl, щоб написати нашу першу async
програму. Ми побудуємо невеликий інструмент командного рядка, який отримує дві web-сторінки,
витягує елемент <title> з кожної та друкує заголовок тієї сторінки, яка завершить увесь цей процес першою.
Визначення функції page_title
Почнімо з написання функції, яка приймає один URL сторінки як параметр, надсилає
до нього запит і повертає текст елемента <title> (див. Listing
17-1).
extern crate trpl; // required for mdbook test
fn main() {
// TODO: we'll add this next!
}
use trpl::Html;
async fn page_title(url: &str) -> Option<String> {
let response = trpl::get(url).await;
let response_text = response.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Спочатку ми визначаємо функцію з назвою page_title і позначаємо її
ключовим словом async. Потім ми використовуємо функцію trpl::get, щоб отримати будь-який URL, який передано
всередину, і додаємо ключове слово await, щоб очікувати відповідь. Щоб отримати текст
response, ми викликаємо її метод text і знову очікуємо його за допомогою
ключового слова await. Обидва ці кроки є асинхронними. Для функції get нам
потрібно дочекатися, поки сервер надішле назад першу частину своєї відповіді, яка міститиме HTTP-заголовки, cookie тощо
і може бути доставлена окремо від тіла відповіді. Особливо якщо тіло дуже велике,
може знадобитися деякий час, щоб усе дійшло. Оскільки нам потрібно дочекатися
всієї відповіді, метод text також є async.
Ми повинні явно очікувати обидва ці future, тому що future в Rust — lazy: вони
нічого не роблять, доки ви не попросите їх про це за допомогою ключового слова await.
(Насправді Rust покаже попередження компілятора, якщо ви не використовуєте future.) Це
може нагадати вам обговорення ітераторів у розділі “Processing a Series of
Items with Iterators” у Главі 13.
Ітератори нічого не роблять, якщо ви не викликаєте їхній метод next — прямо або
через використання циклів for чи методів на кшталт map, які використовують next
під капотом. Так само future нічого не роблять, якщо ви явно не попросите їх про це. Така
лінощі дозволяє Rust не запускати async-код, доки він справді не потрібен.
Примітка: Це відрізняється від поведінки, яку ми бачили під час використання
thread::spawnу розділі “Creating a New Thread with spawn” у Главі 16, де замикання, яке ми передали іншому потоку, починало виконуватися одразу. Це також відрізняється від того, як багато інших мов підходять до async. Але для Rust важливо мати змогу забезпечувати свої гарантії продуктивності, так само як і з ітераторами.
Коли у нас є response_text, ми можемо розібрати його в екземпляр типу Html
за допомогою Html::parse. Замість сирого рядка ми тепер маємо тип даних, який
можна використовувати для роботи з HTML як із багатшою структурою даних. Зокрема, ми можемо
використати метод select_first, щоб знайти перший екземпляр заданого CSS
селектора. Передавши рядок "title", ми отримаємо перший елемент <title>
у документі, якщо такий є. Оскільки може не бути жодного відповідного
елемента, select_first повертає Option<ElementRef>. Нарешті, ми використовуємо метод
Option::map, який дає змогу працювати з елементом в Option, якщо він присутній, і
нічого не робити, якщо його немає. (Ми також могли б використати тут вираз match,
але map є більш ідіоматичним.) У тілі функції, яку ми передаємо до
map, ми викликаємо inner_html на title, щоб отримати його вміст, який є
String. Коли все сказано і зроблено, ми маємо Option<String>.
Зверніть увагу, що ключове слово await у Rust іде після виразу, який ви очікуєте,
а не перед ним. Тобто це постфіксне ключове слово. Це може відрізнятися від того, до чого ви
звикли, якщо використовували async в інших мовах, але в Rust це робить
ланцюжки методів значно зручнішими для роботи. У результаті ми могли б змінити
тіло page_title, щоб об’єднати виклики функцій trpl::get і text
разом із await між ними, як показано в Listing 17-2.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
// TODO: we'll add this next!
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}З цим ми успішно написали нашу першу async-функцію! Перш ніж ми додамо
деякий код у main, щоб викликати її, давайте трохи більше поговоримо про те, що ми
написали і що це означає.
Коли Rust бачить блок, позначений ключовим словом async, він компілює його в
унікальний, анонімний тип даних, який реалізує трейт Future. Коли Rust бачить
функцію, позначену async, він компілює її в не-async функцію,
тіло якої є async-блоком. Тип повернення async-функції — це тип
анонімного типу даних, який компілятор створює для цього async-блоку.
Отже, написання async fn еквівалентне написанню функції, яка повертає
future типу повернення. Для компілятора визначення функції на кшталт
async fn page_title у Listing 17-1 є приблизно еквівалентним не-async
функції, визначеній так:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
use std::future::Future;
use trpl::Html;
fn page_title(url: &str) -> impl Future<Output = Option<String>> {
async move {
let text = trpl::get(url).await.text().await;
Html::parse(&text)
.select_first("title")
.map(|title| title.inner_html())
}
}
}Давайте розглянемо кожну частину перетвореної версії:
- Вона використовує синтаксис
impl Trait, який ми обговорювали ще в Главі 10 у розділі “Traits as Parameters”. - Значення, що повертається, реалізує трейт
Futureіз асоційованим типомOutput. Зверніть увагу, що типOutput— цеOption<String>, який є тим самим, що й оригінальний тип повернення з версіїasync fnдляpage_title. - Увесь код, викликаний у тілі оригінальної функції, обгорнуто в
блок
async move. Пам’ятайте, що блоки — це вирази. Увесь цей блок є виразом, який повертається з функції. - Цей async-блок створює значення типу
Option<String>, як щойно описано. Це значення відповідає типуOutputу типі повернення. Це так само, як і інші блоки, які ви вже бачили. - Нове тіло функції є блоком
async moveчерез те, як воно використовує параметрurl. (Ми ще багато говоритимемо проasyncпротиasync moveпізніше в цій главі.)
Тепер ми можемо викликати page_title у main.
Виконання Async-функції за допомогою runtime
Для початку ми отримаємо заголовок для однієї сторінки, показаної в Listing 17-3. На жаль, цей код ще не компілюється.
extern crate trpl; // required for mdbook test
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Ми дотримуємося того самого шаблону, який використовували для отримання аргументів командного рядка
у розділі “Accepting Command Line Arguments” у
Главі 12. Потім ми передаємо аргумент URL до page_title і очікуємо результат.
Оскільки значення, яке створює future, є Option<String>, ми використовуємо
вираз match, щоб надрукувати різні повідомлення залежно від того, чи мала
сторінка <title>.
Єдине місце, де ми можемо використовувати ключове слово await, — це async-функції або блоки,
а Rust не дозволить нам позначити спеціальну функцію main як async.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
Причина, чому main не може бути позначена як async, полягає в тому, що async-коду потрібен runtime:
крейт Rust, який керує деталями виконання асинхронного коду. Функція main
програми може ініціалізувати runtime, але вона не є runtime
сама по собі. (Невдовзі ми побачимо більше про те, чому це так.) Кожна програма Rust,
яка виконує async-код, має принаймні одне місце, де вона налаштовує runtime, що виконує future.
Більшість мов, які підтримують async, постачають runtime, але Rust — ні. Замість цього, доступно багато різних async runtime, кожен із яких робить різні компроміси, придатні для того варіанта використання, на який він націлений. Наприклад, web-сервер із високою пропускною здатністю, багатьма CPU-ядрами й великою кількістю RAM має зовсім інші потреби, ніж мікроконтролер з одним ядром, невеликою кількістю RAM і без можливості виділення купі. Крейт-и, які надають ці runtime, також часто постачають async-версії поширеної функціональності, такої як файловий або мережевий I/O.
Тут і протягом решти цієї глави ми використовуватимемо функцію block_on з
крейта trpl, яка приймає future як аргумент і блокує
поточний потік, доки цей future не завершить виконання. За лаштунками,
виклик block_on налаштовує runtime за допомогою крейта tokio, який використовується для виконання
переданого future (поведінка block_on у крейті trpl подібна до
функцій block_on в інших крейтах runtime). Коли future завершується,
block_on повертає те значення, яке створив future.
Ми могли б передати future, що повертається page_title, безпосередньо до block_on і,
коли він завершиться, могли б виконати match над отриманим Option<String>, як
ми намагалися зробити в Listing 17-3. Однак для більшості прикладів у главі (і
більшості async-коду в реальному світі) ми робитимемо більше, ніж один виклик async-
функції, тому замість цього ми передамо async-блок і явно очікуємо
результат виклику page_title, як у Listing 17-4.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
})
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Коли ми запускаємо цей код, ми отримуємо поведінку, яку спочатку й очікували:
$ cargo run -- "https://www.rust-lang.org"
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was
Rust Programming Language
Фух — нарешті в нас є трохи робочого async-коду! Але перш ніж ми додамо код, щоб змагати два сайти один з одним, давайте ненадовго повернемо нашу увагу до того, як працюють future.
Кожна await point — тобто кожне місце, де код використовує ключове слово await, — представляє місце, де керування передається
назад runtime. Щоб це працювало, Rust має відстежувати стан, пов’язаний з async-блоком, щоб
runtime міг запустити якусь іншу роботу, а потім повернутися, коли буде готовий знову спробувати просунути першу. Це невидимий автомат станів,
ніби ви написали б такий перелік, щоб зберігати поточний стан на кожній
точці await:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
enum PageTitleFuture<'a> {
Initial { url: &'a str },
GetAwaitPoint { url: &'a str },
TextAwaitPoint { response: trpl::Response },
}
}Писати код для переходу між кожним станом вручну було б нудно й схильне до помилок, особливо коли вам пізніше потрібно додати більше функціональності та більше станів у код. На щастя, компілятор Rust автоматично створює і керує структурами даних автомата станів для async-коду. Звичайні правила запозичення та власності, що стосуються структур даних, усе ще застосовуються, і на щастя, компілятор також перевіряє їх за нас і надає корисні повідомлення про помилки. Декілька з них ми розглянемо пізніше в цій главі.
Зрештою, щось має виконувати цей автомат станів, і цим чимось є runtime. (Ось чому ви можете натрапити на згадки про executors, коли досліджуєте runtime: executor — це частина runtime, відповідальна за виконання async-коду.)
Тепер ви бачите, чому компілятор зупинив нас від того, щоб зробити main саму по собі async-функцією
ще в Listing 17-3. Якби main була async-функцією, щось інше
мало б керувати автоматом станів для будь-якого future, який повернула б main, але
main — це точка запуску програми! Замість цього ми викликали
функцію trpl::block_on у main, щоб налаштувати runtime і виконувати future,
який повертає async-блок, доти, доки він не завершиться.
Примітка: Деякі runtime надають макроси, щоб ви могли написати async
mainfunction. Ці макроси переписуютьasync fn main() { ... }у звичайнуfn main, що робить те саме, що ми зробили вручну в Listing 17-4: викликає функцію, яка виконує future до завершення так, як це робитьtrpl::block_on.
Тепер давайте з’єднаємо ці частини разом і подивимося, як ми можемо написати конкурентний код.
Змагання двох URL один з одним конкурентно
У Listing 17-5 ми викликаємо page_title для двох різних URL, переданих із
командного рядка, і змагаємо їх, вибираючи той future, який завершиться першим.
extern crate trpl; // required for mdbook test
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let title_fut_1 = page_title(&args[1]);
let title_fut_2 = page_title(&args[2]);
let (url, maybe_title) =
match trpl::select(title_fut_1, title_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} returned first");
match maybe_title {
Some(title) => println!("Its page title was: '{title}'"),
None => println!("It had no title."),
}
})
}
async fn page_title(url: &str) -> (&str, Option<String>) {
let response_text = trpl::get(url).await.text().await;
let title = Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html());
(url, title)
}Ми починаємо з виклику page_title для кожного з наданих користувачем URL. Ми зберігаємо
отримані future як title_fut_1 і title_fut_2. Пам’ятайте, що вони
ще нічого не роблять, тому що future ліниві, і ми ще не очікували їх. Потім
ми передаємо future до trpl::select, яка повертає значення, щоб показати, який
із переданих їй future завершується першим.
Примітка: Під капотом
trpl::selectпобудовано на більш загальній функціїselect, визначеній у крейтіfutures. Функціяselectкрейтаfuturesможе робити багато речей, яких не можеtrpl::select, але вона також має деяку додаткову складність, яку ми поки що можемо пропустити.
Будь-який future може законно “виграти”, тож не має сенсу повертати
Result. Натомість trpl::select повертає тип, якого ми ще не бачили,
trpl::Either. Тип Either дещо подібний до Result у тому, що він
має два випадки. На відміну від Result, однак, у Either немає вбудованого поняття успіху
чи помилки. Натомість він використовує Left і Right, щоб позначити
«одне або інше»:
#![allow(unused)]
fn main() {
enum Either<A, B> {
Left(A),
Right(B),
}
}Функція select повертає Left із виходом цього future, якщо перший
аргумент перемагає, і Right із виходом другого аргументу future, якщо той
перемагає. Це відповідає порядку, в якому аргументи з’являються під час виклику
функції: перший аргумент знаходиться ліворуч від другого аргументу.
Ми також оновлюємо page_title, щоб повертати той самий URL, який було передано. Таким чином, якщо
сторінка, яка повертається першою, не має <title>, який ми можемо розв’язати, ми все одно
можемо надрукувати змістовне повідомлення. З цією доступною інформацією ми завершуємо, оновлюючи наш
вивід println!, щоб показати як те, який URL завершився першим, так і
який, якщо такий є, <title> має web-сторінка за цим URL.
Тепер ви створили невеликий робочий web scraper! Виберіть кілька URL і запустіть інструмент командного рядка. Ви можете виявити, що деякі сайти стабільно швидші за інші, тоді як в інших випадках швидший сайт змінюється від запуску до запуску. Що ще важливіше, ви вивчили основи роботи з future, тож тепер ми можемо глибше зануритися в те, що ми можемо робити з async.
Застосування конкурентності за допомогою async
Застосування конкурентності з Async
У цьому розділі ми застосуємо async до деяких із тих самих викликів конкурентності, які ми розв’язували з потоками в Розділі 16. Оскільки ми вже обговорили там багато ключових ідей, у цьому розділі ми зосередимося на тому, що відрізняється між потоками та futures.
У багатьох випадках API для роботи з конкурентністю з використанням async дуже схожі на ті, що використовуються з потоками. В інших випадках вони виявляються зовсім різними. Навіть коли API схожі між потоками та async, вони часто мають іншу поведінку — і майже завжди мають інші характеристики продуктивності.
Створення нової task з spawn_task
Першою операцією, яку ми розв’язували в розділі «Створення нового потоку з
spawn» у Розділі 16, було підраховування на
двох окремих потоках. Давайте зробимо те саме з використанням async. Крейт
trpl надає функцію spawn_task, яка дуже схожа на API thread::spawn, і
функцію sleep, яка є async-версією API thread::sleep. Ми можемо
використати їх разом, щоб реалізувати приклад з підрахунком, як показано в
Лістингу 17-6.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
}Як нашу початкову точку, ми налаштовуємо нашу функцію main з
trpl::block_on, щоб наша функція верхнього рівня могла бути async.
Примітка: Від цього моменту далі в розділі кожен приклад міститиме цей самий обгортковий код із
trpl::block_onуmain, тож ми часто будемо його пропускати, як і зmain. Пам’ятайте додавати його у свій код!
Потім ми пишемо два цикли всередині цього блоку, кожен із викликом
trpl::sleep, який чекає пів секунди (500 мілісекунд) перед надсиланням
наступного повідомлення. Ми поміщаємо один цикл у тіло trpl::spawn_task, а
інший — у верхньорівневий цикл for. Ми також додаємо await після викликів
sleep.
Цей код поводиться подібно до реалізації на основі потоків — зокрема, включно з тим фактом, що ви можете побачити, що повідомлення з’являються в іншому порядку у своєму терміналі, коли ви запускаєте його:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
Ця версія зупиняється щойно цикл for у тілі основного async-блоку
завершується, тому що task, створена spawn_task, завершується, коли функція
main закінчується. Якщо ви хочете, щоб вона виконувалася аж до завершення
task, вам потрібно буде використати join handle, щоб дочекатися завершення
першої task. З потоками ми використовували метод join, щоб “блокуватися”, аж
поки потік не завершить виконання. У Лістингу 17-7 ми можемо використати
await, щоб зробити те саме, тому що сам handle task є future. Її тип
Output — це Result, тож ми також розгортаємо його після await.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let handle = trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
handle.await.unwrap();
});
}Ця оновлена версія виконується, доки не завершаться обидва цикли:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Поки що виглядає так, ніби async і потоки дають нам подібні результати, лише
з різним синтаксисом: використання await замість виклику join на join
handle, і await для викликів sleep.
Більша відмінність полягає в тому, що нам не потрібно було створювати ще один
операційний системний потік, щоб зробити це. Насправді нам тут навіть не
потрібно створювати task. Оскільки async-блоки компілюються в анонімні
futures, ми можемо помістити кожен цикл в async-блок і змусити runtime
виконати їх обидва до завершення за допомогою функції trpl::join.
У розділі «Очікування завершення всіх потоків»
в Розділі 16 ми показали, як використовувати метод join на типі
JoinHandle, який повертається, коли ви викликаєте std::thread::spawn.
Функція trpl::join схожа, але для futures. Коли ви даєте їй дві futures, вона
створює одну нову future, чиїм output є кортеж, що містить output кожної
future, яку ви передали, після того як обидві завершаться. Таким чином, у
Лістингу 17-8 ми використовуємо trpl::join, щоб дочекатися завершення і
fut1, і fut2. Ми не очікуємо fut1 і fut2, а натомість нову future,
створену trpl::join. Ми ігноруємо output, тому що це просто кортеж, що
містить два значення unit.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let fut1 = async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
let fut2 = async {
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
trpl::join(fut1, fut2).await;
});
}Коли ми запускаємо це, ми бачимо, що обидві futures виконуються до завершення:
hi number 1 from the first task!
hi number 1 from the second task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Тепер ви бачитимете точно той самий порядок щоразу, що дуже відрізняється від
того, що ми бачили з потоками та з trpl::spawn_task у Лістингу 17-7. Це
тому, що функція trpl::join є справедливою, тобто вона перевіряє кожну
future однаково часто, чергуючись між ними, і ніколи не дає одній вискочити
вперед, якщо інша готова. З потоками операційна система вирішує, який потік
перевіряти і як довго йому дозволяти працювати. З async Rust runtime вирішує,
яку task перевіряти. (На практиці деталі ускладнюються, тому що async runtime
може використовувати потоки операційної системи під капотом як частину того,
як він керує конкурентністю, тож гарантування справедливості може вимагати
більше роботи для runtime — але це все ще можливо!) Runtime не зобов’язані
гарантувати справедливість для будь-якої конкретної операції, і вони часто
пропонують різні API, щоб ви могли вибрати, чи хочете ви справедливість.
Спробуйте кілька з цих варіацій із await для futures і подивіться, що вони
роблять:
- Приберіть async-блок навколо одного або обох циклів.
- Виконайте
awaitдля кожного async-блоку одразу після його визначення. - Обгорніть лише перший цикл в async-блок і виконайте
awaitдля отриманої future після тіла другого циклу.
Для додаткового виклику спробуйте визначити, яким буде вивід у кожному випадку до запуску коду!
Надсилання даних між двома tasks за допомогою передавання повідомлень
Спільне використання даних між futures також буде знайомим: ми знову використаємо передавання повідомлень, але цього разу з async-версіями типів і функцій. Ми підемо дещо іншим шляхом, ніж у розділі «Передавання даних між потоками за допомогою передавання повідомлень» в Розділі 16, щоб проілюструвати деякі ключові відмінності між потоковою конкурентністю та конкурентністю на основі futures. У Лістингу 17-9 ми почнемо лише з одного async-блоку — не створюючи окрему task, як ми створювали окремий потік.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let val = String::from("hi");
tx.send(val).unwrap();
let received = rx.recv().await.unwrap();
println!("received '{received}'");
});
}Тут ми використовуємо trpl::channel, async-версію API каналу multiple-producer,
single-consumer, який ми використовували з потоками ще в Розділі 16. Async-
версія API лише трохи відрізняється від потокової версії: вона використовує
змінний, а не незмінний receiver rx, і її метод recv створює future,
яку нам потрібно await-ити, замість того щоб повертати значення
безпосередньо. Тепер ми можемо надсилати повідомлення від sender до receiver.
Зверніть увагу, що нам не потрібно створювати окремий потік або навіть task;
нам лише потрібно await-ити виклик rx.recv.
Синхронний метод Receiver::recv у std::mpsc::channel блокується, доки не
отримає повідомлення. Метод trpl::Receiver::recv цього не робить, тому що
він async. Замість блокування він передає керування назад runtime, доки або не
буде отримано повідомлення, або не закриється сторона надсилання каналу. На
відміну від цього, ми не await-имо виклик send, тому що він не блокується.
Йому це й не потрібно, тому що канал, у який ми надсилаємо, є необмеженим.
Примітка: Оскільки весь цей async-код виконується в async-блоці в виклику
trpl::block_on, усе всередині нього може уникати блокування. Однак код поза ним блокуватиметься на тому, що функціяblock_onповертається. У цьому й полягає вся суть функціїtrpl::block_on: вона дає вам вибирати, де блокуватися на деякому наборі async-коду, а отже, де переходити між sync і async-кодом.
Зверніть увагу на дві речі в цьому прикладі. По-перше, повідомлення надійде одразу. По-друге, хоча ми використовуємо тут future, конкурентності ще немає. Усе в лістингу відбувається послідовно, так само, як і було б, якби futures не брали участі.
Давайте розв’яжемо першу частину, надсилаючи серію повідомлень і роблячи паузи між ними, як показано в Лістингу 17-10.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
}Окрім надсилання повідомлень, нам потрібно їх і отримувати. У цьому випадку,
оскільки ми знаємо, скільки повідомлень надійде, ми могли б зробити це вручну,
викликавши rx.recv().await чотири рази. У реальному світі, однак, ми
зазвичай чекатимемо на деяку невідому кількість повідомлень, тож нам
потрібно продовжувати чекати, доки ми не визначимо, що повідомлень більше
немає.
У Лістингу 16-10 ми використовували цикл for, щоб обробити всі елементи,
отримані з синхронного каналу. Однак у Rust ще немає способу використовувати
цикл for із серією елементів, створених асинхронно, тому нам потрібно
використати цикл, який ми ще не бачили: умовний цикл while let. Це
циклічна версія конструкції if let, яку ми бачили в розділі «Стиснений
потік керування з if let і let...else» у Розділі 6.
Цикл продовжуватиме виконуватися, доки зразок, який він задає, продовжує
зіставлятися зі значенням.
Виклик rx.recv створює future, яку ми await-имо. Runtime призупинить цю
future, доки вона не буде готова. Коли надійде повідомлення, future
резольвиться в Some(message) стільки разів, скільки надходить повідомлення.
Коли канал закривається, незалежно від того, чи надійшли якісь повідомлення,
future натомість резольвиться в None, щоб показати, що більше немає
значень і, отже, нам слід припинити polling — тобто припинити await-ити.
Цикл while let об’єднує все це. Якщо результат виклику
rx.recv().await — це Some(message), ми отримуємо доступ до повідомлення
й можемо використати його в тілі циклу, так само, як могли б з if let. Якщо
результат — None, цикл завершується. Щоразу, коли цикл завершується, він
знову доходить до точки await, тож runtime знову призупиняє його, доки не
надійде інше повідомлення.
Тепер код успішно надсилає й отримує всі повідомлення. На жаль, усе ще залишається кілька проблем. По-перше, повідомлення не надходять з інтервалом у пів секунди. Вони надходять усі одразу, через 2 секунди (2 000 мілісекунд) після запуску програми. По-друге, ця програма також ніколи не завершується! Натомість вона вічно чекає нових повідомлень. Вам доведеться зупинити її за допомогою ctrl-C.
Код всередині одного async-блоку виконується лінійно
Почнімо з того, що розглянемо, чому повідомлення надходять усі разом після
повної затримки, а не з паузами між кожним із них. Усередині будь-якого
async-блоку порядок, у якому ключові слова await з’являються в коді, також є
порядком, у якому вони виконуються під час роботи програми.
У Лістингу 17-10 є лише один async-блок, тож усе в ньому виконується
лінійно. Конкурентності все ще немає. Усі виклики tx.send відбуваються,
перемежовуючись усіма викликами trpl::sleep та пов’язаними з ними точками
await. Лише після цього цикл while let отримує змогу пройти через будь-які
точки await на викликах recv.
Щоб отримати бажану поведінку, коли затримка сну відбувається між кожним
повідомленням, нам потрібно помістити операції tx і rx у власні
async-блоки, як показано в Лістингу 17-11. Тоді runtime може виконувати
кожен із них окремо, використовуючи trpl::join, так само, як у Лістингу
17-8. Знову ж таки, ми await-имо результат виклику trpl::join, а не окремі
futures. Якби ми await-или окремі futures послідовно, ми б просто знову
повернулися до послідовного потоку — саме того, чого ми намагаємося не
робити.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}З оновленим кодом у Лістингу 17-11 повідомлення друкуються з інтервалом 500 мілісекунд, а не всі поспіль після 2 секунд.
Переміщення власності в async-блок
Програма все ще ніколи не завершується, однак, через те, як цикл while let
взаємодіє з trpl::join:
- Future, яку повертає
trpl::join, завершується лише тоді, коли завершаться обидві futures, передані їй. - Future
tx_futзавершується, коли вона закінчує спати після надсилання останнього повідомлення вvals. - Future
rx_futне завершиться, доки не закінчиться циклwhile let. - Цикл
while letне закінчиться, докиawait-анняrx.recvне дастьNone. await-анняrx.recvповернеNoneлише тоді, коли інший кінець каналу закрито.- Канал закриється лише якщо ми викличемо
rx.closeабо коли сторона sender,tx, буде викинута. - Ми ніде не викликаємо
rx.close, іtxне буде викинуто, доки зовнішній async-блок, переданий доtrpl::block_on, не завершиться. - Блок не може завершитися, тому що він заблокований на завершенні
trpl::join, що повертає нас на початок цього списку.
Зараз async-блок, у якому ми надсилаємо повідомлення, лише запозичує tx,
оскільки надсилання повідомлення не потребує власності, але якби ми могли
перемістити tx у цей async-блок, він був би викинутий, щойно цей блок
закінчиться. У розділі [«Захоплення посилань або переміщення власності»]
capture-or-move в Розділі 13 ви дізналися, як використовувати
ключове слово move із замиканнями, і, як обговорювалося в розділі «Використання
move-замикань з потоками» у Розділі 16, нам
часто потрібно переміщати дані в замикання, коли ми працюємо з потоками. Ті
самі базові динаміки застосовуються до async-блоків, тож ключове слово move
працює з async-блоками так само, як і з замиканнями.
У Лістингу 17-12 ми змінюємо блок, який використовується для надсилання
повідомлень, з async на async move.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}Коли ми запускаємо цю версію коду, вона коректно завершується після надсилання й отримання останнього повідомлення. Далі давайте подивимося, що потрібно змінити, щоб надсилати дані з більш ніж однієї future.
Об’єднання кількох futures за допомогою макроса join!
Цей async-канал також є каналом multiple-producer, тож ми можемо викликати
clone на tx, якщо хочемо надсилати повідомлення з кількох futures, як
показано в Лістингу 17-13.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(1500)).await;
}
};
trpl::join!(tx1_fut, tx_fut, rx_fut);
});
}Спочатку ми клонуємо tx, створюючи tx1 поза першим async-блоком. Ми
переміщаємо tx1 у цей блок так само, як робили це раніше з tx. Потім,
пізніше, ми переміщаємо оригінальний tx у новий async-блок, де надсилаємо
більше повідомлень із трохи повільнішою затримкою. Так сталося, що ми
розміщуємо цей новий async-блок після async-блоку для отримання повідомлень,
але він міг би бути і перед ним. Ключове тут — порядок, у якому futures
await-яться, а не порядок, у якому вони створюються.
Обидва async-блоки для надсилання повідомлень мають бути блоками async move,
щоб і tx, і tx1 були викинуті, коли ці блоки завершаться. Інакше ми знову
опинимося в тому самому нескінченному циклі, з якого почали.
Нарешті, ми переходимо з trpl::join на trpl::join!, щоб обробити
додаткову future: макрос join! await-ить довільну кількість futures,
коли ми знаємо кількість futures під час компіляції. Ми обговоримо очікування
колекції невідомої кількості futures пізніше в цьому розділі.
Тепер ми бачимо всі повідомлення з обох futures, що надсилають, і оскільки futures, що надсилають, використовують трохи різні затримки після надсилання, повідомлення також отримуються з цими різними інтервалами:
received 'hi'
received 'more'
received 'from'
received 'the'
received 'messages'
received 'future'
received 'for'
received 'you'
Ми дослідили, як використовувати передавання повідомлень для надсилання даних між futures, як код всередині async-блоку виконується послідовно, як переміщувати власність в async-блок і як об’єднувати кілька futures. Далі давайте обговоримо, як і чому повідомляти runtime, що він може перейти до іншої task.
Робота з будь-якою кількістю futures
Надання керування runtime
Пригадайте з розділу “Наша перша async-програма” section, що на кожній точці await Rust дає runtime змогу призупинити task і переключитися на інший, якщо future, яке очікується, ще не готове. Зворотне також вірне: Rust лише призупиняє async-блоки та повертає керування назад до runtime на точці await. Усе між точками await є синхронним.
Це означає, що якщо ви робите багато роботи в async-блоці без точки await, то це future заблокує будь-які інші future від просування. Іноді ви можете почути це як те, що одне future starving інші future. У деяких випадках це може бути не так уже й страшно. Однак, якщо ви робите якийсь дорогий setup або довготривалу роботу, або якщо у вас є future, яке буде безкінечно виконувати певне завдання, вам потрібно буде подумати про те, коли і де повертати керування назад до runtime.
Давайте змоделюємо довготривалу операцію, щоб проілюструвати проблему starvation,
а потім розглянемо, як її розв’язати. Listing 17-14 вводить функцію slow.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
// We will call `slow` here later
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Цей код використовує std::thread::sleep замість trpl::sleep, щоб виклик
slow блокував потік, що виконується, на певну кількість мілісекунд. Ми можемо
використовувати slow як заміну для реальних операцій, які є і довготривалими,
і блокувальними.
У Listing 17-15 ми використовуємо slow, щоб імітувати виконання такого
CPU-bound work у парі future.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
slow("a", 10);
slow("a", 20);
trpl::sleep(Duration::from_millis(50)).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
slow("b", 10);
slow("b", 15);
slow("b", 350);
trpl::sleep(Duration::from_millis(50)).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Кожне future повертає керування назад до runtime лише після виконання кількох повільних операцій. Якщо ви запустите цей код, ви побачите такий вивід:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
Як і в Listing 17-5, де ми використовували trpl::select, щоб змагати future, які
отримують два URLs, select усе ще завершується, щойно a закінчено. Проте
між викликами slow у двох future немає чергування. Future a виконує всю
свою роботу до того, як буде очікувано виклик trpl::sleep, потім future b
виконує всю свою роботу до того, як буде очікувано його власний виклик
trpl::sleep, і нарешті future a завершується. Щоб дозволити обом future
просуватися між їхніми повільними tasks, нам потрібні точки await, щоб ми могли
повернути керування назад до runtime. Це означає, що нам потрібна річ, яку ми
можемо await!
Ми вже можемо бачити таку передачу керування в Listing 17-15: якби ми
прибрали trpl::sleep у кінці future a, воно завершилося б без того, щоб
future b взагалі запускалося. Давайте спробуємо використати функцію
trpl::sleep як відправну точку для того, щоб дозволити операціям переключатися
з просування, як показано в Listing 17-16.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let one_ms = Duration::from_millis(1);
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::sleep(one_ms).await;
slow("a", 10);
trpl::sleep(one_ms).await;
slow("a", 20);
trpl::sleep(one_ms).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::sleep(one_ms).await;
slow("b", 10);
trpl::sleep(one_ms).await;
slow("b", 15);
trpl::sleep(one_ms).await;
slow("b", 350);
trpl::sleep(one_ms).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Ми додали виклики trpl::sleep із точками await між кожним викликом slow.
Тепер робота двох future чергується:
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
Future a все ще виконується деякий час, перш ніж передати керування b, тому що
воно викликає slow перед тим, як викликати trpl::sleep, але після цього future
перемикаються туди й назад щоразу, коли одне з них досягає точки await. У цьому
випадку ми зробили це після кожного виклику slow, але ми могли б розбити роботу
будь-яким способом, який має для нас найбільший сенс.
Втім, ми насправді не хочемо sleep тут: ми хочемо просуватися якнайшвидше. Нам
лише потрібно повернути керування назад до runtime. Ми можемо зробити це напряму,
використовуючи функцію trpl::yield_now. У Listing 17-17 ми замінюємо всі ті
виклики trpl::sleep на trpl::yield_now.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::yield_now().await;
slow("a", 10);
trpl::yield_now().await;
slow("a", 20);
trpl::yield_now().await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::yield_now().await;
slow("b", 10);
trpl::yield_now().await;
slow("b", 15);
trpl::yield_now().await;
slow("b", 350);
trpl::yield_now().await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Цей код є і зрозумілішим щодо фактичного наміру, і може бути значно
швидшим за використання sleep, тому що таймери, такі як той, що використовується
sleep, часто мають обмеження на те, наскільки дрібнозернистими вони можуть бути.
Версія sleep, яку ми використовуємо, наприклад, завжди спатиме щонайменше
одну мілісекунду, навіть якщо ми передамо їй Duration в одну наносекунду.
Знову ж таки, сучасні комп’ютери швидкі: вони можуть зробити багато за одну
мілісекунду!
Це означає, що async може бути корисним навіть для compute-bound tasks, залежно від того, що ще робить ваша програма, тому що він надає корисний інструмент для структурування взаємин між різними частинами програми (але ціною накладних витрат async state machine). Це форма cooperative multitasking, де кожне future має змогу визначати, коли воно передає керування через точки await. Отже, кожне future також несе відповідальність за те, щоб уникати надто довгого блокування. У деяких embedded операційних системах на базі Rust це єдиний вид multitasking!
У реальному коді ви зазвичай, звісно, не чергуватимете виклики функцій із точками await на кожному окремому рядку. Хоча надання керування таким способом є відносно недорогим, воно не є безкоштовним. У багатьох випадках спроба розбити compute-bound task може зробити його значно повільнішим, тому іноді краще для загальної продуктивності дозволити операції коротко блокуватися. Завжди вимірюйте, щоб побачити, де насправді є вузькі місця продуктивності вашого коду. Проте базову динаміку важливо тримати на увазі, якщо ви дійсно бачите, що багато роботи відбувається послідовно там, де ви очікували конкурентного виконання!
Створення наших власних async-абстракцій
Ми також можемо компонувати future разом, щоб створювати нові шаблони. Наприклад,
ми можемо побудувати функцію timeout з async-блоків, які вже маємо. Коли ми
завершимо, результатом буде ще один будівельний блок, який ми могли б використати
для створення ще більшої кількості async-абстракцій.
Listing 17-18 показує, як ми очікували б, що цей timeout працюватиме з повільним
future.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}Давайте реалізуємо це! Для початку давайте подумаємо про API для timeout:
- Він сам має бути async-функцією, щоб ми могли await його.
- Його перший параметр має бути future, яке потрібно запустити. Ми можемо зробити його узагальненим, щоб він працював із будь-яким future.
- Його другий параметр буде максимальною кількістю часу для очікування. Якщо ми використаємо
Duration, це буде легко передати доtrpl::sleep. - Він має повертати
Result. Якщо future завершується успішно,ResultбудеOkзі значенням, яке породило future. Якщо timeout спливає першим,ResultбудеErrз тривалістю, яку timeout очікував.
Listing 17-19 показує це оголошення.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
// Here is where our implementation will go!
}Це задовольняє наші цілі щодо типів. Тепер давайте подумаємо про поведінку, яка нам
потрібна: ми хочемо змагати future, передане всередину, проти тривалості. Ми можемо
використати trpl::sleep, щоб створити future таймера з Duration, і використати
trpl::select, щоб запускати цей таймер разом із future, яке передає викликач.
У Listing 17-20 ми реалізуємо timeout, зіставляючи з результатом await-інгу
trpl::select.
extern crate trpl; // required for mdbook test
use std::time::Duration;
use trpl::Either;
// --snip--
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
match trpl::select(future_to_try, trpl::sleep(max_time)).await {
Either::Left(output) => Ok(output),
Either::Right(_) => Err(max_time),
}
}Реалізація trpl::select не є справедливою: вона завжди polling-ить аргументи в
порядку, у якому їх передано (інші реалізації select випадково вибиратимуть,
який аргумент polling-ити першим). Отже, ми передаємо future_to_try до select
першим, щоб воно мало шанс завершитися навіть якщо max_time є дуже короткою
тривалістю. Якщо future_to_try завершується першим, select поверне Left
із виходом від future_to_try. Якщо timer завершується першим, select
поверне Right із виходом таймера ().
Якщо future_to_try успішно завершується і ми отримуємо Left(output), ми
повертаємо Ok(output). Якщо ж таймер sleep спливає першим і ми отримуємо
Right(()), ми ігноруємо () за допомогою _ і натомість повертаємо
Err(max_time).
З цим ми маємо робочий timeout, зібраний із двох інших async-помічників. Якщо
ми запустимо наш код, він виведе режим збою після timeout:
Failed after 2 seconds
Оскільки future компонуються з іншими future, ви можете створювати справді потужні інструменти, використовуючи менші async-блоки. Наприклад, ви можете використати цей самий підхід, щоб поєднати timeout-и з повторними спробами, а потім використовувати їх з операціями, такими як мережеві виклики (такі як у Listing 17-5).
На практиці ви зазвичай працюватимете безпосередньо з async і await, а
додатково — з функціями, такими як select, і макросами, такими як макрос join!,
щоб керувати тим, як виконуються найзовнішні future.
Тепер ми бачили низку способів працювати з кількома future одночасно. Далі ми розглянемо, як ми можемо працювати з кількома future у послідовності з плином часу за допомогою streams.
Streams: futures у послідовності
Стріми: future у послідовності
Пригадайте, як ми використовували одержувач для нашого async-каналу раніше в цьому розділі
в розділі «Передавання повідомлень». Асинхронний
метод recv породжує послідовність елементів з часом. Це є прикладом
набагато більш загальної моделі, відомої як stream. Багато понять природно
представляються як stream: елементи, що стають доступними в черзі, фрагменти даних,
які поступово зчитуються з файлової системи, коли повний набір даних занадто
великий для пам’яті комп’ютера, або дані, що надходять по мережі з часом.
Оскільки stream є future, ми можемо використовувати їх з будь-яким іншим видом future і
поєднувати їх цікавими способами. Наприклад, ми можемо пакетувати події, щоб уникнути
запуску занадто великої кількості мережевих викликів, встановлювати тайм-аути для послідовностей тривалих
операцій або обмежувати події інтерфейсу користувача, щоб уникнути виконання непотрібної роботи.
Ми бачили послідовність елементів ще в Главі 13, коли розглядали trait Iterator
у розділі «Трейт Iterator і метод next», але є дві відмінності між ітераторами та
одержувачем async-каналу. Перша відмінність — це час: ітератори
синхронні, тоді як одержувач каналу асинхронний. Друга відмінність — це API.
Коли ми працюємо безпосередньо з Iterator, ми викликаємо його синхронний
метод next. Зокрема, з stream trpl::Receiver ми натомість викликали
асинхронний метод recv. В іншому ці API дуже схожі,
і ця схожість не є випадковістю. Stream — це ніби асинхронна форма
ітерації. Хоча trpl::Receiver спеціально чекає на отримання
повідомлень, загальний API stream є значно ширшим: він надає
наступний елемент так, як це робить Iterator, але асинхронно.
Подібність між ітераторами та stream у Rust означає, що ми фактично можемо
створити stream з будь-якого ітератора. Як і з ітератором, ми можемо працювати з
stream, викликаючи його метод next, а потім очікуючи результат, як у Listing
17-21, який ще не скомпілюється.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}Ми починаємо з масиву чисел, який перетворюємо на ітератор, а потім
викликаємо на ньому map, щоб подвоїти всі значення. Потім ми перетворюємо ітератор на
stream за допомогою функції trpl::stream_from_iter. Далі ми
проходимо циклом по елементах у stream у міру їх надходження за допомогою циклу while let.
На жаль, коли ми намагаємося запустити код, він не компілюється, а натомість
повідомляє, що метод next недоступний:
error[E0599]: no method named `next` found for struct `tokio_stream::iter::Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
Як пояснює цей вивід, причина помилки компілятора полягає в тому, що нам потрібен
правильний трейт в області видимості, щоб мати змогу використовувати метод next.
З огляду на нашу попередню розмову, ви могли б обґрунтовано очікувати, що цим
трейт буде Stream, але насправді це StreamExt. Скорочення від extension,
Ext — це поширений шаблон у
спільноті Rust для розширення одного трейт іншим.
Трейт Stream визначає низькорівневий інтерфейс, який фактично поєднує
traits Iterator і Future. StreamExt надає набір API вищого рівня
поверх Stream, включно з методом next, а також інші допоміжні
методи, подібні до тих, що надає trait Iterator. Stream і
StreamExt ще не є частиною стандартної бібліотеки Rust, але більшість крейтів екосистеми
використовують подібні визначення.
Виправлення помилки компілятора полягає в тому, щоб додати оператор use для
trpl::StreamExt, як у Listing 17-22.
extern crate trpl; // required for mdbook test
use trpl::StreamExt;
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// --snip--
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}Коли всі ці частини зібрані разом, цей код працює так, як ми хочемо! Більше того,
тепер, коли StreamExt є в області видимості, ми можемо використовувати всі його допоміжні
методи, як і з ітераторами.
Докладніший погляд на трейти для async
Детальніший погляд на трейтів для async
Упродовж розділу ми використовували трейт Future, Stream і StreamExt
різними способами. Але дотепер ми уникали занурення в
деталі того, як вони працюють або як вони поєднуються, що здебільшого добре
для вашої щоденної роботи з Rust. Проте інколи ви зіткнетеся з
ситуаціями, де вам потрібно буде зрозуміти ще кілька деталей цих трейтів,
разом із типом Pin і трейтів Unpin. У цьому розділі ми зануримося
достатньо, щоб допомогти в таких сценаріях, усе ще залишаючи справді
глибоке занурення для іншої документації.
Трейт Future
Почнемо з того, що детальніше поглянемо на те, як працює трейт Future. Ось
як Rust визначає його:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}Це визначення трейту включає безліч нових типів, а також деякий синтаксис, який ми ще не бачили, тож пройдемося по визначенню по частинах.
По-перше, асоційований тип Output у Future вказує, до чого future
розв’язується. Це аналогічно асоційованому типу Item для трейту
Iterator.
По-друге, Future має метод poll, який приймає спеціальне посилання Pin
для свого параметра self і змінне посилання на тип Context, а
повертає Poll<Self::Output>. Про Pin і Context ми поговоримо трохи
згодом. Наразі зосередьмося на тому, що повертає метод — тип Poll:
#![allow(unused)]
fn main() {
pub enum Poll<T> {
Ready(T),
Pending,
}
}Цей тип Poll подібний до Option. Він має один варіант, що має значення,
Ready(T), і один, що не має його, Pending. Однак Poll означає дещо
зовсім інше, ніж Option! Варіант Pending вказує на те, що future
ще має роботу, яку треба виконати, тож викликачеві потрібно буде перевірити
знову пізніше. Варіант Ready вказує на те, що Future завершив свою роботу
і значення T доступне.
Note: Рідко виникає потреба викликати
pollбезпосередньо, але якщо вам усе ж потрібно це зробити, майте на увазі, що для більшості futures викликач не повинен викликатиpollзнову після того, як future повернувReady. Багато futures викличуть паніку, якщо їх опитати знову після того, як вони стали готовими. Futures, які безпечно опитувати знову, прямо скажуть про це в своїй документації. Це подібно до того, як поводитьсяIterator::next.
Коли ви бачите код, що використовує await, Rust компілює його під капотом у
код, який викликає poll. Якщо ви повернетеся до Listing 17-4, де ми
виводили заголовок сторінки для однієї URL-адреси після того, як вона
розв’язувалася, Rust компілює це в щось на кшталт такого (хоча й не зовсім):
match page_title(url).poll() {
Ready(page_title) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// But what goes here?
}
}Що нам слід робити, коли future усе ще Pending? Нам потрібен якийсь спосіб
спробувати знову, і знову, і знову, доки future нарешті не буде готовим. Іншими
словами, нам потрібен цикл:
let mut page_title_fut = page_title(url);
loop {
match page_title_fut.poll() {
Ready(value) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// continue
}
}
}Якби Rust скомпілював це точно в такий код, кожен await був би
блокувальним — цілком протилежним тому, чого ми прагнули! Натомість Rust
гарантує, що цикл може передати керування чомусь, що може призупинити роботу
над цим future, щоб попрацювати над іншими futures, а потім перевірити цей
знову пізніше. Як ми бачили, цим чимось є async runtime, і це планування та
координація — одне з його головних завдань.
У розділі “Sending Data Between Two Tasks Using Message
Passing” ми описували очікування на
rx.recv. Виклик recv повертає future, а очікування future опитує його. Ми
зазначали, що runtime призупинить future, доки воно не буде готове з Some(message)
або None, коли канал закривається. З нашим глибшим розумінням трейту Future,
і конкретно Future::poll, ми можемо побачити, як це працює. Runtime знає, що
future не готове, коли воно повертає Poll::Pending. Навпаки, runtime знає, що
future готове і просуває його далі, коли poll повертає
Poll::Ready(Some(message)) або Poll::Ready(None).
Точні деталі того, як runtime робить це, виходять за межі цієї книги, але ключове тут — побачити базову механіку futures: runtime опитує кожне future, за яке він відповідає, знову присипляючи future, коли воно ще не готове.
Тип Pin і трейт Unpin
Ще в Listing 17-13 ми використовували макрос trpl::join!, щоб очікувати три
futures. Однак часто буває колекція, наприклад вектор, що містить певну
кількість futures, які не будуть відомі до часу виконання. Змінимо Listing
17-13 на код у Listing 17-23, який поміщає три futures у вектор
і натомість викликає функцію trpl::join_all, яка ще не скомпілюється.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let futures: Vec<Box<dyn Future<Output = ()>>> =
vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(futures).await;
});
}Ми помістили кожне future всередину Box, щоб зробити їх трейт-об’єктами,
так само як ми робили в розділі “Returning Errors from run” у Chapter 12.
(Ми розглянемо трейт-об’єкти детально в Chapter 18.) Використання трейт-об’єктів
дає змогу розглядати кожне з анонімних futures, створених цими типами, як один
і той самий тип, тому що всі вони реалізують трейт Future.
Це може здатися несподіваним. Зрештою, жоден із async-блоків нічого не
повертає, тож кожен із них створює Future<Output = ()>. Пам’ятайте, однак, що
Future — це трейт, а компілятор створює унікальний enum для кожного async
блоку, навіть коли вони мають ідентичні типи виходу. Так само як ви не можете
помістити дві різні вручну написані структури у Vec, ви не можете змішувати
enum-и, згенеровані компілятором.
Потім ми передаємо колекцію futures до функції trpl::join_all і
очікуємо результат. Однак це не компілюється; ось відповідна частина
повідомлень про помилки.
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
Примітка в цьому повідомленні про помилку каже нам, що ми маємо використати
макрос pin!, щоб pin-ити значення, тобто помістити їх усередину типу
Pin, який гарантує, що значення не будуть переміщені в пам’яті. Повідомлення
про помилку каже, що pinning потрібен тому, що dyn Future<Output = ()> має
реалізовувати трейт Unpin, а наразі цього не робить.
Функція trpl::join_all повертає структуру під назвою JoinAll. Ця структура
є узагальненою за типом F, для якого накладено обмеження реалізовувати
трейт Future. Безпосереднє очікування future за допомогою await
неявно pin-ить future. Саме тому нам не потрібно використовувати pin!
скрізь, де ми хочемо очікувати futures.
Однак тут ми не очікуємо future безпосередньо. Замість цього ми створюємо
нове future, JoinAll, передаючи колекцію futures у функцію join_all.
Сигнатура join_all вимагає, щоб типи елементів у колекції всі реалізовували
трейт Future, а Box<T> реалізує Future лише якщо T, яке він
обгортає, є future, яке реалізує трейт Unpin.
Це багато для сприйняття! Щоб по-справжньому зрозуміти це, занурмося трохи
далі в те, як насправді працює трейт Future, зокрема навколо pinning. Ще
раз погляньте на визначення трейту Future:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
// Required method
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}Параметр cx і його тип Context — це ключ до того, як runtime насправді
знає, коли перевіряти будь-яке конкретне future, залишаючись при цьому
лінивим. Знову ж таки, деталі того, як це працює, виходять за межі цього
розділу, і зазвичай вам потрібно думати про це лише тоді, коли ви пишете
власну реалізацію Future. Натомість ми зосередимося на типі для self,
оскільки це перший раз, коли ми бачимо метод, де self має анотацію типу.
Анотація типу для self працює так само, як анотації типу для інших параметрів
функції, але з двома ключовими відмінностями:
- Вона каже Rust, яким має бути тип
self, щоб метод можна було викликати. - Це не може бути будь-який тип. Він обмежений типом, на якому реалізовано
метод, посиланням або розумним вказівником на цей тип, або
Pin, що обгортає посилання на цей тип.
Ми побачимо більше про цей синтаксис у Chapter 18. Наразі
достатньо знати, що якщо ми хочемо опитати future, щоб перевірити, чи воно
Pending або Ready(Output), нам потрібне змінне посилання, обгорнуте в Pin,
на цей тип.
Pin — це обгортка для вказівникоподібних типів, таких як &, &mut, Box
і Rc.
(Технічно, Pin працює з типами, що реалізують трейт Deref або DerefMut,
але це фактично еквівалентно роботі лише з посиланнями та розумними
вказівниками.) Pin сам по собі не є вказівником і не має власної поведінки,
такої як Rc і Arc з підрахунком посилань; це суто інструмент, який
компілятор може використовувати, щоб забезпечувати обмеження на використання
вказівників.
Пригадування того, що await реалізовано через виклики poll, починає
пояснювати повідомлення про помилку, яке ми бачили раніше, але там ішлося про
Unpin, а не про Pin. То як саме Pin пов’язаний із Unpin, і чому Future
потрібен self у типі Pin, щоб викликати poll?
Пам’ятайте з раніше в цьому розділі, що серія точок await у future компілюється в автомат станів, і компілятор переконується, що цей автомат станів дотримується всіх звичайних правил Rust щодо безпеки, включно із запозиченням і власністю. Щоб це працювало, Rust дивиться на те, які дані потрібні між однією точкою await і або наступною точкою await, або кінцем async-блоку. Потім він створює відповідний варіант у скомпільованому автоматі станів. Кожен варіант отримує доступ, який йому потрібен, до даних, що будуть використані в цій частині вихідного коду, або шляхом отримання власності на ці дані, або шляхом отримання до них змінного чи незмінного посилання.
Поки що все добре: якщо ми щось неправильно зробимо з власністю або
посиланнями в певному async-блоці, перевірник запозичень нам про це скаже.
Коли ж ми хочемо перемістити future, яке відповідає цьому блоку, — наприклад,
перемістити його у Vec, щоб передати до join_all, — усе стає складніше.
Коли ми переміщуємо future — чи то шляхом додавання його в структуру даних,
щоб використати як ітератор із join_all, чи то шляхом повернення його з
функції, — це насправді означає переміщення автомата станів, який Rust
створює для нас. І, на відміну від більшості інших типів у Rust, futures,
які Rust створює для async-блоків, можуть у полях будь-якого конкретного
варіанта виявитися з посиланнями на самі себе, як показано в спрощеній
ілюстрації на Figure 17-4.

За замовчуванням, однак, будь-який об’єкт, що має посилання на самого себе, є небезпечним для переміщення, тому що посилання завжди вказують на фактичну адресу пам’яті того, на що вони посилаються (див. Figure 17-5). Якщо ви перемістите саму структуру даних, ці внутрішні посилання залишаться вказувати на старе місце. Однак це місце пам’яті тепер невалідне. По-перше, його значення не буде оновлено, коли ви внесете зміни до структури даних. По-друге — і це важливіше — комп’ютер тепер може повторно використати цю пам’ять для інших цілей! Згодом ви можете прочитати зовсім не пов’язані дані.

Теоретично, компілятор Rust міг би намагатися оновлювати кожне посилання на об’єкт щоразу, коли його переміщують, але це могло б додати значні накладні витрати продуктивності, особливо якщо потрібно оновлювати цілу мережу посилань. Якби замість цього ми могли переконатися, що відповідна структура даних не переміщується в пам’яті, нам не довелося б оновлювати жодні посилання. Саме для цього й існує перевірник запозичень Rust: у безпечному коді він не дає вам переміщувати будь-який елемент з активним посиланням на нього.
Pin спирається на це, щоб дати нам саме ту гарантію, яка нам потрібна. Коли
ми pin-имо значення, обгортаючи вказівник на це значення в Pin, воно
більше не може переміщуватися. Отже, якщо у вас є Pin<Box<SomeType>>, ви
насправді pin-ите значення SomeType, а не вказівник Box. Figure 17-6
ілюструє цей процес.

Насправді вказівник Box усе ще може вільно переміщуватися. Пам’ятайте: нас
цікавить, щоб дані, на які врешті-решт посилаються, залишалися на місці. Якщо
вказівник переміщується, але дані, на які він вказує, залишаються на тому ж
місці, як на Figure 17-7, проблеми немає. (Як окрему вправу, подивіться
документацію для цих типів, а також модуль std::pin, і спробуйте зрозуміти,
як би ви зробили це з Pin, що обгортає Box.) Ключ у тому, що сама
самореферентна структура не може переміщуватися, бо вона все ще pin-ена.

Однак більшість типів цілком безпечно переміщувати, навіть якщо вони
знаходяться за вказівником Pin. Нам потрібно думати про pinning лише тоді,
коли елементи мають внутрішні посилання. Примітивні значення, такі як числа й
булеві значення, безпечні, тому що вони явно не мають жодних внутрішніх
посилань.
Більшість типів, з якими ви зазвичай працюєте в Rust, також не мають таких
посилань. Наприклад, ви можете переміщувати Vec без хвилювання. З огляду на
те, що ми побачили дотепер, якщо у вас є Pin<Vec<String>>, вам довелося б
робити все через безпечні, але обмежувальні API, які надає Pin, хоча
Vec<String> завжди безпечно переміщувати, якщо немає інших посилань на нього.
Нам потрібен спосіб сказати компілятору, що в таких випадках можна
переміщувати елементи, — і саме тут вступає в дію Unpin.
Unpin — це marker trait, подібний до трейтів Send і Sync, які ми бачили
в Chapter 16, і тому не має власної функціональності. Marker traits існують
лише для того, щоб сказати компілятору, що безпечно використовувати тип, який
реалізує певний трейт, у конкретному контексті. Unpin інформує компілятор,
що певний тип не мусить дотримуватися жодних гарантій щодо того, чи може
значення безпечно переміщуватися.
Так само як і для Send і Sync, компілятор реалізує Unpin автоматично
для всіх типів, для яких може довести, що це безпечно. Особливий випадок,
знову подібний до Send і Sync, — це коли Unpin не реалізовано для
типу. Позначення для цього таке: impl !Unpin for SomeType,
де SomeType — це назва типу, який справді має
дотримуватися цих гарантій, щоб бути безпечним усякий раз, коли в Pin
використовується вказівник на цей тип.
Іншими словами, є дві речі, про які слід пам’ятати щодо зв’язку між Pin і
Unpin. По-перше, Unpin — це “нормальний” випадок, а !Unpin — особливий
випадок. По-друге, чи реалізує тип Unpin, чи !Unpin, лише має значення,
коли ви використовуєте pin-ений вказівник на цей тип, такий як Pin<&mut
SomeType>.
Щоб зробити це конкретним, подумайте про String: у нього є довжина й Unicode
символи, з яких він складається. Ми можемо обгорнути String у Pin, як
показано на Figure 17-8. Однак String автоматично реалізує Unpin, як і
більшість інших типів у Rust.

У результаті ми можемо робити речі, які були б незаконними, якби замість цього
String реалізовував !Unpin, наприклад замінювати один рядок іншим у точно
тому самому місці в пам’яті, як на Figure 17-9. Це не порушує контракт Pin,
тому що String не має внутрішніх посилань, які робили б його небезпечним для
переміщення. Саме тому він реалізує Unpin, а не !Unpin.

Тепер ми знаємо достатньо, щоб зрозуміти помилки, повідомлені для того
виклику join_all ще з Listing 17-23. Спочатку ми намагалися перемістити
futures, створені async-блоками, у Vec<Box<dyn Future<Output = ()>>>, але,
як ми бачили, ці futures можуть мати внутрішні посилання, тож вони не
реалізують Unpin автоматично. Щойно ми їх pin-имо, ми можемо передати
отриманий тип Pin у Vec, будучи впевненими, що базові дані у futures не
будуть переміщені. Listing 17-24 показує, як виправити код, викликавши макрос
pin! там, де визначено кожне з трьох futures, і скоригувавши тип
трейт-об’єкта.
extern crate trpl; // required for mdbook test
use std::pin::{Pin, pin};
// --snip--
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = pin!(async move {
// --snip--
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let rx_fut = pin!(async {
// --snip--
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
let tx_fut = pin!(async move {
// --snip--
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let futures: Vec<Pin<&mut dyn Future<Output = ()>>> =
vec![tx1_fut, rx_fut, tx_fut];
trpl::join_all(futures).await;
});
}Цей приклад тепер компілюється й запускається, і ми могли б додавати або видаляти futures з вектора під час виконання та об’єднувати їх усі.
Pin і Unpin здебільшого важливі для побудови бібліотек нижчого рівня або
коли ви будуєте сам runtime, а не для щоденного коду Rust. Однак, коли ви
бачите ці трейтів у повідомленнях про помилки, тепер у вас буде краще уявлення
про те, як виправити свій код!
Note: Це поєднання
PinіUnpinдає змогу безпечно реалізувати в Rust цілий клас складних типів, які інакше були б складними, тому що вони самореферентні. Типи, що потребуютьPin, найчастіше трапляються в async Rust сьогодні, але час від часу ви можете побачити їх і в інших контекстах.Конкретні подробиці того, як працюють
PinіUnpin, і правила, яких вони мають дотримуватися, детально описані в документації API дляstd::pin, тож якщо ви хочете дізнатися більше, це чудове місце для початку.Якщо ви хочете зрозуміти, як усе працює під капотом ще детальніше, дивіться Chapters 2 і 4 з Asynchronous Programming in Rust.
Трейт Stream
Тепер, коли ви краще розумієте трейт Future, Pin і Unpin, ми можемо
перейти до трейту Stream. Як ви дізналися раніше в цьому розділі, streams
схожі на асинхронні ітератори. Однак, на відміну від Iterator і Future,
Stream на момент написання не має визначення у стандартній бібліотеці, але
існує дуже поширене визначення з крейту futures, яке використовується в
усьому екосистемному просторі.
Перш ніж дивитися, як трейт Stream може об’єднати їх, згадаємо визначення
трейтів Iterator і Future. Від Iterator ми маємо ідею послідовності:
його метод next надає Option<Self::Item>. Від Future ми маємо ідею
готовності з часом: його метод poll надає Poll<Self::Output>. Щоб
представити послідовність елементів, які стають готовими з часом, ми
визначаємо трейт Stream, який поєднує ці можливості:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>
) -> Poll<Option<Self::Item>>;
}
}Трейт Stream визначає асоційований тип під назвою Item для типу елементів,
які продукує stream. Це подібно до Iterator, де може бути від нуля до
багатьох елементів, і на відміну від Future, де завжди є один Output,
навіть якщо це unit-тип ().
Stream також визначає метод для отримання цих елементів. Ми називаємо його
poll_next, щоб було зрозуміло, що він опитує так само, як це робить
Future::poll, і продукує послідовність елементів так само, як це робить
Iterator::next. Його тип повернення поєднує Poll з Option. Зовнішній тип
— Poll, тому що його треба перевіряти на готовність, так само як future.
Внутрішній тип — Option, тому що він має сигналізувати, чи є ще повідомлення,
так само як ітератор.
Імовірно, щось дуже схоже на це визначення згодом стане частиною стандартної бібліотеки Rust. Тим часом це частина інструментарію більшості runtime, тож ви можете на це покладатися, і все, що ми розглянемо далі, загалом має застосовуватися!
У прикладах, які ми бачили в розділі “Streams: Futures in Sequence”, однак, ми не використовували ні poll_next, ні Stream, а
натомість використовували next і StreamExt. Звісно, ми могли б працювати
безпосередньо через API poll_next, написавши вручну власні автомати станів
Stream, так само як ми могли б працювати з futures безпосередньо через
їхній метод poll. Використовувати await набагато приємніше, і трейт
StreamExt надає метод next, щоб ми могли саме так і робити:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>,
) -> Poll<Option<Self::Item>>;
}
trait StreamExt: Stream {
async fn next(&mut self) -> Option<Self::Item>
where
Self: Unpin;
// other methods...
}
}Note: Справжнє визначення, яке ми використали раніше в розділі, виглядає трохи інакше, ніж це, тому що воно підтримує версії Rust, які ще не підтримували використання async-функцій у трейтів. У результаті воно виглядає так:
fn next(&mut self) -> Next<'_, Self> where Self: Unpin;Тип
Next— цеstruct, яка реалізуєFutureі дає нам змогу назвати час життя посилання наselfза допомогоюNext<'_, Self>, щобawaitміг працювати з цим методом.
Трейт StreamExt також є домом для всіх цікавих методів, доступних для
використання зі streams. StreamExt автоматично реалізується для кожного
типу, який реалізує Stream, але ці трейтів визначені окремо, щоб дати змогу
спільноті розвивати API зручності без впливу на базовий трейт.
У версії StreamExt, що використовується в крейті trpl, трейт не лише
визначає метод next, але й надає стандартну реалізацію next, яка правильно
обробляє деталі виклику Stream::poll_next. Це означає, що навіть коли вам
потрібно написати власний тип потокових даних, вам лише потрібно реалізувати
Stream, і тоді будь-хто, хто використовує ваш тип даних, автоматично зможе
використовувати StreamExt і його методи з ним.
Це все, що ми збираємося охопити щодо деталей цих трейтів нижчого рівня. На завершення розгляньмо, як futures (включно зі streams), tasks і threads усе разом поєднуються!
Futures, tasks і потоки
Зводимо все докупи: future, tasks і threads
Як ми бачили в Розділі 16, threads надають один підхід до конкурентності. У цьому розділі ми побачили інший підхід: використання async із future і streams. Якщо ви замислюєтеся, коли обрати один метод замість іншого, відповідь така: це залежить! І в багатьох випадках вибір — не threads або async, а радше threads і async.
Багато операційних систем уже десятиліттями надають моделі конкурентності на основі threads, і як наслідок багато мов програмування їх підтримують. Однак ці моделі не позбавлені своїх компромісів. На багатьох операційних системах вони використовують чималу кількість пам’яті для кожного thread. Threads також є варіантом лише тоді, коли ваші операційна система і апаратура підтримують їх. На відміну від поширених настільних і мобільних комп’ютерів, деякі вбудовані системи взагалі не мають ОС, тож у них також немає threads.
Модель async надає інший — і зрештою взаємодоповнювальний — набір
компромісів. У моделі async паралельні операції не потребують власних
threads. Замість цього вони можуть виконуватися на tasks, як тоді, коли ми
використали trpl::spawn_task, щоб запустити роботу із синхронної функції в
розділі про streams. Task подібний до thread, але замість того, щоб
керуватися операційною системою, ним керує код рівня бібліотеки: runtime.
Є причина, чому API для створення threads і створення tasks такі схожі. Threads виступають межею для наборів синхронних операцій; конкурентність можлива між threads. Tasks виступають межею для наборів асинхронних операцій; конкурентність можлива як між, так і всередині tasks, тому що task може перемикатися між future у своєму тілі. Нарешті, future — це найдрібніша одиниця конкурентності в Rust, і кожен future може представляти дерево інших future. Runtime — зокрема, його executor — керує tasks, а tasks керують future. У цьому сенсі tasks подібні до легких threads, керованих runtime, з додатковими можливостями, що виникають завдяки тому, що ними керує runtime, а не операційна система.
Це не означає, що async tasks завжди кращі за threads (або навпаки).
Конкурентність із threads у деяких аспектах є простішою моделлю програмування,
ніж конкурентність з async. Це може бути як перевагою, так і недоліком.
Threads певною мірою працюють за принципом “запустив і забув”; у них немає
вбудованого аналога future, тож вони просто виконуються до завершення, не
перериваючись нічим, окрім самої операційної системи.
І виявляється, що threads і tasks часто дуже добре працюють разом, тому що
tasks можуть (принаймні в деяких runtime) переміщуватися між threads. Фактично,
під капотом runtime, який ми використовували, — включно з функціями
spawn_blocking і spawn_task — за замовчуванням є багатопотоковим!
Багато runtime використовують підхід, який називається work stealing, щоб
прозоро переміщувати tasks між threads залежно від того, як саме threads
зараз використовуються, щоб покращити загальну продуктивність системи. Цей
підхід насправді потребує threads і tasks, а отже й future.
Коли думаєте про те, який метод використовувати в певній ситуації, враховуйте такі правила:
- Якщо робота дуже добре паралелізується (тобто є CPU-bound), наприклад, оброблення великого обсягу даних, де кожну частину можна обробити окремо, threads є кращим вибором.
- Якщо робота дуже конкурентна (тобто є I/O-bound), наприклад, оброблення повідомлень із великої кількості різних джерел, які можуть надходити з різними інтервалами або з різною швидкістю, async є кращим вибором.
І якщо вам потрібні і паралелізм, і конкурентність, вам не потрібно обирати між threads і async. Ви можете вільно використовувати їх разом, дозволяючи кожному виконувати ту роль, у якій він найкращий. Наприклад, Уривок 17-25 показує досить поширений приклад такого поєднання в реальному Rust-коді.
extern crate trpl; // for mdbook test
use std::{thread, time::Duration};
fn main() {
let (tx, mut rx) = trpl::channel();
thread::spawn(move || {
for i in 1..11 {
tx.send(i).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
trpl::block_on(async {
while let Some(message) = rx.recv().await {
println!("{message}");
}
});
}Ми починаємо зі створення async-каналу, а потім створюємо thread, який
заволодіває стороною відправника каналу за допомогою ключового слова move.
Усередині thread ми надсилаємо числа від 1 до 10, засинаючи на секунду між
кожним. Нарешті, ми запускаємо future, створений за допомогою async-блоку,
переданого до trpl::block_on, так само, як ми робили протягом цього розділу.
У цьому future ми чекаємо ці повідомлення, так само, як і в інших прикладах
передавання повідомлень, які ми бачили.
Повертаючись до сценарію, з якого ми почали розділ, уявіть собі виконання набору задач кодування відео з використанням окремого thread (оскільки кодування відео є обчислювально навантаженим), але сповіщення UI про те, що ці операції завершено, за допомогою async-каналу. Існує безліч прикладів таких поєднань у реальних сценаріях використання.
Підсумок
Це не останнє, що ви побачите про конкурентність у цій книзі. Проєкт у Розділі 21 застосує ці концепції в більш реалістичній ситуації, ніж простіші приклади, розглянуті тут, і безпосередніше порівняє розв’язання проблем за допомогою threads, порівняно з tasks і future.
Незалежно від того, який із цих підходів ви оберете, Rust надає вам інструменти, потрібні для написання безпечного, швидкого, конкурентного коду — чи то для вебсервера з високою пропускною здатністю, чи то для вбудованої операційної системи.
Далі ми поговоримо про ідіоматичні способи моделювання проблем і структурування розв’язків у міру того, як ваші Rust-програми ставатимуть більшими. Крім того, ми обговоримо, як ідіоми Rust пов’язані з тими, які вам можуть бути знайомі з об’єктно-орієнтованого програмування.
Ознаки об’єктно-орієнтованого програмування
Об’єктно-орієнтоване програмування (OOP) — це спосіб моделювання програм. Об’єкти як програмна концепція були введені в мову програмування Simula в 1960-х роках. Ті об’єкти вплинули на програмувальну архітектуру Алана Кея, у якій об’єкти передають повідомлення один одному. Щоб описати цю архітектуру, він увів термін object-oriented programming у 1967 році. Багато конкуруючих визначень описують, що таке OOP, і за деякими з цих визначень Rust є об’єктно орієнтованим, але за іншими — ні. У цьому розділі ми дослідимо певні характеристики, які зазвичай вважаються об’єктно орієнтованими, і як ці характеристики переносяться на ідіоматичний Rust. Потім ми покажемо вам, як реалізувати об’єктно-орієнтований шаблон проєктування в Rust, і обговоримо компроміси такого підходу порівняно з реалізацією рішення, що використовує деякі сильні сторони Rust.
Характеристики об'єктно-орієнтованих мов
Характеристики об’єктно-орієнтованих мов
У спільноті програмування немає консенсусу щодо того, якими саме можливостями має володіти мова, щоб вважатися об’єктно-орієнтованою. Rust зазнав впливу багатьох парадигм програмування, зокрема OOP; наприклад, ми дослідили можливості, що походять із функціонального програмування, у Розділі 13. Можна стверджувати, що OOP-мови мають певні спільні характеристики — а саме об’єкти, інкапсуляцію та успадкування. Давайте розглянемо, що означає кожна з цих характеристик і чи підтримує їх Rust.
Об’єкти містять дані та поведінку
Книга Design Patterns: Elements of Reusable Object-Oriented Software авторів Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (Addison-Wesley, 1994), яку в розмовній мові називають книгою The Gang of Four, є каталогом об’єктно-орієнтованих шаблонів проєктування. Вона визначає OOP так:
Об’єктно-орієнтовані програми складаються з об’єктів. Об’єкт упаковує як дані, так і процедури, що працюють із цими даними. Процедури зазвичай називають методами або операціями.
Згідно з цим визначенням, Rust є об’єктно-орієнтованим: структури та переліки
мають дані, а блоки impl надають методи для структур і переліків. Хоча
структури та переліки з методами не називають об’єктами, вони надають ту саму
функціональність, відповідно до визначення об’єктів із книги Gang of Four.
Інкапсуляція, що приховує деталі реалізації
Інший аспект, який зазвичай пов’язують з OOP, — це ідея інкапсуляції, що означає, що деталі реалізації об’єкта недоступні для коду, який використовує цей об’єкт. Отже, єдиний спосіб взаємодіяти з об’єктом — через його публічний API; код, що використовує об’єкт, не повинен мати змоги дістатися до внутрішньої структури об’єкта і змінювати дані або поведінку напряму. Це дає програмісту змогу змінювати та рефакторити внутрішню структуру об’єкта без потреби змінювати код, який використовує об’єкт.
Ми обговорювали, як керувати інкапсуляцією в Розділі 7: ми можемо використати
ключове слово pub, щоб вирішити, які модулі, типи, функції та методи в нашому
коді мають бути публічними, а за замовчуванням усе інше є приватним. Наприклад,
ми можемо визначити структуру AveragedCollection, яка має поле, що містить
вектор значень i32. Структура також може мати поле, що містить середнє
значення елементів у векторі, тобто середнє не потрібно обчислювати на вимогу
кожного разу, коли воно потрібне. Іншими словами, AveragedCollection буде
кешувати обчислене середнє значення для нас. У Переліку 18-1 наведено
визначення структури AveragedCollection.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}Структура позначена як pub, щоб інший код міг її використовувати, але поля
всередині структури залишаються приватними. Це важливо в цьому випадку, тому що
ми хочемо гарантувати, що щоразу, коли значення додається до списку або
видаляється з нього, середнє значення також оновлюється. Ми робимо це,
реалізуючи методи add, remove і average для структури, як показано в
Переліку 18-2.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}Публічні методи add, remove і average — це єдині способи отримати доступ
до даних або змінити їх в екземплярі AveragedCollection. Коли елемент
додається до list за допомогою методу add або видаляється за допомогою
методу remove, реалізації кожного з них викликають приватний метод
update_average, який також відповідає за оновлення поля average.
Ми залишаємо поля list і average приватними, щоб не було способу для
зовнішнього коду додавати елементи до поля list або видаляти їх із нього
безпосередньо; інакше поле average могло б стати несинхронним, коли list
змінюється. Метод average повертає значення в полі average, дозволяючи
зовнішньому коду читати average, але не змінювати його.
Оскільки ми інкапсулювали деталі реалізації структури
AveragedCollection, ми можемо легко змінити такі аспекти, як структура даних,
у майбутньому. Наприклад, ми могли б використати HashSet<i32> замість
Vec<i32> для поля list. Поки сигнатури публічних методів add,
remove і average залишалися б незмінними, код, що використовує
AveragedCollection, не потребував би змін. Якби ми зробили list публічним
замість цього, це не обов’язково було б так: HashSet<i32> і Vec<i32> мають
різні методи для додавання і видалення елементів, тож зовнішньому коду, імовірно,
довелося б змінитися, якби він модифікував list безпосередньо.
Якщо інкапсуляція є обов’язковим аспектом для того, щоб мова вважалася
об’єктно-орієнтованою, тоді Rust відповідає цій вимозі. Можливість
використовувати pub або не використовувати його для різних частин коду
забезпечує інкапсуляцію деталей реалізації.
Успадкування як система типів і як спільне використання коду
Успадкування — це механізм, за допомогою якого об’єкт може успадковувати елементи з визначення іншого об’єкта, таким чином отримуючи дані та поведінку батьківського об’єкта без потреби визначати їх знову.
Якщо мова повинна мати успадкування, щоб бути об’єктно-орієнтованою, тоді Rust не є такою мовою. Немає способу визначити структуру, яка успадковує поля та реалізації методів батьківської структури, без використання макросу.
Однак, якщо ви звикли мати успадкування у своєму інструментарії програмування, ви можете використовувати інші рішення в Rust, залежно від вашої причини звертатися до успадкування.
Ви б обрали успадкування з двох основних причин. Одна — для повторного
використання коду: ви можете реалізувати певну поведінку для одного типу, і
успадкування дає змогу повторно використати цю реалізацію для іншого типу. Ви
можете робити це в обмеженому вигляді в коді Rust, використовуючи реалізації
методів трейтів за замовчуванням, які ви бачили в Переліку 10-14, коли ми
додали реалізацію методу summarize за замовчуванням для трейт Summary.
Будь-який тип, що реалізує трейт Summary, матиме доступний для нього метод
summarize без додаткового коду. Це подібно до того, як батьківський клас має
реалізацію методу, а дочірній клас, що успадковує, також має реалізацію цього
методу. Ми також можемо перевизначити реалізацію методу summarize за
замовчуванням, коли реалізуємо трейт Summary, що подібно до того, як дочірній
клас перевизначає реалізацію методу, успадкованого від батьківського класу.
Інша причина використовувати успадкування пов’язана зі системою типів: щоб дозволити використовувати дочірній тип у тих самих місцях, що й батьківський тип. Це також називається поліморфізмом, що означає, що ви можете підставляти кілька об’єктів один замість одного під час виконання, якщо вони мають певні спільні характеристики.
Поліморфізм
Для багатьох людей поліморфізм є синонімом успадкування. Але насправді це більш загальне поняття, яке стосується коду, здатного працювати з даними кількох типів. Для успадкування цими типами зазвичай є підкласи.
Натомість Rust використовує узагальнені типи, щоб абстрагуватися від різних можливих типів, і обмеження трейтів, щоб накладати умови на те, що ці типи повинні надавати. Це іноді називають обмеженим параметричним поліморфізмом.
Rust обрав інший набір компромісів, не пропонуючи успадкування. Успадкування часто пов’язане з ризиком спільного використання більшої кількості коду, ніж потрібно. Підкласи не завжди повинні ділити всі характеристики свого батьківського класу, але з успадкуванням це відбувається. Це може зробити проєктування програми менш гнучким. Воно також створює можливість виклику методів на підкласах, які не мають сенсу або спричиняють помилки, тому що методи не застосовуються до підкласу. Крім того, деякі мови дозволяють лише одиночне успадкування (тобто підклас може успадковувати лише від одного класу), що ще більше обмежує гнучкість проєктування програми.
З цих причин Rust обирає інший підхід, використовуючи трейт-об’єкти замість успадкування, щоб досягати поліморфізму під час виконання. Давайте подивимося, як працюють трейт-об’єкти.
Використання трейт-об'єктів (trait objects) для абстрагування над спільною поведінкою
Використання трейт-об’єктів для абстрагування над спільною поведінкою
У розділі 8 ми згадували, що одне з обмежень векторів полягає в тому, що вони можуть
зберігати елементи лише одного типу. Ми створили обхідний шлях у Лістингу 8-9, де
визначили перелік SpreadsheetCell, який мав варіанти для зберігання цілих чисел, чисел з плаваючою
комою та тексту. Це означало, що ми могли зберігати різні типи даних у кожній комірці й
водночас мати вектор, який представляв рядок комірок. Це цілком добрий
розв’язок, коли наші взаємозамінні елементи — це фіксований набір типів, який ми знаємо
коли наш код компілюється.
Однак іноді ми хочемо, щоб користувач нашої бібліотеки міг розширювати набір
типів, які є дійсними в певній ситуації. Щоб показати, як ми могли б досягти
цього, ми створимо приклад інструмента графічного інтерфейсу користувача (GUI), який ітерує
через список елементів, викликаючи метод draw для кожного з них, щоб намалювати його на
екрані — поширена техніка для інструментів GUI. Ми створимо крейт бібліотеки під назвою
gui, який містить структуру бібліотеки GUI. Цей крейт може включати
деякі типи для використання людьми, такі як Button або TextField. Крім того,
користувачі gui захочуть створювати власні типи, які можна малювати: наприклад,
один програміст може додати Image, а інший може додати
SelectBox.
На момент написання бібліотеки ми не можемо знати й визначити всі типи, які
інші програмісти можуть захотіти створити. Але ми знаємо, що gui потрібно відстежувати
багато значень різних типів, і йому потрібно викликати метод draw
для кожного з цих значень різних типів. Йому не потрібно точно знати, що
станеться, коли ми викличемо метод draw, лише те, що значення матиме цей
метод, доступний для виклику.
Щоб зробити це в мові з успадкуванням, ми могли б визначити клас під назвою
Component, у якого є метод під назвою draw. Інші класи, такі як
Button, Image і SelectBox, успадковували б від Component і таким чином
успадковували б метод draw. Кожен із них міг би перевизначити метод draw, щоб визначити
їхню власну поведінку, але фреймворк міг би розглядати всі типи так, ніби
вони були екземплярами Component, і викликати на них draw. Але оскільки Rust
не має успадкування, нам потрібен інший спосіб структурувати бібліотеку gui, щоб
дозволити користувачам створювати нові типи, сумісні з бібліотекою.
Визначення трейту для спільної поведінки
Щоб реалізувати поведінку, яку ми хочемо мати в gui, ми визначимо трейт
під назвою Draw, який матиме один метод під назвою draw. Потім ми можемо визначити
вектор, який приймає трейт-об’єкт. Трейт-об’єкт вказує і на екземпляр
типу, що реалізує наш вказаний трейт, і на таблицю, яка використовується для пошуку методів трейту для цього типу під час виконання. Ми створюємо трейт-об’єкт, вказуючи певний
вид вказівника, наприклад посилання або розумний вказівник Box<T>, потім
ключове слово dyn, а потім відповідний трейт. (Ми поговоримо про
причину, чому трейт-об’єкти мають використовувати вказівник, у “Динамічно розмірних типах та
трейті Sized” у розділі 20.) Ми можемо використовувати
трейт-об’єкти замість узагальненого або конкретного типу. Де б ми не використовували трейт-
об’єкт, система типів Rust на етапі компіляції гарантуватиме, що будь-яке значення, яке використовується в
цьому контексті, реалізовуватиме трейт трейт-об’єкта. Отже, нам не
потрібно знати всі можливі типи на етапі компіляції.
Ми вже згадували, що в Rust ми утримуємося від називання структур і переліків
“об’єктами”, щоб відрізняти їх від об’єктів в інших мовах. У структурі або
переліку дані в полях структури та поведінка в блоках impl є
розділеними, тоді як в інших мовах дані й поведінка, об’єднані в одне
поняття, часто називають об’єктом. Трейт-об’єкти відрізняються від об’єктів в інших
мовах тим, що ми не можемо додавати дані до трейт-об’єкта. Трейт-об’єкти не є настільки
загально корисними, як об’єкти в інших мовах: їхнє конкретне призначення — це
дозволити абстрагування над спільною поведінкою.
Лістинг 18-3 показує, як визначити трейт під назвою Draw з одним методом під назвою
draw.
pub trait Draw {
fn draw(&self);
}Цей синтаксис має бути вам знайомий із наших обговорень про те, як визначати трейт
у розділі 10. Далі йде дещо новий синтаксис: Лістинг 18-4 визначає структуру під назвою
Screen, яка містить вектор під назвою components. Цей вектор має тип
Box<dyn Draw>, який є трейт-об’єктом; це заміна для будь-якого типу всередині
Box, що реалізує трейт Draw.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}Для структури Screen ми визначимо метод під назвою run, який викликатиме
метод draw для кожного з її components, як показано в Лістингу 18-5.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Це працює інакше, ніж визначення структури, яка використовує узагальнений параметр
типу з обмеженнями трейту. Узагальнений параметр типу може бути замінений
лише одним конкретним типом за раз, тоді як трейт-об’єкти дозволяють кільком
конкретним типам заповнювати місце трейт-об’єкта під час виконання. Наприклад, ми
могли б визначити структуру Screen з використанням узагальненого типу й обмеження трейту,
як у Лістингу 18-6.
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Це обмежує нас екземпляром Screen, який має список компонентів усіх
типу Button або всіх типу TextField. Якщо у вас завжди будуть лише однорідні
колекції, використання узагальнень і обмежень трейту є кращим, тому що
визначення будуть моноформізовані під час компіляції для використання конкретних типів.
З іншого боку, з методом, який використовує трейт-об’єкти, один екземпляр Screen
може містити Vec<T>, що містить Box<Button>, а також
Box<TextField>. Давайте подивимося, як це працює, а потім поговоримо про
наслідки для продуктивності під час виконання.
Реалізація трейту
Тепер ми додамо деякі типи, які реалізують трейт Draw. Ми надамо
тип Button. Знову ж таки, фактична реалізація бібліотеки GUI виходить за межі
цієї книги, тому метод draw не матиме жодної корисної реалізації в своєму
тілі. Щоб уявити, як могла б виглядати реалізація, структура Button
могла б мати поля для width, height і label, як показано в Лістингу 18-7.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}Поля width, height і label у Button відрізнятимуться від
полів в інших компонентах; наприклад, тип TextField може мати ті самі поля
плюс поле placeholder. Кожен із типів, які ми хочемо малювати на
екрані, реалізовуватиме трейт Draw, але використовуватиме різний код у
методі draw, щоб визначити, як малювати цей конкретний тип, як це зроблено тут у Button
(без фактичного коду GUI, як уже згадувалося). Тип Button, наприклад,
може мати додатковий блок impl, що містить методи, пов’язані з тим, що
відбувається, коли користувач натискає кнопку. Такі методи не будуть застосовні до
типів на кшталт TextField.
Якщо хтось, хто використовує нашу бібліотеку, вирішить реалізувати структуру SelectBox, яка має
поля width, height і options, він реалізує трейт Draw
для типу SelectBox також, як показано в Лістингу 18-8.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}Користувач нашої бібліотеки тепер може написати свою функцію main, щоб створити екземпляр
Screen. До екземпляра Screen вони можуть додати SelectBox і Button,
поклавши кожен у Box<T>, щоб стати трейт-об’єктом. Потім вони можуть викликати
метод run на екземплярі Screen, який викличе draw для кожного з
компонентів. Лістинг 18-9 показує цю реалізацію.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}Коли ми писали бібліотеку, ми не знали, що хтось може додати
тип SelectBox, але наша реалізація Screen змогла працювати з
новим типом і намалювати його, тому що SelectBox реалізує трейт Draw, що
означає, що він реалізує метод draw.
Ця концепція — дбати лише про повідомлення, на які значення відповідає,
а не про конкретний тип значення, — подібна до концепції duck
typing у мовах із динамічною типізацією: якщо це ходить, як качка, і крякає, як
качка, то це мусить бути качка! У реалізації run для Screen у
Лістингу 18-5 run не потрібно знати, який конкретний тип має кожен
компонент. Він не перевіряє, чи є компонент екземпляром Button
або SelectBox, він просто викликає метод draw на компоненті. Вказавши
Box<dyn Draw> як тип значень у векторі components, ми визначили Screen
так, що йому потрібні значення, для яких ми можемо викликати
метод draw.
Перевага використання трейт-об’єктів і системи типів Rust для написання коду,
подібного до коду з duck typing, полягає в тому, що нам ніколи не доводиться перевіряти, чи
реалізує значення певний метод під час виконання, або турбуватися про отримання помилок,
якщо значення не реалізує метод, але ми все одно його викликаємо. Rust не скомпілює
наш код, якщо значення не реалізують трейтів, яких потребують трейт-об’єкти.
Наприклад, Лістинг 18-10 показує, що станеться, якщо ми спробуємо створити Screen
з String як компонентом.
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}Ми отримаємо цю помилку, тому що String не реалізує трейт Draw:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `Box<String>` to `Box<dyn Draw>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
Ця помилка повідомляє нам, що або ми передаємо до Screen щось, що
не мали на увазі передати, і тому повинні передати інший тип, або ми повинні реалізувати
Draw для String, щоб Screen міг викликати на ньому draw.
Виконання динамічної диспетчеризації
Згадайте в “Продуктивність коду з узагальненнями” у розділі 10 наше обговорення процесу моноформізації, який компілятор виконує для узагальнень: компілятор генерує неузагальнені реалізації функцій і методів для кожного конкретного типу, який ми використовуємо замість узагальненого параметра типу. Код, що виникає внаслідок моноформізації, виконує статичну диспетчеризацію, тобто коли компілятор знає, який метод ви викликаєте під час компіляції. Це протиставляється динамічній диспетчеризації, тобто коли компілятор не може визначити під час компіляції, який метод ви викликаєте. У випадках динамічної диспетчеризації компілятор видає код, який під час виконання знатиме, який метод викликати.
Коли ми використовуємо трейт-об’єкти, Rust має використовувати динамічну диспетчеризацію. Компілятор не знає всіх типів, які можуть використовуватися з кодом, що використовує трейт-об’єкти, тому він не знає, який метод, реалізований для якого типу, викликати. Замість цього під час виконання Rust використовує вказівники всередині трейт-об’єкта, щоб знати, який метод викликати. Це звернення коштує часу виконання, чого не відбувається зі статичною диспетчеризацією. Динамічна диспетчеризація також заважає компілятору обрати вбудовування коду методу, що, у свою чергу, заважає деяким оптимізаціям, і в Rust є деякі правила щодо того, де можна, а де не можна використовувати динамічну диспетчеризацію, які називаються dyn-сумісністю. Ці правила виходять за межі цього обговорення, але ви можете прочитати більше про них у довіднику. Однак ми отримали додаткову гнучкість у коді, який ми написали в Лістингу 18-5, і змогли підтримати її в Лістингу 18-9, тож це компроміс, який варто враховувати.
Реалізація шаблону проєктування об'єктно-орієнтованого програмування
Реалізація об’єктно-орієнтованого шаблону проєктування
Шаблон стану є об’єктно-орієнтованим шаблоном проєктування. Суть цього шаблону полягає в тому, що ми визначаємо набір станів, які значення може мати внутрішньо. Стани представлені набором об’єктів стану, і поведінка значення змінюється залежно від його стану. Ми розглянемо приклад структури публікації в блозі, яка має поле для зберігання свого стану, і цей стан буде об’єктом стану з набору “draft”, “review” або “published.”
Об’єкти стану мають спільну функціональність: у Rust, звісно, ми використовуємо структури та трейти, а не об’єкти та наслідування. Кожен об’єкт стану відповідає за власну поведінку та за визначення того, коли він має перейти в інший стан. Значення, що містить об’єкт стану, нічого не знає про різну поведінку станів або про те, коли потрібно переходити між станами.
Перевага використання шаблону стану полягає в тому, що коли бізнес-вимоги програми змінюються, нам не потрібно буде змінювати код значення, яке містить стан, або код, що використовує це значення. Нам потрібно буде лише оновити код усередині одного з об’єктів стану, щоб змінити його правила або, можливо, додати більше об’єктів стану.
Спочатку ми реалізуємо шаблон стану у більш традиційний об’єктно-орієнтований спосіб. Потім ми використаємо підхід, який у Rust є трохи природнішим. Розгляньмо покрокову реалізацію робочого процесу публікації в блозі, використовуючи шаблон стану.
Фінальна функціональність виглядатиме так:
- Публікація в блозі починається як порожній чернетковий запис.
- Коли чернетка готова, запитується перегляд публікації.
- Коли публікацію схвалено, вона публікується.
- Лише опубліковані публікації в блозі повертають вміст для друку, щоб не схвалені публікації не могли випадково бути опубліковані.
Будь-які інші спроби зміни публікації не мають жодного ефекту. Наприклад, якщо ми спробуємо схвалити чернетку публікації в блозі до того, як ми запросили перегляд, публікація має залишитися неопублікованою чернеткою.
Спроба традиційного об’єктно-орієнтованого стилю
Існує нескінченно багато способів структурувати код для розв’язання однієї й тієї самої проблеми, кожен із різними компромісами. Реалізація цього розділу є більш традиційним об’єктно-орієнтованим стилем, який можна написати в Rust, але який не використовує деякі сильні сторони Rust. Пізніше ми продемонструємо інше рішення, яке все ще використовує об’єктно-орієнтований шаблон проєктування, але структуроване так, що може здаватися менш знайомим програмістам із об’єктно-орієнтованим досвідом. Ми порівняємо два рішення, щоб відчути компроміси проєктування коду Rust інакше, ніж код у інших мовах.
У лістингу 18-11 показано цей робочий процес у вигляді коду: це приклад
використання API, який ми реалізуємо в бібліотечному крейті з назвою blog.
Це ще не збереться, тому що ми ще не реалізували крейт blog.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Ми хочемо дозволити користувачеві створювати нову чернеткову публікацію в блозі
за допомогою Post::new. Ми хочемо дозволити додавати текст до публікації в
блозі. Якщо ми спробуємо отримати вміст публікації одразу, до схвалення, ми не
повинні отримати жодного тексту, тому що публікація все ще є чернеткою. Ми
додали assert_eq! у коді для демонстраційних цілей. Чудовим unit test для
цього було б перевірити, що чернеткова публікація в блозі повертає порожній
рядок із методу content, але для цього прикладу ми не будемо писати тести.
Далі ми хочемо увімкнути запит на перегляд публікації, і ми хочемо, щоб
content повертав порожній рядок під час очікування перегляду. Коли публікація
отримує схвалення, вона має бути опублікована, тобто текст публікації буде
повернуто, коли викликається content.
Зверніть увагу, що єдиний тип, з яким ми взаємодіємо з крейту, — це тип
Post. Цей тип використовуватиме шаблон стану та міститиме значення, яке буде
одним із трьох об’єктів стану, що представляють різні стани, у яких може
перебувати публікація — draft, review або published. Перехід з одного стану
в інший буде керуватися всередині типу Post. Зміни станів відбуваються у
відповідь на методи, які викликають користувачі нашої бібліотеки на екземплярі
Post, але їм не потрібно безпосередньо керувати змінами стану. Також
користувачі не можуть припуститися помилки зі станами, наприклад опублікувати
публікацію до того, як її переглянули.
Визначення Post і створення нового екземпляра
Почнімо реалізацію бібліотеки! Ми знаємо, що нам потрібна публічна структура
Post, яка зберігає деякий вміст, тож ми почнемо з визначення структури та
асоційованої публічної функції new для створення екземпляра Post, як
показано в лістингу 18-12. Ми також створимо приватний трейт State, який
визначатиме поведінку, яку повинні мати всі об’єкти стану для Post.
Потім Post міститиме трейт-об’єкт Box<dyn State> всередині Option<T> у
приватному полі з назвою state для зберігання об’єкта стану. Незабаром ви
побачите, чому Option<T> є необхідним.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}Трейт State визначає поведінку, спільну для різних станів публікації. Об’єкти
стану — це Draft, PendingReview і Published, і всі вони реалізовуватимуть
трейт State. Наразі трейт не має жодних методів, і ми почнемо лише з
визначення стану Draft, тому що саме в цьому стані публікація має починатися.
Коли ми створюємо новий Post, ми встановлюємо поле state у значення Some,
яке містить Box. Цей Box вказує на новий екземпляр структури Draft. Це
гарантує, що щоразу, коли ми створюємо новий екземпляр Post, він починатиме
як чернетка. Оскільки поле state у Post є приватним, немає способу створити
Post у будь-якому іншому стані! У функції Post::new ми встановлюємо поле
content у новий порожній String.
Зберігання тексту вмісту публікації
У лістингу 18-11 ми бачили, що хочемо мати змогу викликати метод із назвою
add_text і передавати йому &str, який потім додається як текстовий вміст
публікації в блозі. Ми реалізуємо це як метод, а не як відкриття поля content
через pub, щоб пізніше ми могли реалізувати метод, який контролюватиме, як
зчитуються дані поля content. Метод add_text досить простий, тож додаймо
реалізацію в лістингу 18-13 до блоку impl Post.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}Метод add_text приймає змінне посилання на self, тому що ми змінюємо
екземпляр Post, на якому викликаємо add_text. Потім ми викликаємо push_str
на String у content і передаємо аргумент text, щоб додати його до
збереженого content. Ця поведінка не залежить від стану, в якому перебуває
публікація, тож вона не є частиною шаблону стану. Метод add_text взагалі не
взаємодіє з полем state, але він є частиною поведінки, яку ми хочемо
підтримувати.
Забезпечення того, що вміст чернеткової публікації порожній
Навіть після того, як ми викликали add_text і додали трохи вмісту до нашої
публікації, ми все ще хочемо, щоб метод content повертав порожній зріз рядка,
тому що публікація все ще перебуває в стані чернетки, як показано першим
assert_eq! у лістингу 18-11. Наразі реалізуємо метод content з найпростішим
рішенням, яке задовольнить цю вимогу: завжди повертати порожній зріз рядка.
Ми змінимо це пізніше, коли реалізуємо можливість змінювати стан публікації,
щоб її можна було опублікувати. Поки що публікації можуть бути лише в стані
чернетки, тож вміст публікації завжди має бути порожнім. У лістингу 18-14
показано цю тимчасову реалізацію.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}Після додавання цього методу content усе в лістингу 18-11 аж до першого
assert_eq! працює так, як задумано.
Запит перегляду, який змінює стан публікації
Далі нам потрібно додати функціональність, щоб запитувати перегляд публікації,
що має змінити її стан з Draft на PendingReview. У лістингу 18-15 показано
цей код.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}Ми даємо Post публічний метод із назвою request_review, який прийматиме
змінне посилання на self. Потім ми викликаємо внутрішній метод
request_review на поточному стані Post, і цей другий метод request_review
споживає поточний стан і повертає новий стан.
Ми додаємо метод request_review до трейту State; усі типи, які реалізують
трейт, тепер повинні будуть реалізувати метод request_review. Зверніть увагу,
що замість self, &self або &mut self як першого параметра методу ми маємо
self: Box<Self>. Цей синтаксис означає, що метод є дійсним лише тоді, коли
його викликають на Box, що містить цей тип. Цей синтаксис передає власність
на Box<Self>, роблячи старий стан недійсним, щоб значення стану Post могло
перетворитися на новий стан.
Щоб спожити старий стан, метод request_review має взяти власність на
значення стану. Саме тут і стає у пригоді Option у полі state структури
Post: ми викликаємо метод take, щоб забрати значення Some із поля state
і залишити на його місці None, тому що Rust не дозволяє нам мати незаповнені
поля в структурах. Це дає нам змогу перемістити значення state з Post, а не
запозичувати його. Потім ми встановимо значення стану публікації в результат
цієї операції.
Нам потрібно тимчасово встановити state у None, а не присвоювати його
безпосередньо, як у коді self.state = self.state.request_review();, щоб
отримати власність на значення state. Це гарантує, що Post не зможе
використати старе значення state після того, як ми перетворили його на новий
стан.
Метод request_review у Draft повертає новий екземпляр PendingReview, який
загорнуто в Box, і цей новий тип представляє стан, коли публікація чекає на
перегляд. Структура PendingReview також реалізує метод request_review, але
не виконує жодних перетворень. Натомість вона повертає себе, тому що коли ми
запитуємо перегляд публікації, яка вже перебуває в стані PendingReview, вона
має залишатися в стані PendingReview.
Тепер ми можемо почати бачити переваги шаблону стану: метод request_review
на Post є однаковим незалежно від значення state. Кожен стан відповідає за
власні правила.
Ми залишимо метод content на Post без змін, таким, що повертає порожній
зріз рядка. Тепер у нас може бути Post у стані PendingReview, так само як і
в стані Draft, але ми хочемо таку саму поведінку в стані PendingReview.
Тепер лістинг 18-11 працює аж до другого виклику assert_eq!!
Додавання approve для зміни поведінки content
Метод approve буде схожий на метод request_review: він встановить
state у значення, яке, на думку поточного стану, воно має мати, коли цей стан
схвалено, як показано в лістингу 18-16.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}Ми додаємо метод approve до трейту State і додаємо нову структуру, що
реалізує State, — стан Published.
Подібно до того, як працює request_review у PendingReview, якщо ми викликаємо
метод approve на Draft, це не матиме жодного ефекту, тому що approve
поверне self. Коли ми викликаємо approve на PendingReview, він повертає
новий екземпляр Published, загорнутий у Box. Структура Published
реалізує трейт State, і для методу request_review, і для методу approve
вона повертає себе, тому що публікація має залишатися в стані Published у
цих випадках.
Тепер нам потрібно оновити метод content на Post. Ми хочемо, щоб значення,
яке повертає content, залежало від поточного стану Post, тож ми змусимо
Post делегувати метод content, визначений у його state, як показано в
лістингу 18-17.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}Оскільки мета полягає в тому, щоб зберегти всі ці правила всередині структур,
які реалізують State, ми викликаємо метод content на значенні в state і
передаємо екземпляр публікації (тобто self) як аргумент. Потім ми повертаємо
значення, яке повернулося з використання методу content на значенні state.
Ми викликаємо метод as_ref на Option, тому що хочемо посилання на значення
всередині Option, а не власність на це значення. Оскільки state —
це Option<Box<dyn State>>, коли ми викликаємо as_ref, повертається
Option<&Box<dyn State>>. Якби ми не викликали as_ref, ми б отримали
помилку, тому що не можемо перемістити state з позиченого &self параметра
функції.
Потім ми викликаємо метод unwrap, який, як ми знаємо, ніколи не спричинить
паніку, тому що ми знаємо, що методи на Post гарантують, що state завжди
міститиме значення Some, коли ці методи завершать роботу. Це один із тих
випадків, про які ми говорили в розділі “When You Have More Information Than the
Compiler” у розділі 9, коли ми знаємо, що
значення None ніколи не можливе, хоча компілятор не може цього зрозуміти.
На цьому етапі, коли ми викликаємо content на &Box<dyn State>, спрацює
deref coercion для & і Box, так що метод content у підсумку буде викликано
на типі, який реалізує трейт State. Це означає, що нам потрібно додати
content до визначення трейту State, і саме там ми розмістимо логіку того,
який вміст повертати залежно від того, який стан ми маємо, як показано в
лістингу 18-18.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}Ми додаємо реалізацію за замовчуванням для методу content, яка повертає
порожній зріз рядка. Це означає, що нам не потрібно реалізовувати content у
структурах Draft і PendingReview. Структура Published перевизначить метод
content і поверне значення в post.content. Хоча це зручно, надання
методу content у State для визначення вмісту Post розмиває межі між
відповідальністю State і відповідальністю Post.
Зверніть увагу, що нам потрібні анотації часу життя для цього методу, як ми
обговорювали в розділі 10. Ми беремо посилання на post як аргумент і
повертаємо посилання на частину цього post, тож час життя повернутого
посилання пов’язаний із часом життя аргументу post.
І на цьому все — тепер працює весь лістинг 18-11! Ми реалізували шаблон стану
з правилами робочого процесу публікації в блозі. Логіка, пов’язана з правилами,
знаходиться в об’єктах стану, а не розкидана по всьому Post.
Чому не
enum?Можливо, ви замислювалися, чому ми не використали
enumіз різними можливими станами публікації як варіантами. Це, безумовно, можливе рішення; спробуйте його та порівняйте кінцеві результати, щоб зрозуміти, який варіант вам більше подобається! Один із недоліків використанняenumполягає в тому, що кожне місце, яке перевіряє значенняenum, потребуватиме виразуmatchабо подібного, щоб обробити кожен можливий варіант. Це може стати більш повторюваним, ніж це рішення з трейт-об’єктом.
Оцінювання шаблону стану
Ми показали, що Rust здатний реалізувати об’єктно-орієнтований шаблон стану,
щоб інкапсулювати різні види поведінки, які публікація повинна мати в кожному
стані. Методи на Post нічого не знають про різні види поведінки. Через те,
як ми організували код, нам потрібно дивитися лише в одне місце, щоб знати
різні способи поведінки опублікованої публікації: реалізацію трейту State
для структури Published.
Якби ми створили альтернативну реалізацію, яка не використовує шаблон стану,
ми могли б натомість використовувати вирази match у методах на Post або
навіть у коді main, який перевіряє стан публікації та змінює поведінку в цих
місцях. Це означало б, що нам довелося б дивитися в кілька місць, щоб зрозуміти
всі наслідки того, що публікація перебуває в стані published.
Із шаблоном стану методам Post і місцям, де ми використовуємо Post, не
потрібні вирази match, а щоб додати новий стан, нам потрібно було б лише
додати нову структуру і реалізувати методи трейту для цієї однієї структури в
одному місці.
Реалізацію з використанням шаблону стану легко розширити, щоб додати більше функціональності. Щоб побачити простоту підтримки коду, який використовує шаблон стану, спробуйте кілька з цих пропозицій:
- Додайте метод
reject, який змінює стан публікації зPendingReviewназад наDraft. - Потрібно два виклики
approveперед тим, як стан можна буде змінити наPublished. - Дозвольте користувачам додавати текстовий вміст лише тоді, коли публікація
перебуває в стані
Draft. Підказка: зробіть об’єкт стану відповідальним за те, що може змінюватися у вмісті, але не за змінуPost.
Один із недоліків шаблону стану полягає в тому, що, оскільки стани реалізують
переходи між станами, деякі стани зв’язані один з одним. Якщо ми додамо інший
стан між PendingReview і Published, наприклад Scheduled, нам довелося б
змінити код у PendingReview, щоб він переходив до Scheduled. Було б менше
роботи, якби PendingReview не потрібно було змінювати з додаванням нового
стану, але це означало б перехід до іншого шаблону проєктування.
Інший недолік полягає в тому, що ми дублювали деяку логіку. Щоб усунути частину
дублювання, ми могли б спробувати зробити реалізації за замовчуванням для
методів request_review і approve у трейді State, які повертають self.
Однак це не спрацювало б: коли State використовується як трейт-об’єкт, трейт
не знає точно, яким буде конкретний self, тож тип повернення невідомий на
момент компіляції. (Це одне з правил dyn compatibility, згаданих раніше.)
Інше дублювання включає схожі реалізації методів request_review і approve
на Post. Обидва методи використовують Option::take для поля state у
Post, і якщо state є Some, вони делегують реалізацію однойменному методу
в загорнутому значенні та встановлюють нове значення поля state у результат.
Якби в нас було багато методів на Post, які слідують цьому шаблону, ми могли б
розглянути визначення макросу, щоб усунути повторення (див. розділ
“Macros” у розділі 20).
Реалізуючи шаблон стану саме так, як він визначений для об’єктно-орієнтованих
мов, ми не використовуємо сильні сторони Rust настільки повно, наскільки могли
б. Подивімося на деякі зміни, які ми можемо внести до крейту blog, щоб
невалідні стани та переходи стали помилками часу компіляції.
Кодування станів і поведінки як типів
Ми покажемо вам, як переосмислити шаблон стану, щоб отримати інший набір компромісів. Замість того, щоб повністю інкапсулювати стани та переходи так, щоб зовнішній код не мав про них жодних знань, ми закодуємо стани в різні типи. Внаслідок цього система перевірки типів Rust запобігатиме спробам використовувати чернеткові публікації там, де дозволені лише опубліковані публікації, видаючи помилку компілятора.
Розгляньмо першу частину main у лістингу 18-11:
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Ми все ще дозволяємо створення нових публікацій у стані чернетки за допомогою
Post::new і можливість додавати текст до вмісту публікації. Але замість того,
щоб мати метод content у чернеткової публікації, який повертає порожній рядок,
ми зробимо так, щоб чернеткові публікації взагалі не мали методу content.
Таким чином, якщо ми спробуємо отримати вміст чернеткової публікації, ми
отримаємо помилку компілятора, яка повідомить, що такого методу не існує. У
результаті ми не зможемо випадково показати вміст чернеткової публікації в
продуктивному середовищі, тому що цей код навіть не збереться. У лістингу 18-19
показано визначення структури Post і структури DraftPost, а також методи
для кожної з них.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}І Post, і DraftPost мають приватне поле content, яке зберігає текст
публікації в блозі. У структур більше немає поля state, тому що ми переносимо
кодування стану до типів структур. Структура Post представлятиме опубліковану
публікацію, і вона має метод content, який повертає content.
У нас усе ще є функція Post::new, але замість того, щоб повертати екземпляр
Post, вона повертає екземпляр DraftPost. Оскільки content є приватним і
немає жодних функцій, які повертають Post, наразі неможливо створити
екземпляр Post.
Структура DraftPost має метод add_text, тож ми можемо додавати текст до
content, як і раніше, але зверніть увагу, що DraftPost не має визначеного
методу content! Отже, тепер програма гарантує, що всі публікації починаються
як чернеткові публікації, і вміст чернеткових публікацій недоступний для
відображення. Будь-яка спроба обійти ці обмеження призведе до помилки
компілятора.
То як же нам отримати опубліковану публікацію? Ми хочемо забезпечити правило,
що чернеткову публікацію потрібно переглянути й схвалити, перш ніж її можна
буде опублікувати. Публікація в стані pending review також не повинна
показувати жодного вмісту. Реалізуймо ці обмеження, додавши ще одну структуру,
PendingReviewPost, визначивши метод request_review у DraftPost, який
повертатиме PendingReviewPost, і визначивши метод approve у
PendingReviewPost, який повертатиме Post, як показано в лістингу 18-20.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}Методи request_review і approve приймають власність на self, таким чином
споживаючи екземпляри DraftPost і PendingReviewPost і перетворюючи їх,
відповідно, на PendingReviewPost і опублікований Post. Таким чином, у нас
не залишиться жодних «застарілих» екземплярів DraftPost після того, як ми
викликали на них request_review, і так далі. У структури PendingReviewPost
не визначено методу content, тож спроба прочитати її вміст призводить до
помилки компілятора, як і у випадку з DraftPost. Оскільки єдиний спосіб
отримати екземпляр опублікованого Post, який уже має визначений метод
content, — це викликати метод approve на PendingReviewPost, а єдиний
спосіб отримати PendingReviewPost — це викликати метод request_review на
DraftPost, ми тепер закодували робочий процес публікації в блозі в систему
типів.
Але нам також доведеться внести деякі невеликі зміни до main. Методи
request_review і approve повертають нові екземпляри замість того, щоб
змінювати структуру, на якій їх викликають, тож нам потрібно додати більше
присвоювань із затіненням let post =, щоб зберегти повернуті екземпляри. Ми
також більше не можемо мати перевірки, що вміст чернеткових і публікацій у
стані pending review є порожніми рядками, та й вони нам більше не потрібні:
ми більше не можемо скомпілювати код, який намагається використовувати вміст
публікацій у цих станах. Оновлений код у main показано в лістингу 18-21.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Зміни, які нам потрібно було внести до main, щоб повторно присвоїти post,
означають, що ця реалізація вже не зовсім слідує об’єктно-орієнтованому шаблону
стану: перетворення між станами більше не повністю інкапсульовані всередині
реалізації Post. Однак наша перевага полягає в тому, що невалідні стани тепер
неможливі завдяки системі типів і перевірці типів, яка відбувається під час
компіляції! Це гарантує, що певні помилки, такі як відображення вмісту
неопублікованої публікації, будуть виявлені до того, як вони потраплять у
продуктивне середовище.
Спробуйте виконати завдання, запропоновані на початку цього розділу для крейту
blog у його стані після лістингу 18-21, щоб побачити, що ви думаєте про
проєктування цієї версії коду. Зверніть увагу, що деякі з завдань можуть бути
вже виконані в цьому дизайні.
Ми побачили, що хоча Rust і здатний реалізовувати об’єктно-орієнтовані шаблони проєктування, в Rust також доступні інші шаблони, такі як кодування стану в систему типів. Ці шаблони мають різні компроміси. Хоча ви можете бути дуже знайомі з об’єктно-орієнтованими шаблонами, переосмислення проблеми з використанням особливостей Rust може дати переваги, наприклад запобігання деяким помилкам на етапі компіляції. Об’єктно-орієнтовані шаблони не завжди будуть найкращим рішенням у Rust через певні особливості, такі як власність, яких немає в об’єктно-орієнтованих мовах.
Підсумок
Незалежно від того, чи вважаєте ви Rust об’єктно-орієнтованою мовою після прочитання цього розділу, тепер ви знаєте, що можете використовувати трейт-об’єкти, щоб отримати деякі об’єктно-орієнтовані можливості в Rust. Динамічна диспетчеризація може дати вашому коду певну гнучкість в обмін на невелике зниження продуктивності під час виконання. Ви можете використати цю гнучкість для реалізації об’єктно-орієнтованих шаблонів, які можуть допомогти підтримуваності вашого коду. Rust також має інші можливості, такі як власність, яких немає в об’єктно-орієнтованих мовах. Об’єктно-орієнтований шаблон не завжди буде найкращим способом використати сильні сторони Rust, але це доступний варіант.
Далі ми розглянемо шаблони, які є ще однією з особливостей Rust, що забезпечують велику гнучкість. Ми коротко розглядали їх упродовж усієї книги, але ще не бачили їхньої повної можливості. Тож уперед!
Зіставлення зі зразком (Patterns and Matching)
Зразки — це спеціальний синтаксис у Rust для зіставлення зі структурою
типів, як складних, так і простих. Використання зразків у поєднанні з
виразами match та іншими конструкціями дає вам більше контролю над
потоком керування програми. Зразок складається з деякої комбінації наведеного далі:
- Літерали
- Розібрані масиви, переліки, структури або кортежі
- Змінні
- Підстановні знаки
- Заповнювачі
Деякі приклади зразків включають x, (a, 3) і Some(Color::Red). У
контекстах, у яких зразки є дійсними, ці компоненти описують форму
даних. Потім наша програма зіставляє значення зі зразками, щоб визначити, чи
має вона правильну форму даних, щоб продовжити виконання певного фрагмента коду.
Щоб використовувати зразок, ми порівнюємо його з деяким значенням. Якщо зразок
зіставляється зі значенням, ми використовуємо частини значення у нашому коді.
Згадайте вирази match у Розділі 6, які використовували зразки, такі як приклад
машини для сортування монет. Якщо значення відповідає формі зразка, ми можемо
використати іменовані частини. Якщо ні, код, пов’язаний із зразком, не буде
виконано.
Цей розділ — це довідка про все, що пов’язано зі зразками. Ми розглянемо місця, де можна використовувати зразки, різницю між спростовуваними та неспростовуваними зразками, а також різні види синтаксису зразків, які ви можете побачити. Наприкінці розділу ви знатимете, як використовувати зразки для вираження багатьох концепцій зрозумілим способом.
Усі місця, де можна використовувати зразки
Усі місця, де можна використовувати patterns
Patterns з’являються в низці місць у Rust, і ви використовували їх багато разів, навіть не усвідомлюючи цього! У цьому розділі обговорюються всі місця, де patterns є допустимими.
Арми match
Як обговорювалося в Chapter 6, ми використовуємо patterns в армах виразів
match. Формально, вирази match визначаються як ключове слово match,
значення для зіставлення і одна або більше match-арм, що складаються з
pattern і виразу, який потрібно виконати, якщо значення відповідає pattern цієї
арми, ось так:
match VALUE {
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
}Наприклад, ось вираз match із Listing 6-5, який зіставляє значення
Option<i32> у змінній x:
match x {
None => None,
Some(i) => Some(i + 1),
}Patterns у цьому виразі match — це None і Some(i) ліворуч від кожної
стрілки.
Однією з вимог до виразів match є те, що вони мають бути вичерпними в тому
сенсі, що всі можливості для значення у виразі match мають бути враховані.
Один зі способів переконатися, що ви охопили кожну можливість, — мати
універсальний pattern для останньої арми: наприклад, ім’я змінної, яке
збігається з будь-яким значенням, ніколи не може зазнати невдачі і таким чином
охоплює кожен решта випадок.
Конкретний pattern _ зіставлятиметься з будь-чим, але він ніколи не
прив’язується до змінної, тож його часто використовують в останній армі match.
Pattern _ може бути корисним, коли ви хочете, наприклад, ігнорувати будь-яке
значення, що не вказане. Ми детальніше розглянемо pattern _ у розділі
“Ignoring Values in a
Pattern” пізніше в цьому розділі.
Оператори let
До цього розділу ми явно обговорювали використання patterns лише з match та
if let, але насправді ми використовували patterns і в інших місцях, зокрема
в операторах let. Наприклад, розгляньте це просте присвоєння змінної за
допомогою let:
#![allow(unused)]
fn main() {
let x = 5;
}Щоразу, коли ви використовували такий оператор let, ви використовували
patterns, хоча, можливо, не усвідомлювали цього! Формальніше, оператор let
виглядає так:
let PATTERN = EXPRESSION;
В операторах на кшталт let x = 5;, де в слоті PATTERN стоїть ім’я змінної,
ім’я змінної є просто особливо простою формою pattern. Rust порівнює вираз із
pattern і присвоює всі імена, які знаходить. Отже, у прикладі let x = 5;
x — це pattern, що означає «прив’язати те, що тут відповідає, до змінної
x». Оскільки ім’я x є всім pattern, цей pattern фактично означає
«прив’язати все до змінної x, яке б значення це не було».
Щоб чіткіше побачити аспект зіставлення зі зразком у let, розгляньте Listing
19-1, який використовує pattern з let, щоб деструктурувати кортеж.
fn main() {
let (x, y, z) = (1, 2, 3);
}Тут ми зіставляємо кортеж із pattern. Rust порівнює значення (1, 2, 3) із
pattern (x, y, z) і бачить, що значення відповідає pattern — тобто бачить,
що кількість елементів у обох однакова — тож Rust прив’язує 1 до x, 2
до y, а 3 до z. Ви можете уявляти цей pattern кортежу як такий, що
вкладено містить три окремі patterns змінних.
Якщо кількість елементів у pattern не збігається з кількістю елементів у кортежі, загальний тип не збіжиться, і ми отримаємо помилку компілятора. Наприклад, Listing 19-2 показує спробу деструктурувати кортеж із трьома елементами в дві змінні, що не спрацює.
fn main() {
let (x, y) = (1, 2, 3);
}Спроба скомпілювати цей код призводить до такої помилки типу:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Щоб виправити помилку, ми могли б ігнорувати одне або більше значень у
кортежі, використовуючи _ або .., як ви побачите в розділі
“Ignoring Values in a
Pattern”. Якщо проблема полягає
в тому, що в pattern забагато змінних, розв’язанням буде зробити типи
відповідними, видаливши змінні так, щоб кількість змінних дорівнювала кількості
елементів у кортежі.
Умовні вирази if let
У Chapter 6 ми обговорювали, як використовувати вирази if let головним чином
як коротший спосіб записати еквівалент match, який зіставляє лише один
випадок. За бажанням if let може мати відповідний else, що містить код,
який слід виконати, якщо pattern у if let не збігається.
Listing 19-3 показує, що також можливо змішувати вирази if let, else if і
else if let. Це дає нам більшу гнучкість, ніж вираз match, у якому ми
можемо виразити лише одне значення для порівняння з patterns. Також Rust не
вимагає, щоб умови в серії армі if let, else if і else if let
пов’язувалися одна з одною.
Код у Listing 19-3 визначає, який колір зробити вашим тлом, на основі серії перевірок кількох умов. Для цього прикладу ми створили змінні із жорстко заданими значеннями, які реальна програма могла б отримати від введення користувача.
fn main() {
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse();
if let Some(color) = favorite_color {
println!("Using your favorite color, {color}, as the background");
} else if is_tuesday {
println!("Tuesday is green day!");
} else if let Ok(age) = age {
if age > 30 {
println!("Using purple as the background color");
} else {
println!("Using orange as the background color");
}
} else {
println!("Using blue as the background color");
}
}Якщо користувач вказує улюблений колір, цей колір використовується як фон. Якщо улюблений колір не вказано і сьогодні вівторок, колір фону — зелений. Інакше, якщо користувач вказує свій вік як рядок і ми можемо успішно розібрати його як число, колір буде або фіолетовим, або помаранчевим, залежно від значення числа. Якщо жодна з цих умов не виконується, колір фону буде синім.
Ця умовна структура дає нам змогу підтримувати складні вимоги. З тими
жорстко заданими значеннями, які ми маємо тут, цей приклад виведе Using purple as the background color.
Ви можете бачити, що if let також може вводити нові змінні, які затіняють
існуючі змінні так само, як це можуть робити арми match: рядок if let Ok(age) = age вводить нову змінну age, яка містить значення всередині варіанта Ok,
затіняючи наявну змінну age. Це означає, що нам потрібно розмістити умову
if age > 30 всередині цього блоку: ми не можемо об’єднати ці дві умови в if let Ok(age) = age && age > 30. Новий age, який ми хочемо порівняти з 30,
ще не є дійсним, доки нова область видимості не починається з фігурної дужки.
Недолік використання виразів if let полягає в тому, що компілятор не
перевіряє вичерпність, тоді як з виразами match він це робить. Якби ми
опустили останній блок else і, отже, не обробили деякі випадки, компілятор
не попередив би нас про можливу логічну помилку.
Умовні цикли while let
Подібний за побудовою до if let, умовний цикл while let дає змогу циклу
while виконуватися доти, доки pattern продовжує збігатися. У Listing 19-4 ми
показуємо цикл while let, який очікує повідомлення, надіслані між потоками,
але в цьому випадку перевіряє Result замість Option.
fn main() {
let (tx, rx) = std::sync::mpsc::channel();
std::thread::spawn(move || {
for val in [1, 2, 3] {
tx.send(val).unwrap();
}
});
while let Ok(value) = rx.recv() {
println!("{value}");
}
}Цей приклад виводить 1, 2, а потім 3. Метод recv бере перше
повідомлення зі сторони отримувача каналу і повертає Ok(value). Коли ми
вперше побачили recv ще в Chapter 16, ми розпаковували помилку напряму або
взаємодіяли з ним як з ітератором, використовуючи цикл for. Проте, як показує
Listing 19-4, ми також можемо використовувати while let, тому що метод
recv повертає Ok кожного разу, коли надходить повідомлення, доки існує
відправник, а потім породжує Err, щойно сторона відправника від’єднується.
Цикли for
У циклі for значення, яке безпосередньо слідує за ключовим словом for, є
pattern. Наприклад, у for x in y x — це pattern. Listing 19-5
демонструє, як використовувати pattern у циклі for, щоб деструктурувати, або
розібрати на частини, кортеж як частину циклу for.
fn main() {
let v = vec!['a', 'b', 'c'];
for (index, value) in v.iter().enumerate() {
println!("{value} is at index {index}");
}
}Код у Listing 19-5 виведе таке:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
Ми адаптуємо ітератор за допомогою методу enumerate, щоб він породжував
значення та індекс для цього значення, поміщені в кортеж. Перше значення,
що породжується, — це кортеж (0, 'a'). Коли це значення зіставляється з
pattern (index, value), index буде 0, а value буде 'a', що виведе
перший рядок результату.
Параметри функції
Параметри функції також можуть бути patterns. Код у Listing 19-6, який
оголошує функцію з назвою foo, що приймає один параметр з назвою x типу
i32, тепер має бути знайомим.
fn foo(x: i32) {
// code goes here
}
fn main() {}Частина x — це pattern! Як і з let, ми могли б зіставити кортеж у
аргументах функції з pattern. Listing 19-7 розбиває значення в кортежі, коли
ми передаємо його у функцію.
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({x}, {y})");
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}Цей код виводить Current location: (3, 5). Значення &(3, 5) відповідають
pattern &(x, y), тож x — це значення 3, а y — це значення 5.
Ми також можемо використовувати patterns у списках параметрів замикання так само, як і в списках параметрів функцій, оскільки замикання подібні до функцій, як обговорювалося в Chapter 13.
На цьому етапі ви побачили кілька способів використання patterns, але patterns не працюють однаково в кожному місці, де ми можемо їх використовувати. У деяких місцях patterns мають бути irrefutable; в інших обставинах вони можуть бути refutable. Далі ми обговоримо ці два поняття.
Спростовуваність (refutability): чи може зіставлення зі зразком (pattern matching) завершитися невдачею
Спростовуваність (refutability): Чи може зіставлення зі зразком не вдатися
Зразки бувають двох форм: спростовувані та неспростовувані. Зразки, які будуть
зіставлятися для будь-якого можливого переданого значення, є неспростовуваними. Прикладом був би x у
операторі let x = 5;, тому що x зіставляється з будь-чим і, отже, не може не
зіставитися. Зразки, які можуть не зіставитися для деякого можливого значення, є
спростовуваними. Прикладом був би Some(x) у виразі if let Some(x) = a_value, тому що якщо значення у змінній a_value є None, а не
Some, зразок Some(x) не зіставиться.
Параметри функцій, оператори let і цикли for можуть приймати лише
неспростовувані зразки, тому що програма не може зробити нічого змістовного, коли
значення не зіставляються. Вирази if let і while let, а також
оператор let...else приймають спростовувані та неспростовувані зразки, але
компілятор виводить попередження щодо неспростовуваних зразків, тому що, за означенням, вони
призначені для обробки можливої невдачі: функціональність умовного конструкта полягає в
його здатності поводитися по-різному залежно від успіху чи невдачі.
Загалом вам не повинно бути потрібно турбуватися про різницю між спростовуваними та неспростовуваними зразками; однак вам потрібно бути знайомими з концепцією спростовуваності, щоб ви могли відреагувати, коли побачите її в повідомленні про помилку. У таких випадках вам потрібно буде змінити або зразок, або конструкцію, з якою ви використовуєте зразок, залежно від запланованої поведінки коду.
Давайте подивимося на приклад того, що відбувається, коли ми намагаємося використати спростовуваний зразок
там, де Rust вимагає неспростовуваний зразок, і навпаки. У списку 19-8 показано
оператор let, але для зразка ми вказали Some(x), спростовуваний
зразок. Як ви могли очікувати, цей код не скомпілюється.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}Якби some_option_value було значенням None, воно не зіставилося б із зразком
Some(x), тобто зразок є спростовуваним. Однак оператор let може
приймати лише неспростовуваний зразок, тому що код не може зробити нічого дійсного зі
значенням None. Під час компіляції Rust поскаржиться, що ми спробували
використати спростовуваний зразок там, де потрібен неспростовуваний зразок:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Оскільки ми не охопили (і не могли охопити!) кожне дійсне значення
зразком Some(x), Rust справедливо видає помилку компілятора.
Якщо в нас є спростовуваний зразок там, де потрібен неспростовуваний зразок, ми можемо
виправити це, змінивши код, який використовує зразок: замість використання let, ми
можемо використати let...else. Тоді, якщо зразок не зіставляється, код у фігурних
дужках обробить значення. У списку 19-9 показано, як виправити код у
списку 19-8.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value else {
return;
};
}Ми дали коду вихід! Цей код цілком дійсний, хоча це означає, що ми
не можемо використовувати неспростовуваний зразок без отримання попередження. Якщо ми дамо
let...else зразок, який завжди буде зіставлятися, наприклад x, як показано в списку
19-10, компілятор видасть попередження.
fn main() {
let x = 5 else {
return;
};
}Rust скаржиться, що не має сенсу використовувати let...else з
неспростовуваним зразком:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `let...else` pattern
--> src/main.rs:2:5
|
2 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
З цієї причини гілки match мають використовувати спростовувані зразки, окрім останньої
гілки, яка має зіставляти будь-які решту значення за допомогою неспростовуваного зразка. Rust
дозволяє нам використовувати неспростовуваний зразок у match лише з однією гілкою, але
ця синтаксична форма не особливо корисна і може бути замінена простішим
оператором let.
Тепер, коли ви знаєте, де використовувати зразки та в чому різниця між спростовуваними та неспростовуваними зразками, давайте розглянемо весь синтаксис, який ми можемо використовувати для створення зразків.
Синтаксис зразків
Синтаксис зразків
У цьому розділі ми зібраємо весь синтаксис, який є дійсним у зразках, і обговоримо чому та коли ви можете захотіти використовувати кожен із них.
Зіставлення літералів
Як ви бачили в розділі 6, ви можете зіставляти зразки з літералами безпосередньо. Наступний код наводить кілька прикладів:
fn main() {
let x = 1;
match x {
1 => println!("one"),
2 => println!("two"),
3 => println!("three"),
_ => println!("anything"),
}
}Цей код друкує one, тому що значення в x — це 1. Цей синтаксис корисний
коли ви хочете, щоб ваш код виконав дію, якщо він отримує певне конкретне
значення.
Зіставлення іменованих змінних
Іменовані змінні — це неспростовувані зразки, які зіставляються з будь-яким значенням, і ми використовували
їх багато разів у цій книзі. Однак є ускладнення, коли ви використовуєте
іменовані змінні в виразах match, if let або while let. Оскільки кожен
із цих видів виразів починає нову область видимості, змінні, оголошені як частина
зразка всередині цих виразів, затінюватимуть ті, що мають те саме ім’я зовні
конструкцій, як і у випадку з усіма змінними. У Лістингу 19-11 ми оголошуємо
змінну на ім’я x зі значенням Some(5) і змінну y зі значенням
10. Потім ми створюємо вираз match над значенням x. Подивіться на
зразки в гілках match і println! у кінці та спробуйте з’ясувати,
що друкуватиме код, перш ніж запускати цей код або читати далі.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(y) => println!("Matched, y = {y}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}Давайте розглянемо, що відбувається, коли вираз match виконується. Зразок
у першій гілці match не зіставляється з визначеним значенням x, тож код
продовжується.
Зразок у другій гілці match вводить нову змінну на ім’я y, яка
зіставлятиметься з будь-яким значенням всередині значення Some. Оскільки ми перебуваємо в новій області видимості всередині
виразу match, це нова змінна y, а не y, яку ми оголосили на
початку зі значенням 10. Це нове зв’язування y зіставлятиметься з будь-яким значенням
усередині Some, а саме це ми й маємо в x. Отже,
це нове y прив’язується до внутрішнього значення Some у x.
Це значення — 5, тож виконується вираз для цієї гілки і друкує Matched, y = 5.
Якби x був значенням None замість Some(5), зразки в перших
двох гілках не зіставилися б, тож значення зіставилося б із
підкресленням. Ми не вводили змінну x у зразку
гілки з підкресленням, тож x у виразі все ще є зовнішнім x, який не було
затіненено. У цьому гіпотетичному випадку match друкував би Default case, x = None.
Коли вираз match завершується, завершується і його область видимості, а разом із нею і область видимості
внутрішнього y. Останній println! виводить at the end: x = Some(5), y = 10.
Щоб створити вираз match, який порівнює значення зовнішніх x і
y, а не вводить нову змінну, що затінює наявну змінну y,
нам натомість потрібно було б використати умовний match guard. Про match guards ми поговоримо пізніше в розділі “Додавання умов із Match
Guards”.
Зіставлення кількох зразків
У виразах match ви можете зіставляти кілька зразків, використовуючи синтаксис |,
який є оператором або для зразків. Наприклад, у наведеному нижче коді ми
зіставляємо значення x із гілками match, перша з яких має опцію або,
що означає: якщо значення x збігається з будь-яким із значень у цій гілці,
виконається код цієї гілки:
fn main() {
let x = 1;
match x {
1 | 2 => println!("one or two"),
3 => println!("three"),
_ => println!("anything"),
}
}Цей код друкує one or two.
Зіставлення діапазонів значень за допомогою ..=
Синтаксис ..= дозволяє нам зіставляти включний діапазон значень. У
наступному коді, коли зразок зіставляється з будь-яким із значень у заданому
діапазоні, ця гілка виконається:
fn main() {
let x = 5;
match x {
1..=5 => println!("one through five"),
_ => println!("something else"),
}
}Якщо x дорівнює 1, 2, 3, 4 або 5, перша гілка зіставиться. Цей синтаксис
зручніший для кількох значень у match, ніж використання оператора |
для вираження тієї самої ідеї; якби ми використали |, нам довелося б вказати 1 | 2 | 3 | 4 | 5. Вказувати діапазон набагато коротше, особливо якщо ми хочемо зіставити,
скажімо, будь-яке число між 1 і 1,000!
Компілятор перевіряє, що діапазон не є порожнім, під час компіляції, і оскільки
єдиними типами, для яких Rust може визначити, чи є діапазон порожнім, є char і
числові значення, діапазони дозволені лише для числових значень або char.
Ось приклад використання діапазонів значень char:
fn main() {
let x = 'c';
match x {
'a'..='j' => println!("early ASCII letter"),
'k'..='z' => println!("late ASCII letter"),
_ => println!("something else"),
}
}Rust може визначити, що 'c' входить до діапазону першого зразка, і друкує early ASCII letter.
Розбиття значень на частини за допомогою деструктуризації
Ми також можемо використовувати зразки для деструктуризації структур, переліків і кортежів, щоб використовувати різні частини цих значень. Давайте розглянемо кожне значення.
Структури
Лістинг 19-12 показує структуру Point із двома полями, x і y, які ми можемо
розбити на частини за допомогою зразка з оператором let.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
}Цей код створює змінні a і b, які зіставляються зі значеннями полів x
і y структури p. Цей приклад показує, що імена
змінних у зразку не обов’язково мають збігатися з іменами полів структури.
Однак зазвичай змінні в зразку називають так само, як поля, щоб було
легше пам’ятати, які змінні походять із яких полів. Через це
поширене використання, а також тому, що запис let Point { x: x, y: y } = p;
містить багато повторень, Rust має скорочений запис для зразків, які зіставляються з полями структури:
вам потрібно лише перелічити назву поля структури, а змінні, створені
із зразка, матимуть ті самі імена. Лістинг 19-13 поводиться так само,
як код у Лістингу 19-12, але змінні, створені в зразку let,
— це x і y замість a і b.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x, y } = p;
assert_eq!(0, x);
assert_eq!(7, y);
}Цей код створює змінні x і y, які зіставляються з полями x і y
змінної p. Результатом є те, що змінні x і y містять
значення зі структури p.
Ми також можемо виконувати деструктуризацію з літеральними значеннями як частину зразка структури замість створення змінних для всіх полів. Це дає змогу нам перевіряти деякі поля на певні значення, створюючи змінні для деструктуризації інших полів.
У Лістингу 19-14 у нас є вираз match, який розділяє значення Point
на три випадки: точки, що лежать безпосередньо на осі x (що є правдою, коли
y = 0), на осі y (x = 0) або не на жодній осі.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
match p {
Point { x, y: 0 } => println!("On the x axis at {x}"),
Point { x: 0, y } => println!("On the y axis at {y}"),
Point { x, y } => {
println!("On neither axis: ({x}, {y})");
}
}
}Перша гілка зіставиться з будь-якою точкою, що лежить на осі x, якщо вказати, що
поле y зіставляється тоді, коли його значення збігається з літералом 0. Зразок
все ще створює змінну x, яку ми можемо використовувати в коді цієї гілки.
Подібним чином, друга гілка зіставляє будь-яку точку на осі y, вказуючи, що
поле x зіставляється, якщо його значення дорівнює 0, і створює змінну y для
значення поля y. Третя гілка не вказує жодних літералів, тож вона
зіставляє будь-який інший Point і створює змінні для обох полів x і y.
У цьому прикладі значення p зіставляється з другою гілкою завдяки тому, що
x містить 0, тож цей код друкуватиме On the y axis at 7.
Пам’ятайте, що вираз match припиняє перевірку гілок, щойно знаходить
перший зразок, що зіставляється, тож навіть якщо Point { x: 0, y: 0 } лежить на осі
x і на осі y, цей код надрукував би лише On the x axis at 0.
Переліки
Ми виконували деструктуризацію переліків у цій книзі (наприклад, Лістинг 6-5 у розділі 6),
але ще не обговорювали явно, що зразок для деструктуризації переліку
відповідає способу визначення даних, які зберігаються всередині переліку. Як
приклад, у Лістингу 19-15 ми використовуємо перелік Message із Лістингу 6-2 і пишемо
match зі зразками, які деструктуризують кожне внутрішнє значення.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 160, 255);
match msg {
Message::Quit => {
println!("The Quit variant has no data to destructure.");
}
Message::Move { x, y } => {
println!("Move in the x direction {x} and in the y direction {y}");
}
Message::Write(text) => {
println!("Text message: {text}");
}
Message::ChangeColor(r, g, b) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
}
}Цей код надрукує Change color to red 0, green 160, and blue 255. Спробуйте
змінити значення msg, щоб побачити, як виконуються коди з інших гілок.
Для варіантів переліку без будь-яких даних, як-от Message::Quit, ми не можемо виконати
деструктуризацію значення далі. Ми можемо лише зіставити літеральне значення Message::Quit,
і в цьому зразку немає жодних змінних.
Для подібних до структури варіантів переліку, таких як Message::Move, ми можемо використати зразок,
подібний до того, який ми вказуємо для зіставлення структур. Після назви варіанта ми
ставимо фігурні дужки, а потім перелічуємо поля зі змінними, щоб розібрати
частини для використання в коді цієї гілки. Тут ми використовуємо
скорочену форму, як і в Лістингу 19-13.
Для подібних до кортежу варіантів переліку, як-от Message::Write, що містить кортеж із
одним елементом, і Message::ChangeColor, що містить кортеж із трьома елементами,
зразок подібний до зразка, який ми вказуємо для зіставлення кортежів. Кількість
змінних у зразку має відповідати кількості елементів у варіанті, який ми
зіставляємо.
Вкладені структури й переліки
Досі всі наші приклади зіставляли структури або переліки на один рівень
глибини, але зіставлення може працювати і з вкладеними елементами! Наприклад, ми можемо
переробити код у Лістингу 19-15, щоб підтримувати кольори RGB і HSV у повідомленні
ChangeColor, як показано в Лістингу 19-16.
enum Color {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(Color),
}
fn main() {
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));
match msg {
Message::ChangeColor(Color::Rgb(r, g, b)) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
Message::ChangeColor(Color::Hsv(h, s, v)) => {
println!("Change color to hue {h}, saturation {s}, value {v}");
}
_ => (),
}
}Зразок першої гілки у виразі match зіставляє варіант переліку
Message::ChangeColor, який містить варіант Color::Rgb; потім
зразок прив’язується до трьох внутрішніх значень i32. Зразок другої
гілки також зіставляє варіант переліку Message::ChangeColor, але внутрішній перелік
зіставляється з Color::Hsv замість нього. Ми можемо вказати ці складні умови в одному
виразі match, навіть якщо задіяно два переліки.
Структури та кортежі
Ми можемо змішувати, поєднувати й вкладати зразки деструктуризації ще складнішими способами. Наведений нижче приклад показує складну деструктуризацію, де ми вкладаємо структури й кортежі всередину кортежу та деструктуризуємо всі примітивні значення назовні:
fn main() {
struct Point {
x: i32,
y: i32,
}
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
}Цей код дає нам змогу розбивати складні типи на їхні складові частини, щоб ми могли окремо використовувати значення, які нас цікавлять.
Деструктуризація за допомогою зразків — це зручний спосіб використовувати частини значень, таких як значення з кожного поля в структурі, окремо одне від одного.
Ігнорування значень у зразку
Ви бачили, що іноді корисно ігнорувати значення в зразку, наприклад,
в останній гілці match, щоб отримати гілку для всіх інших випадків, яка фактично нічого
не робить, але охоплює всі інші можливі значення. Є кілька
способів ігнорувати цілі значення або частини значень у зразку: використовуючи
зразок _ (який ви вже бачили), використовуючи зразок _ всередині іншого зразка,
використовуючи ім’я, що починається з підкреслення, або використовуючи .., щоб ігнорувати решту
частин значення. Давайте розглянемо, як і чому використовувати кожен із цих зразків.
Усе значення з _
Ми використовували підкреслення як універсальний зразок, який зіставляється з будь-яким значенням, але не
прив’язується до значення. Це особливо корисно як остання гілка у виразі match,
але ми також можемо використовувати його в будь-якому зразку, включно з параметрами функції, як показано в Лістингу 19-17.
fn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {y}");
}
fn main() {
foo(3, 4);
}Цей код повністю ігнорує значення 3, передане як перший аргумент,
і надрукує This code only uses the y parameter: 4.
У більшості випадків, коли вам більше не потрібен певний параметр функції, ви змінили б сигнатуру так, щоб вона не включала невикористаний параметр. Ігнорування параметра функції може бути особливо корисним у випадках, коли, наприклад, ви реалізуєте трейт, коли вам потрібен певний тип сигнатури, але тіло функції у вашій реалізації не потребує одного з параметрів. Тоді ви уникаєте попередження компілятора про невикористані параметри функції, яке ви б отримали, якби використали ім’я замість цього.
Частини значення з вкладеним _
Ми також можемо використовувати _ всередині іншого зразка, щоб ігнорувати лише частину значення,
наприклад, коли ми хочемо перевірити лише частину значення, але не маємо
використання для інших частин у відповідному коді, який хочемо запустити. Лістинг 19-18 показує код,
що відповідає за керування значенням параметра. Вимоги бізнесу такі:
користувач не повинен мати змоги перезаписати наявне налаштування
значення параметра, але може скасувати налаштування і надати йому значення, якщо воно наразі не задане.
fn main() {
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {setting_value:?}");
}Цей код надрукує Can't overwrite an existing customized value, а потім
setting is Some(5). У першій гілці match нам не потрібно зіставляти або використовувати
значення всередині будь-якого варіанта Some, але нам потрібно перевірити випадок,
коли setting_value і new_setting_value є варіантом Some. У цьому
випадку ми друкуємо причину, чому не змінюємо setting_value, і він не
змінюється.
У всіх інших випадках (якщо або setting_value, або new_setting_value є None)
, виражених зразком _ у другій гілці, ми хочемо дозволити
new_setting_value стати setting_value.
Ми також можемо використовувати підкреслення в кількох місцях усередині одного зразка, щоб ігнорувати певні значення. Лістинг 19-19 показує приклад ігнорування другого і четвертого значень у кортежі з п’яти елементів.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, _, third, _, fifth) => {
println!("Some numbers: {first}, {third}, {fifth}");
}
}
}Цей код надрукує Some numbers: 2, 8, 32, а значення 4 і 16
будуть ігноровані.
Невикористана змінна, ім’я якої починається з _
Якщо ви створюєте змінну, але ніде її не використовуєте, Rust зазвичай видає попередження, тому що невикористана змінна може бути помилкою. Однак іноді корисно мати змогу створити змінну, яку ви поки що не використовуватимете, наприклад, коли ви створюєте прототип або лише починаєте проєкт. У цій ситуації ви можете сказати Rust не попереджати вас про невикористану змінну, почавши ім’я змінної з підкреслення. У Лістингу 19-20 ми створюємо дві невикористані змінні, але коли ми компілюємо цей код, маємо отримати попередження лише щодо однієї з них.
fn main() {
let _x = 5;
let y = 10;
}Тут ми отримуємо попередження про те, що не використовуємо змінну y, але не отримуємо
попередження про те, що не використовуємо _x.
Зверніть увагу, що є тонка відмінність між використанням лише _ і використанням імені,
що починається з підкреслення. Синтаксис _x усе ще прив’язує значення до
змінної, тоді як _ взагалі не прив’язує. Щоб показати випадок, де ця
відмінність має значення, Лістинг 19-21 надасть нам помилку.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{s:?}");
}Ми отримаємо помилку, тому що значення s усе ще буде переміщено в _s,
що заважає нам знову використати s. Однак використання самого підкреслення
ніколи не прив’язує до значення. Лістинг 19-22 скомпілюється без жодних помилок,
тому що s не переміщується в _.
fn main() {
// ANCHOR: here
let s = Some(String::from("Hello!"));
if let Some(_) = s {
println!("found a string");
}
println!("{s:?}");
// ANCHOR_END: here
}Цей код працює цілком нормально, тому що ми ніколи ні до чого не прив’язуємо s; він не переміщується.
Решта частин значення з ..
Для значень, що мають багато частин, ми можемо використати синтаксис .., щоб використовувати певні
частини й ігнорувати решту, уникаючи потреби перелічувати підкреслення для кожного
ігнорованого значення. Зразок .. ігнорує будь-які частини значення, які ми не
зіставили явно в решті зразка. У Лістингу 19-23 у нас є
структура Point, що містить координату в тривимірному просторі. У
виразі match ми хочемо працювати лише з координатою x і ігнорувати
значення в полях y та z.
fn main() {
struct Point {
x: i32,
y: i32,
z: i32,
}
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
Point { x, .. } => println!("x is {x}"),
}
}Ми перелічуємо значення x, а потім просто додаємо зразок ... Це швидше,
ніж перелічувати y: _ і z: _, особливо коли ми працюємо зі
структурами, що мають багато полів, у ситуаціях, коли релевантними є лише одне або два поля.
Синтаксис .. розгорнеться до такої кількості значень, скільки потрібно. Лістинг 19-24
показує, як використовувати .. з кортежем.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, .., last) => {
println!("Some numbers: {first}, {last}");
}
}
}У цьому коді перше і останнє значення зіставляються з first і last.
.. зіставлятиме і ігноруватиме все посередині.
Однак використання .. має бути однозначним. Якщо незрозуміло, які значення
призначені для зіставлення, а які слід ігнорувати, Rust видасть нам помилку.
Лістинг 19-25 показує приклад неоднозначного використання .., тож він не
скомпілюється.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {second}")
},
}
}Коли ми компілюємо цей приклад, отримуємо таку помилку:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Rust неможливо визначити, скільки значень у кортежі слід ігнорувати
перед зіставленням значення з second, а потім скільки наступних значень
слід ігнорувати після цього. Цей код може означати, що ми хочемо ігнорувати 2, прив’язати
second до 4, а потім ігнорувати 8, 16 і 32; або що ми хочемо ігнорувати
2 і 4, прив’язати second до 8, а потім ігнорувати 16 і 32; і так далі.
Ім’я змінної second нічого особливого для Rust не означає, тож ми отримуємо
помилку компілятора, тому що використання .. у двох місцях таке неоднозначне.
Додавання умов із Match Guards
_ Match guard_ — це додаткова умова if, зазначена після зразка в
гілці match, яка також має збігтися, щоб цю гілку було вибрано. Match guards
корисні для вираження складніших ідей, ніж дозволяє один лише зразок. Зауважте,
однак, що вони доступні лише у виразах match, а не if let або
while let.
Умова може використовувати змінні, створені в зразку. Лістинг 19-26 показує
match, де перша гілка має зразок Some(x) і також має match
guard if x % 2 == 0 (який буде true, якщо число парне).
fn main() {
let num = Some(4);
match num {
Some(x) if x % 2 == 0 => println!("The number {x} is even"),
Some(x) => println!("The number {x} is odd"),
None => (),
}
}Цей приклад надрукує The number 4 is even. Коли num порівнюється із
зразком у першій гілці, він зіставляється, тому що Some(4) зіставляється з Some(x). Потім
match guard перевіряє, чи дорівнює остача від ділення x на 2
0, і оскільки це так, вибирається перша гілка.
Якби num був Some(5) замість цього, match guard у першій гілці
був би false, тому що остача від ділення 5 на 2 дорівнює 1, а це не
дорівнює 0. Тоді Rust перейшов би до другої гілки, яка б зіставилася, тому що
друга гілка не має match guard і тому зіставляється з будь-яким варіантом Some.
Немає способу виразити умову if x % 2 == 0 всередині зразка, тож
match guard дає нам можливість виразити цю логіку. Недолік
цієї додаткової виразності в тому, що компілятор не намагається перевіряти
повноту, коли залучені вирази match guard.
Коли ми обговорювали Лістинг 19-11, ми згадали, що могли б використати match guards, щоб
розв’язати нашу проблему затінення в зразках. Згадайте, що ми створили нову змінну
всередині зразка у виразі match замість використання змінної
зовні match. Ця нова змінна означала, що ми не могли перевірити значення
зовнішньої змінної. Лістинг 19-27 показує, як ми можемо використати match guard, щоб виправити
цю проблему.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(n) if n == y => println!("Matched, n = {n}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}Тепер цей код друкуватиме Default case, x = Some(5). Зразок у другій
гілці match не вводить нову змінну y, яка б затінювала зовнішню y,
а це означає, що ми можемо використовувати зовнішню y у match guard. Замість того щоб
вказувати зразок як Some(y), що затінювало б зовнішню y, ми вказуємо
Some(n). Це створює нову змінну n, яка нічого не затінює, тому що
змінної n зовні match не існує.
Match guard if n == y не є зразком і тому не вводить нових
змінних. Це y — це саме зовнішня y, а не нова y, що її затінює, і
ми можемо шукати значення, яке має таке саме значення, як зовнішня y, порівнюючи
n з y.
Ви також можете використовувати оператор або | у match guard, щоб вказати кілька
зразків; умова match guard застосовуватиметься до всіх зразків. Лістинг
19-28 показує пріоритет при поєднанні зразка, який використовує |, із match
guard. Важлива частина цього прикладу полягає в тому, що match guard if y
застосовується до 4, 5 і 6, навіть попри те, що може здатися, ніби if y
застосовується лише до 6.
fn main() {
let x = 4;
let y = false;
match x {
4 | 5 | 6 if y => println!("yes"),
_ => println!("no"),
}
}Умова match стверджує, що гілка зіставляється лише якщо значення x
дорівнює 4, 5 або 6 і якщо y є true. Коли цей код виконується,
зразок першої гілки зіставляється, тому що x дорівнює 4, але match guard if y
є false, тож перша гілка не вибирається. Код переходить до другої
гілки, яка справді зіставляється, і ця програма друкує no. Причина в тому, що
умова if застосовується до всього зразка 4 | 5 | 6, а не лише до останнього
значення 6. Інакше кажучи, пріоритет match guard щодо
зразка поводиться так:
(4 | 5 | 6) if y => ...
а не так:
4 | 5 | (6 if y) => ...
Після запуску коду поведінка пріоритету стає очевидною: якби match guard
застосовувався лише до фінального значення в списку значень, зазначених за допомогою
оператора |, гілка б зіставилася, і програма надрукувала б
yes.
Використання зв’язувань @
Оператор at @ дає нам змогу створити змінну, яка зберігає значення, одночасно
перевіряючи це значення на відповідність зразку. У Лістингу 19-29 ми хочемо
перевірити, що поле id Message::Hello входить до діапазону 3..=7. Ми також
хочемо прив’язати значення до змінної id, щоб ми могли використовувати його в коді,
пов’язаному з цією гілкою.
fn main() {
enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello { id: id @ 3..=7 } => {
println!("Found an id in range: {id}")
}
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
}
Message::Hello { id } => println!("Found some other id: {id}"),
}
}Цей приклад надрукує Found an id in range: 5. Якщо вказати id @
перед діапазоном 3..=7, ми захоплюємо будь-яке значення, що зіставилося з діапазоном, у
змінну на ім’я id, одночасно перевіряючи, що значення зіставляється із зразком діапазону.
У другій гілці, де в зразку вказано лише діапазон, код,
пов’язаний із цією гілкою, не має змінної, що містить фактичне значення
поля id. Значення поля id могло бути 10, 11 або 12, але
код, що відповідає цьому зразку, не знає, яке саме. Код зразка
не може використовувати значення з поля id, тому що ми не зберегли
значення id у змінній.
В останній гілці, де ми вказали змінну без діапазону, у нас є
значення, доступне для використання в коді гілки у змінній на ім’я id. Причина
в тому, що ми використали скорочений синтаксис полів структури. Але ми не
застосували жодної перевірки до значення в полі id у цій гілці, як це зробили в
першій двох гілках: будь-яке значення зіставилося б із цим зразком.
Використання @ дає змогу нам перевірити значення і зберегти його в змінній в межах одного зразка.
Підсумок
Зразки Rust дуже корисні для розрізнення різних видів
даних. Коли вони використовуються у виразах match, Rust гарантує, що ваші зразки охоплюють
кожне можливе значення, інакше ваша програма не скомпілюється. Зразки в
операторах let і параметрах функцій роблять ці конструкції кориснішими, даючи змогу
деструктуризацію значень на менші частини й призначення цих частин
змінним. Ми можемо створювати прості або складні зразки відповідно до наших потреб.
Далі, у передостанньому розділі книги, ми розглянемо деякі розширені аспекти різноманітних можливостей Rust.
Розширені можливості
Тепер ви вже вивчили найуживаніші частини мови програмування Rust. Перш ніж ми зробимо ще один проєкт у розділі 21, ми розглянемо кілька аспектів мови, з якими ви можете час від часу стикатися, але не використовувати щодня. Ви можете використовувати цей розділ як довідник, коли натрапите на щось невідоме. Розглянуті тут можливості корисні в дуже специфічних ситуаціях. Хоча ви, можливо, не звертатиметесь до них часто, ми хочемо переконатися, що ви маєте уявлення про всі можливості, які пропонує Rust.
У цьому розділі ми розглянемо:
- Unsafe Rust: Як відмовитися від деяких гарантій Rust і взяти на себе відповідальність за їхнє ручне дотримання
- Розширені трейт (traits): асоційовані типи, типові параметри за замовчуванням, повний кваліфікований синтаксис, супертрейти та патерн newtype у зв’язку з трейтами
- Розширені типи: Більше про патерн newtype, псевдоніми типів, ніколи тип та динамічно розмірні типи
- Розширені функції та замикання: Вказівники на функції та повернення замикань
- Макроси: Способи визначати код, який визначає більше коду під час компіляції
Це паноплія можливостей Rust, у якій знайдеться дещо для кожного! Давайте зануримося!
Unsafe Rust
Небезпечний (unsafe) Rust
Увесь код, про який ми досі говорили, мав гарантії безпеки пам’яті Rust, що забезпечувалися під час компіляції. Однак у Rust є друга мова, прихована всередині нього, яка не забезпечує цих гарантій безпеки пам’яті: вона називається unsafe Rust і працює так само, як звичайний Rust, але дає нам додаткові суперздібності.
Unsafe Rust існує тому, що за своєю природою статичний аналіз є консервативним. Коли компілятор намагається визначити, чи дотримується код гарантій, для нього краще відхилити деякі коректні програми, ніж прийняти деякі некоректні програми. Хоча код може бути правильним, якщо компілятор Rust не має достатньо інформації, щоб бути впевненим, він відхилить код. У таких випадках ви можете використати небезпечний код, щоб сказати компілятору: «Повір мені, я знаю, що роблю». Але майте на увазі, що ви використовуєте unsafe Rust на власний ризик: якщо ви використовуєте небезпечний код неправильно, можуть виникнути проблеми через небезпеку пам’яті, такі як розіменування нульового вказівника.
Ще одна причина, чому Rust має небезпечне альтер его, полягає в тому, що апаратне забезпечення комп’ютера, на якому він працює, за своєю суттю є небезпечним. Якби Rust не дозволяв вам виконувати небезпечні операції, ви не змогли б робити певні завдання. Rust має дозволяти вам виконувати низькорівневе системне програмування, наприклад безпосередньо взаємодіяти з операційною системою або навіть писати власну операційну систему. Робота з низькорівневим системним програмуванням — одна з цілей мови. Давайте дослідимо, що ми можемо робити з unsafe Rust і як це робити.
Виконання небезпечних суперздібностей
Щоб перейти до unsafe Rust, використайте ключове слово unsafe, а потім
почніть новий блок, який містить небезпечний код. У unsafe Rust ви можете
виконати п’ять дій, яких не можна виконати в безпечному Rust, і які ми
називаємо unsafe superpowers. Ці суперздібності включають можливість:
- Розіменувати raw pointer.
- Викликати небезпечну функцію або метод.
- Отримувати доступ до змінної static mutable або змінювати її.
- Реалізувати unsafe trait.
- Отримувати доступ до полів
unions.
Важливо розуміти, що unsafe не вимикає перевірник запозичень і не вимикає
жодну з інших перевірок безпеки Rust: якщо ви використовуєте посилання в
небезпечному коді, воно все одно буде перевірятися. Ключове слово unsafe
лише дає вам доступ до цих п’яти можливостей, які потім не перевіряються
компілятором на безпеку пам’яті. Усередині unsafe block ви все одно отримаєте
певний рівень безпеки.
Крім того, unsafe не означає, що код усередині блоку обов’язково є
небезпечним або що він точно матиме проблеми з безпекою пам’яті: задум у тому,
що ви, як програміст, забезпечите, щоб код усередині unsafe block отримував
доступ до пам’яті коректним способом.
Люди помиляються, і помилки траплятимуться, але завдяки вимозі, щоб ці п’ять
небезпечних операцій були всередині блоків, позначених unsafe, ви знатимете,
що будь-які помилки, пов’язані з безпекою пам’яті, мають бути всередині
unsafe block. Тримайте unsafe blocks маленькими; ви будете вдячні собі
пізніше, коли досліджуватимете помилки пам’яті.
Щоб максимально ізолювати небезпечний код, найкраще поміщати такий код у
безпечну абстракцію та надавати безпечний API, про що ми поговоримо пізніше в
розділі, коли розглядатимемо небезпечні функції та методи. Частини standard
library реалізовані як безпечні абстракції над небезпечним кодом, який було
аудитовано. Обгортання небезпечного коду в безпечну абстракцію запобігає
«витіканню» використання unsafe у всі ті місця, де ви або ваші користувачі
можуть захотіти використовувати функціональність, реалізовану за допомогою
unsafe code, тому що використання безпечної абстракції є безпечним.
Давайте по черзі розглянемо кожну з п’яти unsafe superpowers. Також подивімося на деякі абстракції, які надають безпечний інтерфейс до небезпечного коду.
Розіменування raw pointer
У главі 4, у розділі “Dangling References”, ми згадували, що компілятор гарантує, що посилання завжди є дійсними.
Unsafe Rust має два нові типи, які називаються raw pointers, що схожі на
посилання. Як і посилання, raw pointers можуть бути незмінними або змінними й
записуються як *const T і *mut T, відповідно. Зірочка — це не оператор
розіменування; вона є частиною назви типу. У контексті raw pointers
незмінний означає, що до вказівника не можна безпосередньо присвоїти значення
після його розіменування.
На відміну від посилань і smart pointers, raw pointers:
- Можуть ігнорувати правила запозичення, маючи як незмінні, так і змінні вказівники або кілька змінних вказівників на те саме місце
- Не гарантується, що вказують на дійсну пам’ять
- Можуть бути null
- Не реалізують жодного автоматичного очищення
Відмовляючись від того, щоб Rust забезпечував ці гарантії, ви можете відмовитися від гарантованої безпеки в обмін на вищу продуктивність або можливість взаємодіяти з іншою мовою чи апаратним забезпеченням, де гарантії Rust не застосовуються.
Listing 20-1 показує, як створити незмінний і змінний raw pointer.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
}Зверніть увагу, що ми не включаємо ключове слово unsafe у цей код. Ми можемо
створювати raw pointers у безпечному коді; ми просто не можемо розіменовувати
raw pointers поза unsafe block, як ви побачите за мить.
Ми створили raw pointers, використавши raw borrow operators: &raw const num
створює *const i32 незмінний raw pointer, а &raw mut num створює *mut i32 змінний raw pointer. Оскільки ми створили їх безпосередньо з локальної
змінної, ми знаємо, що ці конкретні raw pointers є дійсними, але ми не можемо
робити таке припущення про будь-який raw pointer.
Щоб це продемонструвати, далі ми створимо raw pointer, щодо дійсності якого не
можна бути настільки впевненими, використавши ключове слово as, щоб
привести значення, замість використання raw borrow operator. Listing 20-2
показує, як створити raw pointer до довільного місця в пам’яті. Спроба
використовувати довільну пам’ять є невизначеною: там можуть бути дані за цією
адресою, а можуть і не бути, компілятор може оптимізувати код так, що доступу
до пам’яті не буде, або програма може завершитися з segmentation fault. Зазвичай
немає вагомої причини писати такий код, особливо в тих випадках, коли замість
цього можна використати raw borrow operator, але це можливо.
fn main() {
let address = 0x012345usize;
let r = address as *const i32;
}Пригадайте, що ми можемо створювати raw pointers у безпечному коді, але не
можемо розіменовувати raw pointers і читати дані, на які вони вказують. У
Listing 20-3 ми використовуємо оператор розіменування * для raw pointer, що
вимагає unsafe block.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}
}Створення вказівника не завдає шкоди; проблеми виникають лише тоді, коли ми намагаємося отримати доступ до значення, на яке він вказує, і тоді можемо зіткнутися з недійсним значенням.
Також зауважте, що в Listings 20-1 і 20-3 ми створили raw pointers *const i32
і *mut i32, які обидва вказували на те саме місце в пам’яті, де зберігається
num. Якщо б ми замість цього спробували створити незмінне і змінне посилання
на num, код не скомпілювався б, тому що правила власності Rust не дозволяють
змінне посилання одночасно з будь-якими незмінними посиланнями. З raw pointers
ми можемо створити змінний вказівник і незмінний вказівник на те саме місце та
змінювати дані через змінний вказівник, потенційно створюючи стан гонки даних.
Будьте обережні!
За наявності всіх цих небезпек, навіщо взагалі використовувати raw pointers? Один із основних випадків використання — це взаємодія з кодом C, як ви побачите в наступному розділі. Інший випадок — побудова безпечних абстракцій, яких не розуміє перевірник запозичень. Ми представимо небезпечні функції, а потім розглянемо приклад безпечної абстракції, яка використовує небезпечний код.
Виклик небезпечної функції або методу
Другий тип операції, яку ви можете виконати в unsafe block, — це виклик
небезпечних функцій. Небезпечні функції та методи виглядають точно так само, як
звичайні функції та методи, але перед рештою визначення мають додаткове
unsafe. Ключове слово unsafe в цьому контексті вказує на те, що функція має
вимоги, яких ми повинні дотриматися під час її виклику, тому що Rust не може
гарантувати, що ми виконали ці вимоги. Викликаючи небезпечну функцію всередині
unsafe block, ми говоримо, що прочитали документацію цієї функції й беремо на
себе відповідальність за дотримання контрактів функції.
Ось небезпечна функція на ім’я dangerous, яка нічого не робить у своєму
тілі:
fn main() {
unsafe fn dangerous() {}
unsafe {
dangerous();
}
}Ми повинні викликати функцію dangerous всередині окремого unsafe block.
Якщо ми спробуємо викликати dangerous без unsafe block, отримаємо помилку:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
З unsafe block ми стверджуємо перед Rust, що прочитали документацію функції,
розуміємо, як правильно її використовувати, і перевірили, що виконуємо
контракт функції.
Щоб виконувати небезпечні операції в тілі unsafe function, вам усе одно
потрібно використовувати unsafe block, так само як і в звичайній функції, і
компілятор попередить вас, якщо ви забудете. Це допомагає нам тримати
unsafe blocks якомога меншими, оскільки небезпечні операції можуть бути не
потрібні в усьому тілі функції.
Створення безпечної абстракції над небезпечним кодом
Лише тому, що функція містить небезпечний код, не означає, що нам потрібно
позначати всю функцію як unsafe. Насправді обгортання небезпечного коду в
безпечну функцію — це поширена абстракція. Як приклад, давайте вивчимо функцію
split_at_mut зі standard library, яка потребує деякого небезпечного коду. Ми
дослідимо, як могли б її реалізувати. Цей безпечний метод визначено для
mutable slices: він бере один slice і робить із нього два, розділяючи slice за
індексом, переданим як аргумент. Listing 20-4 показує, як використовувати
split_at_mut.
fn main() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
assert_eq!(a, &mut [1, 2, 3]);
assert_eq!(b, &mut [4, 5, 6]);
}Ми не можемо реалізувати цю функцію, використовуючи лише безпечний Rust.
Спроба може виглядати приблизно як у Listing 20-5, який не скомпілюється. Для
простоти ми реалізуємо split_at_mut як функцію, а не метод, і лише для
слайсів значень i32, а не для узагальненого типу T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}Ця функція спочатку отримує загальну довжину slice. Потім вона стверджує, що індекс, переданий як параметр, знаходиться в межах slice, перевіряючи, чи він менший або дорівнює довжині. Це твердження означає, що якщо ми передамо індекс, який більший за довжину, щоб розділити slice в цій точці, функція панікує, перш ніж спробує використати цей індекс.
Потім ми повертаємо два mutable slices у кортежі: один від початку
початкового slice до індексу mid і ще один від mid до кінця slice.
Коли ми спробуємо скомпілювати код у Listing 20-5, отримаємо помилку:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Перевірник запозичень Rust не може зрозуміти, що ми запозичуємо різні частини slice; він лише знає, що ми двічі запозичаємо з одного й того самого slice. Запозичення різних частин slice є принципово коректним, тому що два slices не перетинаються, але Rust недостатньо розумний, щоб це знати. Коли ми знаємо, що код коректний, а Rust — ні, настав час звернутися до небезпечного коду.
Listing 20-6 показує, як використати unsafe block, raw pointer і деякі
виклики небезпечних функцій, щоб реалізація split_at_mut запрацювала.
use std::slice;
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
let ptr = values.as_mut_ptr();
assert!(mid <= len);
unsafe {
(
slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.add(mid), len - mid),
)
}
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}Пригадайте з розділу “The Slice Type” у главі
4, що slice — це вказівник на деякі дані та довжина slice. Ми використовуємо
метод len, щоб отримати довжину slice, і метод as_mut_ptr, щоб отримати
доступ до raw pointer slice. У цьому випадку, оскільки ми маємо mutable slice
до значень i32, as_mut_ptr повертає raw pointer типу *mut i32, який ми
зберегли у змінній ptr.
Ми залишаємо твердження про те, що індекс mid знаходиться в межах slice.
Потім доходить черга до небезпечного коду: функція slice::from_raw_parts_mut
приймає raw pointer і довжину та створює slice. Ми використовуємо цю функцію,
щоб створити slice, який починається з ptr і має довжину mid елементів.
Потім ми викликаємо метод add на ptr, передаючи mid як аргумент, щоб
отримати raw pointer, який починається з mid, і створюємо slice, використовуючи
цей вказівник і решту кількості елементів після mid як довжину.
Функція slice::from_raw_parts_mut є небезпечною, тому що вона приймає raw
pointer і повинна довіряти, що цей вказівник є дійсним. Метод add для raw
pointers також є небезпечним, тому що він повинен довіряти, що місце зі зсувом
також є дійсним вказівником. Тому нам довелося помістити unsafe block навколо
викликів slice::from_raw_parts_mut і add, щоб ми могли їх викликати.
Дивлячись на код і додаючи твердження, що mid має бути меншим або дорівнювати
len, ми можемо сказати, що всі raw pointers, використані всередині unsafe
block, будуть дійсними вказівниками на дані всередині slice. Це прийнятне й
доречне використання unsafe.
Зверніть увагу, що нам не потрібно позначати отриману функцію split_at_mut
як unsafe, і ми можемо викликати цю функцію з безпечного Rust. Ми створили
безпечну абстракцію над небезпечним кодом з реалізацією функції, яка безпечно
використовує unsafe code, тому що вона створює лише дійсні вказівники з даних,
до яких ця функція має доступ.
Натомість використання slice::from_raw_parts_mut у Listing 20-7, імовірно,
завершиться аварійно, коли буде використано slice. Цей код бере довільне місце
в пам’яті та створює slice довжиною 10 000 елементів.
fn main() {
use std::slice;
let address = 0x01234usize;
let r = address as *mut i32;
let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
}Ми не володіємо пам’яттю в цьому довільному місці, і немає гарантії, що slice,
який створює цей код, містить дійсні значення i32. Спроба використати
values, ніби це дійсний slice, призводить до невизначеної поведінки.
Використання extern функцій для виклику зовнішнього коду
Іноді вашому коду Rust може знадобитися взаємодія з кодом, написаним іншою
мовою. Для цього Rust має ключове слово extern, яке полегшує створення та
використання Foreign Function Interface (FFI), тобто способу, яким мова
програмування може визначати функції та дозволяти іншій (foreign) мові
програмування викликати ці функції.
Listing 20-8 демонструє, як налаштувати інтеграцію з функцією abs зі
standard library C. Функції, оголошені всередині extern block, загалом є
небезпечними для виклику з коду Rust, тому extern blocks також мають бути
позначені unsafe. Причина в тому, що інші мови не забезпечують правил і
гарантій Rust, а Rust не може їх перевірити, тож відповідальність лягає на
програміста — забезпечити безпеку.
unsafe extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Absolute value of -3 according to C: {}", abs(-3));
}
}Усередині unsafe extern "C" block ми перелічуємо назви та сигнатури зовнішніх
функцій з іншої мови, які хочемо викликати. Частина "C" визначає, який
application binary interface (ABI) використовує зовнішня функція: ABI
визначає, як викликати функцію на рівні асемблера. ABI "C" є найпоширенішим
і відповідає ABI мови програмування C. Інформація про всі ABI, які підтримує
Rust, доступна в the Rust Reference.
Кожен елемент, оголошений всередині unsafe extern block, неявно є
небезпечним. Однак деякі FFI functions є безпечними для виклику. Наприклад,
функція abs зі standard library C не має жодних міркувань щодо безпеки
пам’яті, і ми знаємо, що її можна викликати з будь-яким i32. У таких
випадках ми можемо використати ключове слово safe, щоб сказати, що ця
конкретна функція є безпечною для виклику, навіть попри те, що вона
знаходиться в unsafe extern block. Щойно ми вносимо цю зміну, її виклик
більше не потребує unsafe block, як показано в Listing 20-9.
unsafe extern "C" {
safe fn abs(input: i32) -> i32;
}
fn main() {
println!("Absolute value of -3 according to C: {}", abs(-3));
}Позначення функції як safe не робить її автоматично безпечною! Натомість це
подібно до обіцянки, яку ви даєте Rust, що вона є безпечною. На вас усе ще
лежить відповідальність переконатися, що ця обіцянка виконується!
Виклик функцій Rust з інших мов
Ми також можемо використовувати extern, щоб створити інтерфейс, який
дозволяє іншим мовам викликати функції Rust. Замість створення цілого extern
block ми додаємо ключове слово extern і вказуємо ABI, який слід
використовувати, прямо перед ключовим словом fn для відповідної функції.
Нам також потрібно додати анотацію #[unsafe(no_mangle)], щоб сказати
компілятору Rust не змінювати ім’я цієї функції. Mangling — це коли
компілятор змінює назву, яку ми дали функції, на іншу назву, яка містить більше
інформації для використання іншими частинами процесу компіляції, але є менш
зрозумілою для людини. Компілятор кожної мови програмування трохи по-різному
mangles імена, тому для того, щоб функцію Rust могли називати інші мови, ми
маємо вимкнути mangling імен компілятором Rust. Це небезпечно, тому що без
вбудованого mangling можуть виникати конфлікти імен між бібліотеками, тож на
нас лежить відповідальність переконатися, що вибране ім’я безпечно
експортувати без mangling.
У наступному прикладі ми робимо функцію call_from_c доступною з коду C після
того, як її буде скомпільовано в shared library і під’єднано з C:
#[unsafe(no_mangle)]
pub extern "C" fn call_from_c() {
println!("Just called a Rust function from C!");
}
Таке використання extern вимагає unsafe лише в атрибуті, а не в extern
block.
Отримання доступу до змінної static mutable або зміна її
У цій книзі ми ще не говорили про глобальні змінні, які Rust підтримує, але які можуть бути проблематичними через правила власності Rust. Якщо два потоки отримують доступ до однієї й тієї самої змінної mutable global variable, це може спричинити стан гонки даних.
У Rust глобальні змінні називаються static variables. Listing 20-10 показує приклад оголошення та використання static variable зі string slice як значенням.
static HELLO_WORLD: &str = "Hello, world!";
fn main() {
println!("value is: {HELLO_WORLD}");
}Static variables схожі на constants, про які ми говорили в розділі
“Declaring Constants” у главі 3. Назви static
variables за домовленістю записують у SCREAMING_SNAKE_CASE. Static variables
можуть зберігати лише посилання з часом життя 'static, що означає, що
компілятор Rust може визначити час життя, і нам не потрібно позначати його
явно. Отримувати доступ до незмінної static variable безпечно.
Непомітна різниця між constants і незмінними static variables полягає в тому,
що значення в static variable мають фіксовану адресу в пам’яті. Використання
значення завжди отримуватиме доступ до тих самих даних. Constants, з іншого
боку, можуть дублювати свої дані щоразу, коли їх використовують. Ще одна
відмінність полягає в тому, що static variables можуть бути mutable. Отримання
доступу до mutable static variables і їх зміна є unsafe. Listing 20-11
показує, як оголосити, отримати доступ і змінити mutable static variable на
ім’я COUNTER.
static mut COUNTER: u32 = 0;
/// SAFETY: Calling this from more than a single thread at a time is undefined
/// behavior, so you *must* guarantee you only call it from a single thread at
/// a time.
unsafe fn add_to_count(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
unsafe {
// SAFETY: This is only called from a single thread in `main`.
add_to_count(3);
println!("COUNTER: {}", *(&raw const COUNTER));
}
}Як і зі звичайними змінними, ми вказуємо змінність за допомогою ключового слова
mut. Будь-який код, який читає або записує COUNTER, має бути всередині
unsafe block. Код у Listing 20-11 компілюється і друкує COUNTER: 3, як ми
й очікували, тому що він однопотоковий. Якщо кілька потоків отримуватимуть
доступ до COUNTER, це, ймовірно, призведе до станів гонки даних, тому це є
невизначеною поведінкою. Отже, нам потрібно позначити всю функцію як unsafe
і задокументувати обмеження безпеки, щоб кожен, хто викликає цю функцію, знав,
що йому дозволено, а що не дозволено робити безпечно.
Щоразу, коли ми пишемо небезпечну функцію, ідіоматично писати коментар, що
починається з SAFETY, і пояснювати, що саме викликач має зробити, щоб
викликати функцію безпечно. Так само щоразу, коли ми виконуємо небезпечну
операцію, ідіоматично писати коментар, що починається з SAFETY, щоб
пояснити, як дотримуються правил безпеки.
Крім того, компілятор за замовчуванням відхилить будь-яку спробу створити
посилання на змінну mutable static variable через compiler lint. Ви повинні або
явно відмовитися від захисту цього lint, додавши анотацію
#[allow(static_mut_refs)], або отримувати доступ до mutable static variable
через raw pointer, створений одним із raw borrow operators. Це стосується й
випадків, коли посилання створюється неявно, як, наприклад, коли воно
використовується в println! у цьому фрагменті коду. Вимога створювати
посилання на mutable static variables через raw pointers допомагає зробити
вимоги безпеки для їх використання очевиднішими.
Коли mutable data є доступними глобально, важко гарантувати, що не буде станів гонки даних, саме тому Rust вважає mutable static variables небезпечними. За можливості краще використовувати техніки конкурентності та thread-safe smart pointers, які ми обговорювали в главі 16, щоб компілятор перевіряв, що доступ до даних із різних потоків відбувається безпечно.
Реалізація unsafe trait
Ми можемо використовувати unsafe, щоб реалізувати unsafe trait. Трейт є
unsafe, коли принаймні один із його методів має інваріант, який компілятор не
може перевірити. Ми оголошуємо, що трейт є unsafe, додаючи ключове слово
unsafe перед trait, і також позначаємо реалізацію трейтa як unsafe, як
показано в Listing 20-12.
unsafe trait Foo {
// methods go here
}
unsafe impl Foo for i32 {
// method implementations go here
}
fn main() {}Використовуючи unsafe impl, ми обіцяємо, що дотримаємося інваріантів, які
компілятор не може перевірити.
Як приклад, пригадайте marker traits Send і Sync, про які ми говорили в
розділі “Extensible Concurrency with Send and Sync” у главі 16: компілятор реалізує ці трейтa автоматично, якщо наші
типи складаються повністю з інших типів, які реалізують Send і Sync. Якщо
ми реалізуємо тип, що містить тип, який не реалізує Send або Sync, такий як
raw pointers, і хочемо позначити цей тип як Send або Sync, ми повинні
використати unsafe. Rust не може перевірити, що наш тип дотримується
гарантій, що його можна безпечно надсилати між потоками або отримувати до
нього доступ із кількох потоків; отже, нам потрібно зробити ці перевірки
вручну й позначити це за допомогою unsafe.
Отримання доступу до полів union
Остання дія, яка працює лише з unsafe, — це доступ до полів union. union
схожа на struct, але лише одне оголошене поле використовується в конкретному
екземплярі в один момент часу. Union переважно використовуються для
взаємодії з union у коді C. Доступ до полів union є небезпечним, тому що Rust
не може гарантувати тип даних, який зараз зберігається в екземплярі union. Ви
можете дізнатися більше про union в the Rust Reference.
Використання Miri для перевірки небезпечного коду
Під час написання небезпечного коду ви, можливо, захочете перевірити, що написане вами дійсно є безпечним і коректним. Один із найкращих способів зробити це — використати Miri, офіційний інструмент Rust для виявлення невизначеної поведінки. Якщо перевірник запозичень — це static інструмент, який працює під час компіляції, то Miri — це dynamic інструмент, який працює під час виконання. Він перевіряє ваш код, запускаючи вашу програму або її test suite, і виявляє, коли ви порушуєте правила, які він розуміє щодо того, як Rust має працювати.
Використання Miri потребує nightly build Rust (про що ми говоримо докладніше в
Appendix G: How Rust is Made and “Nightly Rust”). Ви
можете встановити і nightly версію Rust, і інструмент Miri, ввівши rustup +nightly component add miri. Це не змінює, яку версію Rust використовує ваш
проєкт; це лише додає інструмент у вашу систему, щоб ви могли використовувати
його, коли захочете. Ви можете запустити Miri для проєкту, ввівши cargo +nightly miri run або cargo +nightly miri test.
Як приклад того, наскільки це може бути корисно, розгляньте, що станеться, коли ми запустимо його проти Listing 20-7.
$ cargo +nightly miri run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `file:///home/.rustup/toolchains/nightly/bin/cargo-miri runner target/miri/debug/unsafe-example`
warning: integer-to-pointer cast
--> src/main.rs:5:13
|
5 | let r = address as *mut i32;
| ^^^^^^^^^^^^^^^^^^^ integer-to-pointer cast
|
= help: this program is using integer-to-pointer casts or (equivalently) `ptr::with_exposed_provenance`, which means that Miri might miss pointer bugs in this program
= help: see https://doc.rust-lang.org/nightly/std/ptr/fn.with_exposed_provenance.html for more details on that operation
= help: to ensure that Miri does not miss bugs in your program, use Strict Provenance APIs (https://doc.rust-lang.org/nightly/std/ptr/index.html#strict-provenance, https://crates.io/crates/sptr) instead
= help: you can then set `MIRIFLAGS=-Zmiri-strict-provenance` to ensure you are not relying on `with_exposed_provenance` semantics
= help: alternatively, `MIRIFLAGS=-Zmiri-permissive-provenance` disables this warning
= note: BACKTRACE:
= note: inside `main` at src/main.rs:5:13: 5:32
error: Undefined Behavior: pointer not dereferenceable: pointer must be dereferenceable for 40000 bytes, but got 0x1234[noalloc] which is a dangling pointer (it has no provenance)
--> src/main.rs:7:35
|
7 | let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Undefined Behavior occurred here
|
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: BACKTRACE:
= note: inside `main` at src/main.rs:7:35: 7:70
note: some details are omitted, run with `MIRIFLAGS=-Zmiri-backtrace=full` for a verbose backtrace
error: aborting due to 1 previous error; 1 warning emitted
Miri правильно попереджає нас, що ми приводимо ціле число до вказівника, що може бути проблемою, але Miri не може визначити, чи існує проблема, тому що він не знає, звідки походить вказівник. Потім Miri повертає помилку там, де в Listing 20-7 є невизначена поведінка, тому що ми маємо dangling pointer. Завдяки Miri ми тепер знаємо, що існує ризик невизначеної поведінки, і можемо подумати, як зробити код безпечним. У деяких випадках Miri навіть може надати рекомендації щодо виправлення помилок.
Miri не виявляє всього, що ви можете зробити неправильно під час написання небезпечного коду. Miri — це інструмент динамічного аналізу, тож він виявляє лише проблеми з кодом, який фактично виконується. Це означає, що вам потрібно використовувати його разом із хорошими методами тестування, щоб підвищити впевненість у написаному небезпечному коді. Miri також не охоплює кожен можливий спосіб, у який ваш код може бути unsound.
Іншими словами: якщо Miri дійсно знаходить проблему, ви знаєте, що є помилка, але лише тому, що Miri не знаходить помилку, не означає, що проблеми немає. Проте він може виявити дуже багато. Спробуйте запустити його на інших прикладах небезпечного коду в цій главі й подивіться, що він скаже!
Ви можете дізнатися більше про Miri в його репозиторії GitHub.
Коректне використання небезпечного коду
Використання unsafe, щоб скористатися однією з п’яти щойно обговорених
суперздібностей, не є неправильним і навіть не викликає несхвалення, але
зробити unsafe code коректним складніше, тому що компілятор не може
допомогти забезпечити безпеку пам’яті. Коли у вас є причина використовувати
unsafe code, ви можете це робити, а явна анотація unsafe полегшує
встановлення джерела проблем, коли вони виникають. Щоразу, коли ви пишете
небезпечний код, ви можете використовувати Miri, щоб бути більш впевненими,
що написаний вами код дотримується правил Rust.
Щоб значно глибше дослідити, як ефективно працювати з unsafe Rust, прочитайте
офіційний посібник Rust для unsafe, The Rustonomicon.
Розширені трейти
Розширені трейти
Спочатку ми розглядали трейти в розділі “Визначення спільної поведінки за допомогою трейтів” у розділі 10, але ми не обговорювали більш просунуті деталі. Тепер, коли ви знаєте більше про Rust, ми можемо перейти до суті.
Визначення трейтів з асоційованими типами
Асоційовані типи пов’язують заповнювач типу з трейтом так, що визначення методів трейту можуть використовувати ці типи-заповнювачі у своїх сигнатурах. Той, хто реалізує трейт, вкаже конкретний тип, який буде використаний замість типу-заповнювача для конкретної реалізації. Таким чином, ми можемо визначити трейт, який використовує деякі типи, не потребуючи знати точно, що це за типи, доки трейт не буде реалізовано.
Ми описували більшість просунутих можливостей у цьому розділі як такі, що потрібні рідко. Асоційовані типи перебувають десь посередині: їх використовують рідше, ніж можливості, пояснені в решті книги, але частіше, ніж багато інших можливостей, обговорюваних у цьому розділі.
Одним із прикладів трейту з асоційованим типом є трейт Iterator, який надає
стандартна бібліотека. Асоційований тип називається Item і позначає тип
значень, по яких ітерується тип, що реалізує трейт Iterator. Визначення
трейт-а Iterator показано у Лістингу 20-13.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Тип Item є заповнювачем, а визначення методу next показує, що він повертатиме
значення типу Option<Self::Item>. Ті, хто реалізує трейт Iterator, вкажуть
конкретний тип для Item, а метод next повертатиме Option, що містить
значення цього конкретного типу.
Асоційовані типи можуть здаватися подібною концепцією до узагальнених типів, у
тому сенсі, що останні дозволяють нам визначити функцію без зазначення того,
які типи вона може обробляти. Щоб дослідити різницю між цими двома концепціями,
ми розглянемо реалізацію трейт-а Iterator для типу на ім’я Counter, яка
вказує, що тип Item — це u32:
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}Цей синтаксис здається подібним до синтаксису узагальнених типів. То чому б
просто не визначити трейт Iterator з узагальненими типами, як показано у
Лістингу 20-14?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Різниця полягає в тому, що під час використання узагальнених типів, як у
Лістингу 20-14, ми мусимо анотувати типи в кожній реалізації; оскільки ми також
можемо реалізувати Iterator<String> for Counter або будь-який інший тип, ми
могли б мати кілька реалізацій Iterator для Counter. Іншими словами, коли
трейт має узагальнений параметр, його можна реалізувати для типу кілька разів,
змінюючи конкретні типи узагальнених параметрів типу щоразу. Коли ми
використовуємо метод next на Counter, нам довелося б надавати анотації типів,
щоб указати, яку саме реалізацію Iterator ми хочемо використовувати.
З асоційованими типами нам не потрібно анотувати типи, тому що ми не можемо
реалізувати трейт для типу кілька разів. У Лістингу 20-13 з визначенням, що
використовує асоційовані типи, ми можемо вибрати, яким буде тип Item, лише
один раз, тому що може існувати лише один impl Iterator for Counter. Нам не
потрібно вказувати, що ми хочемо ітератор значень u32, всюди, де ми викликаємо
next на Counter.
Асоційовані типи також стають частиною контракту трейту: ті, хто реалізує трейт, мають надати тип, який замінить заповнювач асоційованого типу. Асоційовані типи часто мають назву, що описує, як буде використовуватися тип, і документування асоційованого типу в документації API — це добра практика.
Використання типових параметрів узагальнених типів і перевантаження операторів
Коли ми використовуємо параметри узагальнених типів, ми можемо вказати типовий
конкретний тип для узагальненого типу. Це усуває потребу для тих, хто реалізує
трейт, указувати конкретний тип, якщо типовий тип підходить. Ви вказуєте типовий
тип під час оголошення узагальненого типу за допомогою синтаксису
<PlaceholderType=ConcreteType>.
Чудовим прикладом ситуації, де ця техніка корисна, є перевантаження операторів,
у якому ви налаштовуєте поведінку оператора (наприклад, +) у певних ситуаціях.
Rust не дозволяє вам створювати власні оператори або перевантажувати довільні
оператори. Але ви можете перевантажувати операції та відповідні трейти,
перелічені в std::ops, реалізувавши трейти, пов’язані з оператором. Наприклад,
у Лістингу 20-15 ми перевантажуємо оператор +, щоб додавати два екземпляри
Point один до одного. Ми робимо це, реалізуючи трейт Add для структури
Point.
use std::ops::Add;
#[derive(Debug, Copy, Clone, PartialEq)]
struct Point {
x: i32,
y: i32,
}
impl Add for Point {
type Output = Point;
fn add(self, other: Point) -> Point {
Point {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
fn main() {
assert_eq!(
Point { x: 1, y: 0 } + Point { x: 2, y: 3 },
Point { x: 3, y: 3 }
);
}Метод add додає значення x двох екземплярів Point і значення y двох
екземплярів Point, щоб створити новий Point. Трейт Add має асоційований
тип на ім’я Output, який визначає тип, що повертається з методу add.
Типовий параметр узагальненого типу в цьому коді міститься в трейт-і Add.
Ось його визначення:
#![allow(unused)]
fn main() {
trait Add<Rhs=Self> {
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
}
}Цей код загалом має вигляд, який вам уже знайомий: трейт з одним методом і
асоційованим типом. Нова частина — Rhs=Self: цей синтаксис називається
типовими параметрами типу. Параметр узагальненого типу Rhs (скорочено від
“right-hand side”) визначає тип параметра rhs у методі add. Якщо ми не
вкажемо конкретний тип для Rhs, коли реалізуємо трейт Add, тип Rhs
за замовчуванням буде Self, тобто типом, для якого ми реалізуємо Add.
Коли ми реалізовували Add для Point, ми використали типовий параметр для
Rhs, тому що хотіли додати два екземпляри Point. Розгляньмо приклад
реалізації трейт-а Add, де ми хочемо налаштувати тип Rhs, а не
використовувати типовий.
У нас є дві структури, Millimeters і Meters, які зберігають значення в
різних одиницях. Це тонке обгортання наявного типу в іншу структуру відоме як
патерн newtype, який ми докладніше описуємо в розділі
“Реалізація зовнішніх трейтів за допомогою патерну newtype” . Ми хочемо додавати значення в міліметрах до значень у метрах і щоб
реалізація Add правильно виконувала перетворення. Ми можемо реалізувати
Add для Millimeters з Meters як Rhs, як показано в Лістингу 20-16.
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}Щоб додати Millimeters і Meters, ми вказуємо impl Add<Meters>, щоб задати
значення параметра типу Rhs замість використання типового значення Self.
Ви використовуватимете типові параметри типу двома основними способами:
- Щоб розширити тип, не ламаючи наявний код
- Щоб дозволити налаштування в конкретних випадках, які більшості користувачів не потрібні
Трейт Add зі стандартної бібліотеки — приклад другої мети: зазвичай ви додаєте
два типи одного виду, але трейт Add надає можливість налаштувати поведінку
ширше за це. Використання типового параметра типу у визначенні трейт-а Add
означає, що вам не потрібно вказувати додатковий параметр більшу частину часу.
Іншими словами, не потрібен деякий шаблонний код реалізації, що робить трейт
простішим у використанні.
Перша мета подібна до другої, але навпаки: якщо ви хочете додати параметр типу до наявного трейт-а, ви можете надати йому типове значення, щоб дозволити розширення функціональності трейт-а без ламання наявного коду реалізації.
Усунення неоднозначності між однаково названими методами
Ніщо в Rust не заважає трейт-у мати метод з тією самою назвою, що й метод іншого трейт-а, і Rust також не забороняє вам реалізувати обидва трейти для одного типу. Також можливо реалізувати метод безпосередньо на типі з тією ж назвою, що й методи з трейтів.
Під час виклику методів з однаковою назвою вам потрібно буде сказати Rust,
який саме ви хочете використовувати. Розгляньте код у Лістингу 20-17, де ми
визначили два трейти, Pilot і Wizard, які обидва мають метод під назвою
fly. Потім ми реалізуємо обидва трейти для типу Human, який уже має метод
під назвою fly, реалізований безпосередньо на ньому. Кожен метод fly
робить щось інше.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {}Коли ми викликаємо fly на екземплярі Human, компілятор за замовчуванням
викликає метод, який реалізовано безпосередньо на типі, як показано в
Лістингу 20-18.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
person.fly();
}Запуск цього коду виведе *waving arms furiously*, показуючи, що Rust викликав
метод fly, реалізований безпосередньо на Human.
Щоб викликати методи fly з трейт-а Pilot або трейт-а Wizard, нам потрібно
використати більш явний синтаксис, щоб указати, який саме метод fly ми
маємо на увазі. Лістинг 20-19 демонструє цей синтаксис.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
Pilot::fly(&person);
Wizard::fly(&person);
person.fly();
}Указання імені трейт-а перед іменем методу робить для Rust зрозумілим, яку
саме реалізацію fly ми хочемо викликати. Ми також могли б написати
Human::fly(&person), що еквівалентно person.fly(), який ми використали в
Лістингу 20-19, але це трохи довше писати, якщо нам не потрібно усувати
неоднозначність.
Запуск цього коду виводить таке:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Оскільки метод fly приймає параметр self, якщо б у нас було два типи,
які обидва реалізують один трейт, Rust міг би визначити, яку реалізацію
трейт-а використовувати, на основі типу self.
Однак асоційовані функції, які не є методами, не мають параметра self. Коли
є кілька типів або трейтів, які визначають не-методні функції з однаковою
назвою функції, Rust не завжди знає, який тип ви маєте на увазі, якщо тільки
ви не використовуєте повністю кваліфікований синтаксис. Наприклад, у
Лістингу 20-20 ми створюємо трейт для притулку для тварин, який хоче називати
всіх цуценят Spot. Ми створюємо трейт Animal з асоційованою не-методною
функцією baby_name. Трейт Animal реалізовано для структури Dog, для якої
ми також безпосередньо надаємо асоційовану не-методну функцію baby_name.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
}Ми реалізуємо код для називання всіх цуценят Spot в асоційованій функції
baby_name, визначеній для Dog. Тип Dog також реалізує трейт Animal,
який описує характеристики, спільні для всіх тварин. Цуценят собак називають
puppies, і це виражено в реалізації трейт-а Animal для Dog у функції
baby_name, пов’язаній з трейт-ом Animal.
У main ми викликаємо функцію Dog::baby_name, яка безпосередньо викликає
асоційовану функцію, визначену для Dog. Цей код виводить таке:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
Цей вивід не той, який ми хотіли. Ми хочемо викликати функцію baby_name,
яка є частиною трейт-а Animal, який ми реалізували для Dog, щоб код
вивів A baby dog is called a puppy. Техніка вказання імені трейт-а, яку ми
використали в Лістингу 20-19, тут не допомагає; якщо ми змінимо main на код
з Лістингу 20-21, ми отримаємо помилку компіляції.
{{#rustdoc_include ../listings/ch20-advanced-features/no-listing-21-impl-animal-for-dog/src/main.rs:here}}Оскільки Animal::baby_name не має параметра self, і можуть існувати інші
типи, які реалізують трейт Animal, Rust не може визначити, яку саме
реалізацію Animal::baby_name ми хочемо. Ми отримаємо цю помилку компілятора:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` (bin "traits-example") due to 1 previous error
Щоб усунути неоднозначність і сказати Rust, що ми хочемо використовувати
реалізацію Animal для Dog, а не реалізацію Animal для якогось іншого
типу, нам потрібно використовувати повністю кваліфікований синтаксис.
Лістинг 20-22 демонструє, як використовувати повністю кваліфікований синтаксис.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}Ми надаємо Rust анотацію типу всередині кутових дужок, яка вказує, що ми хочемо
викликати метод baby_name з трейт-а Animal, реалізованого для Dog, кажучи,
що ми хочемо розглядати тип Dog як Animal для цього виклику функції. Тепер
цей код виведе те, що ми хочемо:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
Загалом повністю кваліфікований синтаксис визначається так:
<Type as Trait>::function(receiver_if_method, next_arg, ...);Для асоційованих функцій, які не є методами, не було б receiver: був би
лише список інших аргументів. Ви можете використовувати повністю кваліфікований
синтаксис усюди, де ви викликаєте функції або методи. Однак вам дозволено
опускати будь-яку частину цього синтаксису, яку Rust може визначити з іншої
інформації в програмі. Вам потрібно використовувати цей більш багатослівний
синтаксис лише в тих випадках, коли існує кілька реалізацій, що використовують
однакову назву, і Rust потрібна допомога, щоб визначити, яку саме реалізацію
ви хочете викликати.
Використання супертрейтів
Іноді ви можете написати визначення трейт-а, яке залежить від іншого трейт-а: щоб тип реалізовував перший трейт, ви хочете вимагати, щоб цей тип також реалізовував другий трейт. Ви робите це для того, щоб ваше визначення трейт-а могло використовувати асоційовані елементи другого трейт-а. Трейт, на який спирається ваше визначення трейт-а, називається супертрейт вашого трейт-а.
Наприклад, припустімо, ми хочемо створити трейт OutlinePrint з методом
outline_print, який друкуватиме задане значення, відформатоване так, щоб воно
було обрамлене зірочками. Тобто, якщо задано структуру Point, яка реалізує
стандартний трейт Display так, що результатом є (x, y), коли ми викликаємо
outline_print на екземплярі Point, який має 1 для x і 3 для y, він
має вивести таке:
**********
* *
* (1, 3) *
* *
**********
У реалізації методу outline_print ми хочемо використовувати функціональність
трейт-а Display. Отже, нам потрібно вказати, що трейт OutlinePrint працюватиме
лише для типів, які також реалізують Display, і надають функціональність,
потрібну OutlinePrint. Ми можемо зробити це у визначенні трейт-а, вказавши
OutlinePrint: Display. Ця техніка подібна до додавання обмеження трейт-а до
трейт-а. Лістинг 20-23 показує реалізацію трейт-а OutlinePrint.
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
fn main() {}Оскільки ми вказали, що OutlinePrint вимагає трейт Display, ми можемо
використати функцію to_string, яка автоматично реалізується для будь-якого
типу, що реалізує Display. Якби ми спробували використати to_string без
додавання двокрапки та без указання трейт-а Display після імені трейт-а, ми
отримали б помилку, що не знайдено метод to_string для типу &Self в
поточній області видимості.
Подивімося, що станеться, коли ми спробуємо реалізувати OutlinePrint для
типу, який не реалізує Display, наприклад структури Point:
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Ми отримуємо помилку, що Display потрібен, але не реалізований:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:23
|
20 | impl OutlinePrint for Point {}
| ^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:24:7
|
24 | p.outline_print();
| ^^^^^^^^^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint::outline_print`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint::outline_print`
4 | fn outline_print(&self) {
| ------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` (bin "traits-example") due to 2 previous errors
Щоб виправити це, ми реалізуємо Display для Point і задовольнимо
обмеження, яке вимагає OutlinePrint, ось так:
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
use std::fmt;
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Тоді реалізація трейт-а OutlinePrint для Point успішно скомпілюється, і ми
зможемо викликати outline_print на екземплярі Point, щоб показати його в
обрамленні із зірочок.
Реалізація зовнішніх трейтів за допомогою патерну newtype
У розділі “Реалізація трейт-а для типу” у розділі 10 ми згадували правило сироти, яке стверджує, що нам дозволено реалізувати трейт для типу лише якщо або трейт, або тип, або обидва, є локальними для нашого крейту. Обійти це обмеження можна за допомогою патерну newtype, який полягає у створенні нового типу в кортежній структурі. (Ми розглядали кортежні структури в розділі “Створення різних типів за допомогою кортежних структур” у розділі 5.) Кортежна структура матиме одне поле і буде тонкою обгорткою навколо типу, для якого ми хочемо реалізувати трейт. Тоді тип обгортки є локальним для нашого крейту, і ми можемо реалізувати трейт для обгортки. Newtype — це термін, що походить із мови програмування Haskell. Використання цього патерну не створює штрафу для продуктивності під час виконання, а тип обгортки усувається під час компіляції.
Як приклад, припустімо, ми хочемо реалізувати Display для Vec<T>, що
правило сироти не дозволяє нам робити безпосередньо, тому що трейт Display і
тип Vec<T> визначені поза нашим крейтом. Ми можемо створити структуру
Wrapper, яка зберігає екземпляр Vec<T>; тоді ми можемо реалізувати Display
для Wrapper і використовувати значення Vec<T>, як показано в Лістингу 20-24.
use std::fmt;
struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
let w = Wrapper(vec![String::from("hello"), String::from("world")]);
println!("w = {w}");
}Реалізація Display використовує self.0, щоб отримати доступ до внутрішнього
Vec<T>, тому що Wrapper є кортежною структурою, а Vec<T> є елементом
з індексом 0 у кортежі. Потім ми можемо використовувати функціональність
трейт-а Display для Wrapper.
Недолік використання цієї техніки полягає в тому, що Wrapper — це новий тип,
тому він не має методів значення, яке він зберігає. Нам довелося б
реалізувати всі методи Vec<T> безпосередньо для Wrapper так, щоб методи
делегували self.0, що дозволило б нам поводитися з Wrapper точно як з
Vec<T>. Якби ми хотіли, щоб новий тип мав кожен метод, який має внутрішній
тип, реалізація трейт-а Deref для Wrapper, щоб повертати внутрішній тип,
була б розв’язком (ми обговорювали реалізацію трейт-а Deref у розділі
“Поводження з розумними вказівниками як зі звичайними посиланнями”
у розділі 15). Якби ми не хотіли, щоб тип Wrapper мав усі методи
внутрішнього типу — наприклад, щоб обмежити поведінку типу Wrapper, —
нам довелося б реалізувати вручну лише ті методи, які ми хочемо.
Цей патерн newtype також корисний навіть тоді, коли трейти не залучені. Тепер перемкнімо увагу й розгляньмо деякі просунуті способи взаємодії з системою типів Rust.
Розширені типи
Розширені типи
Система типів Rust має деякі можливості, які ми досі згадували, але ще не обговорювали. Ми почнемо з обговорення newtypes загалом, коли розглядатимемо, чому вони корисні як типи. Потім ми перейдемо до псевдонімів типів, можливості, подібної до newtypes, але з трохи іншою семантикою. Ми також обговоримо тип ! і динамічно розмірні типи.
Безпека типів і абстракція за допомогою шаблону newtype
У цьому розділі припускається, що ви прочитали попередній розділ “Implementing External
Traits with the Newtype Pattern”. Шаблон newtype
також корисний для завдань, окрім тих, які ми обговорювали досі, включно з
статичним забезпеченням того, що значення ніколи не плутаються, і позначенням одиниць
значення. Ви бачили приклад використання newtypes для позначення одиниць у Listing
20-16: Згадайте, що структури Millimeters і Meters обгортали значення u32
у newtype. Якби ми написали функцію з параметром типу Millimeters, ми
не змогли б скомпілювати програму, яка випадково спробувала б викликати цю
функцію зі значенням типу Meters або звичайним u32.
Ми також можемо використовувати шаблон newtype, щоб абстрагувати деякі деталі реалізації типу: Новий тип може відкривати публічний API, який відрізняється від API приватного внутрішнього типу.
Newtypes також можуть приховувати внутрішню реалізацію. Наприклад, ми могли б надати
тип People, щоб обгорнути HashMap<i32, String>, який зберігає ID людини,
пов’язаний з її ім’ям. Код, що використовує People, взаємодіяв би лише з
публічним API, який ми надаємо, наприклад із методом для додавання рядка імені до
колекції People; цьому коду не потрібно було б знати, що ми внутрішньо призначаємо
іменам ID i32. Шаблон newtype — це легковагий спосіб досягти інкапсуляції,
щоб приховати деталі реалізації, яку ми обговорювали в розділі “Encapsulation that
Hides Implementation
Details”
у Chapter 18.
Синоніми типів і псевдоніми типів
Rust надає можливість оголосити псевдонім типу, щоб дати наявному типу
іншу назву. Для цього ми використовуємо ключове слово type. Наприклад, ми можемо створити
псевдонім Kilometers для i32 ось так:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Тепер псевдонім Kilometers є синонімом для i32; на відміну від типів Millimeters
і Meters, які ми створили в Listing 20-16, Kilometers не є окремим,
новим типом. Значення, що мають тип Kilometers, будуть оброблятися так само, як
значення типу i32:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Оскільки Kilometers і i32 — це один і той самий тип, ми можемо додавати значення обох
типів і можемо передавати значення Kilometers у функції, що приймають
параметри i32. Однак, використовуючи цей метод, ми не отримуємо переваг
перевірки типів, які ми отримуємо від шаблону newtype, обговореного раніше. Іншими словами, якщо
ми десь переплутаємо значення Kilometers і i32, компілятор не видасть нам
помилку.
Основний варіант використання синонімів типів — це зменшення повторення. Наприклад, у нас може бути довгий тип на кшталт цього:
Box<dyn Fn() + Send + 'static>Писати цей довгий тип у сигнатурах функцій і як анотації типів по всьому коду може бути виснажливо й схильним до помилок. Уявіть собі проєкт, повний коду на кшталт того, що в Listing 20-25.
fn main() {
let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi"));
fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) {
// --snip--
}
fn returns_long_type() -> Box<dyn Fn() + Send + 'static> {
// --snip--
Box::new(|| ())
}
}Псевдонім типу робить цей код більш керованим, зменшуючи повторення. У
Listing 20-26 ми запровадили псевдонім із назвою Thunk для багатослівного типу і
можемо замінити всі використання типу коротшим псевдонімом Thunk.
fn main() {
type Thunk = Box<dyn Fn() + Send + 'static>;
let f: Thunk = Box::new(|| println!("hi"));
fn takes_long_type(f: Thunk) {
// --snip--
}
fn returns_long_type() -> Thunk {
// --snip--
Box::new(|| ())
}
}Цей код набагато легше читати і писати! Вибір змістовної назви для псевдоніма типу також може допомогти передати ваш намір (thunk — це слово для коду, який буде обчислено пізніше, тож це відповідна назва для замикання, яке зберігається).
Псевдоніми типів також часто використовуються з типом Result<T, E> для зменшення
повторення. Розгляньте модуль std::io у стандартній бібліотеці. Операції I/O
часто повертають Result<T, E>, щоб обробляти ситуації, коли операції
не вдається виконати. Ця бібліотека має структуру std::io::Error, яка представляє всі
можливі помилки I/O. Багато функцій у std::io повертатимуть
Result<T, E>, де E — це std::io::Error, наприклад ці функції в
трейт Write:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Result<..., Error> повторюється дуже часто. Тому std::io має таке
оголошення псевдоніма типу:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Оскільки це оголошення знаходиться в модулі std::io, ми можемо використовувати повністю
кваліфікований псевдонім std::io::Result<T>; тобто Result<T, E>, у якому E
заповнено як std::io::Error. Сигнатури функцій трейта Write зрештою
виглядають ось так:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Псевдонім типу допомагає двома способами: Він робить код легшим для написання і дає
нам узгоджений інтерфейс для всього std::io. Оскільки це псевдонім, це
просто ще один Result<T, E>, що означає, що ми можемо використовувати з ним будь-які методи, які працюють на
Result<T, E>, а також спеціальний синтаксис, як-от оператор ?.
Тип Never, який ніколи не повертається
Rust має спеціальний тип з назвою !, який у термінах теорії типів відомий як
порожній тип , тому що він не має значень. Ми віддаємо перевагу називати його типом never
оскільки він стоїть на місці типу повернення, коли функція ніколи не
повертає значення. Ось приклад:
fn bar() -> ! {
// --snip--
panic!();
}Цей код читається як “функція bar повертає never”. Функції, що повертають
never, називаються функціями, що розходяться. Ми не можемо створити значення типу !,
тож bar у принципі не може повернути значення.
Але яка користь від типу, для якого ви ніколи не можете створити значення? Згадайте код із Listing 2-5, частину гри в угадай число; ми відтворили його трохи тут у Listing 20-27.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Тоді ми пропустили деякі деталі в цьому коді. У розділі “The match
Control Flow Construct”
Chapter 6 ми обговорювали, що всі гілки match мають повертати один і той самий
тип. Тож, наприклад, наведений нижче код не працює:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}Тип guess у цьому коді мав би бути і цілим числом, і рядком, а Rust вимагає, щоб guess
мав лише один тип. Отже, що повертає continue? Як нам було дозволено повернути u32
з однієї гілки й мати іншу гілку, яка закінчується continue, у Listing 20-27?
Як ви могли здогадатися, continue має значення !. Тобто, коли Rust
обчислює тип guess, він дивиться на обидві гілки match, першу зі
значенням u32 і другу зі значенням !. Оскільки ! ніколи не може мати
значення, Rust вирішує, що тип guess — це u32.
Формальний спосіб описати цю поведінку полягає в тому, що вирази типу ! можуть
бути приведені до будь-якого іншого типу. Нам дозволено завершувати цю гілку match
за допомогою continue, тому що continue не повертає значення; натомість він передає керування
назад на початок циклу, тож у випадку Err ми ніколи не присвоюємо значення
guess.
Тип never також корисний із макросом panic!. Згадайте функцію unwrap,
яку ми викликаємо на значеннях Option<T>, щоб отримати значення або викликати panic
з таким визначенням:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}У цьому коді відбувається те саме, що й у match у Listing 20-27: Rust
бачить, що val має тип T, а panic! має тип !, тож результат
усього виразу match — це T. Цей код працює, тому що panic!
не породжує значення; він завершує програму. У випадку None ми не
повертатимемо значення з unwrap, тож цей код є допустимим.
Останній вираз, який має тип !, — це цикл:
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}Тут цикл ніколи не закінчується, тож ! є значенням виразу. Однак це
не було б правдою, якби ми додали break, тому що цикл завершився б,
коли дійшов би до break.
Динамічно розмірні типи та трейт Sized
Rust потрібно знати певні деталі про свої типи, наприклад скільки місця виділити для значення певного типу. Це залишає один кут його системи типів трохи заплутаним на перший погляд: поняття динамічно розмірних типів. Іноді їх називають DST або типами без розміру, ці типи дають нам змогу писати код, використовуючи значення, розмір яких ми можемо дізнатися лише під час виконання.
Давайте розберемося в деталях динамічно розмірного типу str, який
ми використовували впродовж усієї книги. Саме так, не &str, а str
сам по собі є DST. У багатьох випадках, таких як зберігання тексту, введеного користувачем,
ми не можемо знати, якою є довжина рядка, доки не настане час виконання. Це означає, що ми не можемо створити
змінну типу str, і ми також не можемо взяти аргумент типу str. Розгляньте
наступний код, який не працює:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}Rust потрібно знати, скільки пам’яті виділити для будь-якого значення певного
типу, і всі значення одного типу мають використовувати однаковий обсяг пам’яті. Якби Rust
дозволив нам написати цей код, ці два значення str мали б займати
однаковий обсяг місця. Але вони мають різну довжину: s1 потребує 12 байтів
сховища, а s2 — 15. Ось чому неможливо створити змінну,
що містить динамічно розмірний тип.
Отже, що нам робити? У цьому випадку ви вже знаєте відповідь: Ми робимо тип
str для s1 і s2 рядковим зрізом (&str), а не str. Згадайте з розділу
“String Slices” у Chapter 4, що структура
даних зрізу зберігає лише початкову позицію та довжину зрізу. Отже,
хоча &T — це одне значення, яке зберігає адресу пам’яті, де розташовано T,
рядковий зріз — це два значення: адреса str і його довжина. Таким чином,
ми можемо знати розмір значення рядкового зрізу під час компіляції: Він удвічі
більший за довжину usize. Тобто ми завжди знаємо розмір рядкового зрізу,
незалежно від того, якої довжини рядок, на який він посилається. Загалом це
той спосіб, у який динамічно розмірні типи використовуються в Rust:
Вони мають додатковий біт метаданих, який зберігає розмір динамічної
інформації. Золоте правило динамічно розмірних типів полягає в тому, що ми завжди
маємо розміщувати значення динамічно розмірних типів за якимось
вказівником.
Ми можемо поєднувати str з усіма видами вказівників: наприклад, Box<str> або
Rc<str>. Насправді ви вже бачили це раніше, але з іншим динамічно
розмірним типом: трейтами. Кожен трейт — це динамічно розмірний тип, на який ми можемо посилатися, використовуючи
назву трейта. У розділі “Using Trait Objects to Abstract over
Shared Behavior” у Chapter 18 ми згадували, що щоб використовувати трейт як трейт-об’єкт,
ми маємо помістити його за вказівником, наприклад &dyn Trait або Box<dyn Trait> (Rc<dyn Trait> теж працював би).
Для роботи з DST, Rust надає трейт Sized, щоб визначити, чи відомий
розмір типу під час компіляції. Цей трейт автоматично реалізується
для всього, чий розмір відомий під час компіляції. Крім того, Rust
неявно додає обмеження на Sized до кожної узагальненої функції. Тобто,
оголошення узагальненої функції на кшталт цього:
fn generic<T>(t: T) {
// --snip--
}фактично розглядається так, ніби ми написали це:
fn generic<T: Sized>(t: T) {
// --snip--
}За замовчуванням узагальнені функції працюватимуть лише з типами, для яких розмір відомий під час компіляції. Однак ви можете використати такий спеціальний синтаксис, щоб послабити це обмеження:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}Обмеження трейта на ?Sized означає “T може бути Sized, а може й не бути”, і це
позначення скасовує стандартне правило, за яким узагальнені типи мають мати відомий розмір
під час компіляції. Синтаксис ?Trait із цим значенням доступний лише для
Sized, а не для будь-яких інших трейтів.
Також зауважте, що ми змінили тип параметра t з T на &T.
Оскільки тип може бути не Sized, нам потрібно використовувати його за якимось
вказівником. У цьому випадку ми обрали посилання.
Далі ми поговоримо про функції та замикання!
Розширені функції та замикання
Розширені функції та замикання
Цей розділ досліджує деякі розширені можливості, пов’язані з функціями та замиканнями, зокрема вказівники на функції та повернення замикань.
Вказівники на функції
Ми вже говорили про те, як передавати замикання до функцій; ви також можете передавати звичайні
функції до функцій! Ця техніка корисна, коли ви хочете передати
функцію, яку ви вже визначили, замість визначення нового замикання. Функції
приводяться до типу fn (з малою літерою f), не слід плутати з
трейтoм Fn для замикань. Тип fn називається вказівником на функцію. Передавання
функцій за допомогою вказівників на функції дасть змогу використовувати функції як аргументи
інших функцій.
Синтаксис для вказання того, що параметр є вказівником на функцію, подібний до
синтаксису замикань, як показано в Listing 20-28, де ми визначили функцію
add_one, яка додає 1 до свого параметра. Функція do_twice приймає два
параметри: вказівник на функцію для будь-якої функції, яка приймає параметр i32
і повертає i32, та одне значення i32. Функція do_twice викликає
функцію f двічі, передаючи їй значення arg, а потім додає два результати
виклику функції разом. Функція main викликає do_twice з аргументами
add_one і 5.
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
fn main() {
let answer = do_twice(add_one, 5);
println!("The answer is: {answer}");
}Цей код друкує The answer is: 12. Ми вказуємо, що параметр f у
do_twice є fn, який приймає один параметр типу i32 і повертає
i32. Потім ми можемо викликати f у тілі do_twice. У main ми можемо передати
ім’я функції add_one як перший аргумент до do_twice.
На відміну від замикань, fn є типом, а не трейтом, тож ми вказуємо fn як
тип параметра безпосередньо, а не оголошуємо узагальнений параметр типу з одним
із трейтів Fn як обмеження трейтів.
Вказівники на функції реалізують усі три трейти замикань (Fn, FnMut і
FnOnce), тобто ви завжди можете передати вказівник на функцію як аргумент для
функції, яка очікує замикання. Найкраще писати функції, використовуючи узагальнений
тип і один із трейтів Fn, щоб ваші функції могли приймати або
функції, або замикання.
Тим не менш, один приклад, де ви б хотіли приймати лише fn, а не
замикання, — це взаємодія із зовнішнім кодом, який не має замикань: функції C
можуть приймати функції як аргументи, але C не має замикань.
Як приклад того, де ви могли б використати або замикання, визначене безпосередньо,
або іменовану функцію, подивімося на використання методу map, наданого
трейтoм Iterator у стандартній бібліотеці. Щоб використати метод map для перетворення вектора
чисел у вектор рядків, ми могли б використати замикання, як у Listing 20-29.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(|i| i.to_string()).collect();
}Або ми могли б назвати функцію як аргумент для map замість замикання.
Listing 20-30 показує, як це виглядало б.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(ToString::to_string).collect();
}Зауважте, що ми повинні використовувати повністю кваліфікований синтаксис, про який ми говорили в
розділі “Advanced Traits”, тому що існує
кілька доступних функцій з назвою to_string.
Тут ми використовуємо функцію to_string, визначену в трейтi ToString,
який стандартна бібліотека реалізувала для будь-якого типу, що реалізує
Display.
Пригадайте з розділу “Enum Values” у Chapter 6, що ім’я кожного варіанта переліку, який ми визначаємо, також стає функцією ініціалізації. Ми можемо використовувати ці функції ініціалізації як вказівники на функції, що реалізують трейти замикань, що означає, що ми можемо вказувати функції ініціалізації як аргументи для методів, які приймають замикання, як видно в Listing 20-31.
fn main() {
enum Status {
Value(u32),
Stop,
}
let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect();
}Тут ми створюємо екземпляри Status::Value, використовуючи кожне значення u32 у діапазоні,
на якому викликається map, за допомогою функції ініціалізації Status::Value.
Деякі люди надають перевагу цьому стилю, а деякі люди надають перевагу використанню замикань. Вони
компілюються в той самий код, тож використовуйте той стиль, який вам зрозуміліший.
Повернення замикань
Замикання представлені трейтами, що означає, що ви не можете повертати замикання
безпосередньо. У більшості випадків, коли ви могли б захотіти повернути трейт, ви можете натомість
використати конкретний тип, який реалізує трейт, як значення, що повертається
функцією. Однак зазвичай ви не можете зробити це із замиканнями, тому що вони не
мають конкретного типу, який можна повернути; вам не дозволено використовувати вказівник на функцію fn
як тип, що повертається, якщо замикання захоплює будь-які значення зі своєї
області видимості, наприклад.
Натомість ви зазвичай використовуватимете синтаксис impl Trait, який ми вивчили в
Chapter 10. Ви можете повертати будь-який тип функції, використовуючи Fn, FnOnce і FnMut.
Наприклад, код у Listing 20-32 буде чудово компілюватися.
#![allow(unused)]
fn main() {
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
}Однак, як ми зазначали в розділі “Inferring and Annotating Closure Types” у Chapter 13, кожне замикання також є своїм окремим типом. Якщо вам потрібно працювати з кількома функціями, що мають однаковий сигнатуру, але різні реалізації, вам потрібно буде використовувати трейт-об’єкт для них. Подивіться, що станеться, якщо ви напишете код, подібний до того, що показано в Listing 20-33.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
move |x| x + init
}Тут у нас є дві функції, returns_closure і returns_initialized_closure,
які обидві повертають impl Fn(i32) -> i32. Зверніть увагу, що замикання, які вони
повертають, різні, навіть якщо вони реалізують один і той самий тип. Якщо ми спробуємо
скомпілювати це, Rust повідомить нам, що це не спрацює:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0308]: mismatched types
--> src/main.rs:2:44
|
2 | let handlers = vec![returns_closure(), returns_initialized_closure(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
9 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
13 | fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32`
found opaque type `impl Fn(i32) -> i32`
= note: distinct uses of `impl Trait` result in different opaque types
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions-example` (bin "functions-example") due to 1 previous error
Повідомлення про помилку каже нам, що щоразу, коли ми повертаємо impl Trait, Rust
створює унікальний непрозорий тип, тип, всередину деталей якого ми не можемо
зазирнути, які Rust конструює для нас, і ми також не можемо вгадати тип, який Rust згенерує,
щоб написати його самостійно. Отже, хоча ці функції повертають замикання, що реалізують
один і той самий трейт, Fn(i32) -> i32, непрозорі типи, які Rust генерує для кожного з них, є
різними. (Це схоже на те, як Rust створює різні конкретні типи
для різних async-блоків, навіть коли вони мають той самий тип виводу, як ми бачили в
“The Pin Type and the Unpin Trait” у
Chapter 17.) Ми вже бачили рішення цієї проблеми кілька разів: ми можемо
використати трейт-об’єкт, як у Listing 20-34.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |x| x + init)
}Цей код чудово скомпілюється. Докладніше про трейт-об’єкти дивіться в розділі “Using Trait Objects To Abstract over Shared Behavior” у Chapter 18.
Далі подивімося на макроси!
Макроси
Макроси
Ми використовували макроси, такі як println!, протягом усієї цієї книги, але ще не повністю
розглянули, що таке макрос і як він працює. Термін macro означає сімейство
можливостей у Rust — декларативні макроси з macro_rules! і три види
процедурних макросів:
- Custom
#[derive]макроси, які визначають код, що додається за допомогою атрибутаderive, використаного на структурах і переліках - Макроси, схожі на атрибути, які визначають custom атрибути, придатні для використання на будь-якому item
- Макроси, схожі на функції, які виглядають як виклики функцій, але працюють із токенами, зазначеними як їхній аргумент
Ми поговоримо про кожен із них по черзі, але спочатку подивімося, навіщо нам узагалі потрібні макроси, якщо в нас уже є функції.
Різниця між макросами та функціями
У своїй основі макроси — це спосіб писати код, який пише інший код, що відомо як метапрограмування. В Додатку C ми обговорюємо атрибут derive,
який генерує реалізацію різних трейтів для вас. Ми також використовували макроси println! і vec! протягом усієї книги. Усі ці
макроси розгортаються, щоб створювати більше коду, ніж код, який ви написали вручну.
Метапрограмування корисне для зменшення обсягу коду, який вам доводиться писати й підтримувати, що також є однією з ролей функцій. Однак макроси мають деякі додаткові можливості, яких немає у функцій.
Сигнатура функції має оголошувати кількість і тип параметрів, які має
функція. Макроси, з іншого боку, можуть приймати змінну кількість
параметрів: Ми можемо викликати println!("hello") з одним аргументом або
println!("hello {}", name) з двома аргументами. Крім того, макроси розгортаються
до того, як компілятор інтерпретує значення коду, тож макрос може, наприклад,
реалізувати трейт для заданого типу. Функція не може цього зробити, тому що вона
викликається під час виконання, а трейт має бути реалізований під час компіляції.
Недолік реалізації макросу замість функції полягає в тому, що визначення макросів складніші за визначення функцій, тому що ви пишете код Rust, який пише код Rust. Через цю непрямість визначення макросів загалом важче читати, розуміти й підтримувати, ніж визначення функцій.
Ще одна важлива різниця між макросами та функціями полягає в тому, що ви маєте визначити макроси або імпортувати їх у область видимості до того, як ви викличете їх у файлі, на відміну від функцій, які ви можете визначити будь-де і викликати будь-де.
Декларативні макроси для загального метапрограмування
Найпоширенішою формою макросів у Rust є декларативний макрос. Їх також іноді називають “macros by example”, “macro_rules! macros,”
або просто “macros.” У своїй основі декларативні макроси дають змогу писати
щось подібне до виразу Rust match. Як обговорювалося в Главі 6,
вирази match — це керувальні структури, які приймають вираз, порівнюють
результатний значення виразу зі зразками, а потім виконують код, пов’язаний
із відповідним зразком. Макроси також порівнюють значення зі зразками, які
пов’язані з певним кодом: У цій ситуації значенням є буквальний вихідний код Rust, переданий
макросу; зразки порівнюються зі структурою цього вихідного коду; а код, пов’язаний
із кожним зразком, коли він збігається, замінює код, переданий макросу. Усе це відбувається під час
компіляції.
Щоб визначити макрос, ви використовуєте конструкцію macro_rules!. Дослідимо, як
використовувати macro_rules!, розглянувши, як визначено макрос vec!. У Главі 8
було описано, як ми можемо використовувати макрос vec! для створення нового вектора з певними значеннями.
Наприклад, такий макрос створює новий вектор, що містить три
цілі числа:
#![allow(unused)]
fn main() {
let v: Vec<u32> = vec![1, 2, 3];
}Ми також могли б використовувати макрос vec!, щоб створити вектор із двох цілих чисел або вектор
із п’яти рядкових зрізів. Ми не змогли б використати функцію для того самого,
тому що наперед ми не знали б кількість або тип значень.
Список 20-35 показує дещо спрощене визначення макросу vec!.
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}Примітка: Справжнє визначення макросу
vec!у стандартній бібліотеці містить код для попереднього виділення правильної кількості пам’яті наперед. Цей код є оптимізацією, яку ми тут не включаємо, щоб зробити приклад простішим.
Позначка #[macro_export] вказує, що цей макрос має бути
доступним щоразу, коли крейт, у якому визначено макрос, потрапляє в область видимості.
Без цієї позначки макрос не можна імпортувати в область видимості.
Потім ми починаємо визначення макросу з macro_rules! і назви
макросу, який ми визначаємо, без знака оклику. За назвою, у цьому випадку
vec, ідуть фігурні дужки, що позначають тіло визначення макросу.
Структура в тілі vec! подібна до структури виразу match.
Тут у нас є одна гілка зі зразком ( $( $x:expr ),* ),
за якою слідує => і блок коду, пов’язаний із цим зразком. Якщо
зразок збігається, пов’язаний блок коду буде згенерований. Оскільки це
єдиний зразок у цьому макросі, існує лише один дійсний спосіб зіставлення; будь-який
інший зразок призведе до помилки. Більш складні макроси матимуть більше ніж
одну гілку.
Синтаксис допустимих зразків у визначеннях макросів відрізняється від синтаксису зразків, розглянутого в Главі 19, тому що зразки макросів зіставляються зі структурою коду Rust, а не зі значеннями. Давайте розберемо, що означають елементи зразка в Списку 20-29; для повного синтаксису зразків макросів див. Rust Reference.
Спочатку ми використовуємо набір круглих дужок, щоб охопити весь зразок. Ми використовуємо
знак долара ($), щоб оголосити змінну в системі макросів, яка міститиме
код Rust, що відповідає зразку. Знак долара чітко показує, що це
змінна макросу, на відміну від звичайної змінної Rust. Далі йде набір
круглих дужок, який захоплює значення, що відповідають зразку всередині дужок,
для використання в коді заміни. Усередині $() міститься $x:expr, який відповідає будь-якому
виразу Rust і дає виразу ім’я $x.
Кома після $() вказує, що між кожним екземпляром коду, який відповідає коду в $(),
має з’являтися буквальний символ коми-роздільника.
* визначає, що зразок відповідає нулю або більше будь-чого, що стоїть
перед *.
Коли ми викликаємо цей макрос із vec![1, 2, 3];, зразок $x
збігається тричі з трьома виразами 1, 2 і 3.
Тепер подивімося на зразок у тілі коду, пов’язаного з цією гілкою:
temp_vec.push() у межах $()* генерується для кожної частини, що відповідає $()
у зразку, нуль або більше разів залежно від того, скільки разів
зразок збігається. $x замінюється кожним зіставленим виразом. Коли ми викликаємо цей
макрос із vec![1, 2, 3];, згенерований код, який замінює цей виклик
макросу, буде таким:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}Ми визначили макрос, який може приймати будь-яку кількість аргументів будь-якого типу і може генерувати код для створення вектора, що містить вказані елементи.
Щоб дізнатися більше про те, як писати макроси, зверніться до онлайн-документації або інших ресурсів, таких як “The Little Book of Rust Macros”, започаткованої Daniel Keep і продовженої Lukas Wirth.
Процедурні макроси для генерації коду з атрибутів
Друга форма макросів — це процедурний макрос, який поводиться більше як
функція (і є типом процедури). Процедурні макроси приймають певний код як вхідні дані,
опрацьовують цей код і видають певний код як вихідні дані замість
зіставлення зі зразками та заміни коду іншим кодом, як це роблять декларативні
макроси. Три види процедурних макросів — custom derive,
attribute-like і function-like, і всі працюють подібним чином.
Під час створення процедурних макросів визначення мають розташовуватися у власному крейті
зі спеціальним типом крейту. Це зумовлено складними технічними причинами, які ми сподіваємося
усунути в майбутньому. У Списку 20-36 ми показуємо, як визначити
процедурний макрос, де some_attribute є заповнювачем для використання конкретного
виду макросу.
use proc_macro::TokenStream;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}Функція, яка визначає процедурний макрос, приймає TokenStream як вхідні
дані та видає TokenStream як вихідні дані. Тип TokenStream визначено
крейтом proc_macro, який постачається разом із Rust і представляє послідовність
токенів. Це основа макросу: вихідний код, над яким макрос
працює, утворює вхідний TokenStream, а код, який макрос породжує,
є вихідним TokenStream. Функція також має прикріплений до неї атрибут,
який вказує, який саме вид процедурного макросу ми створюємо. У нас може бути
кілька видів процедурних макросів в одному крейті.
Давайте подивимося на різні види процедурних макросів. Ми почнемо з
custom derive макросу, а потім пояснимо невеликі відмінності, які роблять
інші форми іншими.
Як писати custom derive макрос
Створімо крейт під назвою hello_macro, який визначає трейт під назвою
HelloMacro з однією асоційованою функцією під назвою hello_macro. Замість того, щоб
змушувати наших користувачів реалізовувати трейт HelloMacro для кожного зі своїх типів,
ми надамо процедурний макрос, щоб користувачі могли анотувати свій тип за допомогою
#[derive(HelloMacro)], щоб отримати стандартну реалізацію
функції hello_macro. Стандартна реалізація виводитиме Hello, Macro! My name is TypeName!, де TypeName — це назва типу, на якому було
визначено цей трейт. Іншими словами, ми напишемо крейт, який дає змогу іншому
програмісту писати код на кшталт Списку 20-37, використовуючи наш крейт.
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}Коли ми закінчимо, цей код виводитиме Hello, Macro! My name is Pancakes!. Перший
крок — створити новий бібліотечний крейт ось так:
$ cargo new hello_macro --lib
Далі, у Списку 20-38, ми визначимо трейт HelloMacro і його асоційовану
функцію.
pub trait HelloMacro {
fn hello_macro();
}У нас є трейт і його функція. На цьому етапі користувач нашого крейту міг би реалізувати цей трейт, щоб досягти бажаної функціональності, як у Списку 20-39.
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}Однак їм довелося б писати блок реалізації для кожного типу, який вони
хотіли б використовувати з hello_macro; ми хочемо позбавити їх від необхідності робити
цю роботу.
Крім того, ми ще не можемо надати функції hello_macro стандартну
реалізацію, яка виводитиме ім’я типу, на якому реалізовано
трейт: Rust не має можливостей рефлексії, тому він не може дізнатися ім’я типу під час виконання. Нам потрібен макрос, щоб генерувати код під час компіляції.
Наступний крок — визначити процедурний макрос. На момент написання цього тексту
процедурні макроси мають бути у власному крейті. Згодом це
обмеження може бути зняте. Домовленість щодо структурування крейтів і крейтів макросів така:
для крейту з назвою foo custom derive процедурний макрокрейт називається foo_derive.
Почнімо новий крейт під назвою hello_macro_derive усередині нашого проєкту hello_macro:
$ cargo new hello_macro_derive --lib
Наші два крейти тісно пов’язані, тому ми створюємо крейт процедурного макросу
всередині каталогу нашого крейту hello_macro. Якщо ми змінимо визначення трейту
в hello_macro, нам доведеться змінити й реалізацію
процедурного макросу в hello_macro_derive. Ці два крейти доведеться
публікувати окремо, і програмістам, які використовують ці крейти, потрібно буде додати
обидва як залежності та імпортувати їх обидва в область видимості. Замість цього ми могли б зробити так, щоб
крейт hello_macro використовував hello_macro_derive як залежність і повторно експортував
код процедурного макросу. Однак те, як ми структурували проєкт, дає змогу програмістам використовувати
hello_macro, навіть якщо їм не потрібна функціональність derive.
Нам потрібно оголосити крейт hello_macro_derive як крейт процедурного макросу.
Нам також знадобиться функціональність із крейтів syn і quote, як ви скоро побачите,
тому нам потрібно додати їх як залежності. Додайте таке до файлу
Cargo.toml для hello_macro_derive:
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
Щоб почати визначати процедурний макрос, помістіть код зі Списку 20-40 у
ваш файл src/lib.rs для крейту hello_macro_derive. Зверніть увагу, що цей код не
скомпілюється, доки ми не додамо визначення функції impl_hello_macro.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implementation.
impl_hello_macro(&ast)
}Зверніть увагу, що ми розділили код на функцію hello_macro_derive, яка
відповідає за розбір TokenStream, і функцію impl_hello_macro, яка
відповідає за перетворення синтаксичного дерева: це робить написання процедурного макросу
зручнішим. Код у зовнішній функції (у цьому випадку hello_macro_derive) буде таким самим майже для кожного
крейту процедурного макросу, який ви побачите або створите. Код, який ви вкажете в тілі
внутрішньої функції (у цьому випадку impl_hello_macro), буде іншим
залежно від призначення вашого процедурного макросу.
Ми ввели три нові крейти: proc_macro, syn,
і quote. Крейт proc_macro постачається разом із Rust,
тому нам не потрібно було додавати його до залежностей у Cargo.toml.
Крейт proc_macro — це API компілятора, яке дає нам змогу читати та змінювати
код Rust з нашого коду.
Крейт syn розбирає код Rust із рядка в структуру даних, над якою ми
можемо виконувати операції. Крейт quote перетворює структури даних syn назад
у код Rust. Ці крейти значно спрощують розбір будь-якого виду коду Rust, з яким
ми могли б захотіти працювати: написання повного парсера для коду Rust — це нелегка
задача.
Функцію hello_macro_derive буде викликано, коли користувач нашої бібліотеки
зазначить #[derive(HelloMacro)] на типі. Це можливо, тому що ми
анотували функцію hello_macro_derive тут за допомогою proc_macro_derive і
вказали ім’я HelloMacro, яке збігається з назвою нашого трейту; це
конвенція, якої дотримується більшість процедурних макросів.
Функція hello_macro_derive спершу перетворює input з
TokenStream на структуру даних, яку ми потім можемо інтерпретувати й виконувати над нею
операції. Саме тут у гру вступає syn. Функція parse у
syn приймає TokenStream і повертає структуру DeriveInput, що представляє
розібраний код Rust. Список 20-41 показує відповідні частини структури DeriveInput,
яку ми отримуємо під час розбору рядка struct Pancakes;.
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}Поля цієї структури показують, що розібраний нами код Rust є unit-структурою
з ident (identifier, тобто ім’ям) Pancakes. У цій структурі є ще поля
для опису всіх видів коду Rust; для отримання додаткової інформації див. syn
документацію для DeriveInput.
Незабаром ми визначимо функцію impl_hello_macro, де ми побудуємо
новий код Rust, який хочемо включити. Але перед тим, як це зробити, зауважте, що вихід
нашого макросу derive також є TokenStream. Повернений TokenStream додається
до коду, який пишуть користувачі нашого крейту, тож коли вони компілюватимуть свій крейт,
вони отримають додаткову функціональність, яку ми надаємо в зміненому
TokenStream.
Ви могли помітити, що ми викликаємо unwrap, щоб викликати паніку у функції
hello_macro_derive, якщо тут не вдасться викликати функцію syn::parse. Для нашого процедурного макросу
необхідно викликати паніку при помилках, тому що
функції proc_macro_derive мають повертати TokenStream, а не Result, щоб
відповідати API процедурного макросу. Ми спростили цей приклад, використовуючи
unwrap; у production-коді вам слід надавати точніші повідомлення про помилку
щодо того, що пішло не так, використовуючи panic! або expect.
Тепер, коли ми маємо код, щоб перетворювати анотований код Rust із TokenStream
на екземпляр DeriveInput, згенеруємо код, який реалізує
трейт HelloMacro для анотованого типу, як показано в Списку 20-42.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
generated.into()
}Ми отримуємо екземпляр структури Ident, що містить ім’я (identifier) анотованого типу, використовуючи ast.ident.
Структура в Списку 20-41 показує, що коли ми запустимо функцію
impl_hello_macro на коді зі Списку 20-37, отриманий ident матиме поле ident
зі значенням "Pancakes". Отже,
змінна name у Списку 20-42 міститиме екземпляр структури Ident,
який, коли його буде надруковано, стане рядком "Pancakes", назвою структури в
Списку 20-37.
Макрос quote! дає змогу нам визначити код Rust, який ми хочемо повернути. Компілятор очікує
дещо інше, ніж прямий результат виконання макросу quote!, тому нам потрібно
перетворити його на TokenStream. Ми робимо це, викликаючи метод into, який
споживає це проміжне представлення і повертає значення потрібного типу TokenStream.
Макрос quote! також надає дуже зручні механізми шаблонізації: Ми можемо
вставити #name, і quote! замінить його значенням у змінній
name. Ви навіть можете робити певні повторення, подібні до того, як працюють звичайні макроси.
Зазирніть у документацію крейту quote для докладного вступу.
Ми хочемо, щоб наш процедурний макрос генерував реалізацію нашого трейту HelloMacro
для типу, який анотував користувач, що ми можемо отримати, використавши #name. Реалізація трейту має одну функцію hello_macro, тіло якої містить
функціональність, яку ми хочемо надати: виведення Hello, Macro! My name is, а потім
ім’я анотованого типу.
Макрос stringify!, використаний тут, вбудований у Rust. Він бере
вираз Rust, наприклад 1 + 2, і під час компіляції перетворює вираз на
рядковий літерал, наприклад "1 + 2". Це відрізняється від format! або
println!, які є макросами, що обчислюють вираз, а потім перетворюють
результат на String. Існує ймовірність, що вхід #name може
бути виразом, який слід надрукувати буквально, тому ми використовуємо stringify!.
Використання stringify! також заощаджує виділення пам’яті, перетворюючи #name на рядковий літерал під час компіляції.
На цьому етапі cargo build має успішно завершитися і в hello_macro,
і в hello_macro_derive. Давайте під’єднаємо ці крейти до коду в Списку
20-37, щоб побачити процедурний макрос у дії! Створіть новий бінарний проєкт у
вашому каталозі projects за допомогою cargo new pancakes. Нам потрібно додати
hello_macro і hello_macro_derive як залежності в Cargo.toml крейту
pancakes. Якщо ви публікуєте свої версії hello_macro і
hello_macro_derive на crates.io, вони
були б звичайними залежностями; якщо ні, ви можете вказати їх як
path-залежності так:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Помістіть код зі Списку 20-37 у src/main.rs і запустіть cargo run: Це
має вивести Hello, Macro! My name is Pancakes!. Реалізація
трейту HelloMacro з процедурного макросу була включена без того, щоб
крейт pancakes мав реалізовувати її сам; #[derive(HelloMacro)] додав
реалізацію трейту.
Далі давайте дослідимо, чим інші види процедурних макросів відрізняються від custom
derive макросів.
Макроси, схожі на атрибути
Макроси, схожі на атрибути, подібні до custom derive макросів, але замість
генерування коду для атрибута derive вони дають змогу створювати нові
атрибути. Вони також гнучкіші: derive працює лише для структур і
переліків; атрибути можна застосовувати й до інших items, таких як функції.
Ось приклад використання макросу, схожого на атрибут. Припустімо, у вас є атрибут
під назвою route, який анотує функції під час використання вебфреймворку:
#[route(GET, "/")]
fn index() {Цей атрибут #[route] буде визначено фреймворком як процедурний
макрос. Сигнатура функції визначення макросу виглядала б так:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Тут у нас є два параметри типу TokenStream. Перший призначений для
вмісту атрибута: частина GET, "/". Другий — для тіла item, до якого
прикріплено атрибут: у цьому випадку fn index() {} і решта
тіла функції.
Крім цього, макроси, схожі на атрибути, працюють так само, як custom derive
макроси: Ви створюєте крейт з типом крейту proc-macro і реалізуєте
функцію, яка генерує код, який ви хочете!
Макроси, схожі на функції
Макроси, схожі на функції, визначають макроси, які виглядають як виклики функцій.
Подібно до макросів macro_rules!, вони гнучкіші за функції; наприклад, вони
можуть приймати невідому кількість аргументів. Однак макроси macro_rules! можуть
бути визначені лише за допомогою синтаксису, схожого на match, який ми обговорювали в розділі “Декларативні
макроси для загального метапрограмування” раніше.
Макроси, схожі на функції, приймають параметр TokenStream, і їхнє визначення
змінює цей TokenStream за допомогою коду Rust, як і дві інші форми
процедурних макросів. Прикладом макросу, схожого на функцію, є макрос sql!, який
можна викликати так:
let sql = sql!(SELECT * FROM posts WHERE id=1);Цей макрос розбере SQL-оператор усередині себе і перевірить, що він
синтаксично правильний, що є набагато складнішим обробленням, ніж може зробити
макрос macro_rules!. Макрос sql! було б визначено так:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {Це визначення подібне до сигнатури custom derive макросу: Ми отримуємо
токени, що містяться в дужках, і повертаємо код, який хотіли
згенерувати.
Підсумок
Ух! Тепер у вас є в наборі інструментів деякі можливості Rust, які ви, ймовірно, не використовуватимете часто, але знатимете, що вони доступні за дуже певних обставин. Ми представили кілька складних тем, щоб, коли ви натрапите на них у підказках до повідомлень про помилки або в коді інших людей, ви могли розпізнати ці концепції та синтаксис. Використовуйте цю главу як довідник, щоб спрямувати себе до рішень.
Далі ми застосуємо на практиці все, про що говорили протягом усієї книги, і зробимо ще один проєкт!
Фінальний проєкт: Створення багатопотокового вебсервера
Це була довга подорож, але ми дісталися кінця книги. У цьому розділі ми разом побудуємо ще один проєкт, щоб продемонструвати деякі з концепцій, які ми розглядали в останніх розділах, а також повторити деякі раніші уроки.
Для нашого фінального проєкту ми створимо вебсервер, який говорить “Hello!” і виглядає як рисунок 21-1 у веббраузері.
Ось наш план створення вебсервера:
- Дізнатися трохи про TCP і HTTP.
- Приймати TCP-з’єднання на сокеті.
- Розібрати невелику кількість HTTP-запитів.
- Створити правильну HTTP-відповідь.
- Покращити пропускну здатність нашого сервера за допомогою пулу потоків.
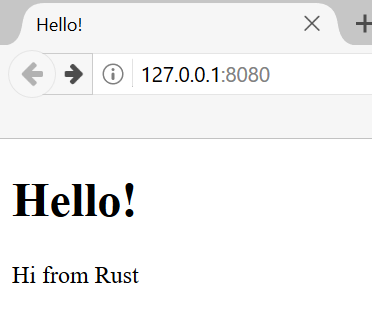
Рисунок 21-1: Наш фінальний спільний проєкт
Перш ніж ми почнемо, слід згадати дві деталі. По-перше, метод, який ми використаємо, не буде найкращим способом побудувати вебсервер за допомогою Rust. Члени спільноти опублікували чимало готових до використання крейтів, доступних на crates.io, які надають більш повні реалізації вебсервера та пулу потоків, ніж ті, які ми побудуємо. Однак наш намір у цьому розділі — допомогти вам навчитися, а не обирати найлегший шлях. Оскільки Rust — це мова системного програмування, ми можемо обирати рівень абстракції, з яким хочемо працювати, і можемо перейти на нижчий рівень, ніж це можливо або практично в інших мовах.
По-друге, тут ми не будемо використовувати async і await. Створення пулу потоків — це і так достатньо складний виклик сам по собі, без додаткового створення async runtime! Однак ми зазначимо, як async і await можуть бути застосовні до деяких із тих самих проблем, які ми побачимо в цьому розділі. Зрештою, як ми зазначали ще в розділі 17, багато async runtime використовують пули потоків для керування своєю роботою.
Тому ми вручну напишемо базовий HTTP-сервер і пул потоків, щоб ви могли дізнатися загальні ідеї та техніки, що лежать в основі крейтів, які ви, можливо, використовуватимете в майбутньому.
Створення однопотокового вебсервера
Побудова однопотокового веб-сервера
Ми почнемо з того, що запустимо однопотоковий веб-сервер. Перш ніж ми почнемо, давайте подивимося на короткий огляд протоколів, що беруть участь у побудові веб серверів. Деталі цих протоколів виходять за межі цієї книги, але короткий огляд дасть вам інформацію, яка вам потрібна.
Два основні протоколи, що беруть участь у веб-серверах, — це Hypertext Transfer Protocol (HTTP) і Transmission Control Protocol (TCP). Обидва протоколи є request-response протоколами, що означає, що client ініціює запити, а server слухає запити та надає відповідь клієнту. Зміст цих запитів і відповідей визначається протоколами.
TCP — це протокол нижчого рівня, який описує деталі того, як інформація потрапляє з одного сервера до іншого, але не визначає, що саме є цією інформацією. HTTP будується поверх TCP, визначаючи вміст запитів і відповідей. Технічно можливо використовувати HTTP з іншими протоколами, але в переважній більшості випадків HTTP надсилає свої дані поверх TCP. Ми працюватимемо з сирими байтами TCP та HTTP-запитів і відповідей.
Прослуховування TCP-з’єднання
Нашому веб-серверу потрібно слухати TCP-з’єднання, тож це перша частина, над якою
ми працюватимемо. Стандартна бібліотека пропонує модуль std::net, який дає нам
змогу це зробити. Створімо новий проєкт звичним способом:
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
Тепер введіть код у Listing 21-1 у src/main.rs, щоб почати. Цей код
слухатиме локальну адресу 127.0.0.1:7878 на вхідні TCP-потоки. Коли він
отримає вхідний потік, він виведе Connection established!.
use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
println!("Connection established!");
}
}Використовуючи TcpListener, ми можемо слухати TCP-з’єднання за адресою
127.0.0.1:7878. В адресі частина перед двокрапкою — це IP-адреса,
що представляє ваш комп’ютер (це однаково на кожному комп’ютері й не
представляє комп’ютер авторів конкретно), а 7878 — це порт. Ми вибрали цей
порт із двох причин: HTTP зазвичай не приймається на цьому порту, тож наш сервер
малоймовірно конфліктуватиме з будь-яким іншим веб-сервером, який ви можете
запустити на вашій машині, а 7878 — це rust, набране на телефоні.
Функція bind у цьому сценарії працює як функція new у тому сенсі, що вона
поверне новий екземпляр TcpListener. Функція називається bind
тому, що в мережевому програмуванні з’єднання з портом для прослуховування відоме
як “binding to a port”.
Функція bind повертає Result<T, E>, що вказує на те, що
прив’язування може завершитися невдало, наприклад, якщо ми запустили два
екземпляри нашої програми і, отже, мали дві програми, що слухають той самий порт.
Оскільки ми пишемо базовий сервер лише з навчальною метою, ми не
турбуватимемось обробкою таких помилок; натомість ми використовуємо unwrap, щоб
зупинити програму, якщо виникнуть помилки.
Метод incoming на TcpListener повертає ітератор, який дає нам
послідовність потоків (точніше, потоків типу TcpStream). Один
потік представляє відкрите з’єднання між клієнтом і сервером.
З’єднання — це назва для повного процесу запиту й відповіді, у якому
клієнт під’єднується до сервера, сервер генерує відповідь, а сервер
закриває з’єднання. Таким чином, ми читатимемо з TcpStream, щоб побачити, що
клієнт надіслав, а потім записуватимемо нашу відповідь у потік, щоб надіслати дані назад
клієнту. Загалом, цей цикл for оброблятиме кожне з’єднання по черзі й
створюватиме для нас серію потоків для обробки.
Наразі наша обробка потоку полягає у виклику unwrap, щоб завершити
нашу програму, якщо потік має будь-які помилки; якщо помилок немає, програма
виводить повідомлення. Ми додамо більше функціональності для успішного випадку в
наступному фрагменті. Причина, через яку ми можемо отримати помилки від методу
incoming, коли клієнт під’єднується до сервера, полягає в тому, що ми насправді не
ітеруємося по з’єднаннях. Натомість ми ітеруємося по спробах під’єднання.
З’єднання може не вдатися з багатьох причин, багато з яких є
специфічними для операційної системи. Наприклад, багато операційних систем мають обмеження на
кількість одночасно відкритих з’єднань, які вони можуть підтримувати; нові спроби
під’єднання понад цю кількість спричинять помилку, доки деякі з відкритих
з’єднань не буде закрито.
Спробуймо запустити цей код! Викличте cargo run у терміналі, а потім відкрийте
127.0.0.1:7878 у веб-браузері. Браузер має показати повідомлення про помилку,
наприклад “Connection reset”, тому що сервер наразі не надсилає жодних
даних. Але коли ви подивитеся на свій термінал, ви маєте побачити кілька повідомлень,
які були виведені, коли браузер під’єднався до сервера!
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
Іноді ви побачите кілька повідомлень, виведених для одного запиту браузера; причина може полягати в тому, що браузер робить запит на сторінку, а також запит на інші ресурси, як-от піктограму favicon.ico, що з’являється у вкладці браузера.
Також може бути, що браузер намагається під’єднатися до сервера кілька
разів, тому що сервер не відповідає жодними даними. Коли stream виходить
за межі видимості й видаляється в кінці циклу, з’єднання закривається як
частина реалізації drop. Браузери іноді поводяться із закритими
з’єднаннями, повторюючи спробу, тому що проблема може бути тимчасовою.
Браузери також іноді відкривають кілька з’єднань із сервером без надсилання жодних запитів, щоб якщо вони дійсно пізніше надішлють запити, ці запити могли відбутися швидше. Коли це стається, наш сервер бачитиме кожне з’єднання, незалежно від того, чи є якісь запити через це з’єднання. Багато версій браузерів на базі Chrome, наприклад, роблять це; ви можете вимкнути цю оптимізацію, використовуючи режим приватного перегляду або інший браузер.
Важливим є те, що ми успішно отримали доступ до TCP-з’єднання!
Не забудьте зупинити програму, натиснувши ctrl-C, коли
завершите роботу з конкретною версією коду. Потім перезапустіть програму,
викликавши команду cargo run після кожного набору змін коду, щоб
переконатися, що ви запускаєте найновіший код.
Читання запиту
Давайте реалізуємо функціональність для читання запиту з браузера! Щоб
розділити завдання спершу отримання з’єднання, а потім виконання певної дії
з цим з’єднанням, ми створимо нову функцію для обробки з’єднань. У цій
новій функції handle_connection ми читатимемо дані з TCP-потоку й
виводитимемо їх, щоб бачити дані, які надсилаються з браузера. Змініть
код так, щоб він виглядав як Listing 21-2.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
println!("Request: {http_request:#?}");
}Ми додаємо std::io::BufReader і std::io::prelude в область видимості, щоб отримати доступ
до трейтов і типів, які дають нам змогу читати з потоку й записувати в нього. У циклі for
у функції main, замість виведення повідомлення про те, що ми встановили
з’єднання, ми тепер викликаємо нову функцію handle_connection і передаємо їй
stream.
У функції handle_connection ми створюємо новий екземпляр BufReader, який
обгортає посилання на stream. BufReader додає буферизацію, керуючи
викликами методів трейта std::io::Read за нас.
Ми створюємо змінну з назвою http_request, щоб зібрати рядки запиту,
які браузер надсилає нашому серверу. Ми вказуємо, що хочемо зібрати ці
рядки у вектор, додаючи анотацію типу Vec<_>.
BufReader реалізує трейт std::io::BufRead, який надає метод
lines. Метод lines повертає ітератор Result<String, std::io::Error>, розбиваючи потік даних щоразу, коли бачить байт нового рядка.
Щоб отримати кожен String, ми map і unwrap кожен Result. Result
може бути помилкою, якщо дані не є дійсним UTF-8 або якщо виникла проблема
під час читання з потоку. Знову ж таки, виробнича програма мала б обробляти ці помилки
плавніше, але ми обираємо зупиняти програму в разі помилки заради
простоти.
Браузер сигналізує про кінець HTTP-запиту, надсилаючи два символи нового рядка підряд, тож щоб отримати один запит із потоку, ми беремо рядки, доки не отримаємо рядок, що є порожнім рядком. Після того як ми зібрали рядки у вектор, ми виводимо їх, використовуючи гарне форматування налагодження, щоб поглянути на інструкції, які веб-браузер надсилає нашому серверу.
Спробуймо цей код! Запустіть програму й зробіть запит у веб-браузері знову. Зверніть увагу, що ми все ще отримаємо сторінку помилки в браузері, але вивід нашої програми в терміналі тепер виглядатиме приблизно так:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
Залежно від вашого браузера, ви можете отримати дещо інший вивід. Тепер,
коли ми виводимо дані запиту, ми можемо побачити, чому отримуємо кілька з’єднань
з одного запиту браузера, подивившись на шлях після GET у першому рядку
запиту. Якщо повторні з’єднання всі запитують /, ми знаємо, що браузер
намагається багаторазово отримати / , тому що не отримує відповіді
від нашої програми.
Розберімо ці дані запиту, щоб зрозуміти, що браузер просить у нашої програми.
Дивлячись ближче на HTTP-запит
HTTP — це текстовий протокол, і запит має такий формат:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
Перший рядок — це рядок запиту, який містить інформацію про те, що
клієнт запитує. Перша частина рядка запиту вказує метод,
що використовується, наприклад GET або POST, який описує, як клієнт робить
цей запит. Наш клієнт використав запит GET, що означає, що він запитує
інформацію.
Наступна частина рядка запиту — це /, що вказує на уніфікований ідентифікатор ресурсу (URI), який запитує клієнт: URI майже, але не зовсім, те саме, що й уніфікований локатор ресурсу (URL). Різниця між URI та URL не є важливою для наших цілей у цьому розділі, але специфікація HTTP використовує термін URI, тож ми можемо просто подумки підставляти URL замість URI тут.
Остання частина — це версія HTTP, яку використовує клієнт, а потім рядок запиту
закінчується послідовністю CRLF. (CRLF означає carriage return і
line feed, які є термінами з часів друкарських машинок!) Послідовність CRLF також може бути
записана як \r\n, де \r — це carriage return, а \n — line feed. Послідовність CRLF
відокремлює рядок запиту від решти даних запиту.
Зверніть увагу: коли CRLF виводиться, ми бачимо початок нового рядка, а не \r\n.
Дивлячись на дані рядка запиту, які ми отримали, запускаючи нашу програму досі,
ми бачимо, що GET — це метод, / — це URI запиту, а HTTP/1.1 — це
версія.
Після рядка запиту решта рядків, починаючи з Host:, є
заголовками. Запити GET не мають тіла.
Спробуйте зробити запит з іншого браузера або попросити іншу адресу, таку як 127.0.0.1:7878/test, щоб побачити, як змінюються дані запиту.
Тепер, коли ми знаємо, чого браузер просить, давайте надішлемо назад трохи даних!
Запис відповіді
Ми збираємося реалізувати надсилання даних у відповідь на запит клієнта. Відповіді мають такий формат:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
Перший рядок — це рядок статусу, який містить версію HTTP, використану у відповіді, числовий код статусу, що підсумовує результат запиту, і фразу причини, яка надає текстовий опис коду статусу. Після послідовності CRLF ідуть будь-які заголовки, ще одна послідовність CRLF і тіло відповіді.
Ось приклад відповіді, яка використовує версію HTTP 1.1 і має код статусу 200, фразу причини OK, без заголовків і без тіла:
HTTP/1.1 200 OK\r\n\r\n
Код статусу 200 — це стандартна відповідь про успіх. Текст — це крихітна
успішна HTTP-відповідь. Давайте запишемо її у потік як нашу відповідь на
успішний запит! У функції handle_connection приберіть
println!, який виводив дані запиту, і замініть його кодом із
Listing 21-3.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let response = "HTTP/1.1 200 OK\r\n\r\n";
stream.write_all(response.as_bytes()).unwrap();
}Перший новий рядок визначає змінну response, яка містить дані
повідомлення про успіх. Потім ми викликаємо as_bytes на нашій response, щоб
перетворити рядкові дані на байти. Метод write_all на stream
приймає &[u8] і надсилає ці байти безпосередньо через з’єднання. Оскільки операція
write_all може завершитися невдало, ми використовуємо unwrap для будь-якого результату помилки, як і раніше.
Знову ж таки, у реальній програмі ви додали б тут обробку помилок.
З цими змінами запустімо наш код і зробімо запит. Ми більше не виводимо жодних даних у термінал, тож не побачимо жодного виводу, окрім виводу від Cargo. Коли ви відкриєте 127.0.0.1:7878 у веб-браузері, ви маєте отримати порожню сторінку замість помилки. Ви щойно вручну закодували отримання HTTP запиту і надсилання відповіді!
Повернення справжнього HTML
Давайте реалізуємо функціональність повернення чогось більшого, ніж порожня сторінка. Створіть новий файл hello.html у корені каталогу вашого проєкту, а не в каталозі src. Ви можете ввести будь-який HTML, який хочете; Listing 21-4 показує один можливий варіант.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
Це мінімальний HTML5-документ із заголовком і деяким текстом. Щоб повернути
його із сервера, коли отримано запит, ми змінимо handle_connection, як
показано в Listing 21-5, щоб прочитати HTML-файл, додати його до відповіді як тіло
і надіслати його.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Ми додали fs до оператора use, щоб увімкнути модуль файлової системи стандартної
бібліотеки в область видимості. Код для читання вмісту файла в
рядок має виглядати знайомо; ми використовували його, коли читали вміст файла для
нашого проєкту I/O у Listing 12-4.
Далі ми використовуємо format!, щоб додати вміст файла як тіло
успішної відповіді. Щоб забезпечити коректну HTTP-відповідь, ми додаємо заголовок
Content-Length, який встановлюється в розмір нашого тіла відповіді — у цьому випадку, у
розмір hello.html.
Запустіть цей код за допомогою cargo run і відкрийте 127.0.0.1:7878 у вашому браузері; ви
маєте побачити відтворений HTML!
Наразі ми ігноруємо дані запиту в http_request і просто
безумовно надсилаємо назад вміст HTML-файлу. Це означає, що якщо ви спробуєте
запросити 127.0.0.1:7878/something-else у вашому браузері, ви все одно
отримаєте назад цю саму HTML-відповідь. На даний момент наш сервер дуже обмежений і
не робить того, що роблять більшість веб-серверів. Ми хочемо налаштовувати наші відповіді
залежно від запиту й надсилати назад HTML-файл лише для правильно сформованого
запиту до /.
Перевірка запиту та вибіркова відповідь
Зараз наш веб-сервер повертатиме HTML у файлі незалежно від того, що
запитував клієнт. Додаймо функціональність, щоб перевіряти, що браузер
запитує / перед поверненням HTML-файлу, і повертати помилку, якщо
браузер запитує щось інше. Для цього нам потрібно змінити handle_connection,
як показано в Listing 21-6. Цей новий код перевіряє вміст отриманого
запиту на відповідність тому, як ми знаємо, виглядає запит до / , і додає блоки if та
else, щоб поводитися з запитами по-різному.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
} else {
// some other request
}
}Ми будемо дивитися лише на перший рядок HTTP-запиту, тож замість
читання всього запиту у вектор ми викликаємо next, щоб отримати
перший елемент з ітератора. Перший unwrap обробляє Option і
зупиняє програму, якщо ітератор не має елементів. Другий unwrap обробляє
Result і має той самий ефект, що й unwrap, який був у map, доданому в
Listing 21-2.
Далі ми перевіряємо request_line, щоб побачити, чи дорівнює він рядку запиту GET
до шляху / . Якщо так, блок if повертає вміст нашого
HTML-файлу.
Якщо request_line не дорівнює запиту GET до шляху / , це
означає, що ми отримали якийсь інший запит. Ми додамо код до блоку else за мить, щоб реагувати на всі інші запити.
Запустіть цей код зараз і зробіть запит до 127.0.0.1:7878; ви маєте отримати HTML із hello.html. Якщо ви зробите будь-який інший запит, наприклад 127.0.0.1:7878/something-else, ви отримаєте помилку з’єднання, як ті, які ви бачили під час запуску коду в Listing 21-1 і Listing 21-2.
Тепер додаймо код із Listing 21-7 до блоку else, щоб повертати відповідь
зі статус-кодом 404, який сигналізує, що вміст для запиту
не знайдено. Ми також повернемо деякий HTML для сторінки, яка відображатиметься в браузері,
щоб показати відповідь кінцевому користувачу.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
// --snip--
} else {
let status_line = "HTTP/1.1 404 NOT FOUND";
let contents = fs::read_to_string("404.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
}
}Тут наша відповідь має рядок статусу зі статус-кодом 404 і фразою причини
NOT FOUND. Тіло відповіді буде HTML у файлі 404.html.
Вам потрібно створити файл 404.html поруч із hello.html для сторінки помилки;
знову ж таки, ви можете використати будь-який HTML, який хочете, або скористатися прикладом HTML у
Listing 21-8.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
З цими змінами знову запустіть ваш сервер. Запит до 127.0.0.1:7878 має повернути вміст hello.html, а будь-який інший запит, як-от 127.0.0.1:7878/foo, має повернути HTML помилки з 404.html.
Рефакторинг
Наразі блоки if і else мають багато повторень: Вони
обидва читають файли й записують вміст файлів у потік. Єдина
відмінність — це рядок статусу та ім’я файла. Давайте зробимо код більш
лаконічним, винісши ці відмінності в окремі рядки if і else,
які призначатимуть значення рядка статусу та імені файла змінним;
потім ми можемо безумовно використовувати ці змінні в коді для читання файла
й запису відповіді. Listing 21-9 показує отриманий код після заміни
великих блоків if і else.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = if request_line == "GET / HTTP/1.1" {
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Тепер блоки if і else лише повертають відповідні значення для
рядка статусу та імені файла у вигляді кортежу; потім ми використовуємо деструктуризацію, щоб присвоїти ці
два значення status_line і filename, використовуючи шаблон у
операторі let, як обговорювалося в Розділі 19.
Код, що раніше дублювався, тепер знаходиться поза блоками if і else та
використовує змінні status_line і filename. Це полегшує побачити
різницю між двома випадками, і це означає, що в нас є лише одне місце, де можна
оновити код, якщо ми хочемо змінити те, як працюють читання файла та запис відповіді.
Поведінка коду в Listing 21-9 буде такою ж, як і в Listing 21-7.
Чудово! Тепер у нас є простий веб-сервер приблизно з 40 рядків коду Rust, який відповідає на один запит сторінкою з вмістом і відповідає на всі інші запити відповіддю 404.
Наразі наш сервер працює в одному потоці, що означає, що він може обслуговувати лише один запит за раз. Давайте розглянемо, як це може бути проблемою, симулюючи повільні запити. Потім ми виправимо це так, щоб наш сервер міг обробляти кілька запитів одночасно.
Від однопотокового до багатопотокового сервера
Від однопотокового до багатопотокового сервера
Наразі сервер оброблятиме кожен запит по черзі, тобто він не обробить друге з’єднання, доки не завершиться обробка першого з’єднання. Якби сервер отримував дедалі більше запитів, таке послідовне виконання ставало б дедалі менш оптимальним. Якщо сервер отримує запит, обробка якого займає багато часу, наступні запити мають чекати, доки довгий запит буде завершено, навіть якщо нові запити можна обробити швидко. Нам потрібно буде це виправити, але спочатку ми подивимося на проблему в дії.
Моделювання повільного запиту
Ми розглянемо, як повільно оброблюваний запит може вплинути на інші запити, зроблені до нашої поточної реалізації сервера. Лістинг 21-10 реалізує обробку запиту до /sleep із змодельованою повільною відповіддю, через що сервер буде спати п’ять секунд перед відповіддю.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
// --snip--
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Тепер, коли в нас є три випадки, ми перейшли з if до match. Нам потрібно
явно зіставляти зі зрізом request_line, щоб виконати зіставлення зі зразком
проти значень рядкового літерала; match не робить автоматичного
посилання та розіменування, як це робить метод equality.
Перша гілка така сама, як і блок if з Лістинга 21-9. Друга гілка
зіставляється із запитом до /sleep. Коли цей запит отримано, сервер буде
спати п’ять секунд перед рендерингом успішної HTML-сторінки. Третя гілка
така сама, як і блок else з Лістинга 21-9.
Ви можете побачити, наскільки примітивним є наш сервер: реальні бібліотеки обробляли б розпізнавання кількох запитів значно менш багатослівно!
Запустіть сервер за допомогою cargo run. Потім відкрийте два вікна
браузера: одне для http://127.0.0.1:7878, а інше для
http://127.0.0.1:7878/sleep. Якщо ви кілька разів введете URI /,
як і раніше, ви побачите, що він відповідає швидко. Але якщо ви введете
/sleep, а потім завантажите /, ви побачите, що / чекає, доки sleep
не проспить свої повні п’ять секунд перед завантаженням.
Є кілька технік, які ми могли б використати, щоб уникнути накопичення запитів за повільним запитом, зокрема використання async, як ми робили в Chapter 17; те, що ми реалізуємо, — це thread pool.
Покращення пропускної здатності за допомогою thread pool
Thread pool — це група запущених threads, які готові й чекають, щоб обробити task. Коли програма отримує новий task, вона призначає один із threads у pool для цього task, і цей thread оброблятиме task. Решта threads у pool доступні для обробки будь-яких інших tasks, що надходять, поки перший thread обробляє свій task. Коли перший thread завершує обробку свого task, його повертають до pool незайнятих threads, готових обробити новий task. Thread pool дає змогу обробляти з’єднання concurrently, збільшуючи throughput вашого сервера.
Ми обмежимо кількість threads у pool невеликою кількістю, щоб захиститися від DoS-атак; якби ми змусили нашу програму створювати новий thread для кожного запиту, щойно він надходить, хтось, хто надішле 10 мільйонів запитів до нашого сервера, міг би спричинити хаос, використавши всі ресурси нашого сервера й повністю зупинивши обробку запитів.
Отже, замість створення необмеженої кількості threads, у нас буде фіксована
кількість threads, що чекають у pool. Запити, які надходять, надсилаються до
pool на обробку. Pool підтримуватиме чергу вхідних запитів. Кожен із threads
у pool буде забирати запит із цієї черги, обробляти його, а потім просити
чергу надати інший запит. За такого дизайну ми можемо concurrently
обробляти до N запитів, де N — це кількість threads. Якщо кожен thread
відповідає на довготривалий запит, наступні запити все ще можуть накопичуватися
в черзі, але ми збільшили кількість довготривалих запитів, які можемо
обробити, перш ніж дійдемо до цього моменту.
Ця техніка — лише один із багатьох способів покращити throughput web server. Інші варіанти, які ви можете дослідити, — це модель fork/join, однопотокова модель async I/O та багатопотокова модель async I/O. Якщо вас цікава ця тема, ви можете прочитати більше про інші рішення і спробувати реалізувати їх; з низькорівневою мовою, такою як Rust, усі ці варіанти можливі.
Перш ніж ми почнемо реалізовувати thread pool, давайте поговоримо про те, як мало б виглядати використання pool. Коли ви намагаєтеся спроєктувати код, спочатку написання інтерфейсу клієнта може допомогти спрямувати ваш дизайн. Напишіть API коду так, щоб він був структурований у спосіб, у який ви хочете його викликати; потім реалізуйте функціональність усередині цієї структури, а не реалізовуйте функціональність, а потім проєктуйте public API.
Подібно до того, як ми використовували test-driven development у проєкті в Chapter 12, тут ми використовуватимемо compiler-driven development. Ми напишемо код, який викликає потрібні нам функції, а потім подивимося на помилки від компілятора, щоб визначити, що нам слід змінити далі, аби код запрацював. Однак перш ніж ми це зробимо, ми дослідимо техніку, яку не будемо використовувати, як відправну точку.
Запуск thread для кожного запиту
Спочатку давайте подивимося, як міг би виглядати наш код, якби він створював новий thread для кожного з’єднання. Як згадувалося раніше, це не наш кінцевий план через проблеми з потенційним створенням необмеженої кількості threads, але це відправна точка, щоб спочатку отримати працездатний багатопотоковий сервер. Потім ми додамо thread pool як покращення, і зіставляти ці два рішення буде простіше.
Лістинг 21-11 показує зміни до main, щоб запускати новий thread для
обробки кожного stream у циклі for.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Як ви дізналися в Chapter 16, thread::spawn створить новий thread, а потім
запустить код у замиканні в новому thread. Якщо ви запустите цей код і
завантажите /sleep у браузері, а потім / у двох інших вкладках браузера,
ви справді побачите, що запити до / не мають чекати, поки /sleep
завершиться. Однак, як ми згадували, це зрештою перевантажить систему, тому
що ви створюватимете нові threads без жодного обмеження.
Ви також можете згадати з Chapter 17, що це саме той тип ситуації, де async і await справді розкриваються! Пам’ятайте про це, коли ми будуватимемо thread pool і думатимемо про те, як усе виглядало б інакше або так само з async.
Створення подібного інтерфейсу для скінченної кількості threads
Ми хочемо, щоб наш thread pool працював подібним, звичним способом, щоб
перехід від threads до thread pool не вимагав великих змін у коді, який
використовує наш API. Лістинг 21-12 показує гіпотетичний інтерфейс для
структури ThreadPool, яку ми хочемо використовувати замість thread::spawn.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Ми використовуємо ThreadPool::new, щоб створити новий thread pool із
налаштовуваною кількістю threads, у цьому випадку чотири. Потім, у циклі
for, pool.execute має подібний інтерфейс до thread::spawn у тому, що
він приймає замикання, яке pool має запускати для кожного stream. Нам потрібно
реалізувати pool.execute так, щоб він приймав замикання і передавав його
thread у pool для виконання. Цей код ще не скомпілюється, але ми спробуємо,
щоб компілятор міг підказати нам, як це виправити.
Побудова ThreadPool за допомогою compiler-driven development
Внесіть зміни з Лістинга 21-12 до src/main.rs, а потім використаємо
помилки компілятора з cargo check, щоб спрямувати нашу розробку. Ось
перша помилка, яку ми отримуємо:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Чудово! Ця помилка повідомляє нам, що нам потрібен тип або модуль ThreadPool,
тому ми зараз його створимо. Наша реалізація ThreadPool буде незалежною від
того, яку саме роботу виконує наш web server. Отже, давайте перетворимо крейт
hello з binary crate на library crate, щоб зберігати нашу реалізацію
ThreadPool. Після переходу на library crate ми також могли б використовувати
окрему library thread pool для будь-якої роботи, яку захочемо виконувати за
допомогою thread pool, а не лише для обслуговування web requests.
Створіть файл src/lib.rs, який міститиме таке, — це найпростіше визначення
структури ThreadPool, яке ми поки що можемо мати:
pub struct ThreadPool;Потім відредагуйте файл main.rs, щоб імпортувати ThreadPool в область
видимості з library crate, додавши такий код на початок src/main.rs:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Цей код усе ще не працюватиме, але давайте перевіримо його знову, щоб отримати наступну помилку, яку нам потрібно виправити:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Ця помилка вказує, що наступним кроком нам потрібно створити асоційовану
функцію під назвою new для ThreadPool. Ми також знаємо, що new має
мати один параметр, який може приймати 4 як аргумент, і має повертати
екземпляр ThreadPool. Давайте реалізуємо найпростішу функцію new, яка
матиме ці характеристики:
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}Ми обрали usize як тип параметра size, тому що знаємо, що від’ємна
кількість threads не має жодного сенсу. Ми також знаємо, що використовуватимемо
це 4 як кількість елементів у колекції threads, а для цього і призначений
тип usize, як обговорювалося в розділі “Integer Types” у Chapter 3.
Давайте перевіримо код ще раз:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Тепер помилка виникає тому, що в нас немає методу execute на ThreadPool.
Згадайте з розділу “Створення подібного інтерфейсу для скінченної кількості
threads”, що ми вирішили, що наш thread pool має мати інтерфейс, подібний
до thread::spawn. Крім того, ми реалізуємо функцію execute так, щоб вона
приймала замикання, яке їй передають, і передавала його незайнятому thread
у pool для виконання.
Ми визначимо метод execute на ThreadPool, щоб він приймав замикання як
параметр. Згадайте з розділу [“Переміщення захоплених значень із замикань”]
moving-out-of-closures у Chapter 13, що ми можемо
приймати замикання як параметри за допомогою трьох різних трейтів: Fn,
FnMut і FnOnce. Нам потрібно вирішити, який саме тип замикання тут
використати. Ми знаємо, що зрештою зробимо щось подібне до стандартної
реалізації library thread::spawn, тож можемо подивитися, які обмеження має
сигнатура thread::spawn на свій параметр. Документація показує таке:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Параметр типу F — це той, який нас тут цікавить; параметр типу T
пов’язаний із значенням, що повертається, і він нас не цікавить. Ми бачимо,
що spawn використовує FnOnce як trait bound для F. Ймовірно, це саме
те, що ми хочемо і тут, тому що зрештою передамо аргумент, який отримуємо в
execute, до spawn. Ми можемо ще більше впевнитися, що FnOnce — це той
trait, який нам потрібно використовувати, тому що thread, який виконує запит,
лише один раз виконає замикання цього запиту, що відповідає Once у FnOnce.
Параметр типу F також має trait bound Send і lifetime bound 'static,
які корисні в нашій ситуації: нам потрібен Send, щоб передати замикання
з одного thread в інший, і 'static, тому що ми не знаємо, скільки часу
thread знадобиться на виконання. Давайте створимо метод execute на
ThreadPool, який прийматиме узагальнений параметр типу F із цими
обмеженнями:
pub struct ThreadPool;
impl ThreadPool {
// --snip--
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Ми й далі використовуємо () після FnOnce, тому що цей FnOnce
представляє замикання, яке не приймає параметрів і повертає unit type ().
Так само, як і у визначеннях функцій, тип, що повертається, можна опустити
із сигнатури, але навіть якщо в нас немає параметрів, дужки все одно потрібні.
Знову ж таки, це найпростіша реалізація методу execute: вона нічого не
робить, але ми лише намагаємося змусити наш код скомпілюватися. Давайте
перевіримо його ще раз:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.24s
Воно компілюється! Але зауважте: якщо ви спробуєте cargo run і зробите
запит у браузері, то побачите помилки в браузері, які ми бачили на початку
розділу. Наша library насправді ще не викликає замикання, передане до
execute!
Примітка: Ви можете почути вислів про мови зі строгими компіляторами, такими як Haskell і Rust: «If the code compiles, it works.» Але цей вислів не є універсально правильним. Наш проєкт компілюється, але абсолютно нічого не робить! Якби ми будували реальний, повний проєкт, це був би гарний час почати писати unit tests, щоб перевірити, що код компілюється і має потрібну нам поведінку.
Поміркуйте: що було б інакше тут, якби ми збиралися виконувати future, а не замикання?
Перевірка кількості threads у new
Ми нічого не робимо з параметрами new і execute. Давайте реалізуємо
тіла цих функцій із потрібною нам поведінкою. Для початку подумаємо про
new. Раніше ми вибрали беззнаковий тип для параметра size, тому що pool
із від’ємною кількістю threads не має сенсу. Однак pool із нульовою
кількістю threads теж не має сенсу, хоча нуль є цілком допустимим usize.
Ми додамо код, щоб перевірити, що size більший за нуль, перед тим як
повернути екземпляр ThreadPool, і змусимо програму panic, якщо вона
отримає нуль, використавши макрос assert!, як показано в Лістингу 21-13.
pub struct ThreadPool;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Ми також додали деяку документацію для нашого ThreadPool за допомогою
doc comments. Зауважте, що ми дотрималися добрих практик документації,
додавши розділ, який вказує на ситуації, у яких наша функція може panic,
як обговорювалося в Chapter 14. Спробуйте запустити cargo doc --open і
натиснути на структуру ThreadPool, щоб побачити, як виглядає згенерована
документація для new!
Замість того щоб додавати макрос assert!, як ми зробили тут, ми могли б
змінити new на build і повертати Result, як ми зробили з Config::build
у I/O проєкті в Лістингу 12-9. Але в цьому випадку ми вирішили, що спроба
створити thread pool без жодного thread є непереборною помилкою. Якщо ви
налаштовані амбітно, спробуйте написати функцію під назвою build із такою
сигнатурою, щоб порівняти її з функцією new:
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {Створення місця для зберігання threads
Тепер, коли ми маємо спосіб переконатися, що в нас є дійсна кількість
threads для зберігання в pool, ми можемо створити ці threads і зберегти їх
у структурі ThreadPool перед тим, як повертати структуру. Але як нам
«зберегти» thread? Давайте ще раз подивимося на сигнатуру thread::spawn:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Функція spawn повертає JoinHandle<T>, де T — це тип, який повертає
замикання. Давайте спробуємо використати JoinHandle теж і подивимося, що
станеться. У нашому випадку замикання, які ми передаємо до thread pool,
оброблятимуть з’єднання і нічого не повертатимуть, тож T буде unit type ().
Код у Лістингу 21-14 скомпілюється, але поки що не створює жодного thread.
Ми змінили визначення ThreadPool, щоб воно містило vector
thread::JoinHandle<()>, ініціалізували vector із ємністю size, налаштували
цикл for, який виконуватиме код для створення threads, і повернули
екземпляр ThreadPool, що містить їх.
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
ThreadPool { threads }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Ми імпортували std::thread у область видимості library crate, тому що
використовуємо thread::JoinHandle як тип елементів у vector у ThreadPool.
Після отримання дійсного size наш ThreadPool створює новий vector, який
може містити size елементів. Функція with_capacity виконує ту саму
задачу, що й Vec::new, але з важливою відмінністю: вона попередньо
виділяє місце у vector. Оскільки ми знаємо, що нам потрібно зберігати
size елементів у vector, робити це виділення наперед трохи ефективніше,
ніж використовувати Vec::new, який змінює свій розмір у міру вставляння
елементів.
Коли ви знову запустите cargo check, він має успішно завершитися.
Надсилання коду з ThreadPool до thread
Ми залишили коментар у циклі for в Лістингу 21-14 щодо створення threads.
Тут ми подивимося, як саме створювати threads. Standard library надає
thread::spawn як спосіб створення threads, і thread::spawn очікує
отримати деякий код, який thread має виконати одразу після створення thread.
Однак у нашому випадку ми хочемо створити threads і змусити їх чекати на
код, який ми надішлемо пізніше. Реалізація threads у standard library не
містить способу зробити це; нам потрібно реалізувати це вручну.
Ми реалізуємо таку поведінку, ввівши нову структуру даних між ThreadPool
і threads, яка керуватиме цією новою поведінкою. Ми назвемо цю структуру
даних Worker, що є поширеним терміном у реалізаціях pooling. Worker
забирає код, який потрібно виконати, і виконує цей код у своєму thread.
Подумайте про людей, які працюють на кухні в ресторані: workers чекають, поки від клієнтів надійдуть замовлення, а потім відповідають за те, щоб узяти ці замовлення й виконати їх.
Замість зберігання vector екземплярів JoinHandle<()> у thread pool ми
зберігатимемо екземпляри структури Worker. Кожен Worker зберігатиме один
екземпляр JoinHandle<()>. Потім ми реалізуємо метод на Worker, який
прийматиме замикання коду для виконання і надсилатиме його вже запущеному
thread для виконання. Ми також надамо кожному Worker id, щоб можна було
розрізняти різні екземпляри Worker у pool під час логування або
налагодження.
Ось новий процес, який відбуватиметься, коли ми створюємо ThreadPool. Ми
реалізуємо код, який надсилає замикання до thread, після того як налаштуємо
Worker у такий спосіб:
- Визначте структуру
Worker, яка міститьidіJoinHandle<()>. - Змініть
ThreadPoolтак, щоб він містив vector екземплярівWorker. - Визначте функцію
Worker::new, яка приймає числоidі повертає екземплярWorker, що міститьidі thread, запущений із порожнім замиканням. - У
ThreadPool::newвикористовуйте лічильник циклуfor, щоб згенеруватиid, створити новийWorkerіз цимidі зберегтиWorkerу vector.
Якщо ви готові до виклику, спробуйте реалізувати ці зміни самостійно, перш ніж дивитися на код у Лістингу 21-15.
Готові? Ось Лістинг 21-15 з одним із способів внести попередні зміни.
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}Ми змінили назву поля в ThreadPool з threads на workers, тому що тепер
воно містить екземпляри Worker замість екземплярів JoinHandle<()>. Ми
використовуємо лічильник у циклі for як аргумент для Worker::new, і
зберігаємо кожен новий Worker у vector під назвою workers.
Зовнішньому коду (як нашому серверу в src/main.rs) не потрібно знати
деталі реалізації щодо використання структури Worker всередині
ThreadPool, тому ми робимо структуру Worker і її функцію new
приватними. Функція Worker::new використовує id, який ми їй даємо, і
зберігає екземпляр JoinHandle<()>, створений шляхом запуску нового
thread із порожнім замиканням.
Примітка: Якщо операційна система не може створити thread через те, що бракує системних ресурсів,
thread::spawnвикличе panic. Це призведе до panic усього нашого сервера, навіть якщо створення деяких threads може успішно завершитися. Для простоти така поведінка прийнятна, але в production-реалізації thread pool, ймовірно, вам варто було б використатиstd::thread::Builderі його методspawn, який натомість повертаєResult.
Цей код скомпілюється й зберігатиме кількість екземплярів Worker, яку ми
вказали як аргумент для ThreadPool::new. Але ми все ще не обробляємо
замикання, яке отримуємо в execute. Давайте подивимося, як зробити це далі.
Надсилання запитів до threads через channels
Наступна проблема, яку ми розв’яжемо, полягає в тому, що замикання, передані
до thread::spawn, абсолютно нічого не роблять. Наразі ми отримуємо
замикання, яке хочемо виконати, у методі execute. Але нам потрібно
дати thread::spawn замикання, яке потрібно виконати, коли ми створюємо
кожен Worker під час створення ThreadPool.
Ми хочемо, щоб щойно створені структури Worker отримували код для
виконання з черги, що зберігається в ThreadPool, і надсилали цей код до
свого thread для виконання.
Channels, про які ми дізналися в Chapter 16, — простий спосіб
комунікації між двома threads — ідеально підходять для цього випадку. Ми
використаємо channel як чергу jobs, а execute надсилатиме job від
ThreadPool до екземплярів Worker, які надсилатимуть job до свого thread.
Ось план:
ThreadPoolстворить channel і зберігатиме sender.- Кожен
Workerзберігатиме receiver. - Ми створимо нову структуру
Job, яка зберігатиме замикання, які ми хочемо передавати через channel. - Метод
executeнадсилатиме job, який він хоче виконати, через sender. - У своєму thread
Workerбуде ітеруватися по receiver і виконувати замикання будь-яких jobs, які він отримує.
Почнемо зі створення channel у ThreadPool::new і збереження sender в
екземплярі ThreadPool, як показано в Лістингу 21-16. Структура Job
поки що нічого не зберігає, але буде типом елемента, який ми передаємо через
channel.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}У ThreadPool::new ми створюємо новий channel і змушуємо pool зберігати
sender. Це успішно скомпілюється.
Спробуймо передати receiver channel кожному Worker, коли thread pool
створює channel. Ми знаємо, що хочемо використовувати receiver у thread,
який запускають екземпляри Worker, тому в замиканні ми звернемося до
параметра receiver. Код у Лістингу 21-17 ще не зовсім скомпілюється.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Ми внесли кілька невеликих і простих змін: передаємо receiver до
Worker::new, а потім використовуємо його всередині замикання.
Коли ми намагаємося перевірити цей код, отримуємо таку помилку:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
25 | for id in 0..size {
| ----------------- inside of this loop
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow instead if owning the value isn't necessary
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` (lib) due to 1 previous error
Код намагається передати receiver кільком екземплярам Worker. Це не
спрацює, як ви пам’ятаєте з Chapter 16: реалізація channel, яку надає Rust,
є multiple producer, single consumer. Це означає, що ми не можемо просто
клонувати споживчий кінець channel, щоб виправити цей код. Ми також не
хочемо надсилати повідомлення кілька разів кільком споживачам; нам потрібен
один список повідомлень із кількома екземплярами Worker, так щоб кожне
повідомлення оброблялося один раз.
Крім того, забирати job із черги channel означає змінювати receiver, тому
threads потрібен безпечний спосіб ділити receiver і змінювати його;
інакше ми можемо отримати race conditions (як розглядалося в Chapter 16).
Згадайте thread-safe smart pointers, про які йшлося в Chapter 16: щоб
розділяти ownership між кількома threads і дозволяти threads змінювати
значення, нам потрібно використовувати Arc<Mutex<T>>. Тип Arc дасть
змогу кільком екземплярам Worker володіти receiver, а Mutex забезпечить,
що лише один Worker отримуватиме job із receiver за раз. Лістинг 21-18
показує зміни, які нам потрібно зробити.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// --snip--
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}У ThreadPool::new ми поміщаємо receiver в Arc і Mutex. Для кожного
нового Worker ми клонуємо Arc, щоб збільшити лічильник посилань так, щоб
екземпляри Worker могли спільно володіти receiver.
З цими змінами код компілюється! Ми рухаємося далі!
Реалізація методу execute
Нарешті давайте реалізуємо метод execute на ThreadPool. Ми також змінимо
Job зі структури на псевдонім типу для trait object, який містить тип
замикання, що його отримує execute. Як обговорювалося в розділі “Type
Synonyms and Type Aliases” у Chapter 20,
type aliases дають змогу зробити довгі типи коротшими для зручності
використання. Подивіться на Лістинг 21-19.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Після створення нового екземпляра Job за допомогою замикання, яке ми
отримуємо в execute, ми надсилаємо цю job через sending end channel.
Ми викликаємо unwrap на send на випадок, якщо надсилання не вдасться.
Це може статися, якщо, наприклад, ми зупинимо виконання всіх наших threads,
тобто receiving end припинить отримувати нові повідомлення. Наразі ми не
можемо зупинити виконання наших threads: вони продовжують виконуватися,
доки pool існує. Причина, чому ми використовуємо unwrap, полягає в тому,
що ми знаємо, що випадок помилки не станеться, але компілятор цього не знає.
Але ми ще не зовсім завершили! У Worker наше замикання, яке передається до
thread::spawn, досі лише посилається на receiving end channel. Натомість
нам потрібно, щоб замикання безкінечно ітерувалося, запитуючи receiving end
channel про job і запускаючи job, коли отримає її. Давайте внесемо зміну,
показану в Лістингу 21-20, до Worker::new.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Тут ми спочатку викликаємо lock на receiver, щоб отримати mutex, а
потім викликаємо unwrap, щоб викликати panic у разі будь-яких помилок.
Отримання lock може завершитися невдачею, якщо mutex перебуває в poisoned
стані, що може статися, якщо якийсь інший thread викликав panic, утримуючи
lock, а не звільняючи його. У цій ситуації виклик unwrap, щоб цей thread
викликав panic, є правильною дією. За бажанням ви можете змінити цей unwrap
на expect із повідомленням про помилку, яке вам зрозуміле.
Якщо ми отримуємо lock на mutex, ми викликаємо recv, щоб отримати Job
із channel. Остаточний unwrap також проходить повз будь-які помилки тут,
які можуть виникнути, якщо thread, що утримує sender, завершив роботу,
подібно до того, як метод send повертає Err, якщо receiver завершує
роботу.
Виклик recv блокує, тож якщо job ще немає, поточний thread чекатиме, доки
job не стане доступною. Mutex<T> забезпечує, що лише один thread Worker
за раз намагається запросити job.
Наша thread pool тепер у робочому стані! Запустіть її за допомогою
cargo run і зробіть кілька запитів:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field `workers` is never read
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- field in this struct
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: fields `id` and `thread` are never read
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ fields in this struct
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `hello` (lib) generated 2 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 4.91s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Успіх! Тепер у нас є thread pool, який виконує з’єднання asynchronously. Ніколи не створюється більше ніж чотири threads, тож наша система не буде перевантажена, якщо сервер отримає багато запитів. Якщо ми зробимо запит до /sleep, сервер зможе обслуговувати інші запити, змушуючи інший thread виконувати їх.
Примітка: Якщо ви відкриєте /sleep у кількох вікнах браузера одночасно, вони можуть завантажуватися по одному з інтервалами в п’ять секунд. Деякі web browsers послідовно виконують кілька екземплярів того самого запиту з міркувань кешування. Це обмеження не спричинене нашим web server.
Зараз гарний момент зупинитися й поміркувати, чим би відрізнявся код у Лістингах 21-18, 21-19 і 21-20, якби ми використовували future замість замикання для роботи, яку потрібно виконати. Які типи змінилися б? Як би відрізнялися сигнатури методів, якщо б відрізнялися взагалі? Які частини коду залишилися б такими самими?
Після вивчення циклу while let у Chapter 17 і Chapter 19 ви можете
замислитися, чому ми не написали код thread Worker, як показано в
Лістингу 21-21.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Цей код компілюється й запускається, але не дає бажаної поведінки threading:
повільний запит усе одно змушуватиме інші запити чекати на обробку. Причина
дещо тонка: структура Mutex не має публічного методу unlock, тому що
ownership lock ґрунтується на lifetime MutexGuard<T> всередині
LockResult<MutexGuard<T>>, який повертає метод lock. На етапі
компіляції перевірник запозичень може забезпечити правило, що ресурс під
захистом Mutex не можна отримати доступ, якщо ми не тримаємо lock. Однак
ця реалізація також може призвести до того, що lock утримуватиметься довше,
ніж задумано, якщо ми не зважатимемо на lifetime MutexGuard<T>.
Код у Лістингу 21-20, який використовує let job = receiver.lock().unwrap().recv().unwrap();, працює тому, що з let будь-які
тимчасові значення, використані у виразі праворуч від знака рівності,
негайно видаляються, коли оператор let завершується. Однак while let
(і if let, і match) не видаляє тимчасові значення до кінця пов’язаного
блоку. У Лістингу 21-21 lock залишається утримуваним протягом виклику
job(), тобто інші екземпляри Worker не можуть отримувати jobs.
Коректне завершення роботи та очищення
М’яке завершення роботи та очищення
Код у Listing 21-20 асинхронно відповідає на запити через використання пулу потоків, як ми й задумували. Ми отримуємо деякі попередження про поля workers, id і thread, які ми не використовуємо безпосереднім чином, що нагадує нам, що ми нічого не очищаємо. Коли ми використовуємо менш елегантний метод ctrl-C, щоб зупинити головний потік, усі інші потоки також зупиняються негайно, навіть якщо вони перебувають у середині обслуговування запиту.
Далі ми реалізуємо трейт Drop, щоб викликати join для кожного з потоків у пулі, щоб вони могли завершити запити, над якими працюють, перед закриттям. Потім ми реалізуємо спосіб повідомити потокам, що вони мають перестати приймати нові запити та завершити роботу. Щоб побачити цей код у дії, ми змінимо наш сервер так, щоб він приймав лише два запити перед м’яким завершенням роботи свого пулу потоків.
Одне, що варто помітити в міру того, як ми просуваємося: жодне з цього не впливає на частини коду, які обробляють виконання замикань, тож усе тут було б таким самим, якби ми використовували пул потоків для async runtime.
Реалізація трейтa Drop для ThreadPool
Почнімо з реалізації Drop для нашого пулу потоків. Коли пул буде скинуто, усі наші потоки мають приєднатися, щоб переконатися, що вони завершили свою роботу. Listing 21-22 показує першу спробу реалізації Drop; цей код ще не зовсім працюватиме.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Спочатку ми проходимося циклом по кожному з workers пулу потоків. Ми використовуємо &mut для цього, тому що self є змінним посиланням, і нам також потрібно мати змогу змінювати worker. Для кожного worker ми виводимо повідомлення про те, що цей конкретний екземпляр Worker завершує роботу, а потім викликаємо join для потоку цього екземпляра Worker. Якщо виклик join завершується помилкою, ми використовуємо unwrap, щоб Rust запанікував і перейшов до негнучкого завершення.
Ось помилка, яку ми отримуємо під час компіляції цього коду:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: `JoinHandle::<T>::join` takes ownership of the receiver `self`, which moves `worker.thread`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:1921:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` (lib) due to 1 previous error
Помилка каже нам, що ми не можемо викликати join, тому що ми маємо лише змінне запозичення кожного worker, а join забирає власність свого аргументу. Щоб розв’язати цю проблему, нам потрібно перемістити потік із екземпляра Worker, який володіє thread, щоб join міг спожити потік. Один зі способів зробити це — застосувати той самий підхід, який ми використали в Listing 18-15. Якби Worker містив Option<thread::JoinHandle<()>>, ми могли б викликати метод take для Option, щоб перемістити значення з варіанта Some і залишити на його місці варіант None. Іншими словами, Worker, який працює, мав би варіант Some у thread, а коли ми захотіли б очистити Worker, ми б замінили Some на None, щоб у Worker не було потоку для виконання.
Однак це сталося б лише тоді, коли Worker скидається. Натомість нам довелося б мати справу з Option<thread::JoinHandle<()>> у будь-якому місці, де ми звертаємося до worker.thread. Ідіоматичний Rust досить часто використовує Option, але коли ви виявляєте, що обгортаєте щось, що, як ви знаєте, завжди буде присутнє, в Option як обхідний шлях, як у цьому випадку, варто пошукати альтернативні підходи, щоб зробити ваш код чистішим і менш схильним до помилок.
У цьому випадку існує краща альтернатива: метод Vec::drain. Він приймає параметр діапазону, щоб указати, які елементи видалити з вектора, і повертає ітератор цих елементів. Передавання синтаксису діапазону .. видалить кожне значення з вектора.
Отже, нам потрібно оновити реалізацію drop для ThreadPool ось так:
#![allow(unused)]
fn main() {
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}
}Це усуває помилку компілятора і не вимагає жодних інших змін у нашому коді. Зверніть увагу, що, оскільки drop може бути викликаний під час паніки, unwrap також може запанікувати й спричинити подвійну паніку, що негайно аварійно завершує програму та припиняє будь-яке очищення, яке триває. Для прикладної програми це нормально, але для production-коду це не рекомендується.
Сигналізація потокам, щоб вони перестали слухати завдання
Після всіх змін, які ми внесли, наш код компілюється без жодних попереджень. Однак погана новина полягає в тому, що цей код ще не працює так, як ми хочемо. Ключ у логіці в замиканнях, які виконуються потоками екземплярів Worker: зараз ми викликаємо join, але це не завершить роботу потоків, тому що вони безкінечно loop-ляться в пошуках завдань. Якщо ми спробуємо скинути наш ThreadPool із поточною реалізацією drop, головний потік буде заблокований назавжди, очікуючи на завершення першого потоку.
Щоб виправити цю проблему, нам потрібна зміна в реалізації drop для ThreadPool, а потім зміна в циклі Worker.
Спочатку ми змінимо реалізацію drop для ThreadPool, щоб явно скинути sender перед очікуванням завершення потоків. Listing 21-23 показує зміни до ThreadPool, щоб явно скинути sender. На відміну від потоку, тут нам дійсно потрібно використовувати Option, щоб мати змогу перемістити sender із ThreadPool за допомогою Option::take.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Скидання sender закриває канал, що означає, що більше не буде надіслано повідомлень. Коли це станеться, усі виклики recv, які екземпляри Worker виконують у нескінченному циклі, повертатимуть помилку. У Listing 21-24 ми змінюємо цикл Worker, щоб у такому разі він м’яко виходив із циклу, що означає, що потоки завершать роботу, коли реалізація drop для ThreadPool викличе для них join.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker { id, thread }
}
}Щоб побачити цей код у дії, давайте змінимо main, щоб він приймав лише два запити перед м’яким завершенням роботи сервера, як показано в Listing 21-25.
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Ви б не хотіли, щоб реальний вебсервер завершував роботу після обслуговування лише двох запитів. Цей код лише демонструє, що м’яке завершення роботи та очищення працюють.
Метод take визначено в трейті Iterator і обмежує ітерацію щонайбільше першими двома елементами. ThreadPool вийде з області видимості в кінці main, і буде виконано реалізацію drop.
Запустіть сервер за допомогою cargo run і зробіть три запити. Третій запит має завершитися помилкою, і у вашому терміналі ви маєте побачити вивід, подібний до такого:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
Ви можете побачити інший порядок Worker-ID та надрукованих повідомлень. Ми можемо зрозуміти, як працює цей код, із повідомлень: екземпляри Worker 0 і 3 отримали перші два запити. Сервер перестав приймати з’єднання після другого з’єднання, і реалізація Drop для ThreadPool починає виконуватися ще до того, як Worker 3 навіть починає свою роботу. Скидання sender від’єднує всі екземпляри Worker і повідомляє їм, що вони мають завершити роботу. Кожен екземпляр Worker друкує повідомлення, коли від’єднується, а потім пул потоків викликає join, щоб дочекатися завершення кожного потоку Worker.
Зверніть увагу на один цікавий аспект цього конкретного виконання: ThreadPool скинув sender, і перш ніж будь-який Worker отримав помилку, ми спробували приєднати Worker 0. Worker 0 ще не отримав помилку від recv, тож головний потік заблокувався, очікуючи завершення Worker 0. Тим часом Worker 3 отримав завдання, а потім усі потоки отримали помилку. Коли Worker 0 завершився, головний потік дочекався завершення решти екземплярів Worker. У цей момент вони всі вийшли зі своїх циклів і зупинилися.
Вітаємо! Ми завершили наш проєкт; тепер у нас є базовий вебсервер, який використовує пул потоків для асинхронної відповіді. Ми можемо виконати м’яке завершення роботи сервера, яке очищає всі потоки в пулі.
Ось повний код для довідки:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Ми могли б зробити тут ще більше! Якщо ви хочете продовжити вдосконалювати цей проєкт, ось кілька ідей:
- Додайте більше документації до
ThreadPoolта його публічних методів. - Додайте тести функціональності бібліотеки.
- Змініть виклики
unwrapна надійнішу обробку помилок. - Використайте
ThreadPool, щоб виконувати якусь іншу задачу, ніж обслуговування вебзапитів. - Знайдіть крейт пулу потоків на crates.io і реалізуйте подібний вебсервер, використовуючи замість цього крейт. Потім порівняйте його API та надійність із пулом потоків, який ми реалізували.
Підсумок
Чудова робота! Ви дійшли до кінця книги! Ми хочемо подякувати вам за те, що ви пройшли разом із нами цей огляд мови програмування Rust. Тепер ви готові реалізовувати власні проєкти Rust і допомагати з проєктами інших людей. Пам’ятайте, що існує привітна спільнота інших растацеанців (Rustaceans), які із задоволенням допоможуть вам із будь-якими викликами, з якими ви зіткнетеся у своїй подорожі Rust.
Додаток
Наступні розділи містять довідковий матеріал, який може бути вам корисним у вашій подорожі з Rust.
A - Ключові слова
Додаток A: Ключові слова
Наведені нижче списки містять ключові слова, зарезервовані для поточного або майбутнього використання мовою Rust. Як такі, вони не можуть використовуватися як ідентифікатори (за винятком raw identifiers, як ми обговорюємо в розділі «Raw Identifiers»). Ідентифікатори — це назви функцій, змінних, параметрів, полів структур, модулів, крейтів, констант, макросів, static-значень, атрибутів, типів, трейтів або часів життя.
Ключові слова, що зараз використовуються
Нижче наведено список ключових слів, що зараз використовуються, з описом їхньої функціональності.
as: Виконати примітивне приведення, розрізнити конкретний трейт, що містить елемент, або перейменувати елементи вuse-операторах.async: ПовернутиFutureзамість блокування поточного потоку.await: Призупинити виконання, доки результатFutureне буде готовий.break: Негайно вийти з циклу.const: Визначити константні елементи або константні raw pointers.continue: Продовжити до наступної ітерації циклу.crate: У шляху модуля вказує на корінь крейту.dyn: Динамічна диспетчеризація до трейт-об’єкта.else: Альтернатива для конструкцій керування потокомifіif let.enum: Визначити перелік.extern: Прив’язати зовнішню функцію або змінну.false: Булевий літерал false.fn: Визначити функцію або тип вказівника на функцію.for: Проходити по елементах з ітератора, реалізувати трейт або вказати lifetime вищого рангу.if: Розгалуження на основі результату умовного виразу.impl: Реалізувати вбудовану або трейт-функціональність.in: Частина синтаксису циклуfor.let: Прив’язати змінну.loop: Цикл безумовно.match: Зіставити значення зі зразками.mod: Визначити модуль.move: Змусити замикання взяти власність на всі свої захоплення.mut: Позначити змінність у посиланнях, raw pointers або прив’язках зразка.pub: Позначити публічну видимість у полях структури, блокахimplабо модулях.ref: Прив’язати за посиланням.return: Повернутися з функції.Self: Псевдонім типу для типу, який ми визначаємо або реалізуємо.self: Об’єкт методу або поточний модуль.static: Глобальна змінна або час життя, що триває протягом усього виконання програми.struct: Визначити структуру.super: Батьківський модуль поточного модуля.trait: Визначити трейт.true: Булевий літерал true.type: Визначити псевдонім типу або асоційований тип.union: Визначити union; це ключове слово лише тоді, коли використовується в оголошенні union.unsafe: Позначити unsafe код, функції, трейт або реалізації.use: Внести символи в область видимості.where: Позначити clauses, що обмежують тип.while: Цикл умовно на основі результату виразу.
Ключові слова, зарезервовані для майбутнього використання
Наведені нижче ключові слова ще не мають жодної функціональності, але зарезервовані Rust для потенційного майбутнього використання:
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
Raw Identifiers
Raw identifiers — це синтаксис, що дає змогу використовувати ключові слова там, де їх зазвичай не дозволено. Ви використовуєте raw identifier, додаючи перед ключовим словом префікс r#.
Наприклад, match — це ключове слово. Якщо ви спробуєте скомпілювати таку функцію, що використовує match як її ім’я:
Filename: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}ви отримаєте цю помилку:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
Помилка показує, що ви не можете використовувати ключове слово match як ідентифікатор функції. Щоб використовувати match як ім’я функції, вам потрібно використовувати синтаксис raw identifier, ось так:
Filename: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}
fn main() {
assert!(r#match("foo", "foobar"));
}Цей код скомпілюється без жодних помилок. Зверніть увагу на префікс r# в імені функції в її визначенні, а також там, де функцію викликають у main.
Raw identifiers дають змогу використовувати будь-яке слово, яке ви оберете, як ідентифікатор, навіть якщо це слово випадково є зарезервованим ключовим словом. Це дає нам більше свободи в доборі імен ідентифікаторів, а також дає змогу інтегруватися з програмами, написаними мовою, у якій ці слова не є ключовими словами. Крім того, raw identifiers дають змогу використовувати бібліотеки, написані в іншому виданні Rust, ніж те, яке використовує ваш крейт. Наприклад, try не є ключовим словом у виданні 2015, але є у виданнях 2018, 2021 і 2024. Якщо ви залежите від бібліотеки, написаної з використанням видання 2015 і яка має функцію try, вам потрібно буде використовувати синтаксис raw identifier, r#try у цьому випадку, щоб викликати цю функцію з вашого коду в пізніших виданнях. Дивіться Додаток E для отримання додаткової інформації про видання.
B - Оператори та символи
Додаток B: Оператори та символи
Цей додаток містить глосарій синтаксису Rust, включно з операторами та іншими символами, які з’являються самі по собі або в контексті шляхів, generics, trait bounds, macros, attributes, comments, tuples, and brackets.
Оператори
Table B-1 містить оператори в Rust, приклад того, як оператор виглядатиме в контексті, коротке пояснення та чи є цей оператор перевантажуваним. Якщо оператор перевантажуваний, перелічується відповідний trait, який потрібно використати для перевантаження цього оператора.
Table B-1: Operators
| Operator | Example | Explanation | Overloadable? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Розгортання макросу | |
! | !expr | Побітове або логічне доповнення | Not |
!= | expr != expr | Порівняння на нерівність | PartialEq |
% | expr % expr | Арифметичний остачок | Rem |
%= | var %= expr | Арифметичний остачок і присвоєння | RemAssign |
& | &expr, &mut expr | Запозичення | |
& | &type, &mut type, &'a type, &'a mut type | Тип запозиченого вказівника | |
& | expr & expr | Побітове AND | BitAnd |
&= | var &= expr | Побітове AND і присвоєння | BitAndAssign |
&& | expr && expr | Логічне AND із коротким замиканням | |
* | expr * expr | Арифметичне множення | Mul |
*= | var *= expr | Арифметичне множення і присвоєння | MulAssign |
* | *expr | Розіменування | Deref |
* | *const type, *mut type | Сирий вказівник | |
+ | trait + trait, 'a + trait | Складена межа типу | |
+ | expr + expr | Арифметичне додавання | Add |
+= | var += expr | Арифметичне додавання і присвоєння | AddAssign |
, | expr, expr | Роздільник аргументів і елементів | |
- | - expr | Арифметичне заперечення | Neg |
- | expr - expr | Арифметичне віднімання | Sub |
-= | var -= expr | Арифметичне віднімання і присвоєння | SubAssign |
-> | fn(...) -> type, |…| -> type | Тип повернення функції та замикання | |
. | expr.ident | Доступ до поля | |
. | expr.ident(expr, ...) | Виклик методу | |
. | expr.0, expr.1, and so on | Індексування кортежу | |
.. | .., expr.., ..expr, expr..expr | Літерал діапазону з правою межею, що не включається | PartialOrd |
..= | ..=expr, expr..=expr | Літерал діапазону з правою межею, що включається | PartialOrd |
.. | ..expr | Синтаксис оновлення літерала структури | |
.. | variant(x, ..), struct_type { x, .. } | Зв’язування зразка «та решта» | |
... | expr...expr | (Застаріло, використовуйте ..= замість цього) У зразку: зразок діапазону з включенням | |
/ | expr / expr | Арифметичне ділення | Div |
/= | var /= expr | Арифметичне ділення і присвоєння | DivAssign |
: | pat: type, ident: type | Обмеження | |
: | ident: expr | Ініціалізатор поля структури | |
: | 'a: loop {...} | Мітка циклу | |
; | expr; | Завершувач оператора та елемента | |
; | [...; len] | Частина синтаксису масиву фіксованого розміру | |
<< | expr << expr | Зсув ліворуч | Shl |
<<= | var <<= expr | Зсув ліворуч і присвоєння | ShlAssign |
< | expr < expr | Порівняння менше ніж | PartialOrd |
<= | expr <= expr | Порівняння менше ніж або дорівнює | PartialOrd |
= | var = expr, ident = type | Присвоєння/еквівалентність | |
== | expr == expr | Порівняння на рівність | PartialEq |
=> | pat => expr | Частина синтаксису гілки match | |
> | expr > expr | Порівняння більше ніж | PartialOrd |
>= | expr >= expr | Порівняння більше ніж або дорівнює | PartialOrd |
>> | expr >> expr | Зсув праворуч | Shr |
>>= | var >>= expr | Зсув праворуч і присвоєння | ShrAssign |
@ | ident @ pat | Зв’язування зразка | |
^ | expr ^ expr | Побітове виключне OR | BitXor |
^= | var ^= expr | Побітове виключне OR і присвоєння | BitXorAssign |
| | pat | pat | Альтернативи зразка | |
| | expr | expr | Побітове OR | BitOr |
|= | var |= expr | Побітове OR і присвоєння | BitOrAssign |
|| | expr || expr | Логічне OR із коротким замиканням | |
? | expr? | Поширення помилки |
Символи, що не є операторами
Наведені нижче таблиці містять усі символи, які не виконують функції операторів; тобто вони не поводяться як виклик функції чи методу.
Table B-2 показує символи, які з’являються самі по собі та є допустимими в різноманітних місцях.
Table B-2: Stand-alone Syntax
| Symbol | Explanation |
|---|---|
'ident | Іменований час життя або мітка циклу |
Digits immediately followed by u8, i32, f64, usize, and so on | Числовий літерал конкретного типу |
"..." | Рядковий літерал |
r"...", r#"..."#, r##"..."##, and so on | Сирий рядковий літерал; escape-символи не обробляються |
b"..." | Байт-рядковий літерал; створює масив байтів замість рядка |
br"...", br#"..."#, br##"..."##, and so on | Сирий байт-рядковий літерал; поєднання сирого та байт-рядкового літерала |
'...' | Символьний літерал |
b'...' | ASCII байтовий літерал |
|…| expr | Замикання |
! | Завжди порожній нижній тип для функцій, що розходяться |
_ | Зв’язування зразка «ігноровано»; також використовується, щоб зробити цілі числові літерали читабельними |
Table B-3 shows symbols that appear in the context of a path through the module hierarchy to an item.
Table B-3: Path-Related Syntax
| Symbol | Explanation |
|---|---|
ident::ident | Шлях простору імен |
::path | Шлях відносно кореня крейту (тобто явно абсолютний шлях) |
self::path | Шлях відносно поточного модуля (тобто явно відносний шлях) |
super::path | Шлях відносно батька поточного модуля |
type::ident, <type as trait>::ident | Асоційовані константи, функції та типи |
<type>::... | Асоційований елемент для типу, який не можна назвати напряму (наприклад, <&T>::..., <[T]>::... тощо) |
trait::method(...) | Уточнення виклику методу шляхом вказування трейтy, який його визначає |
type::method(...) | Уточнення виклику методу шляхом вказування типу, для якого він визначений |
<type as trait>::method(...) | Уточнення виклику методу шляхом вказування трейтa та типу |
Table B-4 shows symbols that appear in the context of using generic type parameters.
Table B-4: Generics
| Symbol | Explanation |
|---|---|
path<...> | Specifies parameters to a generic type in a type (for example, Vec<u8>) |
path::<...>, method::<...> | Specifies parameters to a generic type, function, or method in an expression; often referred to as turbofish (for example, "42".parse::<i32>()) |
fn ident<...> ... | Define generic function |
struct ident<...> ... | Define generic structure |
enum ident<...> ... | Define generic enumeration |
impl<...> ... | Define generic implementation |
for<...> type | Higher ranked lifetime bounds |
type<ident=type> | A generic type where one or more associated types have specific assignments (for example, Iterator<Item=T>) |
Table B-5 shows symbols that appear in the context of constraining generic type parameters with trait bounds.
Table B-5: Trait Bound Constraints
| Symbol | Explanation |
|---|---|
T: U | Generic parameter T constrained to types that implement U |
T: 'a | Generic type T must outlive lifetime 'a (meaning the type cannot transitively contain any references with lifetimes shorter than 'a) |
T: 'static | Generic type T contains no borrowed references other than 'static ones |
'b: 'a | Generic lifetime 'b must outlive lifetime 'a |
T: ?Sized | Allow generic type parameter to be a dynamically sized type |
'a + trait, trait + trait | Compound type constraint |
Table B-6 shows symbols that appear in the context of calling or defining macros and specifying attributes on an item.
Table B-6: Macros and Attributes
| Symbol | Explanation |
|---|---|
#[meta] | Зовнішній атрибут |
#![meta] | Внутрішній атрибут |
$ident | Підстановка макросу |
$ident:kind | Метазмінна макросу |
$(...)... | Повторення макросу |
ident!(...), ident!{...}, ident![...] | Виклик макросу |
Table B-7 shows symbols that create comments.
Table B-7: Comments
| Symbol | Explanation |
|---|---|
// | Коментар до рядка |
//! | Внутрішній рядковий документувальний коментар |
/// | Зовнішній рядковий документувальний коментар |
/*...*/ | Блоковий коментар |
/*!...*/ | Внутрішній блоковий документувальний коментар |
/**...*/ | Зовнішній блоковий документувальний коментар |
Table B-8 shows the contexts in which parentheses are used.
Table B-8: Parentheses
| Symbol | Explanation |
|---|---|
() | Порожній кортеж (також unit), і як літерал, і як тип |
(expr) | Вираз у дужках |
(expr,) | Вираз кортежу з одним елементом |
(type,) | Тип кортежу з одним елементом |
(expr, ...) | Вираз кортежу |
(type, ...) | Тип кортежу |
expr(expr, ...) | Вираз виклику функції; також використовується для ініціалізації кортежних structs і кортежних варіантів enum |
Table B-9 shows the contexts in which curly brackets are used.
Table B-9: Curly Brackets
| Context | Explanation |
|---|---|
{...} | Вираз блоку |
Type {...} | Літерал структури |
Table B-10 shows the contexts in which square brackets are used.
Table B-10: Square Brackets
| Context | Explanation |
|---|---|
[...] | Літерал масиву |
[expr; len] | Літерал масиву, що містить len копій expr |
[type; len] | Тип масиву, що містить len екземплярів type |
expr[expr] | Індексування колекції; перевантажуване (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Індексування колекції, що вдає із себе зріз колекції, використовуючи Range, RangeFrom, RangeTo або RangeFull як «індекс` |
C - Трейти, для яких можливе виведення
Додаток C: Трейти, що можна виводити
У різних місцях у книзі ми обговорювали атрибут derive, який
ви можете застосувати до визначення структури або переліку. Атрибут derive генерує
код, який реалізує трейт із власною реалізацією за замовчуванням на
типі, який ви анотували синтаксисом derive.
У цьому додатку ми надаємо довідку для всіх трейтів у стандартній
бібліотеці, які ви можете використовувати з derive. Кожен розділ охоплює:
- Які оператори та методи стане можливим використовувати завдяки виведенню цього трейту
- Що робить реалізація трейту, надана
derive - Що означає реалізація трейту щодо типу
- Умови, за яких вам дозволено або не дозволено реалізовувати трейт
- Приклади операцій, які потребують трейт
Якщо ви хочете іншу поведінку, ніж та, що надається атрибутом derive,
зверніться до документації стандартної бібліотеки
для кожного трейту, щоб дізнатися подробиці про те, як реалізувати їх вручну.
Трейти, перелічені тут, — це єдині визначені стандартною бібліотекою, які
можна реалізувати на ваших типах за допомогою derive. Інші трейт, визначені у
стандартній бібліотеці, не мають розумної поведінки за замовчуванням, тож
саме вам вирішувати, як реалізувати їх у спосіб, що має сенс для того, чого ви намагаєтеся досягти.
Прикладом трейту, який не можна вивести, є Display, який відповідає за
форматування для кінцевих користувачів. Ви завжди повинні розглядати відповідний спосіб
відображення типу для кінцевого користувача. Які частини типу кінцевому користувачу
слід дозволити бачити? Які частини будуть для нього релевантними? Який формат даних
буде для нього найбільш релевантним? Компілятор Rust не має цього розуміння, тож
він не може надати для вас відповідну поведінку за замовчуванням.
Перелік трейтів, що можна виводити, наданий у цьому додатку, не є вичерпним:
бібліотеки можуть реалізовувати derive для власних трейтів, роблячи перелік
трейтів, які ви можете використовувати з derive, справді відкритим. Реалізація derive
вимагає використання процедурного макроса, який розглядається в розділі “Custom derive
Macros” у розділі 20.
Debug для виведення для програміста
Трейт Debug вмикає форматування для налагодження у форматних рядках, яке ви
позначаєте, додаючи :? усередині заповнювачів {}.
Трейт Debug дозволяє вам друкувати екземпляри типу для цілей налагодження,
щоб ви та інші програмісти, які використовують ваш тип, могли перевірити екземпляр
у певний момент виконання програми.
Трейт Debug потрібен, наприклад, під час використання макроса assert_eq!.
Цей макрос друкує значення екземплярів, переданих як аргументи, якщо
твердження про рівність не виконується, щоб програмісти могли побачити, чому два екземпляри
не були рівними.
PartialEq і Eq для порівнянь на рівність
Трейт PartialEq дозволяє вам порівнювати екземпляри типу, щоб перевірити
рівність, і вмикає використання операторів == та !=.
Виведення PartialEq реалізує метод eq. Коли PartialEq виводиться для
структур, два екземпляри є рівними лише якщо всі поля є рівними, і
екземпляри не є рівними, якщо будь-яке поле не є рівним. Коли виводиться для
переліків, кожен варіант є рівним самому собі і не є рівним іншим варіантам.
Трейт PartialEq потрібен, наприклад, для використання макроса
assert_eq!, якому потрібно вміти порівнювати два екземпляри типу
на рівність.
Трейт Eq не має методів. Його мета — сигналізувати, що для кожного значення
анотованого типу значення є рівним самому собі. Трейт Eq можна застосовувати лише
до типів, які також реалізують PartialEq, хоча не всі типи, що
реалізують PartialEq, можуть реалізувати Eq. Один приклад цього — типи чисел з плаваючою
комою: реалізація чисел з плаваючою комою стверджує, що два
екземпляри значення not-a-number (NaN) не є рівними один одному.
Прикладом того, коли потрібен Eq, є ключі в HashMap<K, V>, щоб
HashMap<K, V> могла визначити, чи є два ключі однаковими.
PartialOrd і Ord для порівнянь порядку
Трейт PartialOrd дозволяє вам порівнювати екземпляри типу для цілей
сортування. Тип, який реалізує PartialOrd, можна використовувати з операторами <, >,
<= та >=. Ви можете застосовувати трейт PartialOrd лише до типів,
які також реалізують PartialEq.
Виведення PartialOrd реалізує метод partial_cmp, який повертає
Option<Ordering>, що буде None, коли надані значення не утворюють
порядку. Прикладом значення, яке не утворює порядку, хоча
більшість значень цього типу можна порівнювати, є значення з плаваючою комою NaN.
Виклик partial_cmp з будь-яким числом з плаваючою комою та
значенням NaN з плаваючою комою поверне None.
Коли виводиться для структур, PartialOrd порівнює два екземпляри, порівнюючи
значення в кожному полі в порядку, в якому поля з’являються у визначенні
структури. Коли виводиться для переліків, варіанти переліку, оголошені раніше у
визначенні переліку, вважаються меншими за варіанти, перелічені пізніше.
Трейт PartialOrd потрібен, наприклад, для методу gen_range
з крейту rand, який генерує випадкове значення в діапазоні, заданому
виразом діапазону.
Трейт Ord дозволяє вам знати, що для будь-яких двох значень
анотованого типу існуватиме коректний порядок. Трейт Ord реалізує метод cmp,
який повертає Ordering, а не Option<Ordering>, тому що коректний
порядок завжди буде можливим. Ви можете застосовувати трейт Ord лише до типів,
які також реалізують PartialOrd і Eq (а Eq вимагає PartialEq). Коли
виводиться для структур і переліків, cmp поводиться так само, як і згенерована
реалізація для partial_cmp у PartialOrd.
Прикладом того, коли потрібен Ord, є зберігання значень у BTreeSet<T>,
структурі даних, яка зберігає дані на основі порядку сортування значень.
Clone і Copy для дублювання значень
Трейт Clone дозволяє вам явно створити глибоку копію значення, і
процес дублювання може включати виконання довільного коду та копіювання даних у купі.
Дивіться розділ “Variables and Data Interacting with
Clone” у
розділі 4 для отримання додаткової інформації про Clone.
Виведення Clone реалізує метод clone, який, коли реалізований для
всього типу, викликає clone для кожної частини типу. Це означає, що всі
поля або значення в типі також мають реалізовувати Clone, щоб вивести Clone.
Прикладом того, коли потрібен Clone, є виклик методу to_vec на
зрізі. Зріз не володіє екземплярами типу, які він містить, але вектор,
повернений з to_vec, має володіти своїми екземплярами, тому to_vec викликає
clone для кожного елемента. Таким чином, тип, що зберігається у зрізі, має реалізовувати Clone.
Трейт Copy дозволяє вам дублювати значення, лише копіюючи біти, збережені на
стеку; жоден довільний код не потрібен. Дивіться розділ “Stack-Only Data:
Copy” у розділі 4 для
отримання додаткової інформації про Copy.
Трейт Copy не визначає жодних методів, щоб запобігти програмістам від
перевизначення цих методів і порушення припущення, що жоден довільний код не
виконується. Таким чином, усі програмісти можуть припускати, що копіювання значення буде
дуже швидким.
Ви можете вивести Copy для будь-якого типу, усі частини якого реалізують Copy. Тип, який
реалізує Copy, також має реалізовувати Clone, тому що тип, який реалізує
Copy, має тривіальну реалізацію Clone, яка виконує ту саму задачу, що й
Copy.
Трейт Copy рідко потрібен; типи, що реалізують Copy, мають
доступні оптимізації, тобто вам не потрібно викликати clone, що робить
код лаконічнішим.
Усе, що можливо з Copy, ви також можете досягти з Clone, але
код може бути повільнішим або мати використовувати clone у деяких місцях.
Hash для відображення значення у значення фіксованого розміру
Трейт Hash дозволяє вам взяти екземпляр типу довільного розміру і
відобразити цей екземпляр у значення фіксованого розміру за допомогою хеш-функції. Виведення
Hash реалізує метод hash. Згенерована реалізація
методу hash поєднує результат виклику hash для кожної з частин типу,
тобто всі поля або значення також мають реалізовувати Hash, щоб вивести Hash.
Прикладом того, коли потрібен Hash, є зберігання ключів у HashMap<K, V>
для ефективного зберігання даних.
Default для значень за замовчуванням
Трейт Default дозволяє вам створити значення за замовчуванням для типу. Виведення
Default реалізує функцію default. Згенерована реалізація
функції default викликає функцію default для кожної частини типу,
тобто всі поля або значення в типі також мають реалізовувати Default, щоб
вивести Default.
Функція Default::default зазвичай використовується в поєднанні з синтаксисом
оновлення структури, обговореним у розділі “Creating Instances from Other Instances with
Struct Update
Syntax” у розділі 5. Ви можете налаштувати кілька полів структури, а
потім задати й використати значення за замовчуванням для решти полів, використовуючи
..Default::default().
Трейт Default потрібен, наприклад, коли ви використовуєте метод unwrap_or_default на
екземплярах Option<T>. Якщо Option<T> — це None, метод
unwrap_or_default поверне результат Default::default для типу
T, що зберігається в Option<T>.
D - Корисні інструменти розробки
Додаток D: Корисні інструменти розробки
У цьому додатку ми говоримо про деякі корисні інструменти розробки, які надає проєкт Rust. Ми розглянемо автоматичне форматування, швидкі способи застосування виправлень до попереджень, лінтер і інтеграцію з IDE.
Автоматичне форматування за допомогою rustfmt
Інструмент rustfmt переформатовує ваш код відповідно до стилю коду спільноти. Багато спільних проєктів використовують rustfmt, щоб запобігти суперечкам про те, який стиль використовувати під час написання Rust: кожен форматує свій код за допомогою цього інструмента.
Встановлення Rust за замовчуванням включають rustfmt, тож у вашій системі вже мають бути програми rustfmt і cargo-fmt. Ці дві команди є аналогами rustc і cargo у тому сенсі, що rustfmt дає тонкіший контроль, а cargo-fmt розуміє домовленості проєкту, який використовує Cargo. Щоб відформатувати будь-який проєкт Cargo, введіть таке:
$ cargo fmt
Запуск цієї команди переформатовує весь код Rust у поточному крейті. Це має змінювати лише стиль коду, а не семантику коду. Докладніше про rustfmt дивіться в його документації.
Виправляйте свій код за допомогою rustfix
Інструмент rustfix входить до складу встановлень Rust і може автоматично виправляти попередження компілятора, для яких є чіткий спосіб виправлення проблеми, імовірно саме той, який вам потрібен. Ви, мабуть, уже бачили попередження компілятора раніше. Наприклад, розгляньте цей код:
Filename: src/main.rs
fn main() {
let mut x = 42;
println!("{x}");
}Тут ми визначаємо змінну x як змінну, але насправді ніколи її не змінюємо. Rust попереджає нас про це:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
Попередження пропонує нам прибрати ключове слово mut. Ми можемо автоматично
застосувати цю пропозицію за допомогою інструмента rustfix, виконавши команду cargo fix:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Коли ми знову подивимося на src/main.rs, побачимо, що cargo fix змінив
код:
Filename: src/main.rs
fn main() {
let x = 42;
println!("{x}");
}Змінна x тепер незмінна, і попередження більше не з’являється.
Ви також можете використовувати команду cargo fix, щоб перевести свій код між
різними виданнями Rust. Видання розглядаються в Додатку E.
Більше лінтів із Clippy
Інструмент Clippy — це набір лінтів для аналізу вашого коду, щоб ви могли виявляти поширені помилки та покращувати свій код Rust. Clippy входить до стандартних встановлень Rust.
Щоб запустити лінти Clippy для будь-якого проєкту Cargo, введіть таке:
$ cargo clippy
Наприклад, припустімо, ви пишете програму, яка використовує наближення математичної константи, такої як пі, як це робить ця програма:
fn main() {
let x = 3.1415;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}Запуск cargo clippy для цього проєкту призводить до такої помилки:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
Ця помилка повідомляє вам, що Rust уже має визначену точнішу константу PI, і що ваша програма була б правильнішою, якби ви використовували цю константу замість неї. Після цього ви змінили б свій код, щоб використовувати константу PI.
Наступний код не призводить до жодних помилок або попереджень від Clippy:
fn main() {
let x = std::f64::consts::PI;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}Докладніше про Clippy дивіться в його документації.
Інтеграція з IDE за допомогою rust-analyzer
Щоб допомогти з інтеграцією з IDE, спільнота Rust рекомендує використовувати
rust-analyzer. Цей інструмент — це набір
утиліт, орієнтованих на компілятор, які розмовляють за допомогою Language Server Protocol, тобто специфікації для того, щоб IDE і мови програмування
обмінювалися між собою. Різні клієнти можуть використовувати rust-analyzer, наприклад
плагін Rust analyzer для Visual Studio Code.
Відвідайте домашню сторінку
проєкту rust-analyzer для інструкцій зі встановлення, а потім установіть підтримку language server у
вашій конкретній IDE. Ваша IDE отримає можливості, такі як автодоповнення, перехід до
визначення та вбудовані помилки.
E - Редакції
Додаток E: Видання
У Розділі 1 ви побачили, що cargo new додає трохи метаданих до вашого
файлу Cargo.toml про видання. У цьому додатку йдеться про те, що це означає!
Мова Rust і компілятор мають шеститижневий цикл випусків, що означає, що користувачі отримують постійний потік нових можливостей. Інші мови програмування випускають більші зміни рідше; Rust випускає менші оновлення частіше. Після деякого часу всі ці дрібні зміни складаються. Але від випуску до випуску може бути важко озирнутися назад і сказати: “Ого, між Rust 1.10 і Rust 1.31 Rust дуже змінився!”
Приблизно кожні три роки команда Rust створює нове Rust видання. Кожне видання об’єднує можливості, що з’явилися, в чіткий пакет із повністю оновленою документацією та інструментарієм. Нові видання виходять у межах звичайного шеститижневого процесу випусків.
Видання слугують різним цілям для різних людей:
- Для активних користувачів Rust нове видання об’єднує поступові зміни в легкий для розуміння пакет.
- Для тих, хто не користується Rust, нове видання сигналізує, що з’явилися деякі значні вдосконалення, які можуть змусити знову придивитися до Rust.
- Для тих, хто розробляє Rust, нове видання надає точку збору для проєкту в цілому.
На момент написання цієї книги доступні чотири видання Rust: Rust 2015, Rust 2018, Rust 2021 і Rust 2024. Ця книга написана з використанням ідіом видання Rust 2024.
Ключ edition у Cargo.toml вказує, яке видання компілятор має
використовувати для вашого коду. Якщо ключа не існує, Rust використовує 2015 як значення
видання з міркувань зворотної сумісності.
Кожен проєкт може вибрати видання, відмінне від стандартного видання 2015 року. Видання можуть містити несумісні зміни, такі як включення нового ключового слова, що конфліктує з ідентифікаторами в коді. Однак, якщо ви не оберете ці зміни, ваш код і далі буде компілюватися, навіть якщо ви оновите версію компілятора Rust, яку використовуєте.
Усі версії компілятора Rust підтримують будь-яке видання, яке існувало до випуску цього компілятора, і вони можуть пов’язувати крейти будь-яких підтримуваних видань разом. Зміни видань впливають лише на те, як компілятор спочатку аналізує код. Тому, якщо ви використовуєте Rust 2015 і один із ваших залежних крейтів використовує Rust 2018, ваш проєкт скомпілюється і зможе використовувати той залежний крейт. Зворотна ситуація, коли ваш проєкт використовує Rust 2018, а залежний крейт використовує Rust 2015, також працює.
Щоб було зрозуміло: більшість можливостей буде доступна в усіх виданнях. Розробники, які використовують будь-яке видання Rust, і надалі бачитимуть поліпшення в міру виходу нових стабільних випусків. Однак у деяких випадках, головним чином коли додаються нові ключові слова, деякі нові можливості можуть бути доступні лише в пізніших виданнях. Вам потрібно буде перемкнутися на інші видання, якщо ви хочете скористатися такими можливостями.
Докладніше дивіться в The Rust Edition Guide. Це
повна книга, яка перелічує відмінності між виданнями та пояснює, як
автоматично оновити ваш код до нового видання за допомогою cargo fix.
F - Переклади книги
Додаток F: Переклади книги
Для ресурсів іншими мовами, ніж англійська. Більшість усе ще в процесі; дивіться мітку Translations, щоб допомогти, або повідомте нам про новий переклад!
- Português (BR)
- Português (PT)
- 简体中文: KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська, alternate
- Español, alternate, Español por RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
- O’zbek
- Tiếng Việt
- Italiano
- বাংলা
G - Як створюється Rust і «Nightly Rust»
Додаток G - Як створюється Rust і «Nightly Rust»
Цей додаток присвячений тому, як створюється Rust і як це впливає на вас як на Rust розробника.
Стабільність без застою
Як мова, Rust дуже дбає про стабільність вашого коду. Ми хочемо, щоб Rust був міцною основою, на якій ви можете будувати, і якби все постійно змінювалося, це було б неможливо. Водночас, якщо ми не можемо експериментувати з новими можливостями, ми можемо не виявити важливі вади аж до після їхнього випуску, коли ми вже не зможемо нічого змінити.
Наше рішення цієї проблеми — це те, що ми називаємо «стабільністю без застою», і наш керівний принцип такий: ви ніколи не повинні боятися оновлюватися до нової версії stable Rust. Кожне оновлення має бути безболісним, але також має приносити вам нові можливості, менше помилок і швидші часи компіляції.
Чух, чух! Канали випуску та поїздки потягами
Розробка Rust працює за розкладом потягів. Тобто вся розробка виконується в головній гілці репозиторію Rust. Випуски дотримуються моделі release train для програмного забезпечення, яка використовувалася Cisco IOS та іншими програмними проєктами. Є три канали випуску для Rust:
- Nightly
- Beta
- Stable
Більшість розробників Rust переважно використовують stable канал, але ті, хто хоче спробувати експериментальні нові можливості, можуть використовувати nightly або beta.
Ось приклад того, як працює процес розробки та випуску: припустімо, що команда Rust працює над випуском Rust 1.5. Цей випуск відбувся в грудні 2015 року, але він дасть нам реалістичні номери версій. До Rust додається нова можливість: новий commit потрапляє в головну гілку. Кожної ночі створюється нова nightly-версія Rust. Кожен день є днем випуску, і ці випуски автоматично створюються нашою інфраструктурою випуску. Тож із плином часу наші випуски виглядають так, щоразу вночі:
nightly: * - - * - - *
Кожні шість тижнів настає час готувати новий випуск! Гілка beta репозиторію
Rust відгалужується від головної гілки, яку використовує nightly. Тепер
є два випуски:
nightly: * - - * - - *
|
beta: *
Більшість користувачів Rust не використовують beta-випуски активно, але тестують beta у своїй CI-системі, щоб допомогти Rust виявляти можливі регресії. Тим часом nightly-випуск усе ще виходить щоночі:
nightly: * - - * - - * - - * - - *
|
beta: *
Припустімо, що виявлено регресію. Добре, що ми встигли трохи протестувати beta
випуск до того, як регресія прослизнула в stable-випуск! Виправлення застосовується до
головної гілки, тож nightly виправлено, а потім виправлення переноситься назад у
гілку beta, і створюється новий beta-випуск:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
Через шість тижнів після створення першої beta настав час stable-випуску! Гілка
stable створюється з гілки beta:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Ура! Rust 1.5 завершено! Однак ми забули про одну річ: оскільки минуло шість
тижнів, нам також потрібна нова beta наступної версії Rust, 1.6.
Тож після того, як stable відгалужується від beta, наступна версія beta знову
відгалужується від nightly:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
Це називається «модель потягів», тому що кожні шість тижнів випуск «від’їжджає зі станції», але все ще має пройти подорож через beta-канал, перш ніж прибути як stable-випуск.
Rust випускається кожні шість тижнів, як годинник. Якщо ви знаєте дату одного випуску Rust, ви можете знати дату наступного: це через шість тижнів. Гарний аспект того, що випуски заплановані кожні шість тижнів, полягає в тому, що наступний потяг невдовзі прибуває. Якщо якась можливість випадково пропустить певний випуск, немає потреби хвилюватися: ще один відбудеться за короткий час! Це допомагає зменшити тиск щоб проштовхувати, можливо, недопрацьовані можливості близько до дедлайну випуску.
Завдяки цьому процесу ви завжди можете перевірити наступну збірку Rust і
переконатися самі, що на неї легко оновитися: якщо beta-випуск не
працює так, як очікувалося, ви можете повідомити про це команді й отримати виправлення до того,
як відбудеться наступний stable-випуск! Порушення в beta-випуску є відносно рідкісним, але
rustc все ще є програмним забезпеченням, а помилки все ж існують.
Час обслуговування
Проєкт Rust підтримує найсвіжішу стабільну версію. Коли виходить нова стабільна версія, стара версія досягає кінця свого життя (EOL). Це означає, що кожна версія підтримується протягом шести тижнів.
Нестабільні можливості
Є ще одна пастка в цій моделі випуску: нестабільні можливості. Rust використовує техніку, яка називається “feature flags”, щоб визначити, які можливості увімкнені в даному випуску. Якщо нова можливість перебуває в активній розробці, вона потрапляє в головну гілку, а отже, у nightly, але за feature flag. Якщо ви, як користувач, хочете спробувати можливість, що перебуває в розробці, ви можете, але ви повинні використовувати nightly-випуск Rust і позначити ваш вихідний код відповідним flag, щоб увімкнути її.
Якщо ви використовуєте beta- або stable-випуск Rust, ви не можете використовувати жодні feature flags. Це ключ, який дозволяє нам практично використовувати нові можливості до того, як ми оголосимо їх назавжди стабільними. Ті, хто хоче перейти на bleeding edge, можуть це зробити, а ті, хто хоче міцний, надійний досвід, можуть залишитися зі stable і знати, що їхній код не зламається. Стабільність без застою.
У цій книзі міститься лише інформація про стабільні можливості, оскільки можливості, що перебувають у розробці, все ще змінюються, і, безперечно, вони будуть іншими між тим, коли ця книга була написана, і тим, коли їх увімкнуть у stable-збірках. Ви можете знайти документацію для можливостей лише для nightly онлайн.
Rustup і роль Rust Nightly
Rustup полегшує перемикання між різними каналами випуску Rust, на глобальній або проєктній основі. За замовчуванням у вас буде встановлено stable Rust. Щоб встановити nightly, наприклад:
$ rustup toolchain install nightly
Ви також можете побачити всі toolchain (випуски Rust і пов’язані
компоненти), які ви встановили, за допомогою rustup. Ось приклад на
комп’ютері Windows одного з ваших авторів:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
Як бачите, stable toolchain є типовим. Більшість користувачів Rust використовують stable
переважно. Ви, можливо, захочете використовувати stable більшість часу, але використовувати
nightly для конкретного проєкту, тому що вас цікавить cutting-edge можливість.
Щоб зробити це, ви можете використати rustup override у каталозі цього проєкту, щоб установити
nightly toolchain як ту, яку rustup має використовувати, коли ви перебуваєте в цьому каталозі:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
Тепер кожного разу, коли ви викликаєте rustc або cargo всередині
~/projects/needs-nightly, rustup подбає про те, щоб ви використовували nightly
Rust, а не ваш типовий stable Rust. Це стає у пригоді, коли у вас
є багато проєктів Rust!
Процес RFC і команди
Тож як ви дізнаєтеся про ці нові можливості? Модель розробки Rust дотримується процесу Request For Comments (RFC). Якщо ви хочете покращення в Rust, ви можете написати пропозицію, яка називається RFC.
Будь-хто може писати RFC, щоб покращити Rust, і пропозиції переглядаються та обговорюються командою Rust, яка складається з багатьох тематичних підкоманд. Повний список команд є на вебсайті Rust, який включає команди для кожної сфери проєкту: дизайну мови, реалізації компілятора, інфраструктури, документації та іншого. Відповідна команда читає пропозицію та коментарі, пише кілька власних коментарів і, зрештою, досягається консенсус щодо прийняття або відхилення можливості.
Якщо можливість прийнято, у репозиторії Rust відкривається issue, і хтось може реалізувати її. Людина, яка реалізує її, цілком можливо, не є тією самою людиною, яка спочатку запропонувала можливість! Коли реалізація готова, вона потрапляє в головну гілку за feature gate, як ми обговорювали в розділі “Нестабільні можливості”.
Через деякий час, коли розробники Rust, які використовують nightly-випуски, зможуть спробувати нову можливість, члени команди обговорять можливість, те, як вона працювала в nightly, і вирішать, чи має вона потрапити в stable Rust, чи ні. Якщо рішення — рухатися далі, feature gate видаляється, і можливість тепер вважається стабільною! Вона їде потягами до нового stable-випуску Rust.